Hadoop生态各组件搭建的环境配置记录汇总【超详细+Flink】
test用户:

node40:主节点
node37,node38,node39是数据节点。
python3.6.4,jdk1.8都是在/usr/local下。
zookeeper3.4.12在node37--node39节点上。
node40:安装的hive,mysql【root】,Sqoop1.99,Kafka。node40设置的HMaster,node38设置的HMaster-back,
node38,node37,node39是Hbase的slaves。
node40-node37:Python3.6,scala2.12.7
node37:Redis
其他所有的生态组件都安装在各节点的/home/test/Hadoop下
-----------------------------------------
========Hadoop集群搭建============
~/bash_profile:各个节点的环境变量的配置文件
-------------------------------------------
PATH=$PATH:$HOME/bin
#Java
export JAVA_HOME=/usr/local/jdk1.8.0_172 #这里路径为自己解压的JDK的路径
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=${JAVA_HOME}/bin:$PATH
# Hadoop Environment Variables
export HADOOP_HOME=/home/test/Hadoop/hadoop-2.9.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
#Maven
export M2_HOME=/public/users/test/Softwares/apache-maven-3.5.4
export PATH=$PATH:$JAVA_HOME/bin:$M2_HOME/bin
#SCALA
export SCALA_HOME=/home/test/Hadoop/scala-2.12.7
export PATH=$PATH:$SCALA_HOME/bin
#SPARK
export SPARK_HOME=/home/test/Hadoop/spark-2.3.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
#Zookeeper
export ZOOKEEPER_HOME=/home/test/Hadoop/zookeeper-3.4.12
export PATH=$PATH:$ZOOKEEPER_HOME/bin
export CLASSPATH=$CLASSPATH:$ZOOKEEPER_HOME/lib
#Hbase
export HBASE_HOME=/home/test/Hadoop/hbase-1.4.7
export PATH=$PATH:$HBASE_HOME/bin
export CLASSPATH=$CLASSPATH:$HBASE_HOME/lib
#Hive
export HIVE_HOME=/home/test/Hadoop/apache-hive-2.3.3-bin
export HIVE_CONF_DIR=/home/test/Hadoop/apache-hive-2.3.3-bin/conf
export PATH=$PATH:$HIVE_HOME/bin
=====================================================
Hadoop文件配置:hadoop-2.9.1/etc/hadoop/
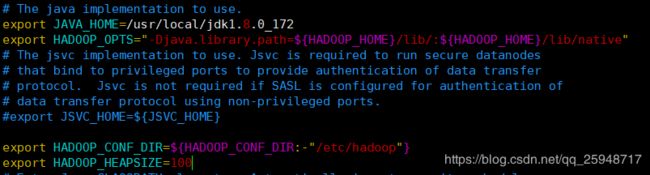
---------hadoop-env.sh----------
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk1.8.0_172
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/:${HADOOP_HOME}/lib/native"
# The jsvc implementation to use. Jsvc is required to run secure datanodes
# that bind to privileged ports to provide authentication of data transfer
# protocol. Jsvc is not required if SASL is configured for authentication of
# data transfer protocol using non-privileged ports.
#export JSVC_HOME=${JSVC_HOME}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
export HADOOP_HEAPSIZE=100
------mapred-env.sh-------
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
export JAVA_HOME=${JAVA_HOME}

-------core-site.xml--------
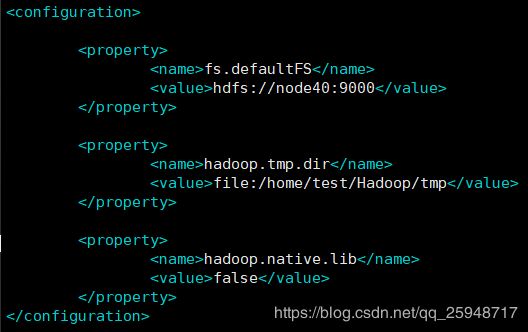
hadf://表示采用hdfs的文件系统,file:/表示采用本机的实际目录,需要手动创建
-----yarn-site.xml---------
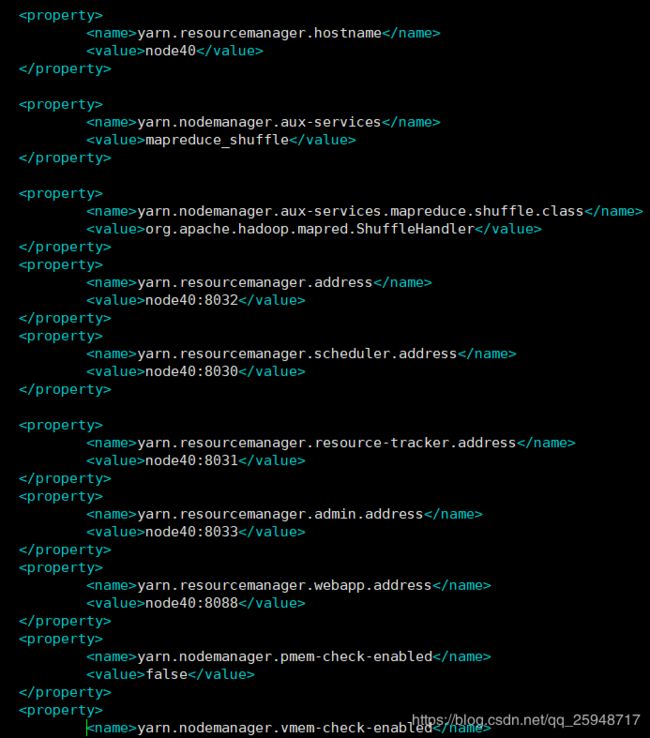
-------hdfs-site.xml------

-----mapred-site.xml-----
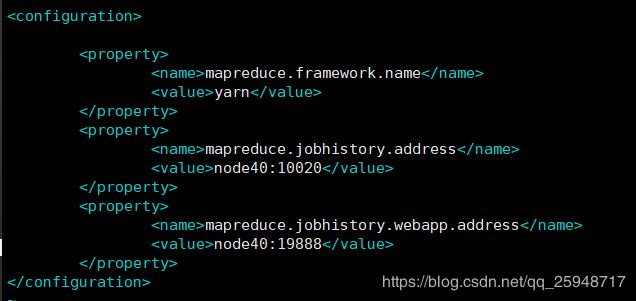
-------------------------------------------------------------------------------------------------
基本配置已完,配置slaves

--------------------------------------------------------------------
依次输入来启动:[我这里把node39设置为secondarynamenode]
hadoop namenode -format
start-dfs.sh
start-yarn.sh
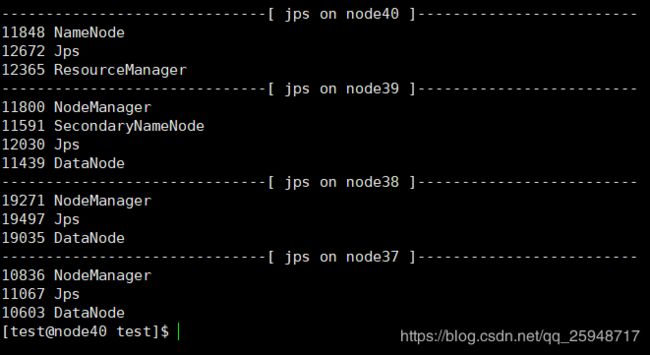
=========Zookeeper集群搭建========
这里将node39,node37,node38搭建zookper集群,奇数个节点。
其中某个是leader,
通过节点之间的投票获得谁是leader。

用途:1.hadoop集群的高可用
2.服务的注册中心
3.分布式锁
-------------------------------------------------------------------------------
先上传解压缩包zookeeper
-----zoo.cfg--------

# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/test/Hadoop/zookeeper-3.4.12/data
dataLogDir=/home/test/Hadoop/zookeeper-3.4.12/logs
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=node39:2222:2223
server.2=node38:3333:3334
server.3=node37:4444:4445
-------------------------------------------------------------------------------
每个节点创建:
dataDir=/home/test/Hadoop/zookeeper-3.4.12/data
dataLogDir=/home/test/Hadoop/zookeeper-3.4.12/logs
目录
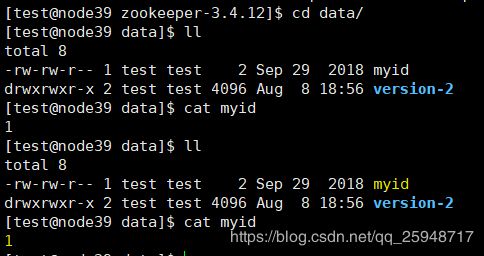
--------------------myid-------------------
在每个节点的/home/test/Hadoop/zookeeper-3.4.12/data创建文件myid。根据zoo.cfg中
server.1=node39:2222:2223
server.2=node38:3333:3334
server.3=node37:4444:4445
在各节点下的myid中输入相应的数值。
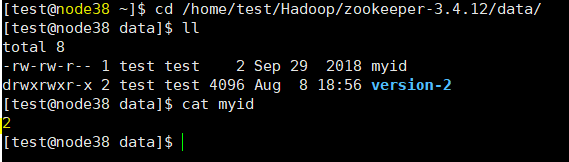
环境变量的配置:如上,每台节点都是这样配置

----------------开启-------------------
为了避免一台台挨着开启,我写一个脚本,可以启动多个几点下的zookeeper:

执行startzookeeper.sh即可:
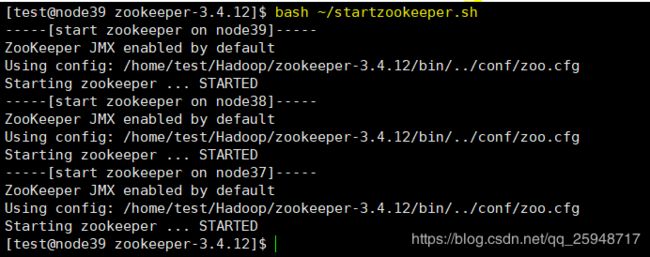
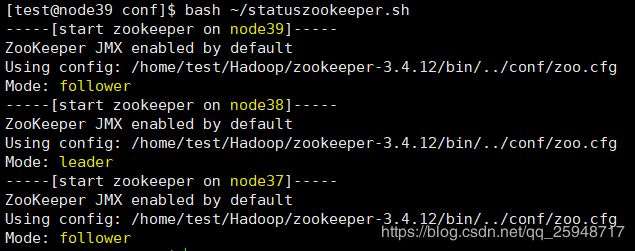
同理写了一个查看状态的脚本:

查看状态:node38是leader。
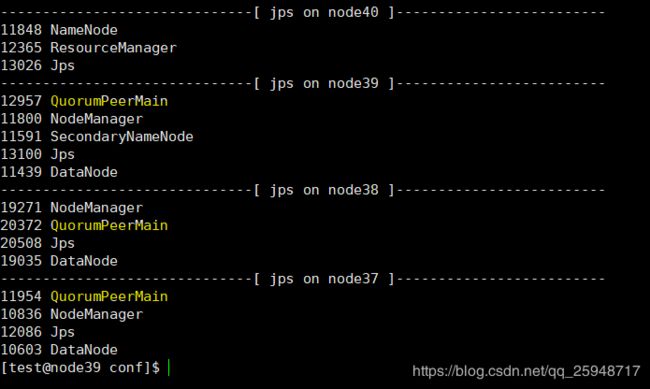
------也可以通过jps----------
==============Hbase集群架构==============
HMaster宕机了,系统可以自动切换到Hmaster上,保证hbase集群24小时服务。
两个Hmaster都要注册到Zookeeper服务器上。
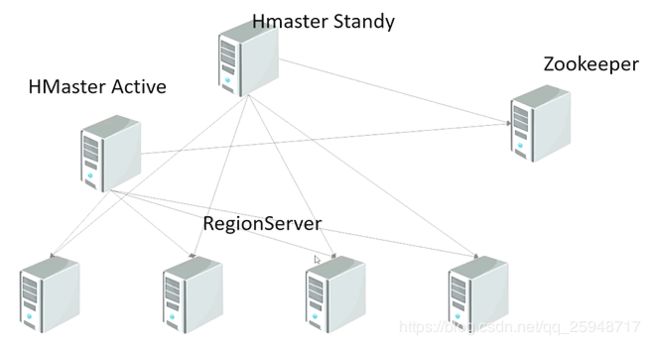
我的方案设计是:node40是HMaster,node38是Hmaster-back,node37-node39都是slaves。
-----------上传解压-------------
其他节点操作一样,可在一个节点下配好再拷贝整个文件到其他节点。
-----hbase-site.xml-------

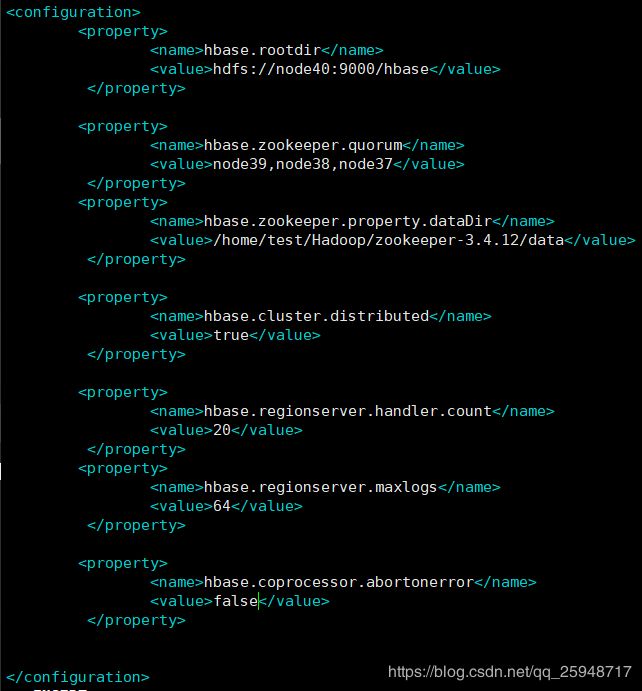
-----regionservers-------
-------配置HMaster-back--------node38是back Hmaster

-------环境变量配置------

-------------启动Hbase-----------
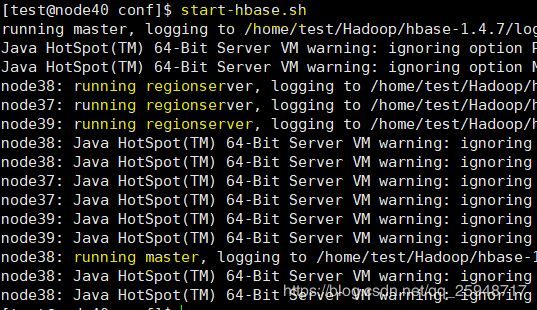
查看:
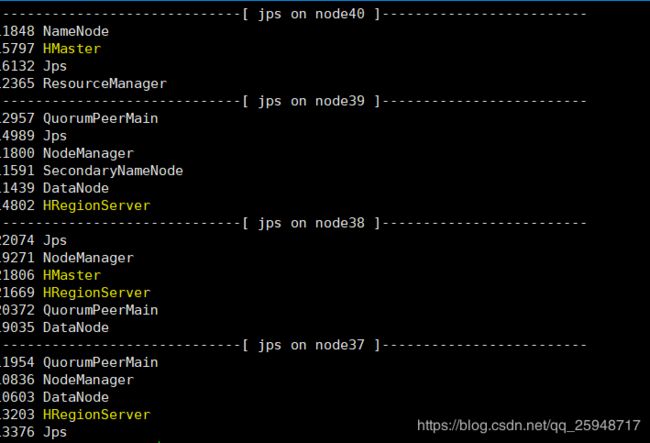
---------端口访问---------
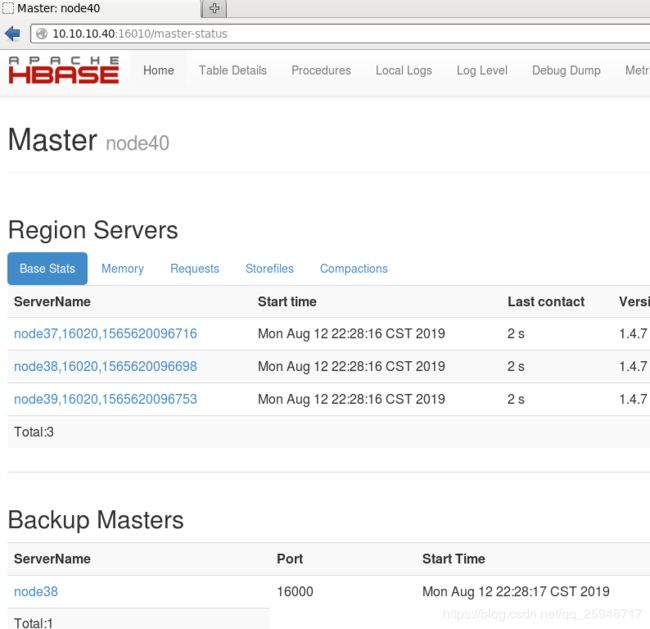
手动杀死node40下的HMaster后,node38会自动接管Hbase集群。
=============Sqoop搭建=================
快速实现Hadoop和传统数据库之间的数据传递
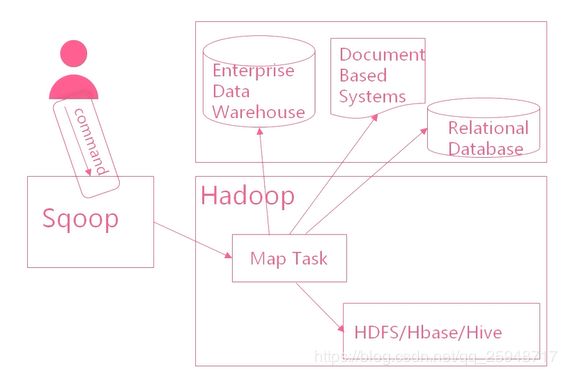
核心技术:1.生成MR作业 2.数据映射 3.作业创建 4.并行控制
下载解压,配置环境变量:
#Sqoop
export SQOOP_HOME=/home/test/Hadoop/sqoop-1.99.7-bin-hadoop200
export PATH=$PATH:$SQOOP_HOME/bin
---------------------------------------------------------------------------------------
===========Hive==================
node40安装hive:下载解压

配置conf里面的hive-site.xml
记住现在node40上安装mysql,然后创建test用户。
将数据库驱动下载拷贝到lib目录下:

确保mysql启动,输入hive即可启动。
==========Flink1.7.2======
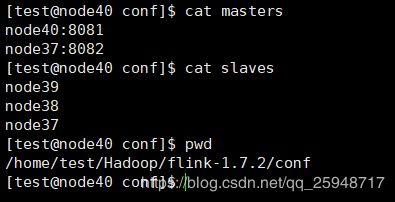
node40,node37是master,node37--node39是slaves
下载解压:
进入到conf配置文件【我这里使用zookeeper集群,搭建高可用的flink集群】:
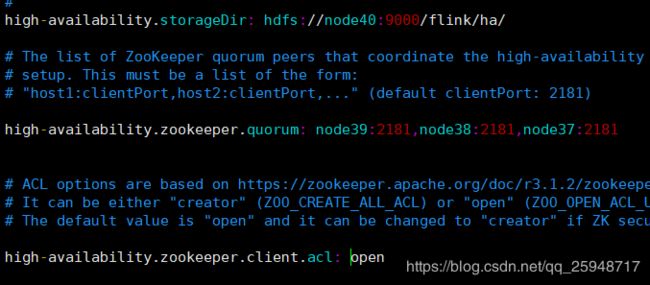
------flink-conf.yaml-----
high-availability: zookeeper
high-availability.storageDir: hdfs://node40:9000/flink/ha/
high-availability.zookeeper.quorum: node39:2181,node38:2181,node37:2181
high-availability.zookeeper.client.acl: open
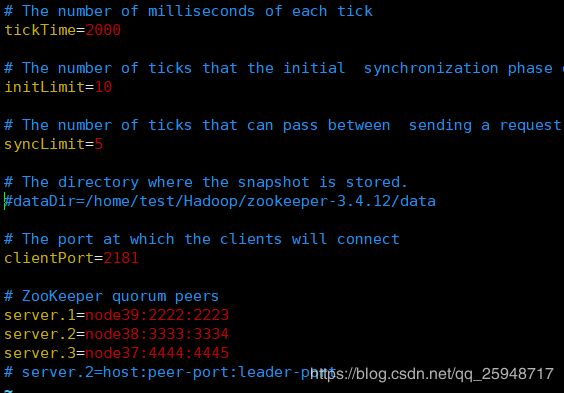
-------zoo.cfg--------
# ZooKeeper quorum peers
server.1=node39:2222:2223
server.2=node38:3333:3334
server.3=node37:4444:4445
-------masters,slaves-------
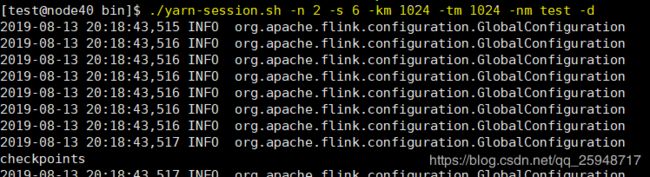
------启动flink到yarn上--------
第一步是必须的:在bin下执行:./yarn-session.sh -n 2 -s 6 -km 1024 -tm 1024 -nm test -d
jps:
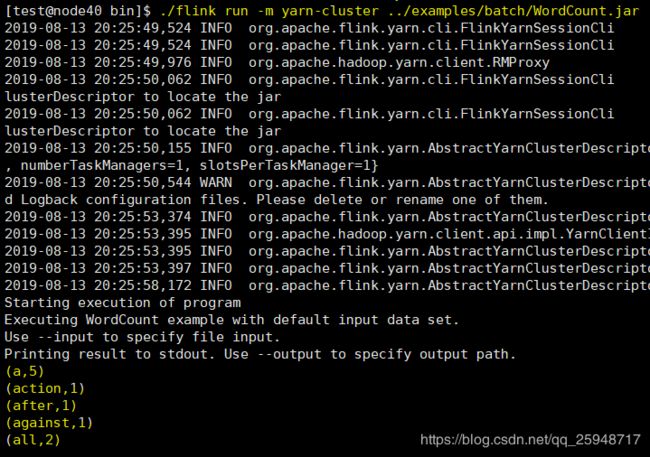
提交任务算例测试:在bin目录下:
./flink run -m yarn-cluster ../examples/batch/WordCount.jar