【新手向】一些C/C++ 与指针有关的知识简单的衍生
(本人能力有限,纯新手向主要是面向那些刚学编程没多久对编程感兴趣的萌新,大佬就没必要花时间看了。当然也欢迎各路大佬来指正小破文不足的地方)
也算是接触了编程有一段时间了,记录一下心得。
当年读C++ primer最头疼的就是无疑就是指针这一章,感觉指针这个东西没啥用处而且十分玄学(毕竟当时对内存的认识只是知道计算机里有个内存条而已)。后来随着指针在书中后面的章节出现频率越来越高我对指针的恐惧也日益加深。可以说,指针是我当年学编程最大的障碍。
直到现在我看到的很多编程初学者也很难理解指针变量的储存形式和作用,于是就想写这篇文章说说现在的我对指针的理解,也算是给当年的自己一个答案吧。。。
指针是什么
这个问题书上说的很清楚,指针是储存变量的地址的变量。那么变量地址是什么呢?这个问题很少有编程书解释的很清楚。变量地址就是变量在计算机里存储的位置,大多数初学者只能得到这个笼统的回答。于是,我们记住了指针是变量在计算机里存储的位置。然而当我们看到:
int num[3] = {1,2,3};
int * p = num;//指向数组的指针
int fun(){
return 0;
}
int main(){
int (* p)() = fun;//指向函数的指针
printf("%d",p());
return 0;
}
void fun(int *p){
*p = 2;
}
int main(){
int *p ,num = 1;
p = #
fun(p);//通过函数改变参数的值
return 0;
}
当我们看到这些代码的时候,我们又开始怀疑人生。指针不是变量地址吗,凭什么数组也是变量就不需要取地址,函数难道也是变量吗,为什么将指针作为形参传递到函数里面就能改变实参的值非指针就不能。而一般的编程初级教程上很难找到这些问题的答案。接着我们就开始怀疑变量地址到底是什么,真的就只是变量储存的位置这么简单吗。这个时候估计很多非计算机专业的同学已经准备开始弃坑了。确实,网上很多“大学学了冷门专业,毕业报班4个月编程学XX语言出来月入10万”广告中这个XX语言很少有是C或者C++的。当然这个问题原因肯定不是因为指针太难学(当然java的确没有指针这个说法),但是我觉得这这两个现象的出现有一个共同的原因:
C与C++语法与计算机程序的运行原理有紧密的联系
因此,对一些完全不了解计算机运行机理的初学者(只是凭多年玩游戏看配置配电脑的那点知识是肯定不够的)很难理解一些概念。这个特点也导致了C/C++算是主流高级编程语言中比较硬核的,不同于java,python之类可以随便学一下就马上可以上岗写一些不太复杂的代码。
有点扯远了,让我们切回正题。指针之所以难以理解正是因为它与内存管理紧密联系。我个人认为指针之所以在C与语言中很重要是因为它极大拓宽了程序管理内存的能力。想要彻底理解指针的本质必须从程序是怎么使用内存的说起:
程序是怎么使用内存的
“程序将变量产生的临时数据放到内存中,需要长期保存的数据放到磁盘中 ”我当年就是这么天真的认为的。事实上实际情况比这稍微复杂一点。。。
(在这里我们不讨论内存分页机制,操作系统多程序同时运行,多线程这些复杂情况,只讨论单线程,一个程序,一块内存)首先我们要知道的是我们运行一个程序的所有资源都是CPU从内存上取得的。这里的资源包括指令也就是我们写的代码(当然是经过编译器翻译成机器码的)。这和我们想象中内存只是数据的中转站有点不太一样。事实上我们的CPU会一边从内存中把指令取出来一边根据指令将计算出来的数据写到内存里面去。这样就诞生了一个问题:如果CPU不小心取到了别的数据而不是指令怎么办呢?解决办法很简单:指令放在一块区域,数据放在另一块区域两块区域隔离开来,CPU要取指令只去专门放代码的区域,CPU改数据就去专门的数据区域去改。这样就有了我们的内存分段
内存分段机制
顾名思义将内存分成各种不同功能的区段,每个区段放对应功能的数据。总体来说内存被分为了4个区段:数据(Data)段,代码(Code)段,堆栈(Stack-Heap)段和附加(Extra)段
其中代码段最好理解,就是我们前文所提的指令数据所放置的区段。数据段稍微有点复杂,可能我们直观感受是数据段是我们代码中所有变量数据所放的位置,而实际上我们变量数据是堆栈段和数据段共同存储的。这个我们稍后会讨论。附加段我不是很了解,为了避免误人子弟我就不过多叙述了。。。(太菜了)。
分好段把数据放到内存里,接下来我们要做的就是要访问内存了。然而内存里全都是0和1的数据,没有什么标记能辨别出我们想要的数据。比如下面这段内存
00001010 11101001 00001111
10010011 11001010 00101001
我们想要访问一个叫做num的unsigned int(32位)变量数据我们该如何知道这48位的数据中哪32个我们想要的呢。
将每8个数据编成一组从0开始给它们一个组编一个号。要想找数据的时候就去找相应的号码,这个号码便是我们的地址。比如:
0:00001010
1:11101001
2:00001111
3:10010011
4:11001010
5:00101001
如果我们告诉cpu我们num变量的地址是1,cpu很容易就能找到11101001 00001111
10010011 11001010。这就是我们要找的num的值接下来就是把它翻译成十进制就能得到我们看到的数值了
事实上这就是我们编译器在编译程序的时候做的事情。我们用高级语言书写代码,声明变量的时候只知道变量的名字而不知道变量的地址值,而cpu在执行程序的时候只知道变量的地址并不知道变量的名字,给变量名字分配地址的过程是由编译器完成的。基本上,我们可以认为我们所声明的每一个变量,编译器都在为我们找了一块大小与变量类型相当大小的内存。(实际上编译器会把可预见值的变量忽略)我们修改变量就是在修改内存!这块内存的编号便是我们变量的地址。
看到这里我们应该很清楚指针变量到底是做什么的了
比如还是这块内存
0:00001010
1:11101001
2:00001111
3:10010011
4:11001010
5:00101001
我们在别的地方声明了一个很特别的变量p它存储的数据是num的地址也就是
(假设p存储在6,实际上指针都是32位的数据这里为了方便只写8位)
6:00000001
这个时候我们就称 p是指向num的指针
在赋值时我们的 p = &num实际上就是&num运算计算出num的地址是00001,接下来将1放到p所对应的内存地址6上,当我们(*p) = 2的时候,(*p)运算符实际上就是将p所对应地址6的数据取出(00000001)再根据数据00000001找到地址1处的num将值2赋给num。
(PS:顺便一提 *符号在 不同场合下有完全不同的意思:
1. int *p;//*是声明指针变量的标志表示我们声明了一个int类型的指针
2.*p = 10;//这里*是解引用运算符意思是找到指针p保存的地址对应的数据并将它修改成10
3.m = 10 * 10;//这里*只是普通乘法符号
这三种情况下*符号意思完全不同,可以把它们理解为三个不同符号)
因此指针能间接修改变量的值
那么为什么能将数组名字赋给指针呢
我们再看一下第一个例子
int num[3] = {1,2,3};
int * p = num;
我们已经知道变量的名字p一般在编译的时候会被翻译成变量所存的值,而数组这个变量比较特殊。
它在内存中是由多个类型相同的变量组成的比如说num数组第一个变量的地址是0的话:
(这里为了方便数据直接用16进制,每4个地址(32位)写一次的方式表示了)
0: 01 00 00 00//num[0]
4: 02 00 00 00//num[1]
8: 03 00 00 00//num[2]
C: 00 00 00 00//p指针
我们发现num在内存中连在一起一个接一个存储的。而num这个名字在编译的时侯会直接被翻译成num数组的首地址0。于是我们p = num这种操作相当于是p = &num[0] 这种将变量地址赋值给指针的操作当然是合法的了,由于在编译时num数组名会被翻译成变量首地址,因此我们也叫它数组指针
我们也可以通过如下方式看到数组的首地址
当然不止有存储数据的内存有地址,整个内存都被分成了8位一小块(8位也就是我们常说的Byte字节)
一小块一个地址的结构。也就是说储存代码的代码段也被分为这种结构。我们计算机所执行的每一条指令都有对应的一个地址。我们可以通过一些反汇编工具查看这些指令以及其地址。
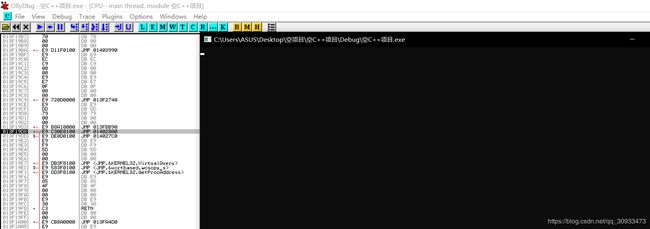
图中为反汇编工具分析出来一个C++编译出来的exe程序指令部分,从左到右依次为为指令在内存中对应的地址(虚拟),指令数据,指令数据翻译成汇编语言的具体样式
我们知道指针是存储地址数据的变量。因此我们可以知道,指针存储的数据也可以是指令的地址
我们再来看最开始提到的第二个例子
int fun(){
return 0;
}
int main(){
int (* p)() = fun;//指向函数的指针
printf("%d",p());
return 0;
}
我们知道函数就是一段指令,指令数据在内存中应该也有对应的地址。因此我们int (*p)() = fun
这种行为也就是合法的。在编译的时候函数名fun相当于是指向函数开头第一个指令的地址数据。将地址数据交给指针p存储,在后来printf("%d",p());中p()会根据p中所存地址找到对应指令根据指令执行完函数得到返回值0之后带入到printf()函数中作为实参。
这样函数指针这种行为也就不难理解了。
接下来就是初学C语言中的一个难点,函数不能改变实参的值而指针却可以
void fun(int *p){
*p = 2;
}
int main(){
int *p ,num = 1;
p = #
fun(p);//通过函数改变参数的值
return 0;
}
在这个小片段中num的值由1变成了2,而我们如果把程序改一下
void fun(int p){
p = 2;
}
int main(){
int num = 1;
fun(num);
return 0;
}
这样最后num的值还是1。
为什么会出现这种情况呢,这与C语言调用函数的原理有关。
讲到调用函数就不得不讲堆栈段和变量在内存里存储的位置
堆栈段和数据段与变量的位置
数据段我们好理解,一看名字我们就知道是存储数据的地方。然而堆栈段大家就相对陌生了。实际上堆和栈是两种特殊的数据结构。而内存中就利用了这两种数据结构的特性来指定了一些特殊的指令,将一些临时的数据存放在这块内存中以堆和栈的方式储存数据便于管理。因此堆栈段的内存也就被分成了两个区:堆区和栈区
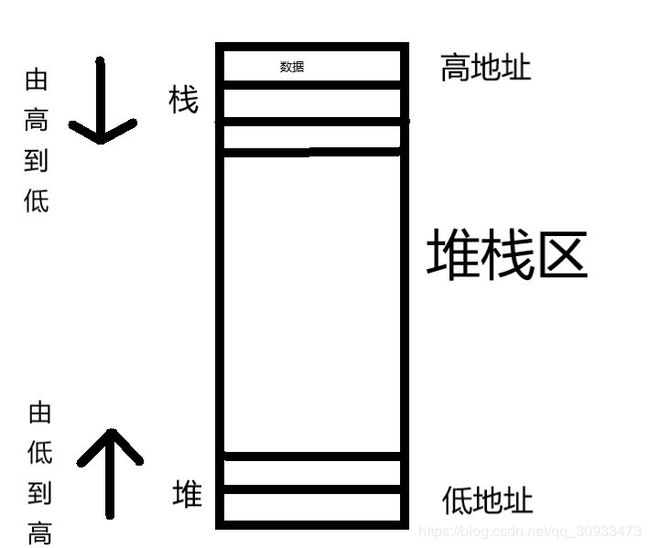
其中栈区起点是高地址(数值较大),从高到低使用内存,堆区起点是低地址,由低到高使用内存。
因为堆区和函数调用机制的实现没太大关系这里我们就暂时不管它,我们主要讨论栈区。
栈是一种先进后出的数据结构,通过push和pop来添加和删除元素,效果如下:
当然C++中也封装好了这种数据结构,我们可以通过#include < stack >来导入相关的库(当然C++里的栈和我们现在讨论的内存栈不是一个东西)//下面是模拟上图的过程
#include
using namespace std;
stack spawExample()
{
stack num;//num现在是一个空栈
num.push(2);
num.push(7);
num.push(1);
return num;
}//此时num的内容与图一一致
int main(){
stack a = spawExample();
a.push(8);//a内容与图二一致
a.push(2);//a内容与图三一致
a.pop();//a内容与图四一致
a.pop();//a内容与图五一致
a.pop();//a内容与图六一致
return 0;
}
当然内存栈中我们可以通过不断push的方式添加数据占用空间,但是这样做效率实在太低,一个数据就push一次,成百上千个数据就需要成百上千个push指令,这样指令就太多了。所以正常情况下编译器不会选择这种方式为变量申请内存。
我们来看看编译器是怎么为这个程序申请内存的
#define NUM 10
#include
int add(int ,int );
int global;
int main()
{
int a ;
scanf("%d",&a);
const int b = 2;
static int num = 3;
num = add(a,b);
global = num + NUM;
return 0;
}
int add(int a,int b){
return a+b;
}
首先编译器从头到尾扫描代码一共找到了2个常量,3个变量它们分别是
常量NUM = 10,常量 (const)b = 2,全局变量 global,局部变量a,局部静态(static)变量num
最好处理的首先是常量NUM和b。常量的值在代码执行过程中不会改变,是可以预见结果的,编译器认为可以预见结果的数据没有必要为它们分配内存,这里无论变量还是常量。它们在编译时会被直接替换成编译器计算得到的值。于是,编译时程序就变成了
#include
int add(int a,int b);
int global;
int main()
{
int a ;
scanf("%d",&a);
//const int b = 2;
static int num = 3;
num = add(a,2);//num = add(a,b);b直接被换成了2!
global = num + 10;//global = num + NUM;NUM直接被换成了10!
return 0;
}
int add(int a,int b){
return a+b;
}
接下来就是给不可预见结果的变量分配内存了
其中global全局变量会被分配到数据段,因为global全局变量在程序中随时都有可能被访问,而数据段的数据就是随时可以被访问的。而静态局部变量num虽然只能在局部访问,但它的生命周期是和程序是一致的因此它也会被分配到数据区,只是编译器会通过一些特殊手段阻止你在其它地方访问它。
最后我们得到了真正的临时数据只有a,编译器会将临时数据a的内存分配到栈中。这个时候编译器真正开始为主函数的调用分配内存了
函数的调用
在cpu中有一块空间专门记录现在栈区分配到的所有内存中最低的地址。这便是栈顶指针 esp(esp其实是cpu内专门存储栈顶地址的存储单元的名字),编译器可以通过修改栈顶指针分配内存。当栈顶指针的地址值减少时,因为栈是由高到低使用内存的,栈分配到的内存也就会随之增加。
因此当有函数被调用,新的内存空间需要被申请的时候,编译器会像我们之前做的那样将函数中需要分配内存的变量找出来从而计算出函数所需要的空间大小。从esp中减去相应的空间大小就能申请到函数所需要的全部空间了。接下来,我们函数的所有临时变量都能在esp的范围内分配到相应的地址和空间了。
同时当我们的函数结束调用,也就是执行到return语句的时候,我们也要将相应的函数的内存释放掉重新回到原来函数的内存空间。这个时候,我们需要将每个函数所占有分割成一块一块的,开头和结尾都有一个标记。这样在这个函数结束调用的时候,我们只需要将函数的结尾的地址值赋值给开头标记,而结尾标记去回复到先前在内存里存储好的结尾标记的地址就可以实现函数内存的释放了。
过程类似下图:
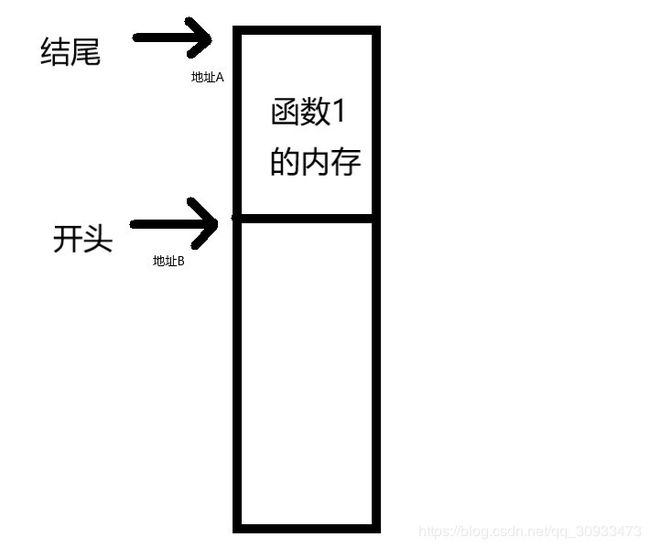
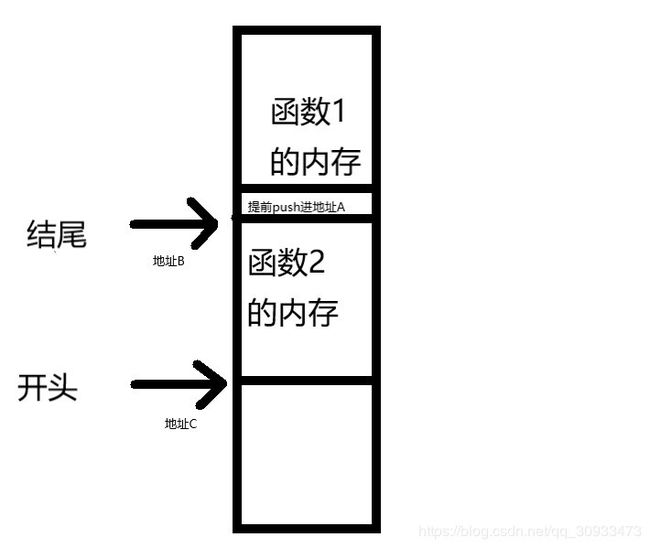
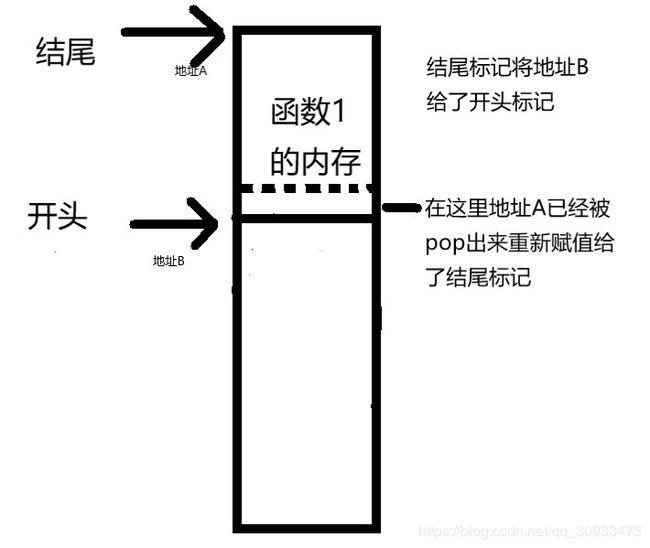
因此在函数的调用过程中我们需要一个结尾标记来标记出函数的起始地址。
在cpu中也有像esp一样的栈底指针------- ebp。
ebp在函数调用中就充当结尾标记的角色。可以说在栈中esp和ebp将每个函数内存分成独立的小块每个小块只操作自己的内存,互不干涉。我们可以把这些小块看成一个独立的内存单元。每块由esp和ebp围成的内存块我们把它们叫做栈帧。每一个调用函数申请内存的过程我们都可以看作是开辟一个新的栈帧的过程。
函数的诞生就是为了让我们把复杂的程序拆分成简单的,独立的小零件。而函数的栈帧就是这种思想的完美体现。两个函数之间的内存不能共享完全独立,自己完成自己的工作。然而,函数之间也必须要有联系。这就是我们函数之间的传参和返回值。(终于扯到重点了)
发现扯的有点太多了,这里就讨论函数的传参机制吧:
函数传参的方式有很多,不同的编程语言有不同的解决方案。甚至C,C++语言自己也提供了多种传参方式(_stdcall,_cdecl等等)这些属于C语言函数组成部分的约定 部分。我们平常基本上没见到这些符号是因为当我们没声明相关符号时编译器默认我们是调用_cdecl约定。这些机制其实对我们研究函数的指针与传参没太大关系。顺口一提,有兴趣可以百度一下。
当然在具体传参的时候还有栈传参,寄存器传参等等。这些方法原理其实都挺类似,为了不引入寄存器这个新概念(其实之前的esp和ebp也是寄存器)我们只讨论栈传参。
我们都知道函数之间内存空间栈帧是互不交互的。为了把数据传递给另一个函数我们需要把数据复制到栈帧之外的另一个区域。比如:
#include
int add(int a,int b);
int global;
int main()
{
int a ;
scanf("%d",&a);
//const int b = 2;
static int num = 3;
num = add(a,2);//num = add(a,b);b直接被换成了2!
global = num + 10;//global = num + NUM;NUM直接被换成了10!
return 0;
}
int add(int a,int b){
return a+b;
}
在num = add(a,2);中在调用add函数时,add函数在自己的栈帧中需要访问到变量a的数值。而此时,a的数值是在函数main的空间中add无法访问。于是在main调用add函数的时候,main函数会将参数从右往左(调用_cdecl约定下)将的参数的拷贝push到自己的栈帧后面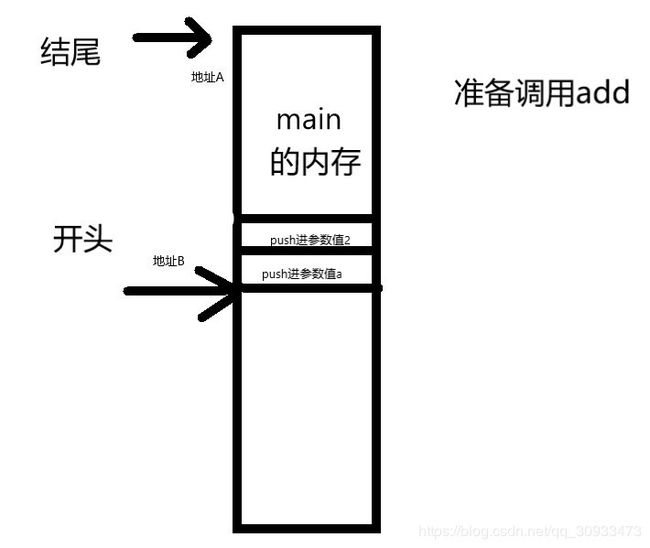
在开启函数add的栈帧后我们就发现
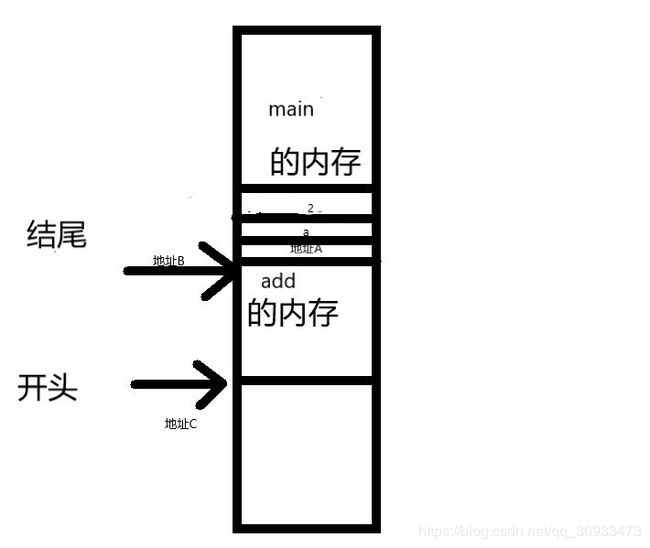
函数add在运行时它很容易就可以从ebp附近找到函数的参数。
这样我们没有让两个函数互相访问对方的栈帧就实现了参数的传递。
当然这个时候,形参已经与实参已经分离开来时两个互不相干的个体了。形参的值如何改变,都不会对实参有任何影响。毕竟形参只是实参的拷贝。最后函数调用结束,形参就会被销毁掉,对实参没有任何影响
我们回到开头的例子3
void fun(int *p){
*p = 2;
}
int main(){
int *p ,num = 1;
p = #
fun(p);//通过函数改变参数的值
return 0;
}
当指针作为参数传递的时候,情况就发生了变化。这个时候在函数fun执行的时候,得到的p的确只是原来指针变量*p的拷贝。但是这个时候指针p的拷贝不再只是简单的一份数据拷贝,而是num在main中的地址数据的拷贝。fun函数通过地址数据找到num的在内存中的位置(即便num数据不在fun所在的栈帧中)修改num的值。
于是这就是为什么指针作为参数传递的时候能修改变量的值
指针的作用
下面我们再来看看指针究竟有什么作用
我们从上面的这些信息可以看出指针有个很大的特点:几乎没有任何访问限制
一个函数的局部变量只能作用在这个函数体内,一个全局变量顶多能在整个程序的作用域内。而指针
几乎没有C语言语法本身带来的限制只要你能给出有效地址,它就能都访问相应的内存。除非这块内存时禁止读写的(禁止读写的内存被修改了操作系统就会把我们的电脑屏幕变成可爱的小蓝屏)
,指针可以随意读写相应的内存。
我下面简单举出指针的几个应用:
1.访问函数自身很难访问的内存
学C语言接触到的第一个函数就是printf()函数(C++的话std::cout<<“Hello world”;就是另一回事了)
这个函数有个很牛逼的特点,没有参数个数,参数类型的限制。
比如printf("%d,%d,%d",1,2,3);
第一个参数是字符串,之后的参数我们可以随便填
事实上我们也可以声明这样的函数
//这里直接给出C++版的代码了
//在参数列表后面加上...就能让我们的函数调用时随意向后填写参数
void Myprintf(const char* s,...);
我们也可以自己尝试一下,当只能利用cout打印字符串的情况下自己实现一个printf
(下面为了简单我们只实现一个只能打印int值的版本,其中直接用%代表替换掉的值
比如Myprintf("%A%",1,2) 我们在屏幕上就能看到1A2)
看起来很简单对吧,然而在实际操作中我们发现我们根本无法操作传进来的后续参数。
这个时候就可以利用指针去访问这些参数了
之前讨论过函数的参数都是从右往左依次push进栈中的,以传进去的参数为Myprintf("%,%,%",1,2,3)为例
那么在栈中从上到下参数数据应该为
3
2
1
char* "%,%,%"的首地址数据
在函数中我们可以得到参数1也就是参数s的地址(不是s所对应字符串的首地址)int* p = (int* )&s;
接下来我们遍历字符串,每当遇到第一个%的时候我们来看内存中:
3
2
1
p-> char* "%,%,%"的首地址数据
如果我们让p自增一个(int)大小的地址值(也就是地址值加4)
3
2
p->1
char* "%,%,%"的首地址数据
这个时候我们p就访问到了参数1的值,接下来只要解引用就可以得到参数值了
接下来同理,每当我们找到一个%我们让指针p自增一次就可以得到后续的参数值了
于是我们可以得到以下代码
#include
#include
using namespace std;
void Myprintf(const char* s, ...) {
int* p = (int*)& s;
string out;
for (; *s != '\0'; s++) {
if (*s == '%') {
p ++;//这里指针自增1的时候编译器会根据指针类型决定地址值的增量为sizeof(int)*1
out += to_string(*p);
}
else {
out += *s;
}
}
cout << out;
}
int main() {
Myprintf("%a%b%c%d", 1, 2, 5, 6);//实际测试一下期望结果“1a2b5c6d”
}
运行结果
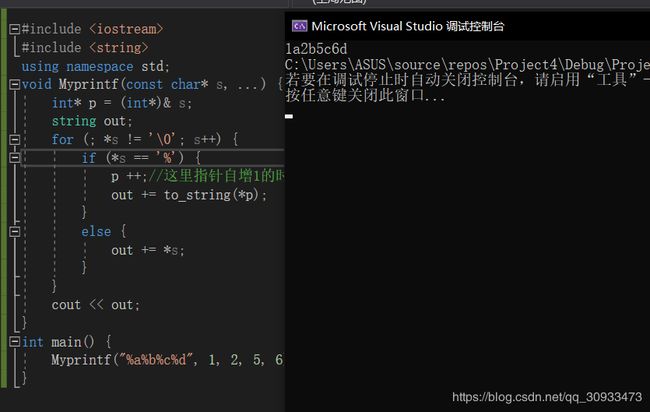
事时上,我们不仅可以利用指针访问未知的参数,我们甚至可以利用指针访问别的正在运行的程序的内存资源。
游戏外挂程序就是利用了这一点,通过内存注入的方式躲过系统审查。它找到游戏程序的相关函数
代码在内存中的地址,利用函数指针访问到函数。通过重复多次调用以达到将修改数值的目的。
这里就不再演示了(其实是因为技术力不够,流下了不学无术的泪水)
2.指针是管理堆内存的重要途经
之前我们一直都在讨论栈内存,是因为在C++/C中我们的所有我们能直接访问到的内存都是栈内存。而堆内存我们就需要通过特殊的函数申请,通过指针手动管理和释放。在Java中看似没有用到指针,而当我们新创建一个非传统对象的时候Java虚拟机都是自动帮我们在堆中申请内存,帮我们取到引用再传递回函数的。同样,Java也是自动监测对象引用次数,最后自动回收已经不需要的内存数据,这就是Java的GC(Garbage Collection)机制(顺便一提,C++在< memory >头文件中也实现了类似的智能指针shared_ptr机制)。有了GC机制,Java看似脱离了通过指针管理堆内存的桎梏,但事实上Java的GC机制也是在一个类似指针的机制上的一次封装。其实,很多看起来没有利用指针机制的高级语言也是通过封装指针来降低学习门槛的(C++面向对象的部分class这之类的机制,实际上也可以在C语言中通过指针实现)。指针本质上还是管理堆内存的重要方式。
那么我们为什么要用堆内存呢
当我们不知道我们要使用的对象个数的时候,我们会选择使用堆内存
————《C++ Primer》 动态内存分配
考虑这种情况,在有时候我们需要处理一串长度未知的字符串。我们可以通过声明
char buffer[256];这样申请很大一块内存。可万一那个字符串不止256个字符呢?而且如果我们的字符串很小呢我们申请了一块很大的内存结果字符串里只有一两个字符这不就很尴尬。
这个时候我们可能会想这样做
int size = Process(...);//通过一系列计算后知道字符串的大小
char str[size];//这个时候申请一块size大小的内存
这样做是绝对错误的。我们之前讨论过,C语言程序是先申请内存,然后执行函数指令
因此在编译过程中,我们必须保证函数占用的内存大小是可预见的。显然这里我们在执行指令前不可能知道size的值是多少。因此编译器无法为我们的程序申请内存。
如果我们真的必须有类似需求的话,我们可以使用malloc函数申请堆内存(C++通过new运算申请内存)。
当我们需要一边执行程序一边申请额外的内存时我们可以选择申请堆内存。因为堆内存不像栈内存,被esp和ebp严格分成了小块的栈帧。没有严格的格式要求,堆内存像是额外的内存可以随意申请。因此我们之前的代码可以修改成:
int size = Process(...);//通过一系列计算后知道字符串的大小
char* str = (char* )malloc(sizeof(char) * size);//申请size个char大小的内存,并把它们转换成字符串指针类型
//当然如果是C++的话我们可以 char* str = new char[size];来申请
3.指针能更好的把控数据在函数之间传递的过程
我们可一看到相比直接传递参数我们编程教程很多时候更愿意这么写
void func(const string& a,vector& b);
TreeNode* Copy(const TreeNode* root);
这是因为在很多时候,传递指针要比传递参数要方便很多也更加安全
下面看例子
class test {
public:
test(int x) :data(new int(x)) {}
test(const test& a){
data = new int(*a.getRefer());
}
int* getRefer() const { return data; }
private:
int* data;
};
void func(test a) {
//经过一系列处理后
return;
}
int main() {
test myTest(1);
func(myTest);
return 0;
}
这个程序看似没有什么问题而且实际运行过程中也能得到我们期望的结果。
但是,这个程序会造成一种比较棘手的程序漏洞----内存泄漏
我个人认为程序的问题一般有三类。第一是最好解决的语法问题,这种问题在程序还没开始运行的时候IDE很快就能找出来。因此这种问题不需要太担心,毕竟这种问题你都不需要自己去找。第二种问题是逻辑问题,你运行程序后马上就发现结果不对需要修改。这种问题有时候不太好修改,但是并不难找。而且现在IDE的调试功能都很强大,逐步分析,追进调用过程,追踪堆栈都十分方便。第三种则是最不好找也是最难修复的问题,这些问题平常根本看不出来,必须在某些特殊情况下才能出现较为严重的问题。而内存泄漏就是第三种问题。
内存泄漏
什么是内存泄漏。在C语言中我们之前讨论过,指针是唯一管理堆内存的方式。一个指针负责一块堆内存。同时指针在被销毁时指针所分配的内存不会被释放,这是为了防止这块内存还有别的指针还在指向这块内存。如果一个指针被销毁时释放了对应的内存话其他还在指向这块内存的指针就不可用了。我们可以通过delete运算符手动释放内存,但是如果我们在手动释放掉这块内存之前所有指向这块内存的指针就被销毁的话,就会出现一块堆内存没有指针能够访问并释放这种情况。这时,在程序结束之前,我们无法再使用这块内存了。这种情况我们称为内存泄漏。
可是,我们在程序中似乎没有出现销毁了唯一指向一块内存的指针的情况。而事实上,这归根结底还是和函数调用机制有关。
函数在调用传参的时候,我们都知道函数会把函数的参数的拷贝push到函数的结尾。在函数调用结束的时候,我们会去释放栈内存。这时,函数的拷贝也会被销毁掉。
对于一些简单的类型int,char,float这之类我们可以很容易拷贝并释放掉。然而我们在使用一些复杂的类的时候,我们会使用类的拷贝构造函数和析构函数完成这些工作。
对C++来说,每个类都会有5个必备函数拷贝构造函数,转移构造函数,拷贝赋值运算符(运算符其实是一种特殊的函数),转移赋值运算符和析构函数。当一个类在声明的时候没有定义这五个函数的话,编译器会自动生成5个相应的函数。因此我们在声明类的时候很少会去自己定义这五种函数。然而这些函数对类的对象来说十分重要。以函数传参为例:
void func(test a) {
//经过一系列处理后
return;
}
这里当test a在传参时作为参数进行拷贝并赋值到a所对的内存区域时,程序会去调用test的拷贝构造函数。一般情况下,程序调用的是编译器合成的拷贝构造函数。然而,此时程序却调用了我们自己定义的拷贝构造函数,因为在test中:
class test {
public:
...
test(const test& a){
data = new int(*data);
}
...
}
test (const test& a)成为了我们自定义的拷贝构造函数。一般对class X当参数列表为X(const X&)的构造函数是拷贝构造函数。而在函数中我们在拷贝得到新对象时会申请一块新内存并把它交给新对象的data成员保管。也就是说当调用func时我们的参数a的成员data申请了一块内存!
接着,在func函数结束调用的时候参数a会被销毁掉。此时程序会尝试调用a的析构函数。而a的析构函数我们没有直接声明,因此程序会调用编译器合成的版本。在编译器合成的版本中a的数据唯一成员data因为是int* 的简单类型,会被直接销毁掉,而data申请的内存不会被释放掉!。这就造成了我们之前说过的内存泄漏!
也就是说函数func每被调用一次,就会多一块(int大小的)内存没有被释放掉。而这一切都是在我们没有任何主动申请内存的情况下发生的!这也就是为什么内存泄漏问题难以被发掘定位的原因。
内存泄漏的危害也是很大的,它会给程序增加很多不稳定性。比如,func如果是一个大型项目的重要工具函数,它在短时间内会被调用成千上百次,那么这个过程会有大量的内存被浪费!我们接下来用while(true)循环模拟这个过程。
class test {
public:
test(int x) :data(new int(x)) {}
test(const test& a) {
data = new int(* a.getRefer());
}
int* getRefer() const { return data; }
private:
int* data;
};
void func(test a) {
//经过一系列处理后
return;
}
int main() {
test myTest(1);
while(true)
func(myTest);
return 0;
}
实际运行看一下
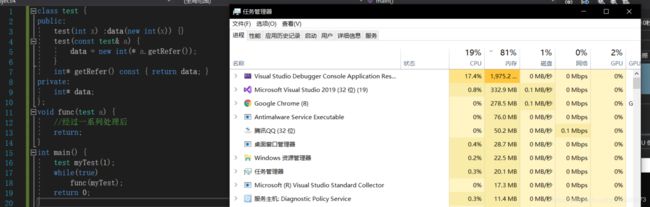
(Visual Studio Debugger Console Application就是我们的程序)
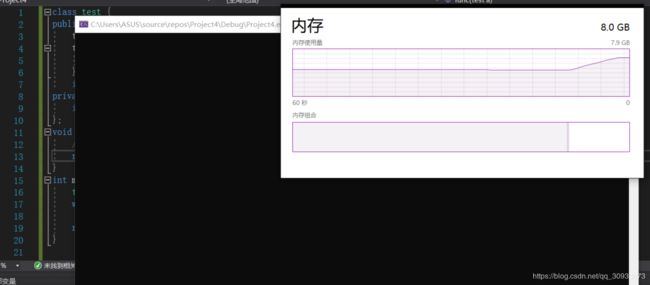
我们可以看到这个程序(第一个)占用的内存大的出奇,且在它开始运行时,系统的总内存占用突然开始异常持续增高(最后出现平稳可能因为堆内存已经被申请爆了,没有位置放新数据了)。这就是内存泄漏的后果。
我们可以通过定义自己版本的析构函数解决问题。但事实上很多时候,直接用指针传参要来的简便的多。
class test {
public:
test(int x) :data(new int(x)) {}
test(const test& a){
data = new int(*a.getRefer());
}
int* getRefer() const { return data; }
private:
int* data;
};
void func(test* a) {
//经过一系列处理后
return;
}
int main() {
test myTest(1);
while(true)
func(&myTest);
return 0;
}
再次运行
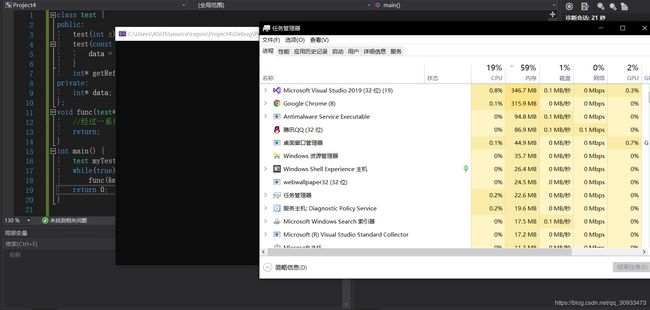
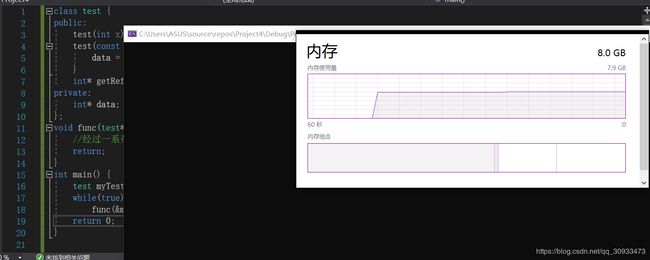
内存占用也一直很平稳没有出现异常情况。
当然如果担心在函数调用过程中不小心修改了参数的值我们只需要加上const限定符阻止修改就行了。例如:
void func(const test* a){
//经过一系列处理
return;
}
可见,函数调用的过程中利用指针会简便安全很多。
4.实现一些特殊的数据结构
数据结构是程序员的基础课,而一些特殊数据结构的实现离不开指针。
比如,链表:
class MyList{
public:
...
private:
int value;
MyList* next;//指向下一个元素
};
二叉树:
class TreeNode{
public:
...
private:
int value;
TreeNode* left;//指向左子叶
TreeNode* right;//指向右子叶
};
这些数据结构都有十分重要的应用
可见指针在C语言编程中十分重要。在初学编程的时候之所以觉得指针无用是因为能力,经验没有达到能灵活使用指针的地步。多练习,多学习自然就能掌握指针的用途了。
