机器学习整理笔记——k-近邻算法
前言:以下是本人通过《Machine Learning in Action》学习机器学习时总结的学习笔记,本文的目的是提炼出简洁易懂的精华,让在学习机器学习的Guys能轻松就融会贯通。希望对读者有用!
环境:Linux-Ubuntu
语言:Python
旁白:在学习的过程中还能熟悉Linux下的Python编程。
k-近邻算法
简单的说,k-近邻(kNN,k-Nearest Neighbor)算法是一种分类算法,采用测量不同特征值之间的距离方法进行分类。看字面就知道实际上它采用的是选取k个样本,计算输入样本与已知样本距离最近的k个,k个里面数量最多的类别就是输入样本的类别。
说完原理来看看书上的例子:

这是一个关于电影分类的例子,我们将实用kNN算法来对表2-1中的最后一部未知电影(?)进行分类——爱情片或者动作片。如表,不管时动作片还是爱情片(还是爱情动作片)都存在打斗镜头和接吻镜头,我们不能单纯依靠是否存在打斗镜头或者接吻镜头来判断电影“?”属于哪种电影类型。但在爱情片中接吻镜头次数偏多,动作片中打斗镜头次数也更频繁,我们可以基于此场景在某部电影中出现的次数来进行电影分类。本节就基于打斗镜头次数和接吻镜头出现的次数来构造kNN算法,自动化分电影类型。
k近邻算法的一般流程:
(1)收集数据:What ever you want!
(2)准备数据:计算机能处理的数据,最好时结构化数据
(3)分析数据:What ever you want!
(4)实用算法:首先输入样本数据;然后运行kNN算法判定输入样本类型
(5)测试算法:计算错误率
(1)使用python导入数据:
首先在Linux终端命令行下创建名为kNN.py的python模块(我用的是vim编译器,所以我输入 vim kNN.py),本章所使用的代码都放在这个模块下。在kNN.py文件中编辑下面代码(#后面的是注释):
程序清单1:
1 # import module of Numpy. the '*' indicate all the modules
2 from numpy import *
3
4 # import module of Operator
5 import operator
6
7 # define function 'CreateDataSet()'
8 def CreateDataSet():
9 # array() indicate the content of bracket is array, which equal to a matrix.
10 sample = array([ [3, 104], [2, 100], [1, 81], [101, 10], [99, 5], [98, 2], [18, 90] ])
11 # variable name 'labels' is a array too
12 labels = ['L', 'L', 'L', 'A', 'A', 'A']
13 return sample, labels
接着在该文件所在的目录下输入python进入Python Shell, 然后导入上面编辑的程序模块
>>>import kNN
然后输入>>>sample, labels = kNN.CreateDataSet()。该命令创建了sample和labels变量,在Python命令提示符下,输入变量变量名字可以检验是否正确的定义变量:
>>> sample>>> labels

这里的sample有6组数据,每组数据有两个我们已知的特征值(打斗镜头次数及接吻镜头次数),而labels变量包含了每组数据的标签信息(属于哪种类型的电影)
(2)实施kNN算法:
本节使用程序清单2的函数进行kNN算法,为输入样本分类。伪代码(实际就是算法流程):
(1)计算已知类别数据集的每个点到当前点之间的距离;
(2)按照距离递增次序排序;
(3)选取与当前点距离最小的k个点;
(4)确定前k个点所在类别的出现频率;
(5)返回前k个点出现频率最高的类别作为当前点的预测分类。
程序清单2:k-近邻算法
# The arguments: "data, samples, labels, k" denote respectively: "the data you want to classify", "the samples what you have",
15 # " the labels of samples", "the numbers k in algorithm of kNN"
16 def Classify( data, samples, labels, k ):
17 # .shape[0]: get the count of row of matrix
18 samplesSize = samples.shape[0]
19 diffMat = tile( data, (samplesSetSize, 1) ) - samples
20 sqDiffMat = diffMat**2
21 # .sum(axis=1): sum of every row of matrix
22 sqDistance = sqDiffMat.sum(axis=1)
23 distance = sqDistance**0.5
24 sortedDistIndicies = distance.argsort()
25 # classCount is a dictionary of Python struct, such as: classCount['A'] = 0; classCount['B'] = 2;
26 classCount={}
27 for i in range(k):
28 voteIlabel = labels[sortedDistIndicies[i]]
29 # list.get(k, d) is similar to a 'if' statement. If list[k] is in the list{} then return list[k], else return d.
30 classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
31 sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
32 return sortedClassCount[0][0]
函数Classify( data, samples, labels, k )有四个参数:用于分类的输入向量是data,已知样本集是samples,标签向量是labels,最后的k表示用于选择最近邻的数目。程序清单2使用欧式距离公式,计算两个向量点(x,y)的距离(书上总爱说一些学术性的语言,实际上就是我们初中学过的计算两坐标点之间的距离公式啦
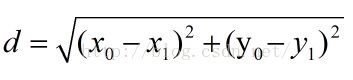
所以根据我们的数据,电影“?”跟其他电影计算出来的欧式距离就是:
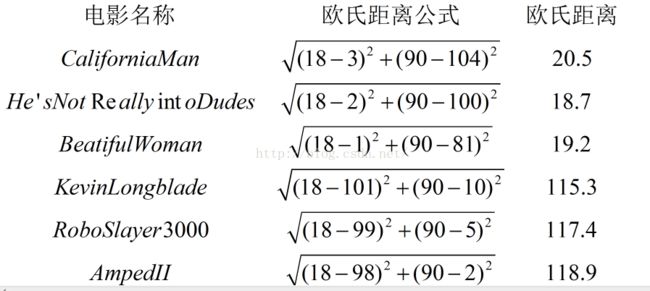
计算完所有样本距离后,我们对距离按照从小到大的次序排序(distance.argsor()函数返回diastance内元素升序排列的下标索引)。然后确定前k个距离最小样本所在的分类;最后将classCount字典分解为元组列表——即{['L':3],['A':0]},然后使用程序清单2中运算符模块的itemgetter方法,按照第二个元素的次序对元祖进行降序排序,最后返回发生频率最高的元素标签。
为了测试数据所在分类,在Python提示符中输入下列命令
>>>reload(kNN)
>>>kNN.Classify([18,90],samples, labels, 3)
输出结果应该是‘L’

到此,我们就已经构造玩了一个kNN算法的分类器,实际上大家可以看出来,这就是简单的计算了需要分类的数据跟哪几个样本最接近而已。所以算法并不难,主要在于理解并灵活运用。