金融量化 - scipy 教程(01)

前篇已经大致介绍了NumPy,接下来让我们看看SciPy能做些什么。NumPy替我们搞定了向量和矩阵的相关操作,基本上算是一个高级的科学计算器。SciPy基于NumPy提供了更为丰富和高级的功能扩展,在统计、优化、插值、数值积分、时频转换等方面提供了大量的可用函数,基本覆盖了基础科学计算相关的问题。
在量化分析中,运用最广泛的是统计和优化的相关技术,本篇重点介绍SciPy中的统计和优化模块,其他模块在随后系列文章中用到时再做详述。
本篇会涉及到一些矩阵代数,如若感觉不适,可考虑跳过第三部分或者在理解时简单采用一维的标量代替高维的向量。
首先还是导入相关的模块,我们使用的是SciPy里面的统计和优化部分:
import numpy as np
import scipy.stats as stats
import scipy.optimize as opt
二、统计部分
2.1 生成随机数
我们从生成随机数开始,这样方便后面的介绍。生成n个随机数可用rv_continuous.rvs(size=n)或rv_discrete.rvs(size=n),其中rv_continuous表示连续型的随机分布,如均匀分布(uniform)、正态分布(norm)、贝塔分布(beta)等;rv_discrete表示离散型的随机分布,如伯努利分布(bernoulli)、几何分布(geom)、泊松分布(poisson)等。我们生成10个[0, 1]区间上的随机数和10个服从参数a=4,b=2的贝塔分布随机数:
rv_unif = stats.uniform.rvs(size=10)
rv_unif
rv_beta = stats.beta.rvs(size=10, a=4, b=2)
rv_beta

在每个随机分布的生成函数里,都内置了默认的参数,如均匀分布的上下界默认是0和1。可是一旦需要修改这些参数,每次生成随机都要敲这么老长一串有点麻烦,能不能简单点?SciPy里头有一个Freezing的功能,可以提供简便版本的命令。SciPy.stats支持定义出某个具体的分布的对象,我们可以做如下的定义,让beta直接指代具体参数a=4和b=2的贝塔分布。为让结果具有可比性,这里指定了随机数的生成种子,由NumPy提供。
np.random.seed(seed=2015)
rv_beta = stats.beta.rvs(size=10, a=4, b=2)
np.random.seed(seed=2015)
beta = stats.beta(a=4, b=2)
2.2 假设检验
好了,现在我们生成一组数据,并查看相关的统计量(相关分布的参数可以在这里查到):
norm_dist = stats.norm(loc=0.5, scale=2)
n = 200
dat = norm_dist.rvs(size=n)
print("mean of data is: " + str(np.mean(dat)))
print("median of data is: " + str(np.median(dat)))
print("standard deviation of data is: " + str(np.std(d
假设这个数据是我们获取到的实际的某些数据,如股票日涨跌幅,我们对数据进行简单的分析。最简单的是检验这一组数据是否服从假设的分布,如正态分布。这个问题是典型的单样本假设检验问题,最为常见的解决方案是采用K-S检验( Kolmogorov-Smirnov test)。单样本K-S检验的原假设是给定的数据来自和原假设分布相同的分布,在SciPy中提供了kstest函数,参数分别是数据、拟检验的分布名称和对应的参数:
mu = np.mean(dat)
sigma = np.std(dat)
stat_val, p_val = stats.kstest(dat, 'norm', (mu, sigma))
print('KS-statistic D = %6.3f p-value = %6.4f' % (stat_val
假设检验的p-value值很大(在原假设下,p-value是服从[0, 1]区间上的均匀分布的随机变量,可参考 http://en.wikipedia.org/wiki/P-value ),因此我们接受原假设,即该数据通过了正态性的检验。在正态性的前提下,我们可进一步检验这组数据的均值是不是0。典型的方法是t检验(t-test),其中单样本的t检验函数为ttest_1samp:
stat_val, p_val = stats.ttest_1samp(dat, 0)
print('One-sample t-statistic D = %6.3f, p-value = %6.
我们看到p-value<0.05,即给定显著性水平0.05的前提下,我们应拒绝原假设:数据的均值为0。我们再生成一组数据,尝试一下双样本的t检验(ttest_ind):
norm_dist2 = stats.norm(loc=-0.2, scale=1.2)
dat2 = norm_dist2.rvs(size=100)
stat_val, p_val = stats.ttest_ind(dat, dat2, equal_var=False)
print('Two-sample t-statistic D = %6.3f, p-value = %6.4f'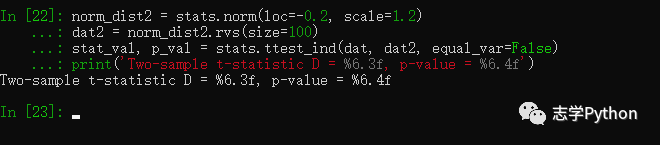
注意,这里我们生成的第二组数据样本大小、方差和第一组均不相等,在运用t检验时需要使用Welch's t-test,即指定ttest_ind中的equal_var=False。我们同样得到了比较小的p-value$,在显著性水平0.05的前提下拒绝原假设,即认为两组数据均值不等。
stats还提供其他大量的假设检验函数,如bartlett和levene用于检验方差是否相等;anderson_ksamp用于进行Anderson-Darling的K-样本检验等。
2.3 其他函数
有时需要知道某数值在一个分布中的分位,或者给定了一个分布,求某分位上的数值。这可以通过cdf和ppf函数完成:
g_dist = stats.gamma(a=2)
print("quantiles of 2, 4 and 5:")
print(g_dist.cdf([2, 4, 5]))
print("Values of 25%, 50% and 90%:")
print(g_dist.pdf([0.25, 0.5, 0.95]))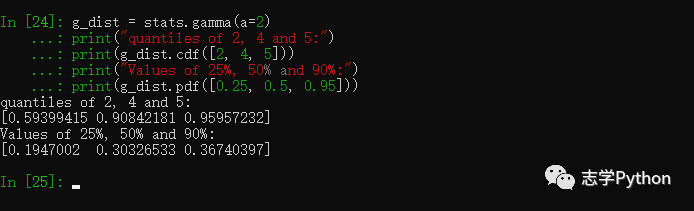
对于一个给定的分布,可以用moment很方便的查看分布的矩信息,例如我们查看N(0,1)的六阶原点矩:
stats.norm.moment(6, loc=0, scale=1)
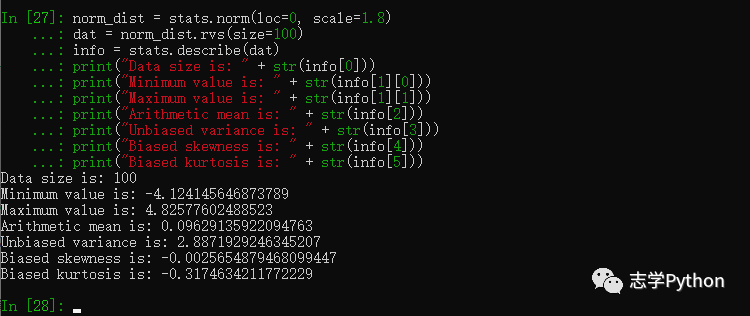
describe函数提供对数据集的统计描述分析,包括数据样本大小,极值,均值,方差,偏度和峰度:
norm_dist = stats.norm(loc=0, scale=1.8)
dat = norm_dist.rvs(size=100)
info = stats.describe(dat)
print("Data size is: " + str(info[0]))
print("Minimum value is: " + str(info[1][0]))
print("Maximum value is: " + str(info[1][1]))
print("Arithmetic mean is: " + str(info[2]))
print("Unbiased variance is: " + str(info[3]))
print("Biased skewness is: " + str(info[4]))
print("Biased kurtosis is: " + str(info[5]))
当我们知道一组数据服从某些分布的时候,可以调用fit函数来得到对应分布参数的极大似然估计(MLE, maximum-likelihood estimation)。以下代码示例了假设数据服从正态分布,用极大似然估计分布参数:
norm_dist = stats.norm(loc=0, scale=1.8)
dat = norm_dist.rvs(size=100)
mu, sigma = stats.norm.fit(dat)
print("MLE of data mean:" + str(mu))
print("MLE of data standard deviation:" + str(sigma))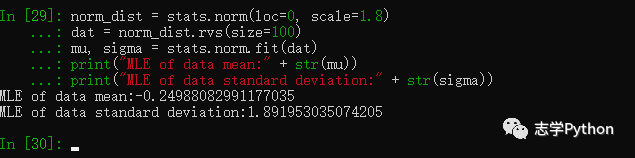
pearsonr和spearmanr可以计算Pearson和Spearman相关系数,这两个相关系数度量了两组数据的相互线性关联程度:
norm_dist = stats.norm()
dat1 = norm_dist.rvs(size=100)
exp_dist = stats.expon()
dat2 = exp_dist.rvs(size=100)
cor, pval = stats.pearsonr(dat1, dat2)
print("Pearson correlation coefficient: " + str(cor))
cor, pval = stats.pearsonr(dat1, dat2)
print("Spearman's rank correlation coefficient: " + str(cor))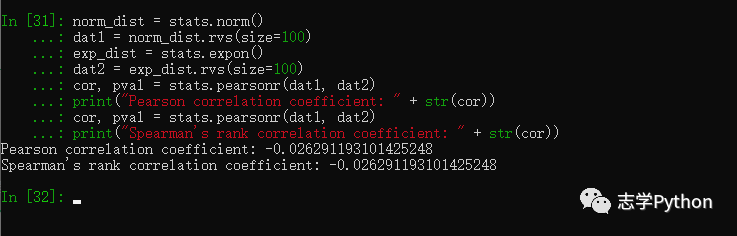
其中的p-value表示原假设(两组数据不相关)下,相关系数的显著性。最后,在分析金融数据中使用频繁的线性回归在SciPy中也有提供,我们来看一个例子:
x = stats.chi2.rvs(3, size=50)
y = 2.5 + 1.2 * x + stats.norm.rvs(size=50, loc=0, scale=1.5)
slope, intercept, r_value, p_value, std_err = stats.linregress(x, y)
print("Slope of fitted model is:" , slope)
print("Intercept of fitted model is:", intercept)
print("R-squared:", r_value**2)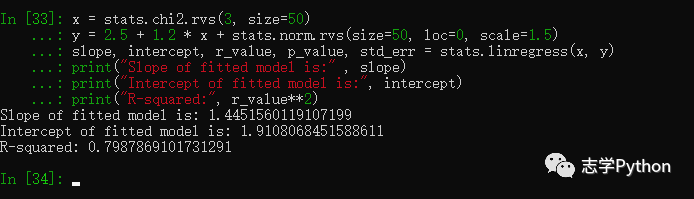
在前面的链接中,可以查到大部分stat中的函数,本节权作简单介绍,挖掘更多功能的最好方法还是直接读原始的文档。另外,StatsModels( http://statsmodels.sourceforge.net )模块提供了更为专业,更多的统计相关函数。若在SciPy没有满足需求,可以采用StatsModels。
