Apache Kafka 核心组件和流程-控制器-设计-原理(入门教程轻松学)
本入门教程,涵盖Kafka核心内容,通过实例和大量图表,帮助学习者理解,任何问题欢迎留言。
目录:
- kafka简介
- kafka安装和使用
- kafka核心概念
- kafka核心组件和流程--控制器
- kafka核心组件和流程--协调器
- kafka核心组件和流程--日志管理器
- kafka核心组件和流程--副本管理器
- kafka编程实战
通过前几章的学习,我们已经从宏观层面了解了kafka的设计理念。包括kafka集群的组成、消息的主题、主题的分区、分区的副本等内容。接下来我们会继续深入,了解kafka的主要组件以及核心的流程,最后还会介绍kafka的消息是如何存储的。此章非常重要,通过本章和上一章的学习,你已经能够掌握kafka 80%的核心内容。当然随着学习的深入,难度也会越来越大,有任何问题欢迎留言或者私信。
Kafka主要的组件如下:
控制器
协调器
日志管理器
副本管理器
我们将会逐个进行讲解,讲解过长还将保持前面章节的特点,多用有形的图表帮助读者理解。
本篇博客先讲解控制器部分。其它组件再逐步发出
1、控制器
在前一章的学习中,我们已经知道Kafka的集群由n个的broker所组成,每个broker就是一个kafka的实例或者称之为kafka的服务。其实控制器也是一个broker,控制器也叫leader broker。
他除了具有一般broker的功能外,还负责分区leader的选取,也就是负责选举partition的leader replica。
控制器是kafka核心中的核心,需要重点学习和理解。
控制器选举
kafka每个broker启动的时候,都会实例化一个KafkaController,并将broker的id注册到zookeeper,这在第二章中已经通过例子做过讲解。集群在启动过程中,通过选举机制选举出其中一个broker作为leader,也就是前面所说的控制器。
包括集群启动在内,有三种情况触发控制器选举:
1、集群启动
2、控制器所在代理发生故障
3、zookeeper心跳感知,控制器与自己的session过期
按照惯例,先看图。我们根据下图来讲解集群启动时,控制器选举过程。
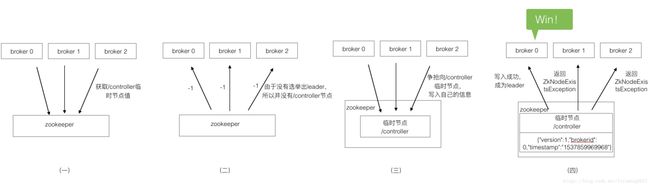
假设此集群有三个broker,同时启动。
(一)3个broker从zookeeper获取/controller临时节点信息。/controller存储的是选举出来的leader信息。此举是为了确认是否已经存在leader。
(二)如果还没有选举出leader,那么此节点是不存在的,返回-1。如果返回的不是-1,而是leader的json数据,那么说明已经有leader存在,选举结束。
(三)三个broker发现返回-1,了解到目前没有leader,于是均会触发向临时节点/controller写入自己的信息。最先写入的就会成为leader。
(四)假设broker 0的速度最快,他先写入了/controller节点,那么他就成为了leader。而broker1、broker2很不幸,因为晚了一步,他们在写/controller的过程中会抛出ZkNodeExistsException,也就是zk告诉他们,此节点已经存在了。
经过以上四步,broker 0成功写入/controller节点,其它broker写入失败了,所以broker 0成功当选leader。
此外zk中还有controller_epoch节点,存储了leader的变更次数,初始值为0,以后leader每变一次,该值+1。所有向控制器发起的请求,都会携带此值。如果控制器和自己内存中比较,请求值小,说明kafka集群已经发生了新的选举,此请求过期,此请求无效。如果请求值大于控制器内存的值,说明已经有新的控制器当选了,自己已经退位,请求无效。kafka通过controller_epoch保证集群控制器的唯一性及操作的一致性。
由此可见,Kafka控制器选举就是看谁先争抢到/controller节点写入自身信息。
控制器初始化
控制器的初始化,其实是初始化控制器所用到的组件及监听器,准备元数据。
前面提到过每个broker都会实例化并启动一个KafkaController。KafkaController和他的组件关系,以及各个组件的介绍如下图:
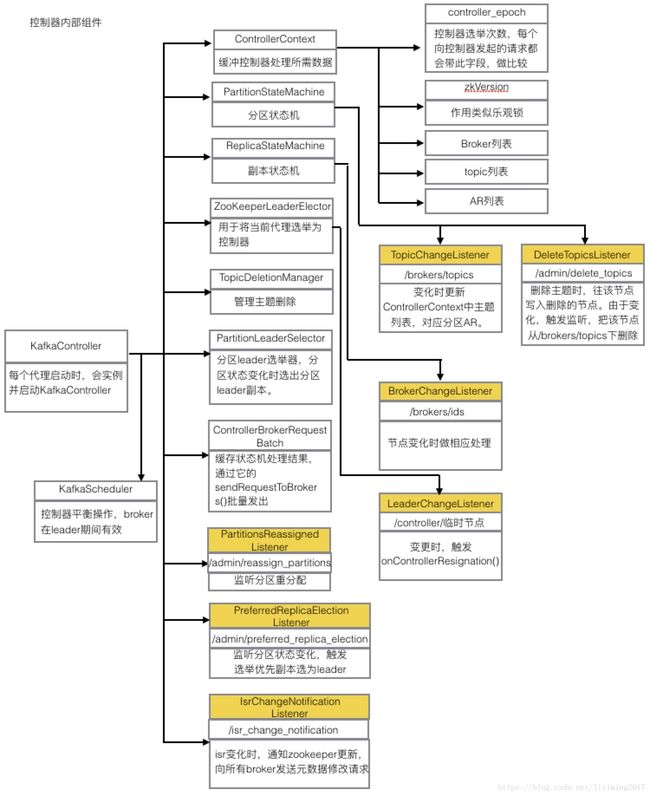
图中箭头为组件层级关系,组件下面还会再初始化其他组件。可见控制器内部还是有些复杂的,主要有以下组件:
1、ControllerContext,此对象存储了控制器工作需要的所有上下文信息,包括存活的代理、所有主题及分区分配方案、每个分区的AR、leader、ISR等信息。
2、一系列的listener,通过对zookeeper的监听,触发相应的操作,黄色的框的均为listener
3、分区和副本状态机,管理分区和副本。
4、当前代理选举器ZookeeperLeaderElector,此选举器有上位和退位的相关回调方法。
5、分区leader选举器,PartitionLeaderSelector
6、主题删除管理器,TopicDeletetionManager
7、leader向broker批量通信的ControllerBrokerRequestBatch。缓存状态机处理后产生的request,然后统一发送出去。
8、控制器平衡操作的KafkaScheduler,仅在broker作为leader时有效。
图片是我根据资料所总结,个人认为对于理解kafkaController的全貌很有帮助。本章节后面讲到相应组件和流程时,还需要反复回来理解此图,思考组件所处的位置,对整体的作用。
故障转移
故障转移其实就是leader所在broker发生故障,leader转移为其他的broker。转移的过程就是重新选举leader的过程。
重新选举leader后,需要为该broker注册相应权限,调用的是ZookeeperLeaderElector的onControllerFailover()方法。在这个方法中初始化和启动了一系列的组件来完成leader的各种操作。具体如下,其实和控制器初始化有很大的相似度。
1、注册分区管理的相关监听器
| 监听名称 | 监听zookeeper节点 | 作用 |
| PartitionsReassignedListener | /admin/reassign_partitions | 节点变化将会引发分区重分配 |
| IsrChangeNotificationListener | /isr_change_notification | 处理分区的ISR发生变化引发的操作 |
| PreferredReplicaElectionListener | /admin/preferred_replica_election | 将优先副本选举为leader副本 |
2、注册主题管理的相关监听
| 监听名称 | 监听zookeeper节点 | 作用 |
| TopicChangeListener | /brokers/topics | 监听主题发生变化时进行相应操作 |
| DeleteTopicsListener | /admin/delete_topics | 完成服务器端删除主题的相应操作。否则客户端删除主题仅仅是表示删除 |
3、注册代理变化监听器
| 监听名称 | 监听zookeeper节点 | 作用 |
| BrokerChangeListener | /brokers/ids | 代理发生增减的时候进行相应的处理 |
4、重新初始化ControllerContext,
5、启动控制器和其他代理之间通信的ControllerChannelManager
6、创建用于删除主题的TopicDeletionManager对象,并启动。
7、启动分区状态机和副本状态机
8、轮询每个主题,添加监听分区变化的PartitionModificationsListener
9、如果设置了分区平衡定时操作,那么创建分区平衡的定时任务,默认300秒检查并执行。
除了这些组件的启动外,onControllerFailover方法中还做了如下操作:
1、/controller_epoch值+1,并且更新到ControllerContext
2、检查是否出发分区重分配,并做相关操作
3、检查需要将优先副本选为leader,并做相关操作
4、向kafka集群所有代理发送更新元数据的请求。
下面来看leader权限被取消时,调用的方法onControllerResignation
1、该方法中注销了控制器的权限。取消在zookeeper中对于分区、副本感知的相应监听器的监听。
2、关闭启动的各个组件
3、最后把ControllerContext中记录控制器版本的数值清零,并设置当前broker为RunnignAsBroker,变为普通的broker。
通过对控制器启动过程的学习,我们应该已经对kafka工作的原理有了了解,核心是监听zookeeper的相关节点,节点变化时触发相应的操作。其它的处理流程都是相类似的。本篇教程接下来做简要介绍,想要了解详情的,可以先找其它资料。我后续也会再补充更为详细的教程。
代理上下线
有新的broker加入集群时,称为代理上线。反之,当broker关闭,推出集群时,称为代理下线。
代理上线:
1、新代理启动时向/brokers/ids写数据
2、BrokerChangeListener监听到变化。对新上线节点调用controllerChannelManager.addBroker(),完成新上线代理网络层初始化
3、调用KafkaController.onBrokerStartup()处理
3.1通过向所有代理发送UpdateMetadataRequest,告诉所有代理有新代理加入
3.2根据分配给新上线节点的副本集合,对副本状态做变迁。对分区也进行处理。
3.3触发一次leader选举,确认新加入的是否为分区leader
3.4轮询分配给新broker的副本,调用KafkaController.onPartitionReassignment(),执行分区副本分配
3.5恢复因新代理上线暂停的删除主题操作线程
代理下线:
1、查找下线节点集合
2、轮询下线节点,调用controllerChannelManager.removeBroker(),关闭每个下线节点网络连接。清空下线节点消息队列,关闭下线节点request请求
3、轮询下线节点,调用KafkaController.onBrokerFailure处理
3.1处理leader副本在下线节点上上的分区,重新选出leader副本,发送updateMetadataRequest请求。
3.2处理下线节点上的副本集合,做下线处理,从ISR集合中删除,不再同步,发送updateMetadataRequest请求。
4、向集群全部存活代理发送updateMetadataRequest请求
主题管理
通过分区状态机及副本状态机来进行主题管理
1、创建主题
/brokers/topics下创建主题对应子节点
TopicChangeListener监听此节点
变化时获取重入锁ReentrantLock,调用handleChildChange方法进行处理。
通过对比zookeeper中/brokers/topics存储的主题集合及控制器的ControllerContext中缓存的主题集合的差集,得到新增的主题。反过来求差集,得到删除的主题。
接下来遍历新增的主题集合,进行主题操作的实质性操作。之前仅仅是在zookeeper中添加了主题。新增主题涉及的操作有分区、副本状态的转化、分区leader的分配、分区存储日志的创建等。
2、删除主题
/admin/delete_topics创建删除主题的子节点
DeleteTopicsListener监听此节点,
变化时获取重入锁ReentrantLock,进行处理
具体的删除逻辑再次就不再详述。
分区管理
1、分区自动平衡
onControllerFailover方法中启动分区自动平衡任务。定时检查是否失去平衡。
自动平衡的操作就是把优先副本选为分区leader,AR中第一个副本为优先副本。
先查出所有可用副本,以分区AR头节点分组。
轮询代理节点,判断分区不平衡率是否超过10%(leader为非优先副本的分区/该代理分区总数),则调用onPreferredReplicaElection(),让优先副本成为leader。达到自动平衡。
分区平衡操作的流程已经在第三章做了很详细的讲解,此处不再重复,可以参考kafka核心概念。
2、分区重分配
当zk节点/admin/reassign_partitions变化时,触发分区重分配操作。该节点存储分区重分配的方案。
通过计算主题分区原AR(OAR)和重新分配后的AR(RAR),分别做相应处理:
1、OAR+RAR:更新到该主题分区AR,并通知副本节点同步。leader_epoch+1
2、RAR-OAR:副本设为NewReplica。
3、(OAR+RAR)- RAR:需要下线的副本,做下线操作
具体流程不再详述
小结:关于控制器的相关知识点就先讲到这里,控制器初始化中的那张图需要充分去理解,理解了此图,对控制器内部的构造,以及控制器要做什么事情、如何做的,就已经掌握了。另外考虑本教程定位为入门轻松学,所以具体的流程没有展开来讲,以后我会再写相应的主题文章来说明。
下一步:开始《kafka核心组件和流程--协调器》的学习