12、MapReduce编程案例
文件开发环境搭建请参考《11、HDFS编程案例》一文
一、MapReduce项目开发说明
关于MapReduc程序最核心的操作类就是Job接口类,可以知道linux下当我们通过hadoop提交jar包运行的时候,控制台打印的就是job运行整个过程,包括Map完成百分比Reduce完成百分比等。所以Job的核心就主要包括Map数据输入读取过程与Reduce数据的计算输出过程。当然中间也包括一个shuffle过程。当然实际上MapReduce的实际过程包括5个阶段。
思想:
分而治之,合并结果(合久必分,分久必合)
MR经典5个过程示意图
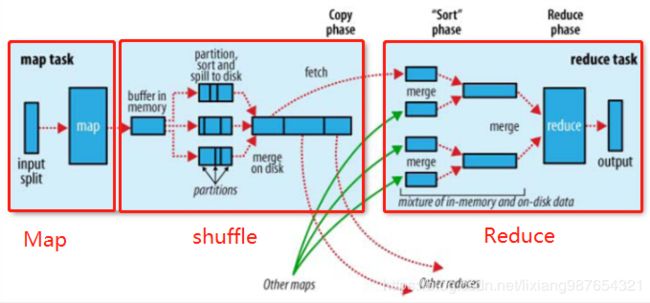
1). input阶段
获取输入数据进行分片(split)作为map的输入,此处的分片为逻辑分片,可以自己配置,默认情况下为块大小。逻辑分片过大导致数据负载不均衡,处理任务过重过大,效率无法提升上来。逻辑分片过小导致map的yarnchild进程过多,而且导致逻辑块分割成多个片,一个块文件跨主机传输,浪费带宽,减低效率。
2). map阶段
过程对某种输入格式的一条记录解析成一条或多条记录,简单点理解就是一个Map任务对应一个yarnchild,负责读取该逻辑分片(默认为块大小,防止跨块跨主机传输)的数据并按逻辑key分离输出数据到shuffle过程。
3). shffle阶段
对中间数据的控制,作为reduce的输入,通过map的数据被一行行处理后以key-value的形式输出,shuffle过程就是将相同的key组装到一块,然后通过key排序得到结果输出到reduce的过程
4). reduce阶段
对相同key的数据进行合并。一个reduce对应一组key,默认的分区算法是使用哈希余模进行分区的
5). output阶段
按照格式输出到指定目录
注意:
1)逻辑分片数量就等于Map过程中使用yarnchild进程的数量(一个splite就需要一个yarnchild的map子进程),逻辑分片默认为block大小(2.0为128M,1.0为64M),原始文件越大,分块越多,对应的map任务子进程数量越多。
2)Reduce的数量不像map过程一样,通过逻辑切分的方式自动进行,而是需要自己手动指定reduce进程数量的,指定数量n后,reduce的编号从0-(n-1)进行编号。数据从shuffle过程输出时候可能需要手动指定分区算法来达到负载均衡(如果默认的分区算法无法实现负载均衡)或者不同分类输出的目的。
通过以上步骤的分析,我们通过编程可以干预的部分包括:
1)Map过程,对输入的每一行数据进行转换并以指定不同key-value形式进行输出
2)Map输出过程对相同的key进行初次合并计算
3)shuffle过程对输出数据进行自定义分区
4)shuffle过程对数据进行自定义排序
5)Reduce过程对相同key的分组数据进行计算
6)output过程,对结果进行导向或自定义输出
二、案例一:对某目录下的所有文件进行单词个数统计
MapReduce的思路:
针对所有文件,按照块大小(实际上是逻辑分片)进行yarn计算资源分配,分配与文件相等数量的map子进程分别统计每一个文件得单词数量,然后将所有的统计结果按照相同单词(key)进行合并计算并输出结果(默认输出的HDFS)。这个过程MapReduce实现上已经帮助我们实现了,我们只需要实现Map过程结果和Reduce过程结果即可(最少的接口,可以根据自己需要自定义Map、Combiner、分区、排序、Reduce、输出等过程相关接口)。
在实现实现我们先通过脚本创建/wc目录以及上传一个单词的文件到该目录
hadoop fs -mkdir /wc
hadoop fs -ls /

hadoop fs -mv /001/1.txt /wc
hadoop fs -ls /wc
我这里使用文件移动方式,可以自己上传文件
hadoop fs -put /home/hadoop/1.txt /wc
注意:
后面得程序输出目录不能存在,hadoop为了防止结果覆盖,如果发现输出路径已经存在是会报错的!
1) 自定义实现Map过程实现
这里我们只需要实现MR程序提供的Mapper接口即可。采用内部类实现:
static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
/**
* key:每一个map读取block所在的行,一般没有用
* value: 每一行对应的数据
* context:执行全局上下文
*/
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] keys = value.toString().split(" ");
for (String string : keys) {
// 将数据输出到下一个步骤shuffle
context.write(new Text(string), new IntWritable(1));
}
}
}
我们的单词统计mapper继承自org.apache.hadoop.mapreduce.Mapper,这里有四个参数,单独拿出来说明一下以便后续更好的理解,因为Map过程实际上是读取逻辑分片的过程(默认分片大小等于块大小128M),map过程读取的就是文件块的数据,MapReduce的思想就是“合久必分,分久必合”,也就是先把大数据按照多个逻辑分片进行分割读取统计,然后把分割收的统计结果合并计算输出(大概就是这个意思,具体包括的以上图形的5个步骤,被hadoop搭建了框架实现,5个步骤你都可以自定义相关操作而不需要进行框架开发),所以map的过程就是数据的输入与数据的输出,4个参数前两个为输入数据类型,后两个为输出数据类型,所有的数据类型都是要序列化的,hadoop实现类自己一套轻量级的序列号接口(摒弃了Java的重量级序列化接口–因为Java自带的会序列化类本身信息而hadoop不需要,只需要序列化属性数据即可)
参数信息
LongWritable: 输入行类型,这个保持整形即可
Text:map的输入数据类型,我们默认使用FileInputFormat的是其实现类TextInputFormat,即读取一行的文本数据,hadoop序列化的文本类为Text
Text:我们设定的map输出的key为单词,所以这里输出类型为Text
IntWritable:我们设定的map输出的value为单词的数量,所以这里输出类型为IntWritable实现类
FileInputFormat继承类关系
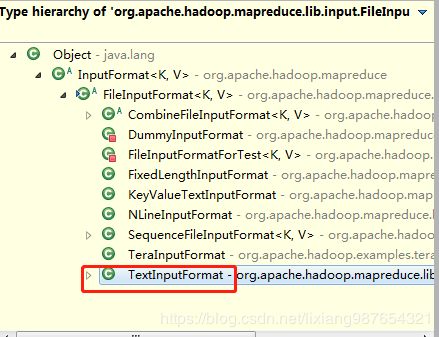
此处,我们的map过程就是处理一行数据,通过空格分隔一行数据,并以key-value形式输出,每一个单词都累计一个值为1(在reduce中分组后直接累加即可)
2)自定义Reduce过程实现
static class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
/**
* 将map过程输出数据到shuffle过程会经过combine、分区、排序、分组、溢写过程,最后到reduce
* reduce的输入数据是[combine合并没有自定义就没有该过程]、经过分区的(默认哈希余模分区)、排序的(默认是按照key的降序)、分组的(默认按照key分组)数据
* 我们只需要将相同key的多个values进行处理然后通过context输出到文件中(默认输出大hdfs中)
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
// 对相同的key进行累加合并,如输入数据{hello, {1,1,1,1}}、{world, {1,1,1,1}}、{test, {1,1,1,1}}
int sum = 0;
for (IntWritable intWritable : values) {
sum += intWritable.get();
}
context.write(key, new IntWritable(sum));
}
}
经过map的数据就是将相同的key分区后的、按照key排序后的、按照key(默认是key的Comparable接口Compre或compareTo返回0的进行分组)分组的数据,这里reduce只要将相同key进行累计合并即可。这里我们是累计相加运算。
3)驱动类实现
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 设置系统运行用户
System.setProperty("HADOOP_USER_NAME", "hadoop");
// 配置类
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop01:9000");
// 创建MapReduce程序的任务Job
Job job = Job.getInstance(conf);
// 设置job驱动类:原因一个jar可以有多个主类或入口
job.setJarByClass(Driver.class);
// 设置job的map和reduce过程处理类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
// 设置map的输出key和value的类型
// 原因:类中的泛型声明只能在编译期间是否可以编译通过,编译完成后字节中类的泛型是不知道具体类类型的
// 所以需要手动指定泛型的输入key和value的类类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置reduce的输出key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 文件读取类:设置作业的输入数据与输出路径
// 输入数据可以是文件,也可以是目录(表示处理目录下所有的数据)
FileInputFormat.setInputPaths(job, new Path("/wc"));
FileOutputFormat.setOutputPath(job, new Path("/wc_out"));
// 提交计算作业
// 这种方式是没有日志打印的
//job.submit();
job.waitForCompletion(true);
}
这里我们需要注意以及几点:
A、每一个MapReduce程序都是一个job(保持和linux脚本执行一样)
B、每一个Job必须设置jar包的主类、自定义过程的类(如自定义Map、自定义Combine、自定义分区、自实现Comparable分组、自定义Reduce等)
C、Map或Reduce的输出key和value的类型必须手动指定,因为泛型只有编译过程生效保证程序不正确无法编译通过,但是运行时需要手动指定
D、waitForCompletion包含了submit的是否启动日志功能的实现
4)直接在Eclipse中运行
通过全局计数器,我们可以看到mapreduce程序自带的全局计数器统计结果
File System Counters
FILE: Number of bytes read=3236
FILE: Number of bytes written=605979
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1356
HDFS: Number of bytes written=683
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Map-Reduce Framework
Map input records=10
Map output records=128
Map output bytes=1173
Map output materialized bytes=1435
Input split bytes=94
Combine input records=0
Combine output records=0
Reduce input groups=88
Reduce shuffle bytes=1435
Reduce input records=128
Reduce output records=88
Spilled Records=256
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=52
Total committed heap usage (bytes)=827326464
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=678
File Output Format Counters
Bytes Written=683
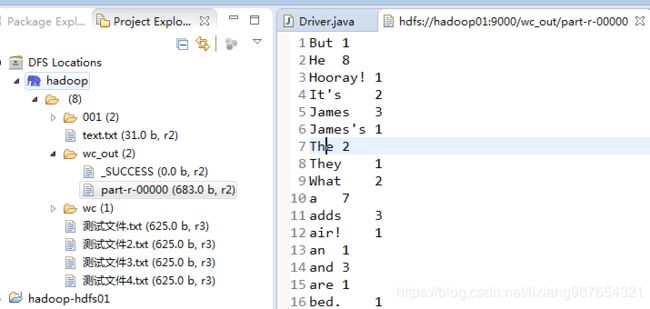
以上总共5个过程n个全集计数器,shuffle Errors统计的就是map与reduce成功或失败的数量。发现都为0,没有错误,查看结果,刷新eclipse的DFS节点

可以看到输出目录/wc_out下生产两个文件,第一个为标志文件表示成功或失败,字节为0,另一个为reduce的输出文件(因为默认只有一个reduce所以只有一个)part-r-00000(名称为part+reduce的r《如果没有reduce,只有map,输出结果为part-m-0000》+reduce的序号,从0开始标识的序号),结果中可以看到各个单词的统计结果!
5)生产环境下运行
打包成jar包到linux下



注意:
不需要导出hadoop相关的jar包,因为生产环境下已经包括了这些jar包!将jar上传到hadoop的任意机器,次数我们随意选择hadoop03
运行我们打包的程序,首先我们看一下hadoop jar的命令格式

RunJar jarFile [mainClass] args...

所以命令格式如下:
hadoop jar 可运行jar的位置 主类的完整包名 程序运行需要的参数列表
因为我们程序没有运行参数,所以我们运行jar包如下
hadoop jar /home/hadoop/wordcount.jar com.easystudy.Driver
注意需要保证,否则报错,我们的输出目录不存在(hadoop为了安全,防止数据覆盖必须要求输出目录不存在)
[hadoop@hadoop03 hadoop]$ hadoop jar /home/hadoop/wordcount.jar com.easystudy.Driver
19/12/18 21:27:22 INFO client.RMProxy: Connecting to ResourceManager at hadoop03/192.168.8.242:8032
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://hadoop01:9000/wc_out already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:146)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:266)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:139)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1758)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308)
at com.easystudy.Driver.main(Driver.java:103)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
[hadoop@hadoop03 hadoop]$
删除目录后再次运行
hadoop fs -rm -r -f /wc_out
hadoop jar /home/hadoop/wordcount.jar com.easystudy.Driver

通过YARN资源管理页面我们可以看到我们提交的作业执行进度信息

查看输出结果(可以使用web或者Eclipse的插件查看)
3、使用自定义Combine优化map的输出过程
在WordCount案例中,即将每一行中的内容分割为单独的单词之后,就立即写出。但是想一下,如果我们同时有多个Mapper任务在运行。每个Mapper处理各自负责的内容,如果我们在每个Mapper内部进行局部汇总之后,再将多个Mapper任务的输出合并到Reducer中,是不是效率更高呢?
关于局部汇总概念,通过案例来讲解,假设我们的word.txt中的内容为
hello you
hello me
hello he
hello she
假设我们分片较小,正好使得mapper1负责处理1、2行,mapper2负责处理3、4行。在没有进行局部汇总的情况下,那么
mapper1输出
,1>
,1>
,1>
,1>
mapper2输出
,1>
,1>
,1>
,1>
combine分为map端和reduce端,作用是把同一个key的键值对合并在一起,可以自定义的。combine函数把一个map函数产生的
在进行了局部汇总的情况下,mapper1输出:
**,2>**
,1>
,1>
mapper2输出
**,2>**
,1>
,1>
可以看到使用的combine之后,各个map的输出得到以下优化:
(1)key-value以key相同进行的初步合并(同reduce的过程几乎完全一样)计算,减少了网络传输
(2)将部分计算任务放置到map过程,减少了大量数据完全由reduce计算所带来的负载和压力,提升了整体执行效率
自定义combine的实现
/**
* @文件名: Driver.java
* @功 能: TODO(自定义combine)
* @作 者: [email protected]
* @日 期: 2019年12月19日
* @版 本: V1.0
* @说 明: combine类实现的功能和reduce逻辑基本上相同,都是处理相同key的分组合并,不同之处在于combine是处理每一个map的小部分整合
* 而reduce做的功能就是整个数据的负载均衡后到达该reduce的所有数据(可能来自多个map经过combine之后的数据)的整合,
* **所以:Combine类可以用Reduce类进行替代!!(我说的是大多数情况下)
*/
static class MyCombiner extends Reducer<Text, IntWritable, Text, IntWritable>{
/**
* 将map过程输出数据到shuffle过程会经过combine、分区、排序、分组、溢写过程,最后到reduce
* reduce的输入数据是[combine合并没有自定义就没有该过程]、经过分区的(默认哈希余模分区)、排序的(默认是按照key的降序)、分组的(默认按照key分组)数据
* 我们只需要将相同key的多个values进行处理然后通过context输出到文件中(默认输出大hdfs中)
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
System.out.println("****************************");
// 对相同的key进行累加合并,如输入数据{hello, {1,1,1,1}}、{world, {1,1,1,1}}、{test, {1,1,1,1}}
int sum = 0;
for (IntWritable intWritable : values) {
sum += intWritable.get();
System.out.println("key:" + key + ", value:" + intWritable.get());
}
context.write(key, new IntWritable(sum));
}
}
调用主类实现
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 设置系统运行用户
System.setProperty("HADOOP_USER_NAME", "hadoop");
// 配置类
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop01:9000");
// 创建MapReduce程序的任务Job
Job job = Job.getInstance(conf);
// 设置job驱动类:原因一个jar可以有多个主类或入口
job.setJarByClass(Driver.class);
// 设置job的map和reduce过程处理类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
job.setCombinerClass(MyCombiner.class);
// 设置map的输出key和value的类型
// 原因:类中的泛型声明只能在编译期间是否可以编译通过,编译完成后字节中类的泛型是不知道具体类类型的
// 所以需要手动指定泛型的输入key和value的类类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置reduce的输出key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 文件读取类:设置作业的输入数据与输出路径
// 输入数据可以是文件,也可以是目录(表示处理目录下所有的数据)
FileInputFormat.setInputPaths(job, new Path("/wc"));
FileOutputFormat.setOutputPath(job, new Path("/wc_out4"));
// 提交计算作业
// 这种方式是没有日志打印的
//job.submit();
job.waitForCompletion(true);
}
我们增加了自定义combiner类的设置
job.setCombinerClass(MyCombiner.class);
因为Combiner的工作同Reduce工作一样,一个是处理map输出的部分数据,一个是处理所有map输出的数据,所以Combiner和Reduce第等价的,代码几乎100%相同,所以Combiner可以使用Reduce处理类进行替换:
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 设置系统运行用户
System.setProperty("HADOOP_USER_NAME", "hadoop");
// 配置类
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop01:9000");
// 创建MapReduce程序的任务Job
Job job = Job.getInstance(conf);
// 设置job驱动类:原因一个jar可以有多个主类或入口
job.setJarByClass(Driver.class);
// 设置job的map和reduce过程处理类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
job.setCombinerClass(MyCombiner.class);
// 以上等价于如下配置
//job.setCombinerClass(WordCountReduce.class);
// 设置map的输出key和value的类型
// 原因:类中的泛型声明只能在编译期间是否可以编译通过,编译完成后字节中类的泛型是不知道具体类类型的
// 所以需要手动指定泛型的输入key和value的类类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置reduce的输出key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 文件读取类:设置作业的输入数据与输出路径
// 输入数据可以是文件,也可以是目录(表示处理目录下所有的数据)
FileInputFormat.setInputPaths(job, new Path("/wc"));
FileOutputFormat.setOutputPath(job, new Path("/wc_out4"));
// 提交计算作业
// 这种方式是没有日志打印的
//job.submit();
job.waitForCompletion(true);
}
4、自定义分区
我们知道Reduce的数量决定了程序的处理效率,在不手动设置Reduce数量的情况下,默认的reduce数量就一个,也就是说所有的Map输出默认经过哈希余模分区后全部进入到序号为0的reduce程序中,但是如果数据量非常大,那么一个reduce就要处理所有的数据,极大影响数据的处理效率,所以,我们需要根据数据量以及自己需要的输出结果手动设置Reduce数量来达到提升效率、数据分类输出的目的;
自定义分区的原因
(1) 解决数据倾斜问题
每个Reduce都对应对应多个Map,多个map输出数据进入到Reduce的过程中都需要经过分区算法,造成Map过程输出到不同Reduce过程数据输入不均衡,就会导致数据倾斜问题,所以,分区算法的好坏决定了是否产生数据倾斜(负载均衡)和程序性能的关键。默认情况下Shuffle过程的分区算法使用的是“哈希余模”算法,也就是将所有key的哈希值(如果超过32bit只取32bit)余上reduce的数量,换句话说,map的输出数据会根据分区算法“均匀”的分布到0~n个reduce中,当然这种情况是数据量非常大且数据本身分布均衡的情况下才可能不会造成数据倾斜问题,很多时候使用默认的分区算法会造成数据倾斜(及数据负载不均衡)问题,所以我们需要自定义分区算法来达到负载均衡。
(2)自定义输出问题
比如,如果我们有一大批通话记录数据,我们需要根据不同的城市来统计通话信息? 那怎么办?需求的目的就是不同的城市的通话信息分类输出到不同的结果文件中,那就说明不同的Reduce要处理不同城市的数据并输出到该城市的结果集中,所以我们需要创建n个城市对应n个reduce,然后自定义分区根据城市将数据发送到指定的reduce即可达到以上目录。
以下实例中有部分从网上down下来的用户上网数据,大致如下,让我们来做一个小的测试实现自定义分区

各个数据字段的含义大致如下:
用户访问时间,用户账号,用户查询关键词,该URL在返回结果中的排名+用户点击的顺序号,用户点击的网站地址
上传测试数据
hadoop fs -mkdir /surf
hadoop fs -put surf_data.txt /surf
需求如下:
将用户上网数据按照用户账号的第一位进行输出到不同的结果中,这里就分为0-9总共10个分区,不同的分区输出不同的数据
(3)自定义分区实现
/**
* @功 能: TODO(根据用户账号第一位确定分区索引)
* @作 者: [email protected]
* @日 期: 2019年12月19日
* @版 本: V1.0
*/
static class CustomPartition extends Partitioner<Text, SurfRecord>{
@Override
public int getPartition(Text key, SurfRecord value, int numPartitions) {
try {
String account = key.toString();
int partition = Integer.parseInt(account.substring(0, 1));
return partition;
} catch (Exception e) {
e.printStackTrace();
return -1;
}
}
}
可以看到我们是通过账号的第一个字符0-9进行分区的,0shuffle过程中被送到0号reduce中,9则被送入到9号refuce进程中进行处理
(4)map过程实现
/**
* key:每一个map读取block所在的行,一般没有用
* value: 每一行对应的数据
* context:执行全局上下文
*/
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
try {
if(-1 != value.toString().indexOf("[") && -1 != value.toString().indexOf("]")){
String left = value.toString().substring(0, value.toString().indexOf("[") - 1);
String right = value.toString().substring(value.toString().indexOf("]") + 2);
String keyword = value.toString().substring(value.toString().indexOf("[") + 1, value.toString().indexOf("]"));
String[] keys = left.split(",");
String[] keys2 = right.split(",");
String[] rand_order = keys2[keys2.length-2].trim().split(" ");
if (rand_order.length == 2 && keys.length >= 2 && keys2.length >= 2) {
SurfRecord record = new SurfRecord(keys[0].trim(),keys[1].trim(),keyword.trim(),
Integer.parseInt(rand_order[0].trim()),
Integer.parseInt(rand_order[1].trim()),
keys2[keys2.length-1].trim());
context.write(new Text(record.getAccount()), record);
} else{
System.out.println("不合法记录:" + value.toString());
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
map过程的输出key为用户账号,输出类型为自定义类型SurfRecord(必定义类必须实现序列化接口)
(5)reduce过程实现
static class PartitionReduce extends Reducer<Text, SurfRecord, Text, SurfRecord>{
/**
* 将map过程输出数据到shuffle过程会经过combine、分区、排序、分组、溢写过程,最后到reduce
* reduce的输入数据是[combine合并没有自定义就没有该过程]、经过分区的(默认哈希余模分区)、排序的(默认是按照key的降序)、分组的(默认按照key分组)数据
* 我们只需要将相同key的多个values进行处理然后通过context输出到文件中(默认输出大hdfs中)
*/
@Override
protected void reduce(Text key, Iterable<SurfRecord> values,
Context context) throws IOException, InterruptedException {
for (SurfRecord record : values) {
context.write(key, record);
}
}
}
reduce过程仅仅是将分组后的数据重新输出,value也是自定义类(实现了toSting接口)
(6)自定义key实现
/**
* @文件名: SurfRecord.java
* @功 能: TODO(用一句话描述该文件做什么)
* @作 者: [email protected]
* @日 期: 2019年12月19日
* @版 本: V1.0
*/
package com.easystudy.mode;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
/**
* @文件名: SurfRecord.java
* @功 能: TODO(用一句话描述该文件做什么)
* @作 者: [email protected]
* @日 期: 2019年12月19日
* @版 本: V1.0
*/
public class SurfRecord implements Writable{
private String time; // 用户访问时间
private String account; // 访问用户账号
private String keyWord; // 搜索关键词
private int rank; // URL在返回结果中的排名
private int order; // 用户单击的顺序号
private String url; // 用户访问的URL
public SurfRecord() {
super();
}
public SurfRecord(String time, String account, String keyWord, int rank, int order, String url) {
super();
this.time = time;
this.account = account;
this.keyWord = keyWord;
this.rank = rank;
this.order = order;
this.url = url;
}
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
public String getAccount() {
return account;
}
public void setAccount(String account) {
this.account = account;
}
public String getKeyWord() {
return keyWord;
}
public void setKeyWord(String keyWord) {
this.keyWord = keyWord;
}
public int getRank() {
return rank;
}
public void setRank(int rank) {
this.rank = rank;
}
public int getOrder() {
return order;
}
public void setOrder(int order) {
this.order = order;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
/**
* SurfRecord轻量级序列化接口
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(time);
out.writeUTF(account);
out.writeUTF(keyWord);
out.writeInt(rank);
out.writeInt(order);
out.writeUTF(url);
}
/**
* SurfRecord轻量级反序列化接口
*/
@Override
public void readFields(DataInput in) throws IOException {
time = in.readUTF();
account = in.readUTF();
keyWord = in.readUTF();
rank = in.readInt();
order = in.readInt();
url = in.readUTF();
}
/**
* 自定义输出格式:保持原格式输出
*/
@Override
public String toString() {
return time + "," + account + "," + keyWord + "," + rank + "," + order + "," + url;
}
}
可以看到该类实现了序列化和反序列化接口,注意序列化和反序列化字段的顺序必须相同以便存入和取出字段一一对应。
(7)驱动类入口实现
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 设置系统运行用户
System.setProperty("HADOOP_USER_NAME", "hadoop");
// 配置类
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop01:9000");
// 创建MapReduce程序的任务Job
Job job = Job.getInstance(conf);
// 设置job驱动类:原因一个jar可以有多个主类或入口
job.setJarByClass(WordCountDriver.class);
// 设置job的map和reduce过程处理类
job.setMapperClass(PartitionMapper.class);
job.setReducerClass(PartitionReduce.class);
// 设置map的输出key和value的类型
// 原因:类中的泛型声明只能在编译期间是否可以编译通过,编译完成后字节中类的泛型是不知道具体类类型的
// 所以需要手动指定泛型的输入key和value的类类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(SurfRecord.class);
// 设置reduce的输出key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(SurfRecord.class);
// 设置reduce处理进程(yarnchild)数量
job.setNumReduceTasks(10);
job.setPartitionerClass(CustomPartition.class);
// 文件读取类:设置作业的输入数据与输出路径
// 输入数据可以是文件,也可以是目录(表示处理目录下所有的数据)
FileInputFormat.setInputPaths(job, new Path("/surf"));
FileOutputFormat.setOutputPath(job, new Path("/surf_out"));
// 提交计算作业
// 这种方式是没有日志打印的
//job.submit();
job.waitForCompletion(true);
}
驱动类,我们做了如下修改,增加了设定reduce数量以及设定自定义分区设置
// 设置reduce处理进程(yarnchild)数量
job.setNumReduceTasks(10);
job.setPartitionerClass(CustomPartition.class);
最后运行结果:

可以看到我们输出的时候value为自定义类,输出的第一列为key也是包含了account,所以我们需要调整如下,key与value输出自定义分隔符,自定义类不在输出account以免重复!修改自定义类的toString方法
A、去掉account输出
/**
* 自定义输出格式:保持原格式输出
*/
@Override
public String toString() {
return time + "," + keyWord + "," + rank + "," + order + "," + url;
}
B、自定义文本输出分隔符
// 配置类
Configuration conf = new Configuration();
// 设置fs文件系统的访问地址(namenode)
conf.set("fs.defaultFS", "hdfs://hadoop01:9000");
// 自定义文本输出格式分隔符
conf.set("mapred.textoutputformat.separator", ",");
最后修正后输出结果如下

当然还有一种方式就是输出key设置为NullWritable,value设置为SurfRecord(此时toString就不需要去掉account)
5、自定义key
默认情况下MapReduce框架对key进行排序是按照key的字母表顺序进行升序排序的,如果需要自定义key,那么久必须实现WritableComparable(实际上是Writable和Comparable两个接口的实现接口)接口,做到序列化和两个key的排序比较功能,所以,如果将自定义对象作为key,那么value我们可以直接设置为NullWritable,即value什么都不用输出,只输出key即可!
需求:
将上一步骤的输出结果,按照URL排名升序排列、访问序号降序排列输出。上一步骤的输出结果如下:

首先,我们需要改造SurfRecord实体类,使其实现WritableComparable接口
/**
* @文件名: SurfRecord.java
* @功 能: TODO(用一句话描述该文件做什么)
* @作 者: [email protected]
* @日 期: 2019年12月19日
* @版 本: V1.0
*/
package com.easystudy.mode;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/**
* @文件名: SurfRecord.java
* @功 能: TODO(用一句话描述该文件做什么)
* @作 者: [email protected]
* @日 期: 2019年12月19日
* @版 本: V1.0
*/
public class SurfRecord implements WritableComparable<SurfRecord>{
private String time; // 用户访问时间
private String account; // 访问用户账号
private String keyWord; // 搜索关键词
private int rank; // URL在返回结果中的排名
private int order; // 用户单击的顺序号
private String url; // 用户访问的URL
public SurfRecord() {
super();
}
public SurfRecord(String time, String account, String keyWord, int rank, int order, String url) {
super();
this.time = time;
this.account = account;
this.keyWord = keyWord;
this.rank = rank;
this.order = order;
this.url = url;
}
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
public String getAccount() {
return account;
}
public void setAccount(String account) {
this.account = account;
}
public String getKeyWord() {
return keyWord;
}
public void setKeyWord(String keyWord) {
this.keyWord = keyWord;
}
public int getRank() {
return rank;
}
public void setRank(int rank) {
this.rank = rank;
}
public int getOrder() {
return order;
}
public void setOrder(int order) {
this.order = order;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
/**
* SurfRecord轻量级序列化接口
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(time);
out.writeUTF(account);
out.writeUTF(keyWord);
out.writeInt(rank);
out.writeInt(order);
out.writeUTF(url);
}
/**
* SurfRecord轻量级反序列化接口
*/
@Override
public void readFields(DataInput in) throws IOException {
time = in.readUTF();
account = in.readUTF();
keyWord = in.readUTF();
rank = in.readInt();
order = in.readInt();
url = in.readUTF();
}
/**
* 自定义排序接口实现
* URL排名升序排名,访问次序降序排名
*/
@Override
public int compareTo(SurfRecord o) {
if(this.rank - o.getRank() > 0){
return this.rank - o.getRank();
}
return o.getOrder() - this.order;
}
/**
* 自定义key实现类
*
*/
@Override
public String toString() {
return account + ";" + time + ";" + keyWord + ";" + rank + ";" + order + ";" + url;
}
/**
* 实体类不是key实现
* 自定义输出格式:保持原格式输出
@Override
public String toString() {
return time + ";" + keyWord + ";" + rank + ";" + order + ";" + url;
}*/
}
这里,我们实现了WritableComparable接口(也可以在实现Writable接口上实现Comparable接口),首先通过rank进行升序排序,然后在通过order降序排序。
驱动类实现:
/**
* @文件名: OrderDriver.java
* @功 能: TODO(用一句话描述该文件做什么)
* @作 者: [email protected]
* @日 期: 2019年12月19日
* @版 本: V1.0
*/
package com.easystudy;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.easystudy.mode.SurfRecord;
/**
* @文件名: OrderDriver.java
* @功 能: TODO(使用自带的key升序功能排序)
* @作 者: [email protected]
* @日 期: 2019年12月19日
* @版 本: V1.0
* @需 求: 实现以返回结果中的排名降序,以用户点击的顺序号升序的用户访问记录信息
*/
public class OrderDriver {
static class OrderMapper extends Mapper<LongWritable, Text, SurfRecord, NullWritable>{
/**
* key:每一个map读取block所在的行,一般没有用
* value: 每一行对应的数据
* context:执行全局上下文
*/
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
try {
String[] splits = value.toString().split(";");
SurfRecord record = new SurfRecord(splits[1], splits[0], splits[2],
Integer.parseInt(splits[3].trim()),
Integer.parseInt(splits[4].trim()),
splits[5]);
context.write(record, NullWritable.get());
} catch (Exception e) {
System.out.println("非法:" + value);
}
}
}
static class OrderReduce extends Reducer<SurfRecord, NullWritable, SurfRecord, NullWritable>{
/**
* 将map过程输出数据到shuffle过程会经过combine、分区、排序、分组、溢写过程,最后到reduce
* reduce的输入数据是[combine合并没有自定义就没有该过程]、经过分区的(默认哈希余模分区)、排序的(默认是按照key的降序)、分组的(默认按照key分组)数据
* 我们只需要将相同key的多个values进行处理然后通过context输出到文件中(默认输出大hdfs中)
*/
@Override
protected void reduce(SurfRecord key, Iterable<NullWritable> values,Context context)
throws IOException, InterruptedException {
System.out.println("**********************");
for (NullWritable record : values) {
context.write(key, record);
System.out.println(key);
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 设置系统运行用户
System.setProperty("HADOOP_USER_NAME", "hadoop");
// 配置类
Configuration conf = new Configuration();
// 设置fs文件系统的访问地址(namenode)
conf.set("fs.defaultFS", "hdfs://hadoop01:9000");
// 自定义文本输出格式分隔符
conf.set("mapred.textoutputformat.separator", "");
// 创建MapReduce程序的任务Job
Job job = Job.getInstance(conf);
// 设置job驱动类:原因一个jar可以有多个主类或入口
job.setJarByClass(OrderDriver.class);
// 设置job的map和reduce过程处理类
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReduce.class);
// 设置map的输出key和value的类型
// 原因:类中的泛型声明只能在编译期间是否可以编译通过,编译完成后字节中类的泛型是不知道具体类类型的
// 所以需要手动指定泛型的输入key和value的类类型
job.setMapOutputKeyClass(SurfRecord.class);
job.setMapOutputValueClass(NullWritable.class);
// 设置reduce的输出key和value的类型
job.setOutputKeyClass(SurfRecord.class);
job.setOutputValueClass(NullWritable.class);
// 设置reduce处理进程(yarnchild)数量
job.setNumReduceTasks(1);
// 文件读取类:设置作业的输入数据与输出路径
// 输入数据可以是文件,也可以是目录(表示处理目录下所有的数据)
FileInputFormat.setInputPaths(job, new Path("/surf_out"));
FileOutputFormat.setOutputPath(job, new Path("/surf_out2"));
// 提交计算作业
// 这种方式是没有日志打印的
//job.submit();
job.waitForCompletion(true);
}
}
处理结果:
可以看到排序首先先按照rank升序排列,然后按照order降序排列!
注意《重点》:
我们在执行过程中,可以看到reduce中的每一组打印数据如下所示(截取了一小部分):

可以看到分区的一句是两个key(也就是SurfRecord)中的rank相等且order相等才会被分到一组,也就是说如果key是Text,那么就是Text相同会被分到一组,如果是自定义对象的时候,那么被分到一组的条件是:compare或compareTo返回0的情况(适用于所有类型的key,包括Text的compare)!
6、自定义分组
从上面的示例我们可以知道,使用MR的key的默认排序是因为实现了Comparable接口或GroupComparator接口,在没有明确设置分组类的时候,MR根据key实现的接口的compareTo或compare(GroupComparator)返回的值为0的进行分组,所以以上示例中,我们使用自定义的key实现了WritableComparable接口(既可以序列化又可以排序分组),但是这个接口仅仅只能对key中包含的字段进行分组,很多时候我们分组的字段可能不包含在自定义的key中,比如“三年1班、三年2班”两个字段,我们按照“三年”进行排序(这只是一个说明而已),那么此时就只能使用自定义分组的形式实现了。或者说排序的字段有多个,但是分组的字段我们只需要其中一个,但是不能为了兼顾key分组其他字段就不考虑作为排序的一部分(因为冲突了,排序可能多个字段,分组就一个字段,但是只有返回0才认为是一组,这就导致本可以分为一组的却应为包含其他排序字段导致不能返回0,所以导致无法分到一组进入reduce),所以此时也必须用到自定义排序。
如下一组测试数据:
chinese,zhangsan,80,90,99,60,70,85,93
math,lisi,55,67,88,92
english,wangwu,90,98,96,87,82,80
chemistry,99,88,77,89,96,89,84,76
chinese,lisi,80,90,99,60,70,85,93
math,zhaoliu,88,89,88,92,89
english,zhangsan,80,90,99,60,70,85,93
chemistry,100,87,76,80,96,89,84,76
每一行表示某门课程某人的每次考试成绩列表(不固定)
(1)需求
求每门课程平均分的最高分成绩人员名单
(2)分析
首先根据需求,我们可以知道reduce输入数据必须按照课程进行分组进入,然后我们必须对进入的数据(某人的平均值)进行排序,所以,进入的数据应该是自定义数据,且包括课程和平均值;其次,我们必须根据课程字段进行分组,对平均值字段进行排序。
(3)上传文件
hadoop fs -mkdir -p /corse
hadoop fs -put corse.txt /corse

(4)实现
通过以上分析,我们的实现是编写一个自定义类,使用课程和平均分进行排序,使用自定义分组进行分组。一下实现过程如下所示:
自定义实体类:
/**
* @文件名: AverageScore.java
* @功 能: TODO(用一句话描述该文件做什么)
* @作 者: [email protected]
* @日 期: 2019年12月21日
* @版 本: V1.0
*/
package com.easystudy.mode;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/**
* @文件名: AverageScore.java
* @功 能: TODO(用一句话描述该文件做什么)
* @作 者: [email protected]
* @日 期: 2019年12月21日
* @版 本: V1.0
*/
public class AverageScore implements WritableComparable<AverageScore>{
private String corse; // 课程名
private float score; // 平均分
private String name;
public AverageScore() {
super();
}
public AverageScore(String corse, float score) {
super();
this.corse = corse;
this.score = score;
}
public String getCorse() {
return corse;
}
public void setCorse(String corse) {
this.corse = corse;
}
public float getScore() {
return score;
}
public void setScore(float score) {
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return corse + "," + name + "," + score;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(corse);
out.writeUTF(name);
out.writeFloat(score);
}
@Override
public void readFields(DataInput in) throws IOException {
corse = in.readUTF();
name = in.readUTF();
score = in.readFloat();
}
/**
* 注意:在map到reduce过程中会默认先进行排序在进行分组的,所以此处必须先按课程排序,在按分数排序
* 否则会出现如下分组问题:
* ----------------------
* english 85.5
* english 83
* ----------------------
*/
@Override
public int compareTo(AverageScore o) {
// 将分组字段纳入排序范围,否则导致排序后再分组会出现reduce端多条记录
// 先按分组字段(这里是课程)排序,然后在按分数排序
if (0 == this.getCorse().compareTo(o.getCorse())) {
// 课程相同的时候在进行排序
if(0 == this.getScore() - o.getScore())
return 0;
return this.getScore() - o.getScore() > 0 ? -1 : 1;
}
return this.getCorse().compareTo(o.getCorse());
}
}
注意:
A、在map到reduce过程中会默认先进行排序在进行分组的,所以此处必须先按课程排序,在按分数排序,目的是到reduce相同课程的排在一起
B、如果有自定义分组,必须将分组字段纳入排序范围,否则导致排序后再分组会出现reduce端多条记录
自定义mapper类计算平均数
/**
* @功 能: TODO(自定义key排序)
* @作 者: [email protected]
* @日 期: 2019年12月21日
* @版 本: V1.0
*/
static class CorseMapper extends Mapper<LongWritable, Text, AverageScore, AverageScore>{
// 创建成员对象,防止不断创建对象导致内存暴增(GC不能及时回收)
private AverageScore avgScore = new AverageScore();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 输入数据:chinese,zhangsan,80,90,99,60,70,85,93
String[] splite = value.toString().split(",");
int sum = 0;
for (int i = 2; i < splite.length; i++) {
sum += Integer.parseInt(splite[i].trim());
}
float avg = sum*1.0f / ( splite.length -2 );
// 计算并设置课程平均分
avgScore.setCorse(splite[0].trim());
avgScore.setName(splite[1].trim());
avgScore.setScore(avg);
// 写出输入(每次调用立马回写出,所以avgScore不会后续修改导致数据变化)
context.write(avgScore, avgScore);
}
}
注意:
为了能尽量占用内存或保证内存及时释放,我们将在map的每一行都开辟的两遍提取到Mapper的成员变量,然后只需要开辟一个对象即可,这样就极大的降低内存需求,减少内存使用!
自定义分组类:
/**
* @功 能: TODO(对实现了序列化排序接口自定义key进行自定义分组)
* @作 者: [email protected]
* @日 期: 2019年12月21日
* @版 本: V1.0
*/
static class CorseGroup extends WritableComparator{
/**
* 这里很关键,第二个参数:默认情况下是不会创建内部对象的,所以必须重载构造函数第二参数设置为true
* 使其创建内部对象,否则运行会报空指针错误
*/
public CorseGroup() {
super(AverageScore.class, true);
}
@Override
@SuppressWarnings("rawtypes")
public int compare(WritableComparable a, WritableComparable b) {
AverageScore asc = (AverageScore)a;
AverageScore bsc = (AverageScore)b;
return asc.getCorse().compareTo(bsc.getCorse());
}
}
注意:
A、分组其实就是一个比较过程,按照key比较,只要返回0的就是一组。所以自定义分组实现
WritableComparator的compare方法即可(比较的就是自定义key)
B、这里必须实现构造,构造的第二参数设置为true,用于创建内部对象,默认为false不会创建内部对象,否则运行报空指针错误!
C、默认情况下排序在分组之前(正常的shuffle过程:在map到reduce过程中会默认先进行排序),而我们需要的是先分组在分组后进行排序
自定义reducer类实现
/**
* @功 能: TODO(自定义reduce实现平均分最高输出)
* @作 者: [email protected]
* @日 期: 2019年12月21日
* @版 本: V1.0
*/
static class CorseReduce extends Reducer<AverageScore, AverageScore, Text, NullWritable>{
@Override
protected void reduce(AverageScore key, Iterable<AverageScore> values, Context context)
throws IOException, InterruptedException {
AverageScore max = values.iterator().next();
String outText = key.getCorse() + "," + max.getName() + "," + max.getScore();
context.write(new Text(outText), NullWritable.get());
}
}
驱动类入口实现
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 设置JVM环境变量,设置运行hadoop运行用户
System.setProperty("HADOOP_USER_NAME", "hadoop");
// 配置运行参数:不配置参数默认使用依赖jar下的xx-default.xml配置
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop01:9000");
// 创建MapReduce程序的任务Job
Job job = Job.getInstance(conf);
// 设置job驱动类:原因一个jar可以有多个主类或入口
job.setJarByClass(CorseDriver.class);
// 设置job的map和reduce过程处理类
job.setMapperClass(CorseMapper.class);
job.setReducerClass(CorseReduce.class);
// 设置自定义分组
job.setGroupingComparatorClass(CorseGroup.class);
// 设置map的输出key和value的类型
// 原因:类中的泛型声明只能在编译期间是否可以编译通过,编译完成后字节中类的泛型是不知道具体类类型的
// 所以需要手动指定泛型的输入key和value的类类型
job.setMapOutputKeyClass(AverageScore.class);
job.setMapOutputValueClass(AverageScore.class);
// 设置reduce的输出key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 设置reduce处理进程(yarnchild)数量:默认为1
//job.setNumReduceTasks(1);
// 文件读取类:设置作业的输入数据与输出路径
// 输入数据可以是文件,也可以是目录(表示处理目录下所有的数据)
FileInputFormat.setInputPaths(job, new Path("/corse"));
FileOutputFormat.setOutputPath(job, new Path("/corse_out1"));
// 提交计算作业
// 这种方式是没有日志打印的
//job.submit();
job.waitForCompletion(true);
}
注意这里增加了自定义分组设置,否则会按照AverageScore的compareTo返回0的对象进行分组
job.setGroupingComparatorClass(CorseGroup.class);
(5)运行
运行结果:

可以看到按照每门课程的平均分进行了排序,且只显示了最高分的名单(99一行记录没有名字,数据错误,忽略即可)
总结:
(1)如果没有自定义分组,默认情况下shuffle的分组依据是key的实现的WritableComparable接口的compareTo方法返回0的为一组,不返回0分到下一组
(2)如果有自定义分组,则使用自定义分组进行分组而不是compareTo返回0的进行分组
(3)如果自定义的key不是自定义key中的所有字段进行分组的,那么必须继承自定义分组WritableComparator类,实现compare(参数为WritableComparable类型)方法
7、全局计数器
在运行MR程序时候,我们可以在控制台中看到本次作业的运行的统计结果
File System Counters
FILE: Number of bytes read=2063324185
FILE: Number of bytes written=3944914269
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2649155499
HDFS: Number of bytes written=938170285
HDFS: Number of read operations=535
HDFS: Number of large read operations=0
HDFS: Number of write operations=130
Map-Reduce Framework
Map input records=1715473
Map output records=1714792
Map output bytes=183636431
Map output materialized bytes=187355187
Input split bytes=1070
Combine input records=0
Combine output records=0
Reduce input groups=714590
Reduce shuffle bytes=187355187
Reduce input records=1714792
Reduce output records=1714792
Spilled Records=3429584
Shuffled Maps =100
Failed Shuffles=0
Merged Map outputs=100
GC time elapsed (ms)=445
Total committed heap usage (bytes)=24647827456
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=170648744
File Output Format Counters
Bytes Written=170581244
这里面就用的是全局统计计数器,一般情况下,我们使用全局计数器的作用就是用来统计输入数据中不合法的数据记录等(当然根据应用使用),统计结果会追加在以上的输出中,当然为了统计输入数据的不合法性,我们可以将统计在map端进行统计,也可以在reduce端进行统计,一般情况我们放在map端进行统计即可。接下啦,我们就统计一下总的输入数据条数以及不合法数据条数。
(1)首先,为了使用全局计数器,我们必须按照mapreduce框架定义一个枚举类,添加自己要统计的属性。
/**
* @功 能: TODO(全局计数器枚举类)
* @作 者: [email protected]
* @日 期: 2019年12月20日
* @版 本: V1.0
*/
static enum DataError{
TOTAL_RECORD,
INVALID_RECORD
}
(2)其次,为了做全局输入数据的统计,我们只需要实现map过程即可,并且我们不需要输出数据,所以对于map的输出key和value都设置为NullWritable即可,实现如下:
static class CounterMapper extends Mapper<LongWritable, Text, NullWritable, NullWritable>{
/**
* key:每一个map读取block所在的行,一般没有用
* value: 每一行对应的数据
* context:执行全局上下文
*/
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 获取全局总条数计数器
Counter counter = context.getCounter(DataError.TOTAL_RECORD);
counter.setValue(counter.getValue() + 1);
try {
String[] splits = value.toString().split(";");
if(splits.length != 6){
throw new Exception("记录不合法!");
}
@SuppressWarnings("unused")
SurfRecord record = new SurfRecord(splits[1], splits[0], splits[2],
Integer.parseInt(splits[3].trim()),
Integer.parseInt(splits[4].trim()),
splits[5]);
} catch (Exception e) {
// 获取全局总条数计数器
Counter invalid = context.getCounter(DataError.INVALID_RECORD);
invalid.setValue(invalid.getValue() + 1);
}
}
}
计数器首先获取全局计数器,然后通过setvalue方法对计数器递增,如果数据不合法则递增不合法数据计数器条数。使用方式如下
// 获取全局总条数计数器
Counter invalid = context.getCounter(DataError.INVALID_RECORD);
invalid.setValue(invalid.getValue() + 1);
(3)驱动类入口实现
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 设置系统运行用户
System.setProperty("HADOOP_USER_NAME", "hadoop");
// 配置类
Configuration conf = new Configuration();
// 设置fs文件系统的访问地址(namenode)
conf.set("fs.defaultFS", "hdfs://hadoop01:9000");
// 自定义文本输出格式分隔符
conf.set("mapred.textoutputformat.separator", "");
// 创建MapReduce程序的任务Job
Job job = Job.getInstance(conf);
// 设置job驱动类:原因一个jar可以有多个主类或入口
job.setJarByClass(CounterDriver.class);
// 设置job的map和reduce过程处理类
job.setMapperClass(CounterMapper.class);
// 设置map的输出key和value的类型
// 原因:类中的泛型声明只能在编译期间是否可以编译通过,编译完成后字节中类的泛型是不知道具体类类型的
// 所以需要手动指定泛型的输入key和value的类类型
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(NullWritable.class);
// 设置reduce的输出key和value的类型
//job.setOutputKeyClass(NullWritable.class);
//job.setOutputValueClass(NullWritable.class);
// 设置reduce处理进程(yarnchild)数量
job.setNumReduceTasks(0);
// 文件读取类:设置作业的输入数据与输出路径
// 输入数据可以是文件,也可以是目录(表示处理目录下所有的数据)
FileInputFormat.setInputPaths(job, new Path("/surf_out"));
FileOutputFormat.setOutputPath(job, new Path("/surf_out3"));
// 提交计算作业
// 这种方式是没有日志打印的
//job.submit();
job.waitForCompletion(true);
}
注意
因为我们不需要reduce处理,所以设置reduce数量为0,所以运行后的输出结果应该只有map的输出文件(part-m-xxxxx)
(4)输出运行结果
File System Counters
FILE: Number of bytes read=56425
FILE: Number of bytes written=3007820
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=942668059
HDFS: Number of bytes written=0
HDFS: Number of read operations=250
HDFS: Number of large read operations=0
HDFS: Number of write operations=120
Map-Reduce Framework
Map input records=1715473
Map output records=0
Input split bytes=1070
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=91
Total committed heap usage (bytes)=4258267136
这是自定义全局计数器输出
com.easystudy.CounterDriver$DataError
INVALID_RECORD=867
TOTAL_RECORD=1715473
File Input Format Counters
Bytes Read=170648744
File Output Format Counters
Bytes Written=0
可以看到我们自定义的枚举类“DataError”的INVALID_RECORD和TOTAL_RECORD两个全局计数器,两个全局计数器说明总记录为1715473条记录,其中有867条记录是不合法的(中间我们没有处理中文字符转换异常也包含其中,不管,我们仅仅是做demon而已,正好能说明我们的计数器作用)。
因为输入10个文件,所有有10个map的结果文件,又因为map输出都为NullWritable,所以没有输出内容,字节数量为0
注意:因为不需要reduce过程,所以设置reduce数量为0
// 设置reduce处理进程(yarnchild)数量
job.setNumReduceTasks(0);
8、join过程
很多时候,面对复杂的需求,我们不能活很难通过一次计算就可以将结果计算出来,这时候我们可以将复杂问题简化为多个小问题,然后逐个解决。但是问题来了,我们是否需要些多个MapReduce程序然后手动跑多次呢?也就是说我们将分解的多个MapReduce通过一次就可以跑完?这里就是将要讲的MapReduce的join过程(hive的join就是通过MR的join实现的),它通过将多个job通过JobControl连接在一块,我们只需要设置job与job的依赖关系就可以了。
(1)准备数据
如下为好友列表
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
上面的数据中,冒号前是一个用户,冒号后是该用户的所有好友,如A的好友有B,C,D,F,E,O,注意,好友是单向关系。
上传数据
hadoop fs -mkdir -p /cf
hadoop fs -put friends.txt /cf
hadoop fs -ls /
(2)需求
求出哪些人两两之间有共同好友,及他俩的共同好友都有谁?
(3)分析
首先,根据需求,我们要找到两个人的好友,必须满足如下条件,如
B:A
C:A
即,B的好友为A,C的好友为A,那么B和C之间就有好友A,所以我们分两个步骤进行
i、将每一行的数据,以好友为key,用户为value进行计算输出
如A:B,C,D,F,E,O可以切分成B:A,C:A,D:A,F:A,E:A,O:A,然后以第一个好友账号(即第二列)分组,
reduce拿到的数据如:
最后可以总结为:A-B有C,A-E有C,A-F有C,A-G有C,B-E有C,B-F有C,B-G有C,E-F有C,E-G有C,F-G有C
输出格式可以为:…
通过以上步骤我们就可以找到,每两个人之间的一个好友
ii、通过第一个步骤,我们知道的没两个人有一个好友,那么下一步就以上一步骤输出结果为输入数据,只要将将两个人的一个好友,通过分组然后组合起来就可以了。也就是说
map:输入,
reduce: 将分组统筹结果为:
(4)第一步骤的map过程实现
/**
* @功 能: TODO(求共同好友第一步骤:以好友为key,用户为value输出)
* @作 者: [email protected]
* @日 期: 2019年12月21日
* @版 本: V1.0
*/
static class CommonFriendMapper_step01 extends Mapper<LongWritable, Text, Text, Text>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// A:B,C,D,F,E,O
String splite[] = value.toString().split(":");
String friends[] = splite[1].split(",");
for (int i = 0; i < friends.length; i++) {
//
context.write(new Text(friends[i].trim()), new Text(splite[0].trim()));
}
}
}
第一步map的作用就是讲好友作为key,将用户自己作为value(标记用户为其他好友的好友)
(5)第一步的reducer过程
/**
* 将分组后的数据
* @功 能: TODO(用一句话描述该文件做什么)
* @作 者: [email protected]
* @日 期: 2019年12月21日
* @版 本: V1.0
*/
static class CommonFriendReducer_step01 extends Reducer<Text, Text, Text, NullWritable>{
private StringBuffer sb = new StringBuffer();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// ,, 第一步的reducer实现的就是将第一个的key分组后的所有好友都相互标记有共同好友key,如
A:B
A:C
A:D
那么B-C与B-D和C-D都有共同好友A,输出为:B-C A B-D A C-D A
(6)第二步的map过程实现
/**
* @功 能: TODO(将第一步输出数据合并)
* @作 者: [email protected]
* @日 期: 2019年12月21日
* @版 本: V1.0
*/
static class CommonFriendMapper_step02 extends Mapper<LongWritable, Text, Text, Text>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 将第一步输出结果按照某某x和某某y的好友进行输出,启动key为某某x和某某y的组合,value为他们的好友,采用默认分则策略,也就是说某某x-某某y称为分组的依据,属于相同的x-y的记录数据会默认被分成一组,如这些数据x-y对应key相等,所以被分到同一组。
(7)第二步的reduce过程实现
/**
* @功 能: TODO(对第二步map输入数据进行合并输出)
* @作 者: [email protected]
* @日 期: 2019年12月21日
* @版 本: V1.0
*/
static class CommonFriendReducer_step02 extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
// 输入:
String commonFriends = "";
for (Text text : values) {
commonFriends += text.toString();
commonFriends += ",";
}
// 移除最后一个逗号
if(commonFriends.endsWith(",")){
commonFriends = commonFriends.substring(0, commonFriends.length() - 1);
}
// 输出: A-B C,F,E
context.write(key, new Text(commonFriends));
}
}
将第二步map输出结果按照某某x和某某y的好友进行合并,即X-Y A和X-Y B合并变为:X-Y A,B也就是说X和Y的共同好友有A和B…
(8)将两个MapReduce程序进行join关联
public static void main(String[] args) throws IOException, InterruptedException {
// 设置jvm的hadoop运行用户
System.setProperty("HADOOP_USER_NAME", "hadoop");
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop01:9000");
Job job1 = Job.getInstance(conf);
job1.setJarByClass(CommonFriendDriver.class);
job1.setMapperClass(CommonFriendMapper_step01.class);
job1.setReducerClass(CommonFriendReducer_step01.class);
job1.setMapOutputKeyClass(Text.class);
job1.setMapOutputValueClass(Text.class);
job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(NullWritable.class);
job1.setNumReduceTasks(1);
FileInputFormat.setInputPaths(job1, new Path("/cf"));
FileOutputFormat.setOutputPath(job1, new Path("/cf_out1"));
//job1.waitForCompletion(true);
Job job2 = Job.getInstance(conf);
job2.setJarByClass(CommonFriendDriver.class);
job2.setMapperClass(CommonFriendMapper_step02.class);
job2.setReducerClass(CommonFriendReducer_step02.class);
job2.setMapOutputKeyClass(Text.class);
job2.setMapOutputValueClass(Text.class);
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(Text.class);
job2.setNumReduceTasks(1);
FileInputFormat.setInputPaths(job2, new Path("/cf_out1"));
FileOutputFormat.setOutputPath(job2, new Path("/cf_out2"));
//job2.waitForCompletion(true);
JobControl jobControl = new JobControl("my_mr_join");
// 将job1转为可控制的job
ControlledJob cjob1 = new ControlledJob(job1.getConfiguration());
cjob1.setJob(job1);
// 将job2转为可控制的job
ControlledJob cjob2 = new ControlledJob(job2.getConfiguration());
cjob2.setJob(job2);
// job2依赖job1
cjob2.addDependingJob(cjob1);
// 将可控制job添加到job控制器
jobControl.addJob(cjob1);
jobControl.addJob(cjob2);
// JobControl实现了Runnable,启动使用线程
Thread thread = new Thread(jobControl);
thread.start();
// 等待所有job执行完成
while (!jobControl.allFinished()) {
thread.sleep(500);
}
// 停止线程
thread.stop();
}
可以看到,第二个job依赖第一个job,所以我们可以一个一个提交job,先提交job1,然后提交job2,但是还有一种方法就是讲两个job交由JobControl组件进行控制,然后使用线程监听运行该job控制器,job提交给JobControl的前提是将Job转为可控制的job(ControlledJob),然后设定两个可控job的依赖关系,最后启动线程等待所有job执行完成,核心代码如下:
JobControl jobControl = new JobControl("my_mr_join");
// 将job1转为可控制的job
ControlledJob cjob1 = new ControlledJob(job1.getConfiguration());
cjob1.setJob(job1);
// 将job2转为可控制的job
ControlledJob cjob2 = new ControlledJob(job2.getConfiguration());
cjob2.setJob(job2);
// job2依赖job1
cjob2.addDependingJob(cjob1);
// 将可控制job添加到job控制器
jobControl.addJob(cjob1);
jobControl.addJob(cjob2);
// JobControl实现了Runnable,启动使用线程
Thread thread = new Thread(jobControl);
thread.start();
// 等待所有job执行完成
while (!jobControl.allFinished()) {
thread.sleep(500);
}
// 停止线程
thread.stop();
(9)执行结果
第一个mr执行输出结果:
B-F A
C-F A
D-F A
A-F B
A-E B
B-E C
E-F C
A-E C
C-F D
E-F D
A-F D
D-F E
B-F E
A-F E
A-C F
C-D F
D-E L
E-F M
A-F O

第二个mr执行结果:
A-C F
A-E B,C
A-F D,O,E,B
B-E C
B-F A,E
C-D F
C-F D,A
D-E L
D-F E,A
E-F C,M,D
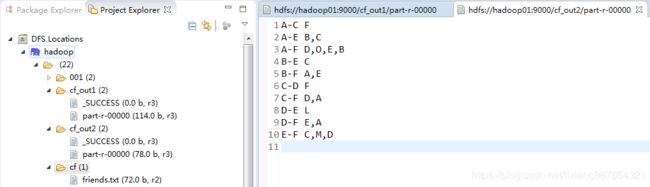
可以看到:A和C只有一个共同好友,A和E有两个共同好友B、C,比较原始数据可以发现是正确的。
总结:
(1)一个复杂的需求,我们可以通过化整为零,逐个击破,雷同HDFS的分而治之思想。
(2)多个job之间通过job控制器来进行join,各个job需要设置之间的依赖关系
(3)涉及到排序的,我们尽量使用map的shuffle过程进行排序,因为其并行度比reduce端高,且不会造成reduce端的数据倾斜
(4)当既有分组又有排序字段的时候,因为shuffle过程排序在前分组在后,排序字段已经要包含分组字段并且必须把分组字段在前排序,其他字段在后排序
(5)实际上的分组仅仅是将map输出的结果相邻的进行比较(因为排序在前分组在后)为0则分为一组,不为0则重新划分一组。如果要分组一定要保证分组字段数据在响铃的位置,即保证相同的分组数据相邻!(同4说明)
(6)两个坑:reduce中的迭代器只能循环遍历一次;所以的迭代器中所有对象共用同一个地址;
(7)map或reduce的中间过程因为执行次数较多,所以需要开辟内存的最好在成员变量中声明,避免每次都开辟新的空间,GC不能及时清理导致内存暴增
三、MR高级开发
1、前言分析
前面所有介绍都是操作一个表数据的,也就是说对于map输入端的数据结构都是相同的,不能处理不同表的情况,但很多时候,我们需要处理多表联查的情况,也就是说SQL的join操作(注意着不同于两个MR程序的join操作,而是同一个MR中处理多个表的输入数据),为了能处理多个表数据,我们可能需要满足如下条件:
(1)将不同表(数据结构不同)放在同一个MR的输入目录下或者通过FileInputFormat增加不同输入路径的文件作为MR的输入数据源
(2)MR必须要能识别输入数据是来自哪个文件中的一行数据以便根据不同的输入数据源格式处理不同的数据
(3)数据的join(关联查询)可以分为Map端的join过程和reduce端的join过程,如果join过程放在reduce端,那么reduce的输入key必须是两个表的连接字段作为key,以便相同的key单数据来源不同的数据能否进入reduce
(4)如果是reduce端的join,相同key输出到不同表的数值字段被分成一组输出到reduce,reduce为了能区分Iterable
values中来自哪个表,在map端必须打上标记来自哪个表(尽可能简单短以便不影响中间输出和带宽)
2、Map过程中获取输入数据来源
前面的章节中,我们只讲了mapper接口的map方法,它的调用频次是一行调用一次,那么为什么如此呢?首先我们来看看Mapper类的实现
/**
* The Context passed on to the {@link Mapper} implementations.
*/
public abstract class Context
implements MapContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
}
/**
* Called once at the beginning of the task.
*/
protected void setup(Context context
) throws IOException, InterruptedException {
// NOTHING
}
/**
* Called once for each key/value pair in the input split. Most applications
* should override this, but the default is the identity function.
*/
@SuppressWarnings("unchecked")
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
/**
* Called once at the end of the task.
*/
protected void cleanup(Context context
) throws IOException, InterruptedException {
// NOTHING
}
/**
* Expert users can override this method for more complete control over the
* execution of the Mapper.
* @param context
* @throws IOException
*/
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
}
代码最核心的就是run方法,我们所有的map的run方法其实就是一个循环,在每一个map创建后调用run方法进入循环前都会调用一次setup方法,然后进入循环一直读取一行数据就处理一条数据(map方法),最后当数据处理完成后退出循环后调用cleanup方法!也就是我们知道:
setup:每一个map创建后开始循环执行前都会调用一次且调用一次,一般用于资源的初始化如数据量连接等,提高程序处理效率,降低频次,防止多次调用导致性能问题
map:每读取一行记录就会调用一次进行输入清理 cleanup:
map退出时候调用一次清理,一般与setup对应,用于对setup中创建的资源进行清理释放
3、获取数据源名称
根据2的接口分析,我们知道,如果输入数据源有多个,那么我们必须在map创建的时候(也就是setup方法中)获取对应的文件(也就是表名),然后在map中根据不同的表进行处理,最后输出到reduce的时候进行打标签即可(这种情况是reduce端join情况)
static class MyMapper extends Mapper<LongWritable, Text, Text, Text>{
// 文件名-也就是表名
private String tableName;
@Override
protected void setup(Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// 注意引入2.x新包的InputSplit,而不是mpred下的旧包(1.x)
InputSplit input = context.getInputSplit();
// 切片信息是一个抽象类无具体方法,有DB或File等实现,当前输入的hdfs文件所以为FileSplit
FileSplit fileSplit = (FileSplit)input;
// 获取文件切片的文件路径
tableName = fileSplit.getPath().getName().toString();
}
}
注意:
我们使用的文件输入,所以切片为文件切片类,我们通过切片类就可以获取切片关联的相关属性,这里我们需要的是切片路径
以下,我们以常见的商品表以及订单表来说明我们的问题
(1)商品表product
商品编号 商品名称 商品分类 商品价格
P001 iphone6 C01 5500
P002 mi5 C01 2000
P003 honor C01 1000
(2)订单表order
订单编号 订单日期 产品编号 库存容量
1001 20191210 P001 99
1002 20191211 P002 100
1003 20191221 P003 500
1004 20191220 P002 101
1005 20191220 P003 501
上传数据
hadoop fs -mkdir /rj
hadoop fs -put order /rj
hadoop fs -put product /rj


接下来,我们需要实现如下的连接查询需求(join)
select * from order join product on left join order.PID = product.PID
4、Reduce端口join实现
正如我们分析,如果要在reduce端做join的话,那么必须满足:
(1)reduce的输入数据(也就是map的输出)分组后包括了来自不同表的数据,也就是分组依据必须是关联的join字段(这里为PID)。
(2)我们要显示所有数据,reduce端口除了PID之外的其他字段到reduce时候必须带上标记,标明来源是哪个表
(3)以1-n的n为依据将少的一方连接到多个一方,然后将连接结果输出
那么我们实现如下
(1)map端的数据输入打标签
static class MyMapper extends Mapper<LongWritable, Text, Text, Text>{
// 文件名-也就是表名
private String tableName;
// key-value
private Text k = new Text();
private Text v = new Text();
@Override
protected void setup(Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// 注意引入2.x新包的InputSplit,而不是mpred下的旧包(1.x)
InputSplit input = context.getInputSplit();
// 切片信息是一个抽象类无具体方法,有DB或File等实现,当前输入的hdfs文件所以为FileSplit
FileSplit fileSplit = (FileSplit)input;
// 获取文件切片的文件路径
tableName = fileSplit.getPath().getName().toString();
}
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// 商品数据
if(tableName.equals("product")){
// P001 iphone6 C01 5500
String[] splites = value.toString().split("\t");
k.set(splites[0]);
// 值添加所属表标志-商品P
v.set("P" + splites[1] + "," + splites[2] + "," + splites[3]);
// 输出key-value到reduce-相同key分组,key为两个表的关联字段
context.write(k, v);
// 订单数据
} else if (tableName.equals("order")) {
// 1001 20191210 P001 99
String[] splites = value.toString().split("\t");
k.set(splites[2]);
// 值添加所属表来源标志-订单O
v.set("O" + splites[0] + "," + splites[1] + "," + splites[3]);
// 输出key-value到reduce-相同key分组,key为两个表的关联字段
context.write(k, v);
}
}
}
我们看到,我们的map过程输入要处理两种不同的数据且输出的字段key为关联字段(以便到reduce端是以key作为分组以及,该key下的一组数据才能包括多个表的数据),value打上来数据来演,订单打上了“O”,商品打上了“P”,而且标签简短短小且不冲突,目的就是为了减少存储数据网络传输量。
(2)Reduce端join
到reduce端口的数据就是按照关联字段分组的数据了,这些数据可能是order的数据,也可能是product的数据,那么我们要分离出来,然后在见两个分离出来的数据进行join连接,最后输出join之后的数据。实现流程代码如下所示:
static class MyReducer extends Reducer<Text, Text, Text, NullWritable>{
// 临时列表-防止频繁申请与释放内存
private List<String> listProduct = new ArrayList<String>();
private List<String> listOrder = new ArrayList<String>();
private Text joinText = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
// 输入数据(以关联字段作为key分组,包含两个表的数据):
// 商品:P001 iphone6,C01,5500 移除P标签
// 订单:P001 1001,20191210,99 移除O标签
listProduct.clear();
listOrder.clear();
for (Text text : values) {
if (text.toString().startsWith("P")) {
listProduct.add(text.toString().substring(1));
} else {
listOrder.add(text.toString().substring(1));
}
}
// 1对n,以n为依据连接
for (String order : listOrder) {
for (String product : listProduct) {
// P001 1001,20191210,99,iphone6,C01,5500
String line = key.toString() + "," + order + "," + product;
joinText.set(line);
context.write(joinText, NullWritable.get());
}
}
}
}
(3)主入口实现
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 设置JVM环境变量,设置运行hadoop运行用户
System.setProperty("HADOOP_USER_NAME", "hadoop");
// 配置运行参数:不配置参数默认使用依赖jar下的xx-default.xml配置
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop01:9000");
// 创建MapReduce程序的任务Job
Job job = Job.getInstance(conf);
// 设置job驱动类:原因一个jar可以有多个主类或入口
job.setJarByClass(ReduceJoinDriver.class);
// 设置job的map和reduce过程处理类
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
// 设置map的输出key和value的类型
// 原因:类中的泛型声明只能在编译期间是否可以编译通过,编译完成后字节中类的泛型是不知道具体类类型的
// 所以需要手动指定泛型的输入key和value的类类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 设置reduce的输出key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 设置reduce处理进程(yarnchild)数量:默认为1
//job.setNumReduceTasks(1);
// 文件读取类:设置作业的输入数据与输出路径
// 输入数据可以是文件,也可以是目录(表示处理目录下所有的数据)
FileInputFormat.setInputPaths(job, new Path("/rj"));
FileOutputFormat.setOutputPath(job, new Path("/rj_out"));
// 提交计算作业
// 这种方式是没有日志打印的
//job.submit();
job.waitForCompletion(true);
}
(4)运行结果
P001,1001,20191210,99,iphone6,C01,5500
P002,1004,20191220,101,mi5,C01,2000
P002,1002,20191211,100,mi5,C01,2000
P003,1005,20191220,501,honor,C01,1000
P003,1003,20191221,500,honor,C01,1000

未完待续…
快来成为我的朋友或合作伙伴,一起交流,一起进步!:
QQ群:961179337
微信:lixiang6153
邮箱:[email protected]
公众号:IT技术快餐