Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition、SPP-Net、空间金字塔池化
空间金字塔池化
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition、SPP-Net、空间金字塔池化
一、相关理论
本篇博文主要讲解大神何凯明2014年的paper:《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》,这篇paper主要的创新点在于提出了空间金字塔池化。paper主页:http://research.microsoft.com/en-us/um/people/kahe/eccv14sppnet/index.html 这个算法比R-CNN算法的速度快了n多倍。
我们知道在现有的CNN中,对于结构已经确定的网络,需要输入一张固定大小的图片,比如224224,3232,9696等。这样对于我们希望检测各种大小的图片的时候,需要经过裁剪,或者缩放等一系列操作,这样往往会降低识别检测的精度,于是paper提出了“空间金字塔池化”方法,这个算法的牛逼之处,在于使得我们构建的网络,可以输入任意大小的图片,不需要经过裁剪缩放等操作,只要你喜欢,任意大小的图片都可以。不仅如此,这个算法用了以后,精度也会有所提高,总之一句话:牛逼哄哄。
空间金字塔池化,又称之为“SPP-Net”,记住这个名字,因为在以后的外文文献中,你会经常遇到,特别是物体检测方面的paper。这个就像什么:OverFeat、GoogleNet、R-CNN、AlexNet……为了方便,学完这篇paper之后,你就需要记住SPP-Net是什么东西了。空间金子塔以前在特征学习、特征表达的相关文献中,看到过几次这个算法。
既然之前的CNN要求输入固定大小的图片,那么我们首先需要知道为什么CNN需要输入固定大小的图片?CNN大体包含3部分,卷积、池化、全连接。
首先是卷积,卷积操作对图片输入的大小会有要求吗?比如一个55的卷积核,我输入的图片是3081的大小,可以得到(26,77)大小的图片,并不会影响卷积操作。我输入600500,它还是照样可以进行卷积,也就是卷积对图片输入大小没有要求,只要你喜欢,任意大小的图片进入,都可以进行卷积。
池化:池化对图片大小会有要求吗?比如我池化大小为(2,2)我输入一张3040的,那么经过池化后可以得到1520的图片。输入一张5322大小的图片,经过池化后,我可以得到2611大小的图片。因此池化这一步也没对图片大小有要求。只要你喜欢,输入任意大小的图片,都可以进行池化。
全连接层:既然池化和卷积都对输入图片大小没有要求,那么就只有全连接层对图片结果又要求了。因为全连接层我们的连接劝值矩阵的大小W,经过训练后,就是固定的大小了,比如我们从卷积到全连层,输入和输出的大小,分别是50、30个神经元,那么我们的权值矩阵(50,30)大小的矩阵了。因此空间金字塔池化,要解决的就是从卷积层到全连接层之间的一个过度。
也就是说在以后的文献中,一般空间金子塔池化层,都是放在卷积层到全连接层之间的一个网络层。
二、算法概述
OK,接着我们即将要讲解什么是空间金字塔池化。我们先从空间金字塔特征提取说起(这边先不考虑“池化”),空间金字塔是很久以前的一种特征提取方法,跟Sift、Hog等特征息息相关。为了简单起见,我们假设一个很简单两层网络:
输入层:一张任意大小的图片,假设其大小为(w,h)。
输出层:21个神经元。
也就是我们输入一张任意大小的特征图的时候,我们希望提取出21个特征。空间金字塔特征提取的过程如下:

图片尺度划分
如上图所示,当我们输入一张图片的时候,我们利用不同大小的刻度,对一张图片进行了划分。上面示意图中,利用了三种不同大小的刻度,对一张输入的图片进行了划分,最后总共可以得到16+4+1=21个块,我们即将从这21个块中,每个块提取出一个特征,这样刚好就是我们要提取的21维特征向量。
第一张图片,我们把一张完整的图片,分成了16个块,也就是每个块的大小就是(w/4,h/4);
第二张图片,划分了4个块,每个块的大小就是(w/2,h/2);
第三张图片,把一整张图片作为了一个块,也就是块的大小为(w,h)
空间金字塔最大池化的过程,其实就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出神经元。最后把一张任意大小的图片转换成了一个固定大小的21维特征(当然你可以设计其它维数的输出,增加金字塔的层数,或者改变划分网格的大小)。上面的三种不同刻度的划分,每一种刻度我们称之为:金字塔的一层,每一个图片块大小我们称之为:windows size了。如果你希望,金字塔的某一层输出n*n个特征,那么你就要用windows size大小为:(w/n,h/n)进行池化了。
当我们有很多层网络的时候,当网络输入的是一张任意大小的图片,这个时候我们可以一直进行卷积、池化,直到网络的倒数几层的时候,也就是我们即将与全连接层连接的时候,就要使用金字塔池化,使得任意大小的特征图都能够转换成固定大小的特征向量,这就是空间金字塔池化的奥义(多尺度特征提取出固定大小的特征向量)。具体的流程图如下:

空间金字塔池化(Spatial Pyramid Pooling, SPP)原理和代码实现(Pytorch)
想直接看公式的可跳至第三节 3.公式修正
1|0一、为什么需要SPP
首先需要知道为什么会需要SPP。
我们都知道卷积神经网络(CNN)由卷积层和全连接层组成,其中卷积层对于输入数据的大小并没有要求,唯一对数据大小有要求的则是第一个全连接层,因此基本上所有的CNN都要求输入数据固定大小,例如著名的VGG模型则要求输入数据大小是 (224*224) 。
固定输入数据大小有两个问题:
1.很多场景所得到数据并不是固定大小的,例如街景文字基本上其高宽比是不固定的,如下图示红色框出的文字。


2.可能你会说可以对图片进行切割,但是切割的话很可能会丢失到重要信息。
综上,SPP的提出就是为了解决CNN输入图像大小必须固定的问题,从而可以使得输入图像高宽比和大小任意。
2|0二、SPP原理
更加具体的原理可查阅原论文:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
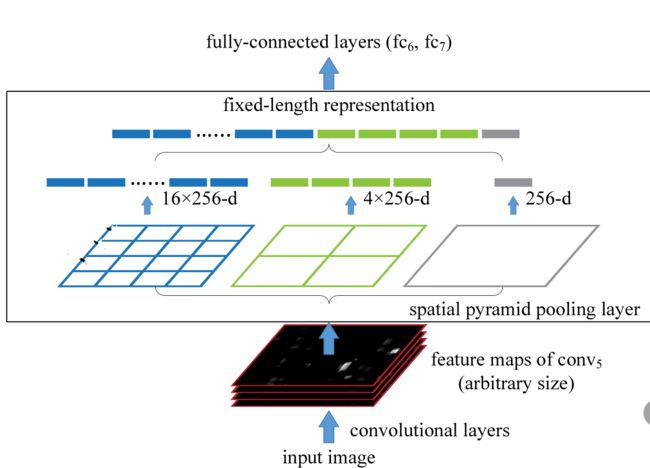
上图是原文中给出的示意图,需要从下往上看:
- 首先是输入层(input image),其大小可以是任意的
- 进行卷积运算,到最后一个卷积层(图中是conv5conv5。
四、算法源码实现、Pytorch:
#coding=utf-8
import math
import torch
import torch.nn.functional as F
# 构建SPP层(空间金字塔池化层)
class SPPLayer(torch.nn.Module):
def __init__(self, num_levels, pool_type='max_pool'):
super(SPPLayer, self).__init__()
self.num_levels = num_levels
self.pool_type = pool_type
def forward(self, x):
num, c, h, w = x.size() # num:样本数量 c:通道数 h:高 w:宽
for i in range(self.num_levels):
level = i+1
kernel_size = (math.ceil(h / level), math.ceil(w / level))
stride = (math.ceil(h / level), math.ceil(w / level))
pooling = (math.floor((kernel_size[0]*level-h+1)/2), math.floor((kernel_size[1]*level-w+1)/2))
# 选择池化方式
if self.pool_type == 'max_pool':
tensor = F.max_pool2d(x, kernel_size=kernel_size, stride=stride, padding=pooling).view(num, -1)
else:
tensor = F.avg_pool2d(x, kernel_size=kernel_size, stride=stride, padding=pooling).view(num, -1)
# 展开、拼接
if (i == 0):
x_flatten = tensor.view(num, -1)
else:
x_flatten = torch.cat((x_flatten, tensor.view(num, -1)), 1)
return x_flatten
def test():
spp1 = SPPLayer(1)
spp2 = SPPLayer(2)
spp3 = SPPLayer(3)
x1 = torch.ones((1, 3, 32, 32), dtype=torch.float)
x2 = torch.ones((1, 3, 64, 64), dtype=torch.float)
out11 = spp1(x1)
out12 = spp1(x2)
out21 = spp2(x1)
out22 = spp2(x2)
out31 = spp3(x1)
out32 = spp3(x2)
print(out11.shape, out12.shape)
print(out21.shape, out22.shape)
print(out31.shape, out32.shape)
test()