爬虫爬取豆瓣的读书搜索页 java+jsoup+selenium
图书搜索页面:
https://book.douban.com/subject_search?search_text=9787535681942&cat=1001
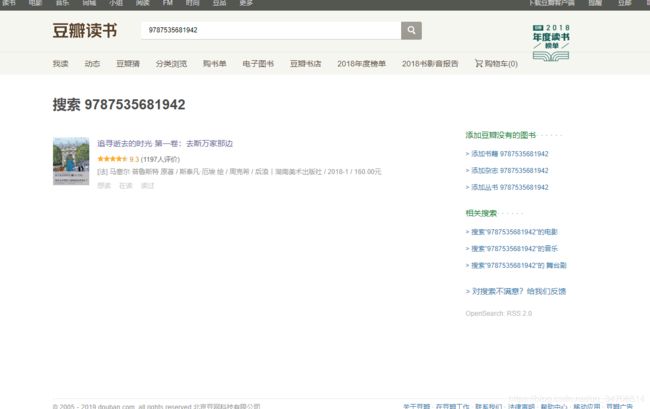
以前写的爬虫使用发现不能用了,检查发现豆瓣也有加密了,有可能是为了防止新手乱爬吧,一看到这个就觉得爬虫越来越不好做了,随便一个页面都有 js 加密。
仔细查看了各个页面发现只有搜索页面有加密,其余都是直接放在html上的,那么我们只要过了搜索其余都好说了
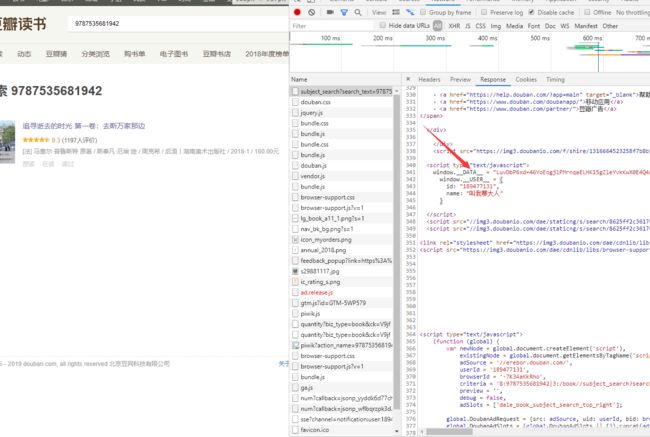
仔细看了看页面.也搜索了大佬的方法,发现图书数据都是在window._DATA_ 里,在网上找大佬的解密方法,调试了一天,各种尝试发现就是不好用.感觉自己进入了死胡同,于是弃用解密的方式,换一种思路来.采用selenium 一下下午搞出来了.
思路:
1. https://book.douban.com/subject_search?search_text=9787535681942&cat=1001
去搜索页面 找到搜索内容 从搜到的图书中获取到豆瓣的图书ID
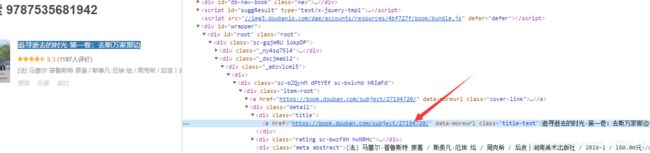
2. https://book.douban.com/subject/27194720/ 把这个id记起来 去到图书详情页. 在详情页 取到短评和评论的数量 和 总评分


3. https://book.douban.com/subject/27194720/comments/hot?p=1
继续拿图书的id 去拿短评 p是页数 从1开始 豆瓣每页20个
int pages = 短评数 % 20 == 0 ? (短评数 /20) : (短评数/20)+1; //计算有多少页然后取昵称 头像 评论时间 评论内容
4. https://book.douban.com/subject/27194720/reviews?start=0 评论页面 继续拿图书的id start是从第几开始
int start = (第几页 - 1) * 20; 由于评论都比较长,所有要去评论详情页面爬数据,拿到评论的详情ID

https://book.douban.com/review/9243340/ 详情id 去到详情页 可以爬
昵称 头像 评论时间 评论内容 评论标题
下面放源码
import com.aliyun.oss.OSSClient;
import com.tonglifang.common.utils.StrUtils;
import org.apache.commons.lang.StringUtils;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.openqa.selenium.By;
import org.openqa.selenium.Cookie;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.openqa.selenium.support.ui.ExpectedCondition;
import org.openqa.selenium.support.ui.WebDriverWait;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.regex.Pattern;
/**
* @Author: liangkesai
* @CreateDate: 2018/7/31 17:58
*/
public class Test {
private static final String SEARCH = "https://book.douban.com/subject_search?search_text="; //搜索地址
private static final String SHORTCOMMENT = "https://book.douban.com/subject/"; //短评地址
private static final String COMMENT = "https://book.douban.com/subject/"; //评论地址
private static final String COMMENT_DETAILS = "https://book.douban.com/review/"; //评论详情
private static final int limit = 20; //豆瓣页数
private static OSSClient client;
static {
client = new OSSClient("*", "*","*");
}
public static void main(String[] args) throws IOException{
search("9787534293467");
}
public static void search(String isbn) throws IOException {
String baseUrl = SEARCH + isbn+"&cat=1001"; //搜索的地址
System.setProperty("webdriver.chrome.driver", "D:/chromedriver_win32/chromedriver.exe");
//声明chromeoptions,主要是给chrome设置参数
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless"); //无浏览器模式
options.addArguments("--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
options.addArguments("--referer="+baseUrl);
WebDriver driver = new ChromeDriver(options);
driver.get(baseUrl); //访问基础地址
Cookie ck = new Cookie("bid","*"); //bid自己去cookie里找
driver.manage().addCookie(ck);
By by = By.cssSelector("div[id='root']");
waitForLoad(driver, by); //防止页面加载不完全
System.out.println("开始爬取ISBN: "+isbn);
String pageSource = driver.getPageSource();
Document baseDoc = Jsoup.parse(pageSource);
Elements baseEles = baseDoc.select("a[class=title-text]"); //所有搜索的结果
if(baseEles.size() > 0){ //有搜索记录 ,只去第一条 我的业务是取第一条你们也可以循环
String regEx="[^0-9]";
Pattern p = Pattern.compile(regEx);
Element baseEle = baseEles.get(0);
String bookName = baseEle.text(); //书名
String detailsUrl = baseEle.attr("href"); //详情链接
String doubanBookId = p.matcher(detailsUrl).replaceAll("").trim();
System.out.println("爬到图书: "+bookName);
System.out.println("图书ID: "+doubanBookId);
System.out.println("开始爬取评分");
//抓取评分
Connection detailsConn = setConnHeader(detailsUrl);
Document ratingDoc = detailsConn.get();
String score = ratingDoc.getElementsByClass("rating_num").text(); //评分
if(StringUtils.isBlank(score)){
score = "无评分";
}
System.out.println("评分: "+score);
//评分数量 用于算页数
Elements shortComment = ratingDoc.select("div[class=mod-hd] span[class=pl] a");
int shortCommentNum = Integer.parseInt(p.matcher(shortComment.text()).replaceAll("").trim());
System.out.println("短评数量: "+shortCommentNum);
if(shortCommentNum > 0){
System.out.println("开始爬取短评");
int pages = shortCommentNum%limit == 0 ? (shortCommentNum/limit) : (shortCommentNum/limit)+1; //总页数
for (int i= 1 ; i <= pages ; i++){
String shortUrl = SHORTCOMMENT + doubanBookId+ "/comments/hot?p="+i;
Connection shortCommentConn = setConnHeader(shortUrl);
Document shortCommentDoc = shortCommentConn.get();
Elements shortCommentElements = shortCommentDoc.getElementsByClass("comment-item"); //短评组
for (Element element : shortCommentElements){
String avatar = element.select("div[class=avatar] a img").attr("src"); //头像
String nickName = element.select("div[class=avatar] a").attr("title"); //昵称
String shortCommentTime = element.select("div[class=comment] h3 span[class=comment-info] span").eq(1).text(); //评论时间
String shortComments = element.select("div[class=comment] p[class=comment-content] span[class=short]").text(); //评论内容
//头像转存OSS
avatar = ossByDoubanAvatar(avatar);
System.out.println(avatar+" | "+nickName + " | "+shortCommentTime + " | "+shortComments);
}
}
System.out.println("结束爬取短评");
}
Elements comment = ratingDoc.select("section[class=reviews mod book-content] header span[class=pl] a");
int commentNum = Integer.parseInt(p.matcher(comment.text()).replaceAll("").trim());
System.out.println("评论数量: "+commentNum);
if(commentNum > 0){
System.out.println("开始爬取评论");
int pages = commentNum%limit == 0 ? (commentNum/limit) : (commentNum/limit)+1; //总页数
for (int i= 1 ; i<= pages ; i++){
int offset = (i - 1) * limit;
String commentUrl = COMMENT + doubanBookId+ "/reviews?start="+offset;
Connection commentConn = setConnHeader(commentUrl);
Document commentDoc = commentConn.get();
Elements commentElements = commentDoc.getElementsByClass("main review-item"); //长评组
for (Element element : commentElements){
String commentId = element.attr("id");
String commentDetailsUrl = COMMENT_DETAILS + commentId;
Connection commentDetailsConn = setConnHeader(commentDetailsUrl);
Document commentDetailsDoc = commentDetailsConn.get();
String avatar = commentDetailsDoc.select("a[class=avatar author-avatar left] img").attr("src"); //头像
String nickName = commentDetailsDoc.select("header[class=main-hd] a").eq(0).select("span").text(); //昵称
String commentTime = commentDetailsDoc.select("header[class=main-hd] span[class=main-meta]").text(); //评论时间
String commentTitle = commentDetailsDoc.select("div[class=article] h1 span").text(); //评论标题
//头像转存OSS
avatar = ossByDoubanAvatar(avatar);
System.out.println(avatar+" | "+ nickName+" | "+ commentTime +" | "+commentTitle);
String comments = commentDetailsDoc.getElementById("link-report").select("div[class=review-content clearfix]").toString();
Elements imgs = commentDetailsDoc.getElementById("link-report").select("div[class=review-content clearfix] img"); //评论里的所有图
for (Element e : imgs){
String src = e.attr("src");
comments = comments.replaceAll(src,ossByDoubanAvatar(src));
}
System.out.println(comments);
System.out.println("*************************************一条评论结束*************************************");
}
}
System.out.println("结束爬取评论");
}
}
driver.quit();
System.out.println("========================================================================================================");
}
/**
* 等待元素加载,10s超时
* @param driver
* @param by
*/
public static void waitForLoad(final WebDriver driver, final By by){
new WebDriverWait(driver, 10).until(new ExpectedCondition() {
public Boolean apply(WebDriver d) {
WebElement element = driver.findElement(by);
if (element != null){
return true;
}
return false;
}
});
}
/**
* //头像转存OSS
* @param avatar 豆瓣头像
* @return
* @throws IOException
*/
public static String ossByDoubanAvatar(String avatar) throws IOException {
//new一个URL对象
URL url1 = new URL(avatar);
//打开链接
HttpURLConnection conn = (HttpURLConnection)url1.openConnection();
//设置请求方式为"GET"
conn.setRequestMethod("GET");
//超时响应时间为5秒
conn.setConnectTimeout(5 * 1000);
//通过输入流获取图片数据
InputStream inputStream = conn.getInputStream();
//头像转存OSS
String path = "douban/avatar/"+StrUtils.getRandomStringByLength(36)+".jpg";
client.putObject("whtlf-sonspace", path, inputStream);
return "https://*.oss-cn-beijing.aliyuncs.com/"+path;
}
/**
* 设置表头
* @param url
* @return
*/
private static Connection setConnHeader(String url){
Connection conn = Jsoup.connect(url).timeout(5000);
conn.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3");
conn.header("Accept-Encoding", "gzip, deflate, br");
conn.header("Accept-Language", "zh-CN,zh;q=0.9,en;q=0.8");
conn.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
conn.header("referer",url);
conn.header("Cookie","*");
return conn;
}
} bid

我把爬到的数据里的所有图片进行了 转存. 防止防盗链 , 自己用删掉转存代码就行