大数据基础知识学习-----Storm学习笔记
Storm学习笔记总结
Storm概述
离线计算是什么
离线计算:批量获取数据、批量传输数据、周期性批量计算数据、数据展示
代表技术:Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算数据、Hive批量计算数据
流式计算是什么
流式计算:数据实时产生、数据实时传输、数据实时计算、实时展示
代表技术:Flume实时获取数据、Kafka实时数据存储、Storm/JStorm实时数据计算、Redis实时结果缓存、持久化存储(mysql)。
离线计算与实时计算最大的区别:实时收集、实时计算、实时展示
Storm是什么
Storm是一个分布式计算框架,主要使用Clojure与Java语言编写,最初是由Nathan Marz带领Backtype公司团队创建,在Backtype公司被Twitter公司收购后进行开源。最初的版本是在2011年9月17日发行,版本号0.5.0。
2013年9月,Apache基金会开始接管并孵化Storm项目。Apache Storm是在Eclipse Public License下进行开发的,它提供给大多数企业使用。经过1年多时间,2014年9月,Storm项目成为Apache的顶级项目。目前,Storm的最新版本1.1.0。
Storm是一个免费开源的分布式实时计算系统。Storm能轻松可靠地处理无界的数据流,就像Hadoop对数据进行批处理;
Storm与Hadoop的区别
- Storm用于实时计算,Hadoop用于离线计算。
- Storm处理的数据保存在内存中,源源不断;Hadoop处理的数据保存在文件系统中,一批一批处理。
- Storm的数据通过网络传输进来;Hadoop的数据保存在磁盘中。
- Storm与Hadoop的编程模型相似
| Storm | hadoop |
|---|---|
| 角色 | Nimbus |
| Supervisor | |
| Worker | |
| 应用名称 | Topology |
| 编程接口 | Spout/Bolt |
hadoop的相关名称
- Job:任务名称
- JobTracker:项目经理(JobTracker对应于NameNode;JobTracker是一个master服务,软件启动之后JobTracker接收Job,负责调度Job的每一个子任务task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。)
- TaskTracker:开发组长(TaskTracker对应于DataNode;TaskTracker是运行在多个节点上的slaver服务。TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务。)
- Child:负责开发的人员
- Mapper/Reduce:开发人员中的两种角色,一种是服务器开发、一种是客户端开发
storm相关名称
- Topology:任务名称
- Nimbus:项目经理
- Supervisor:开组长
- Worker:开人员
- Spout/Bolt:开人员中的两种角色,一种是服务器开发、一种是客户端开发
Storm应用场景
Storm用来实时计算源源不断产生的数据,如同流水线生产,Storm能用到很多场景中,包括:实时分析、在线机器学习、连续计算等。
- 推荐系统:实时推荐,根据下单或加入购物车推荐相关商品
- 金融系统:实时分析股票信息数据
- 预警系统:根据实时采集数据,判断是否到了预警阈值。
- 网站统计:实时销量、流量统计,如淘宝双11效果图
Sotrm特点
适用场景广泛:Storm可以适用实时处理消息、更新数据库、持续计算等场景。可伸缩性高:Storm的可伸缩性可以让Storm每秒处理的消息量达到很高。扩展一个实时计算任务,你所需要做的就是加机器并且提高这个计算任务的并行度。Storm使用Zookeeper来协调机器内的各种配置使得Storm的集群可以很容易的扩展。保证无数据丢失:Storm保证所有的数据都被处理。异常健壮:Storm集群非常容易管理,轮流重启节点不影响应用。容错性好:在消息处理过程中出现异常,Storm会进行重试。
Storm基础理论
Storm编程模型

元组(Tuple)
元组(Tuple),是消息传递的基本单元,是一个命名的值列表,元组中的字段可以是任何类型的对象。Storm使用元组作为其数据模型,元组支持所有的基本类型、字符串和字节数组作为字段值,只要实现类型的序列化接口就可以使用该类型的对象。元组本来应该是一个key-value的Map,但是由于各个组件间传递的元组的字段名称已经事先定义好,所以只要按序把元组填入各个value即可,所以元组是一个value的List。
流(Stream)
流是Storm的核心抽象,是一个无界的元组系列,源源不断传递的元组就组成了流,在分布式环境中并行地进行创建和处理
水龙头(Spout)
Spout是拓扑的流的来源,是一个拓扑中产生源数据流的组件。通常情况下,Spout会从外部数据源中读取数据,然后转换为拓扑内部的源数据。
- Spout可以是可靠的,也可以是不可靠的。如果Storm处理元组失败,可靠的Spout能够重新发射,而不可靠的Spout就尽快忘记发出的元组。
- Spout可以发出超过一个流。
- Spout的主要方法是nextTuple()。NextTuple()会发出一个新的Tuple到拓扑,如果没有新的元组发出,则简单返回。
- Spout的其他方法是ack()和fail()。当Storm检测到一个元组从Spout发出时,ack()和fail()会被调用,要么成功完成通过拓扑,要么未能完成。Ack()和fail()仅被可靠的Spout调用。IRichSpout是Spout必须实现的接口。
转接头(Bolt)
在拓扑中所有处理都在Bolt中完成,Bolt是流的处理节点,从一个拓扑接收数据,然后执行进行处理的组件。Bolt可以完成过滤、业务处理、连接运算、连接与访问数据库等任何操作。
- Bolt是一个被动的角色,七接口中有一个execute()方法,在接收到消息后会调用此方法,用户可以在其中执行自己希望的操作。
- Bolt可以完成简单的流的转换,而完成复杂的流的转换通常需要多个步骤,因此需要多个Bolt。
- Bolt可以发出超过一个的流。
拓扑(Topology)
拓扑(Topology)是Storm中运行的一个实时应用程序,因为各个组件间的消息流动而形成逻辑上的拓扑结构。
把实时应用程序的运行逻辑打成jar包后提交到Storm的拓扑(Topology)。Storm的拓扑类似于MapReduce的作业(Job)。其主要的区别是,MapReduce的作业最终会完成,而一个拓扑永远都在运行直到它被杀死。一个拓扑是一个图的Spout和Bolt的连接流分组。
Storm核心组件
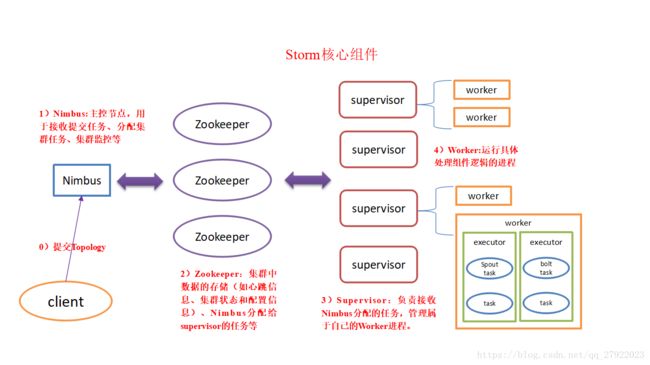
nimbus是整个集群的控管核心,负责topology的提交、运行状态监控、任务重新分配等工作。
zk就是一个管理者,监控者。
总体描述:nimbus下命令(分配任务),zk监督执行(心跳监控,worker、supurvisor的心跳都归它管),supervisor领旨(下载代码),招募人马(创建worker和线程等),worker、executor就给我干活!task就是具体要干的活。
主控节点与工作节点
Storm集群中有两类节点:主控节点(Master Node)和工作节点(Worker Node)。其中,主控节点只有一个,而工作节点可以有多个。
Nimbus进程与Supervisor进程
主控节点运行一个称为Nimbus的守护进程类似于Hadoop的JobTracker。Nimbus负责在集群中分发代码,对节点分配任务,并监视主机故障。
每个工作节点运行一个称为Supervisor的守护进程。Supervisor监听其主机上已经分配的主机的作业,启动和停止Nimbus已经分配的工作进程。
流分组(Stream grouping)
流分组,是拓扑定义中的一部分,为每个Bolt指定应该接收哪个流作为输入。流分组定义了流/元组如何在Bolt的任务之间进行分发。Storm内置了8种流分组方式。
工作进程(Worker)
Worker是Spout/Bolt中运行具体处理逻辑的进程。一个worker就是一个进程,进程里面包含一个或多个线程。
执行器(Executor)
一个线程就是一个executor,一个线程会处理一个或多个任务。
任务(Task)
一个任务就是一个task。
实时计算常用架构图
后台系统 –>Flume集群–>Kafka集群–>Storm集群–>Redis集群
- Flume获取数据。
- Kafka临时保存数据。
- Strom计算数据。
- Redis是个内存数据库,用来保存数据。
Storm集群搭建
环境准备
jar包下载
安装集群步骤:http://storm.apache.org/releases/1.1.2/Setting-up-a-Storm-cluster.html
虚拟机准备
- 准备3台虚拟机
配置ip地址
1.在终端命令窗口中输入
[root@hadoop101 /]#vim /etc/udev/rules.d/70-persistent-net.rules
删除eth0该行;将eth1修改为eth0,同时复制物理ip地址
2.修改IP地址
[root@hadoop101 /]#vim /etc/sysconfig/network-scripts/ifcfg-eth0
需要修改的内容有5项:
IPADDR=192.168.1.101
GATEWAY=192.168.1.2
ONBOOT=yes
BOOTPROTO=static
DNS1=192.168.1.2
:wq 保存退出
3.执行service network restart
4.如果报错,reboot,重启虚拟机配置主机名称
3台主机分别关闭防火墙
[root@hadoop102 luo]# chkconfig iptables off
[root@hadoop103 luo]# chkconfig iptables off
[root@hadoop104 luo]# chkconfig iptables off
安装Jdk
卸载现有jdk
- 查询是否安装java软件:
rpm -qa|grep java - 如果安装的版本低于1.7,卸载该jdk:
rpm -e 软件包
用filezilla工具将jdk、Hadoop-2.7.2.tar.gz导入到opt目录下面的software文件夹下面
在linux系统下的opt目录中查看软件包是否导入成功
[root@hadoop101opt]# cd software/
[root@hadoop101software]# ls
jdk-7u79-linux-x64.gz hadoop-2.7.2.tar.gz
解压jdk到/opt/module目录下
tar -zxf jdk-7u79-linux-x64.gz -C /opt/module/
配置jdk环境变量
1.先获取jdk路径:
[root@hadoop101 jdk1.7.0_79]# pwd /opt/module/jdk1.7.0_79
2.打开/etc/profile文件:
[root@hadoop101 jdk1.7.0_79]# vi /etc/profile
在profie文件末尾添加jdk路径:
##JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.7.0_79
export PATH=$PATH:$JAVA_HOME/bin
3.保存后退出:
:wq
4.让修改后的文件生效:
[root@hadoop101 jdk1.7.0_79]# source /etc/profile
5.重启(如果java –version可以用就不用重启):
[root@hadoop101 jdk1.7.0_79]# sync
[root@hadoop101 jdk1.7.0_79]# reboot
6.测试jdk安装成功
[root@hadoop101 jdk1.7.0_79]# java -version
java version "1.7.0_79"
安装Zookeeper
集群规划
在hadoop102、hadoop103和hadoop104三个节点上部署Zookeeper
解压安装
解压zookeeper安装包到/opt/module/目录下l
[luo@hadoop102 software]$ tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/
在/opt/module/zookeeper-3.4.10/这个目录下创建zkDatae
mkdir -p zkData
重命名/opt/module/zookeeper-3.4.10/conf这个目录下的zoo_sample.cfg为zoo.cfg
mv zoo_sample.cfg zoo.cfg
配置zoo.cfg文件
具体配置
dataDir=/opt/module/zookeeper-3.4.10/zkData
增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
配置参数说明
Server.A=B:C:D
A是一个数字,表示这个是第几号服务器;
B是这个服务器的ip地址;
C是这个服务器与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,
选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
集群操作
在/opt/module/zookeeper-3.4.10/zkData目录下创建一个myid的文件
touch myid
添加myid文件,注意一定要在linux里面创建,在notepad++里面很可能乱码
编辑myid文件
vi myid
在文件中添加与server对应的编号:如2
拷贝配置好的zookeeper到其他机器上
scp -r zookeeper-3.4.10/ [email protected]:/opt/app/
scp -r zookeeper-3.4.10/ [email protected]:/opt/app/
并分别修改myid文件中内容为3、4
分别启动zookeeper
[root@hadoop102 zookeeper-3.4.10]# bin/zkServer.sh start
[root@hadoop103 zookeeper-3.4.10]# bin/zkServer.sh start
[root@hadoop104 zookeeper-3.4.10]# bin/zkServer.sh start
查看状态
[root@hadoop102 zookeeper-3.4.10]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
[root@hadoop103 zookeeper-3.4.10]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: leader
[root@hadoop104 zookeeper-3.4.5]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
Storm集群部署
配置集群
- 拷贝jar包到hadoop102的/opt/software目录下
- 解压jar包到/opt/module目录下:
[luo@hadoop102 software]$ tar -zxvf apache-storm-1.1.0.tar.gz -C /opt/module/ - 修改解压后的apache-storm-1.1.0.tar.gz文件名称为storm:
[luo@hadoop102 module]$ mv apache-storm-1.1.0/ storm - 在/opt/module/storm/目录下创建data文件夹:
[luo@hadoop102 storm]$ mkdir data 修改配置文件
[luo@hadoop102 conf] pwd/opt/module/storm/conf[luo@hadoop102conf] p w d / o p t / m o d u l e / s t o r m / c o n f [ l u o @ h a d o o p 102 c o n f ] vi storm.yaml
设置Zookeeper的主机名称
storm.zookeeper.servers:
- “hadoop102”
- “hadoop103”
- “hadoop104”
设置主节点的主机名称
nimbus.seeds: [“hadoop102”]
设置Storm的数据存储路径
storm.local.dir: “/opt/module/storm/data”
设置Worker的端口号
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703配置环境变量
[root@hadoop102 storm]# vi /etc/profile #STORM_HOME
export STORM_HOME=/opt/module/storm
export PATH= PATH: P A T H : STORM_HOME/bin
[root@hadoop102 storm]# source /etc/profile分发配置好的Storm安装包:
[luo@hadoop102 storm]$ xsync storm/启动集群
后台启动nimbus
[luo@hadoop102 storm]bin/storm nimbus &
[luo@hadoop103 storm] bin/storm nimbus & [luo@hadoop103 storm] bin/storm nimbus &
[luo@hadoop104 storm]$ bin/storm nimbus &后台启动supervisor
[luo@hadoop102 storm]bin/storm supervisor &
[luo@hadoop103 storm] bin/storm supervisor & [luo@hadoop103 storm] bin/storm supervisor &
[luo@hadoop104 storm]$ bin/storm supervisor &启动Storm ui
[luo@hadoop102 storm]$ bin/storm ui
通过浏览器查看集群状态:http://hadoop102:8080/index.html
Storm日志信息查看
查看nimbus的日志信息
在nimbus的服务器上
cd /opt/module/storm/logs
tail -100f /opt/module/storm/logs/nimbus.log
查看ui运行日志信息
在ui的服务器上,一般和nimbus一个服务器
cd /opt/module/storm/logs
tail -100f /opt/module/storm/logs/ui.log
查看supervisor运行日志信息
在supervisor服务上
cd /opt/module/storm/logs
tail -100f /opt/module/storm/logs/supervisor.log
查看supervisor上worker运行日志信息
在supervisor服务上
cd /opt/module/storm/logs
tail -100f /opt/module/storm/logs/worker-6702.log
logviewer,可以在web页面点击相应的端口号即可查看日志
分别在supervisor节点上执行:
[luo@hadoop102 storm]bin/storm logviewer &
[luo@hadoop103 storm] bin/storm logviewer & [luo@hadoop103 storm] bin/storm logviewer &
[luo@hadoop104 storm]$ bin/storm logviewer &
Storm命令行操作
- nimbus:启动nimbus守护进程:
storm nimbus - supervisor:启动supervisor守护进程:
storm supervisor - ui:启动UI守护进程:
storm ui - list:列出正在运行的拓扑及其状态:
storm list - logviewer:Logviewer提供一个web接口查看Storm日志文件:
storm logviewer - jar:storm jar 【jar路径】 【拓扑包名.拓扑类名】 【拓扑名称】
- kill:杀死名为Topology-name的拓扑:
storm kill topology-name [-w wait-time-secs]-w:等待多久后杀死拓扑 - active:激活指定的拓扑spout:
storm activate topology-name - deactivate:禁用指定的拓扑Spout:
storm deactivate topology-name - help:打印一条帮助消息或者可用命令的列表:
storm help和storm help
常用API
API简介
Component组件
基本接口
- IComponent接口
- ISpout接口
- IRichSpout接口
- IStateSpout接口
- IRichStateSpout接口
- IBolt接口
- IRichBolt接口
- IBasicBolt接口
基本抽象类
- BaseComponent抽象类
- BaseRichSpout抽象类
- BaseRichBolt抽象类
- BaseTransactionalBolt抽象类
- BaseBasicBolt抽象类
spout水龙头
Spout的最顶层抽象是ISpout接口
Open():初始化方法close():该spout关闭前执行,但是并不能得到保证其一定被执行,kill -9时不执行,Storm kill {topoName} 时执行activate():当Spout已经从失效模式中激活时被调用。该Spout的nextTuple()方法很快就会被调用deactivate:当Spout已经失效时被调用。在Spout失效期间,nextTuple不会被调用。Spout将来可能会也可能不会被重新激活nextTuple():当调用nextTuple()方法时,Storm要求Spout发射元组到输出收集器(OutputCollecctor)。NextTuple方法应该是非阻塞的,所以,如果Spout没有元组可以发射,该方法应该返回。nextTuple()、ack()和fail()方法都在Spout任务的单一线程内紧密循环被调用。当没有元组可以发射时,可以让nextTuple去sleep很短的时间,例如1毫秒,这样就不会浪费太多的CPU资源ask():成功处理tuple回调方法fail():处理失败tuole回调方法
bolt转接头
bolt的最顶层抽象是IBolt接口
prepare():prepare ()方法在集群的工作进程内被初始化时被调用,提供了Bolt执行所需要的环境。
execute():接受一个tuple进行处理,也可emit数据到下一级组件。
cleanup():Cleanup方法当一个IBolt即将关闭时被调用。不能保证cleanup()方法一定会被调用,因为Supervisor可以对集群的工作进程使用kill -9命令强制杀死进程命令。
如果在本地模式下运行Storm,当拓扑被杀死的时候,可以保证cleanup()方法一定会被调用。
实现一个Bolt,可以实现IRichBolt接口或继承BaseRichBolt,如果不想自己处理结果反馈,可以实现 IBasicBolt接口或继承BaseBasicBolt,它实际上相当于自动做了prepare方法和collector.emit.ack(inputTuple)。
spout的tail特性
Storm可以实时监测文件数据,当文件数据变化时,Storm自动读取。
分组策略和并发度
读取文件路径和方法
- spout数据源:数据库、文件、MQ(比如:Kafka)
- 数据源是数据库:只适合读取数据库的配置文件
- 数据源是文件:只适合测试、讲课用(因为集群是分布式集群)
- 企业产生的log文件处理步骤:(1)读出内容写入MQ(2)Storm再处理
分组策略(Stream Grouping)
stream grouping用来定义一个stream应该如何分配给Bolts上面的多个Executors(多线程、多并发)。
Storm里面有7种类型的stream grouping
Shuffle Grouping: 随机分组,轮询,平均分配。随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。Global Grouping:全局分组,这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。Non Grouping:不分组,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果。在多线程情况下不平均分配。Direct Grouping:直接分组,这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。- Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发送给这些tasks。否则,和普通的Shuffle Grouping行为一致。
并发度
并发度场景
- 单线程下:加减乘除、全局汇总
- 多线程下:局部加减乘除、持久化DB等
并发度
并发度:用户指定一个任务,可以被多个线程执行,并发度的数量等于线程executor的数量。
Task就是具体的处理逻辑对象,一个executor线程可以执行一个或多个tasks,但一般默认每个executor只执行一个task,所以我们往往认为task就是执行线程,其实不是。
Task代表最大并发度,一个component的task数是不会改变的,但是一个componet的executer数目是会发生变化的(storm rebalance命令),task数>=executor数,executor数代表实际并发数。