JAVA函数式编程
JAVA函数式编程
- 背景
- 常见的编程范式
- 函数式编程的优劣
- JAVA8中为函数式编程引入的变化
- JAVA函数式编程可以简单概括
- 基本函数
- Lambda表达式
- 方法引用
- Stream流API
- 创建操作
- 中间操作
- 终止从操作
- 并行流
- 级联表达式与柯里化
- 收集器(终止操作因为内容较多提出来说明)
- Stream特性
- 工程地址
背景
JAVA版本最新的目前已经发布到11了,但目前市面上大多数公司依然在使用Java7之前版本的语法,然而这些编程模式已经渐渐的跟不上新时代的技术了。比如时下潮流前沿spring framework5中的响应式编程就是使用到了函数式编程的风格。
当时有一段时间了解了一下大数据领域生态发现对于写spark中的程序来说如果你使用java7前的命令式编程会使得整体代码相当臃肿,又臭又长匿名类大几百行的代码其中写到的逻辑其实不过几十行,大部分的代码浪费在语法上。使得代码的可读性变得非常差。spark本身是使用Scala编写的对于本身就支持函数式编程的语言,使得代码简洁而又易于理解。当然spark也支持jdk8相对于jdk7来说8加入了函数式编程的支持使得整体优雅了许多。
在编程历史的长河中java向来可维护性、可扩展性是一直受业界所推崇的。但由于java语法臃肿,也流失了一部分转向了python、go等。在学习大数据的时候发现大部分的教程更倾向Scala(如果大家有java8的教程麻烦连接评论哦!),而Scala本身依赖与jvm,所以若不是公司技术栈限制的话我相信大家更倾向与使用Scala来编程。OK!那么java也推出了函数式编程也通过本文来了解一下。
常见的编程范式
- 命令式编程:命令式编程的主要思想是关注计算机执行的步骤,即一步一步告诉计算机先做什么再做什么。这种风格我相信对于传统程序员来说都不陌生。甚至一些大牛闭着眼睛都可以敲了。
代表语言有:C, C++, Java, Javascript, BASIC,Ruby等多为老牌语言 - 声明式编程:声明式编程是以数据结构的形式来表达程序执行的逻辑。它的主要思想是告诉计算机应该做什么,但不指定具体要怎么做。乍一看似乎没有见过但其实日常来说大家也都在用。
代表语言有:SQL,HTML,CSS - 函数式编程:函数式编程将函数作为编程中的“一等公民”,关注于流程而非具体实现。可以将函数作为参数或返回值。所有数据的操作都通过函数来实现。可以理解为数学中的函数。较新的语言基本上追求语法上的简洁基本都有支持。
代表语言有:JAVA(8以上),js(ES6),C#,Scala,python等
函数式编程的优劣
优点:
- 代码简洁可读性强,逻辑结构清晰。
- 线程安全,内部API屏蔽了coder对多线程的关注。
- 更好的复用性,往往一个函数适用于各种计算场景。
缺点:
- 由于函数内数据不变原则,导致的资源占用
- 调试上相对于命令式的困难
JAVA8中为函数式编程引入的变化
- 函数式接口,函数式接口中只能有一个抽象方法
@FunctionInterface,这也是为了函数调用时避免带来二义性。@FunctionInterface并不是一定要标注但若是标注可以在编译时就给你提示错误。 - 静态方法,静态方法目的完全出于编写类库,对某些行为进行抽象,但是接口中的静态方法不能被继承。
- 默认实现,是不得已而为之,因为Java8引入了函数式接口,许多像Collection这样的基础接口中增加了方法,如果还是一个传统的抽象方法的话,那么可能很多第三方类库就会变得完全无法使用。新增一个方法所有实现类都要实现一次。被default修饰的方法–默认实现
JAVA函数式编程可以简单概括
lambda + 方法引用 + stream API = java函数式编程
基本函数
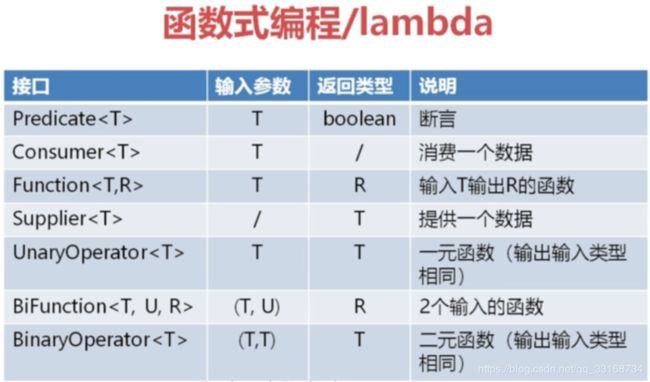
以上是在函数式编程中的基本函数模型,我们大可以将其与数学函数做关联:y = x +1,我们仅仅需要关注这个函数的输入输出即可。
以predicte函数举例:该函数输入一个表达式,输出一个布尔类型
一元函数function:输入一个类型参数输出为另一个类型,当然这两个类型可以是相同的,当相同时也可以使用unaryOperator来代替。具体下面有给出实际场景的代码断:
public class FunctionDemo {
public static void main(String[] args) {
//断言型
// predicate();
//消费型
// consumer();
//一元函数 输入输出不同
// function();
//提供型
// supplier();
//一元函数 输入输出类型相同
// unaryOperator();
//二元函数 输入输出不同
// biFunction();
//二元函数 输入输出相同
binaryOperator();
}
/**
*
*/
public static void predicate(){
Predicate<Integer> predicate = i -> i > 0;
IntPredicate intPredicate = i -> i > 0;
System.out.print(predicate.test(6));
System.out.print(intPredicate.test(-1));
}
public static void consumer(){
Consumer<String> consumer = s -> System.out.println(s);
consumer.accept("我是一个消费者");
}
public static void function(){
Function<Integer,String> function = x -> "数字是:"+ x;
System.out.println(function.apply(88));
}
public static void supplier(){
Supplier<String> supplier = () -> "我是一个提供者";
System.out.println(supplier.get());
}
public static void unaryOperator(){
UnaryOperator<Integer> unaryOperator = x -> ++x;
System.out.println(unaryOperator.apply(1));
}
public static void biFunction(){
BiFunction<Integer,Double,Double> biFunction = (x,y) -> {
++x;
++y;
return x+y;
};
System.out.println(biFunction.apply(1,2.3));
}
public static void binaryOperator(){
IntBinaryOperator intBinaryOperator = (x,y) -> x + y;
System.out.println(intBinaryOperator.applyAsInt(2,3));
}
}
Lambda表达式
相信大家在写一些匿名内部类时编译器会提示你,该处可以转换为lambda,例如:
public static void main(String[] args){
IMethod iMethod = () -> {};
}
public static void useLambda(){
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.print("123");
}
});
thread.start();
//lambda
new Thread(() -> System.out.print("123")).start();
}
定义一个线程并启动他,传统写法我们用了7行,但其实只有 System.out.print(“123”);这句话是有用的,而lambda表达式我们仅仅一行就达到了相同目的。‘
lambda表达式主要用于实例化一些函数式接口,替换匿名类的写法,主要形式有:
(输入) -> {输出} // 我们仅仅关注输入输出即可,若代码有多行大括号里面可以写多行,多行有返回值要显示声明return。输入可以为空即()。
在lambda表达式中无需像传统写法那样声明参数和返回值类型,它会根据你的上下文通过类型推导你实现的是哪一个接口,从而跟具这个接口的定义知道你变量的类型。这也是为什么函数式接口只能声明一个方法的原因。
文末链接有附带工程demo链接可以参考哦!
方法引用
我们可以直接使用两个冒号::来调用方法
- 静态方法引用
- 非静态 实例方法引用
- 非静态 类方法引用
- 构造函数方法引用
public class MethodReferenceDemo {
public static void main(String[] args) {
//消费者 方法引用模式
// consumer();
//静态方法引用
// callStaticMethod();
//非静态 实例方法引用
// callMethod();
//非静态 类方法引用
// callMethodByClass();
//构造函数方法引用
// callConstructorMethod();
//数据不变模式
callMethod2();
}
public static void consumer(){
Consumer<String> consumer = System.out::println;
consumer.accept("我是一个消费者");
}
private static void callStaticMethod() {
Consumer<Dog> consumer = Dog::bark;
consumer.accept(new Dog());
}
private static void callMethod() {
Dog dog = new Dog();
Function<Integer,Integer> function = dog::eat;
System.out.println("还剩[" + function.apply(3) + "]斤狗粮");
}
private static void callMethodByClass() {
BiFunction<Dog,Integer,Integer> biFunction = Dog::eat;
System.out.println("还剩[" + biFunction.apply(new Dog(),4) + "]斤狗粮");
}
private static void callConstructorMethod() {
Supplier<Dog> supplier = Dog::new;
System.out.println("new 了一个对象" + supplier.get());
}
private static void callMethod2() {
Dog dog = new Dog();
Function<Integer,Integer> function = dog::eat; //函数声明
dog = null;
System.out.println("还剩[" + function.apply(3) + "]斤狗粮");
}
}
Stream流API
Stream API是Java 8中加入的一套新的API,主要用于处理集合操作。Stream流API是函数式编程的核心所在,它以一种流式编程来对数据进行各种加工运算。形象的来说你可以把它看作工业中的流水线,将原料放入流中经过操作1、操作2…操作N输出一个产品。Stream也是如此它分为创建操作、中间操作、终止操作。业务逻辑清晰简单、代码看上去优雅不少。
流通常是由三个部分组成:
- 数据源:流的获取,比如list.stream()方法;
- 中间处理:中间处理是对流元素的一系列处理。比如过滤filter,排序sorted,映射map;
- 终端处理:终端处理会生成结果,结果可以是任何不是流值。
创建操作
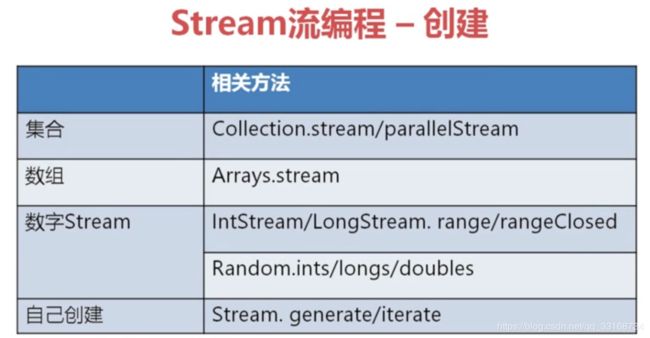
在jdk8中集合数组加入了不少流的方法其中就有直接通过实例或是工具类创建流。如:list.stream(),而数据没有自身API需要借助工具类Arrays来创建。这里通过parallelStream()并行流的模式来创建就可以透明的使用到多线程了。
注:通过阅读源码可以知Stream类与IntStream、LongStream并没有继承关系
public class CreateStream {
public static void main(String[] args) {
// collectionCreate();
// arrayCreate();
// numCreate();
selfCreate();
}
/**
* 集合创建
*/
public static void collectionCreate(){
List<String> list = new ArrayList<>();
Stream<String> stream = list.stream();
Stream<String> parallelStream = list.parallelStream();
}
/**
* 数组创建
*/
public static void arrayCreate(){
Integer[] array = new Integer[5];
Stream<Integer> stream = Arrays.stream(array);
}
/**
* 数字创建
*/
public static void numCreate(){
IntStream.of(1,2,3);
IntStream.rangeClosed(1,10);
new Random().ints().limit(10);
}
/**
* 自己创建
*/
public static void selfCreate(){
Random random = new Random();
Stream.generate(random::nextInt).limit(20);
Stream.iterate(2, (x) -> x*2).limit(10).forEach(System.out::println);
}
}
中间操作
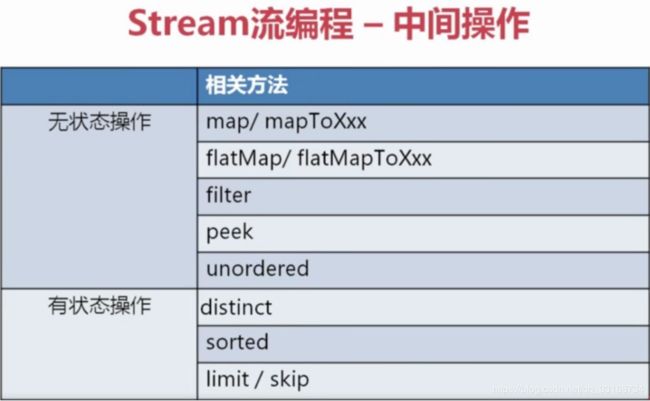
中间操作分为有状态操作、无状态操作。无状态操作即该中间操作不依赖与另外的空间来存放临时结果。有状态即需要。这么说还是比较抽象,我们不妨来举个栗子0.0。
比如说:你的排序操作传统我们要进行排序是否需要依赖额外空间来进行大小的比较。去重操作需要额外空间来存放未重复的值。而像是filter只是单纯返回过滤后的结果无需额外空间。
这是一种说法,另一种说法该操作与其他操作,没有依赖关系即为无状态,反正则为有状态。这么说也没错,你看像是order操作不是就要等前面操作都执行完才可以执行吗。后面会提到一点就是Stream的操作模式实际上是每一条数据通过A操作B操作C操作来进行的,而到了中间有有状态操作是,必须停下等所有数据都操作到这一步时一起进行,否则你让他如何进行排序呢?
public class MiddleStream {
public static void main(String[] args) {
// mapOrMapToXXX();
// flatMap();
// peek();
// distinct();
// sort();
limitSkip();
}
/**
* map操作 A -> B
* filter操作
*/
public static void mapOrMapToXXX(){
String s = "my name is 007";
Stream.of(s.split(" ")).map(String::length).forEach(System.out::println);
System.out.println("-------------");
Stream.of(s.split(" ")).filter(x -> x.length() > 2).mapToDouble(x -> x.length()).forEach(System.out::println);
}
/**
* flatMap操作 A -> B list
* IntStream/LongStream 并不是stream的子类需要进行装箱
*/
public static void flatMap(){
String s = "my name is 007";
Stream.of(s.split(" ")).flatMap(x -> x.chars().boxed()).forEach(x -> System.out.println((char)x.intValue()));
}
/**
* peek 要类型对应
*/
public static void peek(){
IntStream.of(new int[]{1,2,3,4,5}).peek(System.out::println).forEach(x->{});
}
/**
* distinct
*/
public static void distinct(){
IntStream.of(new int[]{1,3,3,4,5}).distinct().forEach(System.out::println);
}
/**
* sort
*/
public static void sort(){
IntStream.of(new int[]{5,4,3,1,2}).sorted().forEach(System.out::println);
}
/**
* limitSkip
*/
public static void limitSkip(){
IntStream.of(new int[]{1,2,3,4,5,6,7,8}).skip(2).limit(2).forEach(System.out::println);
}
}
这里提到Stream有个特性叫做:惰性求值。什么意思呢?就是当stream没有调用到终止操作时,实际上是不会执行之前的所有过程的。这一点可以在demo工程中有相应的证明方法。 有接触过spark的同学可以将这一特性类比为Transformation和Action。
终止从操作
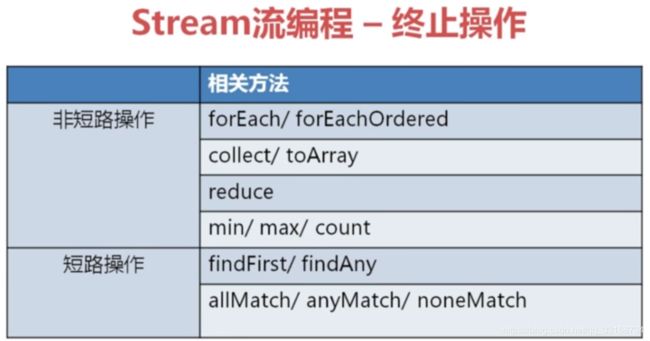
终止操作即流水线的最后一个操作,往往就是返回你所要的产品。
这里分为短路操作和非短路操作:
非短路操作:从流中获取所有数据进行运算返回,有可能返回一个或多个值,但必定运用到了所有数据
短路操作:从流中截取部分数据返回。
public class FinalStream {
public static void main(String[] args){
// forEachOrdered();
// collect();
// reduce();
// minMixCount();
findFirst();
}
/**
* forEachOrdered
*/
public static void forEachOrdered(){
IntStream.of(new int[]{1,2,3,4,5,6,7}).parallel().forEach(System.out::println);
// IntStream.of(new int[]{1,2,3,4,5,6,7}).parallel().forEachOrdered(System.out::println);
}
/**
* collect、toArray
*/
public static void collect(){
String s = "hello world!";
List<String> collect = Stream.of(s.split(" ")).collect(Collectors.toList());
System.out.println(collect);
}
/**
* reduce
*/
public static void reduce(){
Integer[] intArr = new Integer[]{1,2,3,4,5,6,7,8,9,10};
Optional<Integer> optional = Stream.of(intArr).reduce((x, y) -> x + y);
System.out.println(optional.get());
}
/**
* minMixCount
*/
public static void minMixCount(){
Integer[] intArr = new Integer[]{1,2,3,4,5,6,7,8,9,10};
Optional<Integer> optional = Stream.of(intArr).max(Comparator.comparingInt(x -> x));
System.out.println(optional.get());
}
//短路操作--------------------------------
/**
* findFirst
*/
public static void findFirst(){
Optional<Integer> first = Stream.generate(() -> new Random().nextInt()).findFirst();
System.out.println(first.get());
}
}
并行流
这里注释已经很全了就不做冗余说明。
public class ParallelStream {
public static void main(String[] args) {
// createParallelStream();
// feature2();
// feature3();
feature4();
}
/**
* 特性一 并行流线程数
* 并行流线程数默认为cpu个数
* 默认线程池
*/
public static void createParallelStream(){
IntStream.range(1, 100).parallel().forEach(ParallelStream::printDebug);
}
/**
* 特性二 并行再串行 以最后一个流为准
*/
private static void feature2(){
IntStream.range(1, 100).parallel().peek(ParallelStream::printDebug).sequential().peek(ParallelStream::printDebug2).count();
}
/**
* 特性三 默认线程池与设置默认线程数
*/
private static void feature3(){
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","3");
IntStream.range(1, 100).parallel().forEach(ParallelStream::printDebug);
}
/**
* 特性四 自定义线程池 防止线程被阻塞
*/
private static void feature4(){
ForkJoinPool forkJoinPool = new ForkJoinPool();
forkJoinPool.submit(() -> IntStream.range(1, 100).parallel().forEach(ParallelStream::printDebug));
forkJoinPool.shutdown();
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private static void printDebug(int i){
// System.out.println(i);
System.out.println(Thread.currentThread().getName() + "debug:" + i);
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private static void printDebug2(int i){
System.err.println(i);
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
级联表达式与柯里化
简单来说就是将一个复杂表达式拆解为多个简单表达式,比如数学中的:
y=5! 可以等价为 y = 1 * 2 * 3 * 4 * 5
注意:这里涉及一个基础概念数据不变性,说白了就是匿名类中运用到外部变量时,外部变量需要是常量。细心的你会发现在级联表达式中外部变量均为常量。
/**
* 级联表达式和柯里化
*
* @author 旭旭
* @create 2018-08-12 1:09
**/
public class CurryDemo {
public static void main(String[] args) {
//级联表达式
Function<Integer,Function<Integer,Integer>> fun = x -> y -> x + y;
//柯里化(Currying)是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数
//柯里化的意义:函数标准化
//高阶函数:返回函数的函数
System.out.println(fun.apply(2).apply(3));
Function<Integer,Function<Integer,Function<Integer,Integer>>> fun2 = x -> y -> z -> x + y + z;
}
}
收集器(终止操作因为内容较多提出来说明)
终止操作中将数据以集合方式回收,可以对数据进行分类统计等。
/**
* 收集器
*
* @author 旭旭
* @create 2018-08-18 23:43
**/
public class CollectorsStream {
public static void main(String[] args) {
List<Student> students = new ArrayList<>();
students.add(new Student("一号",7,true,"一年级"));
students.add(new Student("二号",8,true,"二年级"));
students.add(new Student("三号",8,false,"二年级"));
students.add(new Student("四号",9,true,"三年级"));
students.add(new Student("五号",7,false,"一年级"));
students.add(new Student("六号",8,true,"二年级"));
students.add(new Student("七号",10,true,"四年级"));
// dataToList(students);
// summary(students);
// partitioning(students);
group(students);
}
/**
* 获取某一数据的集合
*/
public static void dataToList(List<Student> students){
List<Integer> list = students.stream().map(Student::getAge).collect(Collectors.toList());
System.out.println(list);
}
/**
* 获取某一数据的汇总值
*/
public static void summary(List<Student> students){
IntSummaryStatistics collect = students.stream().collect(Collectors.summarizingInt(Student::getAge));
System.out.println(collect);
}
/**
* 根据某一数据分类
*/
public static void partitioning(List<Student> students){
Map<Boolean, List<Student>> collect = students.stream().collect(Collectors.partitioningBy(x -> x.isGender()));
System.out.println(collect);
}
/**
* 根据某一数据分组
*/
public static void group(List<Student> students){
Map<String, Long> collect = students.stream().collect(Collectors.groupingBy(Student::getGrade, Collectors.counting()));
System.out.println(collect);
}
}
Stream特性
/**
* 流运行机制,基本特性
*
* @author 旭旭
* @create 2018-08-19 22:51
**/
public class FeatureStream {
public static void main(String[] args){
// feature123();
feature46();
// feature5();
}
/**
* 特性一 所有操作都是链式调用一个操作只迭代一次
* 特性二 每一个中间流返回一个新的流,里面的sourceStage都指向同一个地方就是Head
* 特性三 Head -> NextStage -> NextStage -> null
*/
public static void feature123(){
Random random = new Random();
Stream<Integer> integerStream = Stream.generate(random::nextInt)
.limit(500)
.peek(x -> System.out.println("peek -> " + x))
.filter(x -> {System.out.println("filter -> " + x);return x > 100000;});
integerStream.count();
}
/**
* 特性四 有状态操作(多个参数操作),会把无状态操作阶段分隔,单独处理。
* parallel / sequetial 这个2个操作也是中间操作,但是他们不创建新的流,而是修改
* Head的并行状态,所以多次调用时只会生效最后一个。
*/
public static void feature46(){
Random random = new Random();
Stream<Integer> integerStream = Stream.generate(random::nextInt)
.limit(500)
.peek(x -> System.out.println("peek -> " + x))
.filter(x -> {System.out.println("filter -> " + x);return x > 100000;})
.sorted((x,y) -> {System.out.println("sorted -> " + x);return x - y;})
.filter(x -> {System.out.println("filter -> " + x);return x > 100000;})
// .parallel()
;
integerStream.count();
}
/**
* 特性五 有状态操作并行环境下不一定能并行操作
*/
public static void feature5(){
Random random = new Random();
Stream<Integer> integerStream = Stream.generate(random::nextInt)
.limit(500)
.peek(x -> print("peek -> " + x))
.filter(x -> {print("filter -> " + x);return x > 100000;})
.sorted((x,y) -> {print("sorted -> " + x);return x - y;})
.filter(x -> {print("filter -> " + x);return x > 100000;})
.parallel();
integerStream.count();
}
private static void print(String x){
System.out.println(Thread.currentThread().getName() + " " + x);
}
}
工程地址
俗话说的好:光说不练假把式,这里附上工程连接拉,有需要的童靴可以拉下来玩玩。
https://gitee.com/softcx/functional_programming