Java 基础知识回顾(一)
java基础第一章节
1.面向过程和面向对象的区别
面向过程
优点: 性能比面向对象高。因为类调用时需要实例化,开销比较大,比较消耗资源,所以当性能是最重要的考量因素的时候,比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发
缺点: 没有面向对象易维护、易复用、易扩展
面向对象
优点: 易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护
缺点: 性能比面向过程低
2.java语言特点
3.JDK和JRE、JVM
JVM是运行JAVA程序的虚拟机。JVM有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。
什么是字节码?采用字节码的好处是什么?
在 Java 中,JVM可以理解的代码就叫做字节码(即扩展名为 .class 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java程序无须重新编译便可在多种不同操作系统的计算机上运行。
Java 程序从源代码到运行一般有下面3步:
4.oracle JDK和 OPEN JDK
可能在看这个问题之前很多人和我一样并没有接触和使用过 OpenJDK 。那么Oracle和OpenJDK之间是否存在重大差异?下面我通过收集到的一些资料,为你解答这个被很多人忽视的问题。
对于Java 7,没什么关键的地方。OpenJDK项目主要基于Sun捐赠的HotSpot源代码。此外,OpenJDK被选为Java 7的参考实现,由Oracle工程师维护。关于JVM,JDK,JRE和OpenJDK之间的区别,Oracle博客帖子在2012年有一个更详细的答案:
问:OpenJDK存储库中的源代码与用于构建Oracle JDK的代码之间有什么区别?
答:非常接近 - 我们的Oracle JDK版本构建过程基于OpenJDK 7构建,只添加了几个部分,例如部署代码,其中包括Oracle的Java插件和Java WebStart的实现,以及一些封闭的源代码派对组件,如图形光栅化器,一些开源的第三方组件,如Rhino,以及一些零碎的东西,如附加文档或第三方字体。展望未来,我们的目的是开源Oracle JDK的所有部分,除了我们考虑商业功能的部分。
总结:
Oracle JDK版本将每三年发布一次,而OpenJDK版本每三个月发布一次;
OpenJDK 是一个参考模型并且是完全开源的,而Oracle JDK是OpenJDK的一个实现,并不是完全开源的;
Oracle JDK 比 OpenJDK 更稳定。OpenJDK和Oracle JDK的代码几乎相同,但Oracle JDK有更多的类和一些错误修复。因此,如果您想开发企业/商业软件,我建议您选择Oracle JDK,因为它经过了彻底的测试和稳定。某些情况下,有些人提到在使用OpenJDK 可能会遇到了许多应用程序崩溃的问题,但是,只需切换到Oracle JDK就可以解决问题;
在响应性和JVM性能方面,Oracle JDK与OpenJDK相比提供了更好的性能;
Oracle JDK不会为即将发布的版本提供长期支持,用户每次都必须通过更新到最新版本获得支持来获取最新版本;
Oracle JDK根据二进制代码许可协议获得许可,而OpenJDK根据GPL v2许可获得许可。
5.Java和C++区别
我知道很多人没学过 C++,但是面试官就是没事喜欢拿咱们 Java 和 C++ 比呀!没办法!!!就算没学过C++,也要记下来!
都是面向对象的语言,都支持封装、继承和多态
Java 不提供指针来直接访问内存,程序内存更加安全
Java 的类是单继承的,C++ 支持多重继承;虽然 Java 的类不可以多继承,但是接口可以多继承。
Java 有自动内存管理机制,不需要程序员手动释放无用内存
6.什么是 Java 程序的主类 应用程序和小程序的主类有何不同
一个程序中可以有多个类,但只能有一个类是主类。在 Java 应用程序中,这个主类是指包含 main()方法的类。而在 Java 小程序中,这个主类是一个继承自系统类 JApplet 或 Applet 的子类。应用程序的主类不一定要求是 public 类,但小程序的主类要求必须是 public 类。主类是 Java 程序执行的入口点。
7.Java 应用程序与小程序之间有那些差别
简单说应用程序是从主线程启动(也就是 main() 方法)。applet 小程序没有main方法,主要是嵌在浏览器页面上运行(调用init()线程或者run()来启动),嵌入浏览器这点跟 flash 的小游戏类似。
8. 字符型常量和字符串常量的区别?
形式上: 字符常量是单引号引起的一个字符; 字符串常量是双引号引起的若干个字符
含义上: 字符常量相当于一个整形值( ASCII 值),可以参加表达式运算; 字符串常量代表一个地址值(该字符串在内存中存放位置)
占内存大小 字符常量只占2个字节; 字符串常量占若干个字节(至少一个字符结束标志) (注意: char在Java中占两个字节)
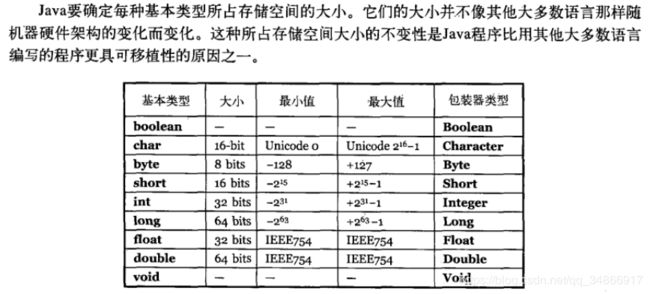
9. 构造器 Constructor 是否可被 override?
在讲继承的时候我们就知道父类的私有属性和构造方法并不能被继承,所以 Constructor 也就不能被 override(重写),但是可以 overload(重载),所以你可以看到一个类中有多个构造函数的情况。
10. 重载和重写的区别
重载: 发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同,发生在编译时。
重写: 发生在父子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为 private 则子类就不能重写该方法。
11. Java 面向对象编程三大特性: 封装 继承 多态
封装
封装把一个对象的属性私有化,同时提供一些可以被外界访问的属性的方法,如果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没有提供给外界访问的方法,那么这个类也没有什么意义了。
继承
继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承我们能够非常方便地复用以前的代码。
关于继承如下 3 点请记住:
子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,只是拥有。
子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
子类可以用自己的方式实现父类的方法。(以后介绍)。
多态
所谓多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量到底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
在Java中有两种形式可以实现多态:继承(多个子类对同一方法的重写)和接口(实现接口并覆盖接口中同一方法)。
12. String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?
可变性
简单的来说:String 类中使用 final 关键字修饰字符数组来保存字符串,private final char value[],所以 String 对象是不可变的。而StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串char[]value 但是没有用 final 关键字修饰,所以这两种对象都是可变的。
StringBuilder 与 StringBuffer 的构造方法都是调用父类构造方法也就是 AbstractStringBuilder 实现的,大家可以自行查阅源码。
AbstractStringBuilder.java
abstract class AbstractStringBuilder implements Appendable, CharSequence {
char[] value;
int count;
AbstractStringBuilder() {
}
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
13. 自动装箱与拆箱
装箱:将基本类型用它们对应的引用类型包装起来;
拆箱:将包装类型转换为基本数据类型;
14. 在一个静态方法内调用一个非静态成员为什么是非法的?
静态方法不可以通过对象调用,因此在静态方法中,不能调用其他非静态变量,也不可以访问非静态变量成员。
15. 在 Java 中定义一个不做事且没有参数的构造方法的作用
Java 程序在执行子类的构造方法之前,如果没有用 super() 来调用父类特定的构造方法,则会调用父类中“没有参数的构造方法”。因此,如果父类中只定义了有参数的构造方法,而在子类的构造方法中又没有用 super() 来调用父类中特定的构造方法,则编译时将发生错误,因为 Java 程序在父类中找不到没有参数的构造方法可供执行。解决办法是在父类里加上一个不做事且没有参数的构造方法。
16. import java和javax有什么区别?
刚开始的时候 JavaAPI 所必需的包是 java 开头的包,javax 当时只是扩展 API 包来使用。然而随着时间的推移,javax 逐渐地扩展成为 Java API 的组成部分。但是,但是,将扩展从 javax 包移动到 java 包确实太麻烦了,最终会破坏一堆现有的代码。因此,最终决定 javax 包将成为标准API的一部分。
所以,实际上java和javax没有区别。这都是一个名字。
17. 接口和抽象类的区别是什么?
接口的方法默认是 public,所有方法在接口中不能有实现(Java 8 开始接口方法可以有默认实现),而抽象类可以有非抽象的方法。
接口中的实例变量默认是 final 类型的,而抽象类中则不一定。
一个类可以实现多个接口,但最多只能实现一个抽象类。
一个类实现接口的话要实现接口的所有方法,而抽象类不一定。
接口不能用 new 实例化,但可以声明,但是必须引用一个实现该接口的对象。从设计层面来说,抽象是对类的抽象,是一种模板设计,而接口是对行为的抽象,是一种行为的规范。
备注:在JDK8中,接口也可以定义静态方法,可以直接用接口名调用。实现类和实现是不可以调用的。如果同时实现两个接口,接口中定义了一样的默认方法,则必须重写,不然会报错。
详见issue:https://github.com/Snailclimb/JavaGuide/issues/146)
19. 创建一个对象用什么运算符?对象实体与对象引用有何不同?
new运算符,new创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。一个对象引用可以指向0个或1个对象(一根绳子可以不系气球,也可以系一个气球);一个对象可以有n个引用指向它(可以用n条绳子系住一个气球)。
20. 什么是方法的返回值?返回值在类的方法里的作用是什么?
方法的返回值是指我们获取到的某个方法体中的代码执行后产生的结果!(前提是该方法可能产生结果)。返回值的作用:接收出结果,使得它可以用于其他的操作!
21. 一个类的构造方法的作用是什么? 若一个类没有声明构造方法,该程序能正确执行吗? 为什么?
主要作用是完成对类对象的初始化工作。可以执行。因为一个类即使没有声明构造方法也会有默认的不带参数的构造方法。
- 构造方法有哪些特性?
名字与类名相同。
没有返回值,但不能用void声明构造函数。
生成类的对象时自动执行,无需调用。 - 静态方法和实例方法有何不同
在外部调用静态方法时,可以使用"类名.方法名"的方式,也可以使用"对象名.方法名"的方式。而实例方法只有后面这种方式。也就是说,调用静态方法可以无需创建对象。
静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制。
- 对象的相等与指向他们的引用相等,两者有什么不同?
对象的相等,比的是内存中存放的内容是否相等。而引用相等,比较的是他们指向的内存地址是否相等。
String 中的 equals 方法是被重写过的,因为 object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
27. hashCode 与 equals (重要)
面试官可能会问你:“你重写过 hashcode 和 equals 么,为什么重写equals时必须重写hashCode方法?”
hashCode()介绍
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在JDK的Object.java中,这就意味着Java中的任何类都包含有hashCode() 函数。
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
为什么要有 hashCode
我们先以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode: 当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的Java启蒙书《Head first java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
通过我们可以看出:hashCode() 的作用就是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。**hashCode() 在散列表中才有用,在其它情况下没用。**在散列表中hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。
hashCode()与equals()的相关规定
如果两个对象相等,则hashcode一定也是相同的
两个对象相等,对两个对象分别调用equals方法都返回true
两个对象有相同的hashcode值,它们也不一定是相等的
因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖
hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
推荐阅读:Java hashCode() 和 equals()的若干问题解答
-
为什么Java中只有值传递?
为什么Java中只有值传递? -
简述线程、程序、进程的基本概念。以及他们之间关系是什么?
线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享同一块内存空间和一组系统资源,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
程序是含有指令和数据的文件,被存储在磁盘或其他的数据存储设备中,也就是说程序是静态的代码。
进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。简单来说,一个进程就是一个执行中的程序,它在计算机中一个指令接着一个指令地执行着,同时,每个进程还占有某些系统资源如CPU时间,内存空间,文件,文件,输入输出设备的使用权等等。换句话说,当程序在执行时,将会被操作系统载入内存中。 线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。从另一角度来说,进程属于操作系统的范畴,主要是同一段时间内,可以同时执行一个以上的程序,而线程则是在同一程序内几乎同时执行一个以上的程序段。
31 关于 final 关键字的一些总结
final关键字主要用在三个地方:变量、方法、类。
对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。
当用final修饰一个类时,表明这个类不能被继承。final类中的所有成员方法都会被隐式地指定为final方法。
使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升(现在的Java版本已经不需要使用final方法进行这些优化了)。类中所有的private方法都隐式地指定为final。
32 Java 中的异常处理
在 Java 中,所有的异常都有一个共同的祖先java.lang包中的 Throwable类。Throwable: 有两个重要的子类:Exception(异常) 和 Error(错误) ,二者都是 Java 异常处理的重要子类,各自都包含大量子类。
Error(错误):是程序无法处理的错误,表示运行应用程序中较严重问题。大多数错误与代码编写者执行的操作无关,而表示代码运行时 JVM(Java 虚拟机)出现的问题。例如,Java虚拟机运行错误(Virtual MachineError),当 JVM 不再有继续执行操作所需的内存资源时,将出现 OutOfMemoryError。这些异常发生时,Java虚拟机(JVM)一般会选择线程终止。
这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,如Java虚拟机运行错误(Virtual MachineError)、类定义错误(NoClassDefFoundError)等。这些错误是不可查的,因为它们在应用程序的控制和处理能力之 外,而且绝大多数是程序运行时不允许出现的状况。对于设计合理的应用程序来说,即使确实发生了错误,本质上也不应该试图去处理它所引起的异常状况。在 Java中,错误通过Error的子类描述。
Exception(异常):是程序本身可以处理的异常。Exception 类有一个重要的子类 RuntimeException。RuntimeException 异常由Java虚拟机抛出。NullPointerException(要访问的变量没有引用任何对象时,抛出该异常)、ArithmeticException(算术运算异常,一个整数除以0时,抛出该异常)和 ArrayIndexOutOfBoundsException (下标越界异常)。
注意:异常和错误的区别:异常能被程序本身可以处理,错误是无法处理。
Throwable类常用方法
public string getMessage():返回异常发生时的详细信息
public string toString():返回异常发生时的简要描述
public string getLocalizedMessage():返回异常对象的本地化信息。使用Throwable的子类覆盖这个方法,可以声称本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与getMessage()返回的结果相同
public void printStackTrace():在控制台上打印Throwable对象封装的异常信息
异常处理总结
**try 块:**用于捕获异常。其后可接零个或多个catch块,如果没有catch块,则必须跟一个finally块。
**catch 块:**用于处理try捕获到的异常。
**finally 块:**无论是否捕获或处理异常,finally块里的语句都会被执行。当在try块或catch块中遇到return语句时,finally语句块将在方法返回之前被执行。
在以下4种特殊情况下,finally块不会被执行:
在finally语句块第一行发生了异常。 因为在其他行,finally块还是会得到执行
在前面的代码中用了System.exit(int)已退出程序。 exit是带参函数 ;若该语句在异常语句之后,finally会执行
程序所在的线程死亡。
关闭CPU。
下面这部分内容来自issue:https://github.com/Snailclimb/JavaGuide/issues/190。
关于返回值:
如果try语句里有return,返回的是try语句块中变量值。 详细执行过程如下:
如果有返回值,就把返回值保存到局部变量中;
执行jsr指令跳到finally语句里执行;
执行完finally语句后,返回之前保存在局部变量表里的值。
如果try,finally语句里均有return,忽略try的return,而使用finally的return.
33java序列化中如果有些字段不想进行序列化,怎么办?
对于不想进行序列化的变量,使用transient关键字修饰
transient关键字的作用是:阻止实例中那些用此关键字修饰的变量序列化;当对象被反序列化时,被transient修饰的变量值不会被持久化和恢复。transient只能修饰变量,不能修饰类和方法。
transient暂住某地的人;过往旅客;临时工
34键盘输入常用的两种方法
方法一
Scanner input=new Scanner(System.in);
String s=input.nextLine();
input.close();
方法二
BufferedReader input=new BufferedReader (new InputStreamReader(System.in);
String s=input.readLine();
JAVA中IO流分为几种?BIO,NIO,AIO有什么区别?
- 按照流向流,分为输入和输出流
- 按照操作分为字符流和字节流
- 按照流的角色分为节点流和处理流
BIO,NIO,AIO 有什么区别?
BIO (Blocking I/O): 同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
并发量低下
NIO (New I/O): NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了NIO框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发
并发量高
AIO (Asynchronous I/O): AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。AIO 是异步IO的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO操作本身是同步的。查阅网上相关资料,我发现就目前来说 AIO 的应用还不是很广泛,Netty 之前也尝试使用过 AIO,不过又放弃了。