从0开始 - 完整搭建Spark+IDEA+Maven开发环境(基于Linux)
前言
本章将完整记录博主从0开始搭建Spark+IDEA的开发环境。
首先你需要安装Ubuntu 系统,如果未安装可以网上搜索教程即可。
准备maven 和IDEA的安装包:

链接:https://pan.baidu.com/s/1bPqf24DfZe-YpSrBrfIOKQ
提取码:3110
注:需要联网
1. JDK的安装
解压安装包,添加环境变量:
vim ~/.bashrc
JAVA_HOME=/usr/local/java/jdk1.8.0_152
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME CLASSPATH PATH
source ~/.bashrc

2. Maven的安装
安装可参考:https://blog.csdn.net/hbtj_1216/article/details/78815106
另外附上博主的settings.xml,直接覆盖即可,配置了阿里源,下载比国外快。
注:默认Maven 的依赖文件仓库是在~/.m2下(所以要保证你的Linux用户目录的空间足够大,至少以G为单位),如:

如果你的用户目录空间不够,可以修改settings.xml其存放位置(目录需先创建):

3. IDEA的安装
解压后进入目录,执行:
![]()
IDEA简单配置可参考:https://blog.csdn.net/qq_38038143/article/details/89066180
4. Scala的安装
解压
解压路径自己随意:
tar -zxvf scala-2.12.8.tgz -C /home/hadoop/
配置环境变量:
vim ~/.bashrc
# Scala
export PATH=$PATH:/home/hadoop/scala-2.12.8/bin
执行 scala 可成功进入即成功安装。
5. Spark的安装
解压
下载完成后,上传到Linux,博主使用的是Ubuntu16.04,解压文件,并修改名称:
tar -xf spark-2.4.0-bin-hadoop2.7.tgz -C /home/hadoop
cd /home/hadoop
mv spark-2.0.2-bin-hadoop2.7.tgz spark-2.0.2
配置环境变量
vim ~/.bashrc
文件末尾加入如下信息:
# Spark
export SPARK_HOME=/home/hadoop/spark-2.0.2
export PATH=$PATH:$SPARK_HOME/bin/
执行 spark-shell 可成功进入即成功安装。
6. 构建第一个Spark Streaming程序
-
左上角File,新建一个Project,选择Maven:

-
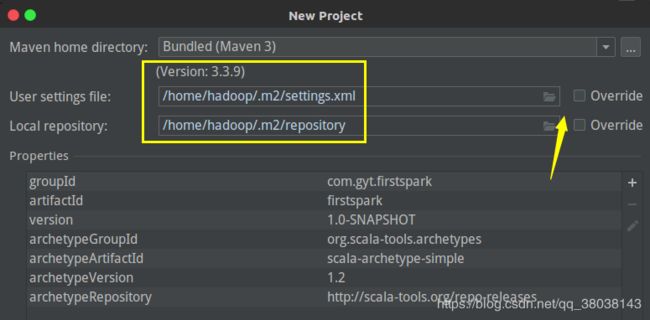
设置相应信息:

-
Maven仓库的选择:
注:如果你需改更改,需要勾选后面的Override
-
Finish:

-
创建成功:

-
依赖设置(pom.xml):
修改Scala的版本:

修改为2.12.8。
然后删除一些目前没有必要的依赖,这里给出配置如下(build及以下的没有更改):
4.0.0
com.gyt.firstspark
firstspark
1.0-SNAPSHOT
2008
2.12.8
2.4.0
org.apache.spark
spark-streaming_2.12
${spark.version}
com.fasterxml.jackson.module
jackson-module-scala_2.12
2.6.7.1
org.scala-lang
scala-library
${scala.version}
org.specs
specs
1.2.5
test
。。。。。。
注意看右下角有个弹窗,点击imoprt(或者手动选择IDEA上方选项栏下的Rebuild Project):

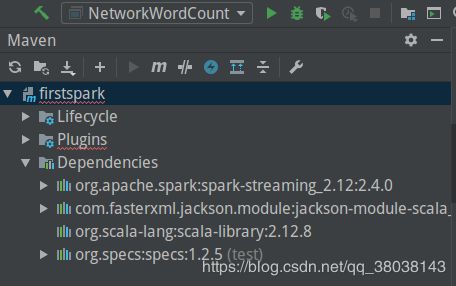
窗口显示依赖:
下载完成后,效果如下:
-
设置项目环境:
点击左上角的选项:
点中main目录下的scala,然后点击上方的Sources。点中test目录,然后点击上面的Tests:

设置Scala资源:

选择下方的Browse 选项,选择安装的目录:

效果:
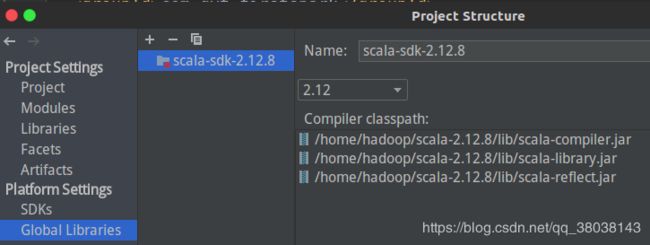
Apply and ok。 -
创建NetworkWordCount:


完整代码:
ssc.socketTextStream(“master”, 9999) 主机名根据自己设置。
package com.gyt.firstspark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object NetworkWordCount {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
sparkConf.setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(4))
val lines = ssc.socketTextStream("master", 9999)
val results = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)
results.print()
ssc.start()
ssc.awaitTermination()
}
}
- 运行程序:
删除com.gyt.firstspark 下的App:


先在终端启动nc -lk 9999:

然后右键Run 运行程序:

运行后,可能报如下错误:
![]()
解决办法:删除test 目录下的MySpec

再次运行:

在 nc 中输入单词:


另外你可以看到,控制台输出了很多INFO信息,如何去掉:
main 目录下创建resources 目录,并将saprk按照目录下conf/log4j xxx 复制过来(网盘链接中已有):
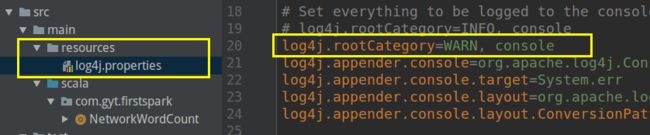
Project Structure中设置:

效果:

至此,一个可用的Spark Streaming开发环境已经搭建成功。
更多示例
https://blog.csdn.net/qq_38038143/article/details/89928768
GitHub 完整项目:
https://github.com/GYT0313/Spark-Learning/tree/master/sparkstream