C++11基础知识点
1998年是C++标准委员会成立的第一年,以后每五年视实际需要更新一次标准,它开发于1998年并于2003年更新,统称为C++98或者C++03,国际标准化组织于2001年9月1号出版发布ISO/IEC 14882:2011,称为C++11。相比于C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。相比较而言,C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更强大,而且能提升程序员的开发效率。
此篇文章我只对C++11的基础知识做简要总结。
1.统一的初始化
什么叫做统一的初始化呢?例如:我们以前在往vector中插入数据的时候,只能一个元素一个元素调用push_back进行插入,现在我们可以想数组初始化的方式一样来给vector进行初始化,例如:
以前的做法(很不方便):
int main()
{
vector v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
vector::iterator i=v.begin();
while(i!=v.end())
{
cout<<*i<< " ";
++i;
}
} 现在我们可以对自定义类型来进行统一初始化:
vector v{1,2,3,4}; C++11扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和用户自定义的类型,使用初始化列表时,可添加等号(=),也可不添加。
2.关键字auto和decltype
在以前我们在C语言的见过auto这个关键字,使用auto定义的变量,我们成为自动变量(具有自动存储器的局部变量);
在C++11中,它被赋予了新的含义,auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。 (在这里想到了我们的python大法,定义变量从来不用写类型,这些都是编译器自动去识别的) ,来看一个例子:
void test2()
{
int a=10;
auto b=10;
auto c=1.1;
auto str="hello";
//RTTI
cout<运行结果:

这好像也没有什么意思吧!!接下来就是体会auto优势的地方了
map dict{ { "insert", "插入" }, { "sort", "排序" } };
map::iterator dit = dict.begin();
while (dit != dict.end())
{
cout << dit->first << ":" << dit->second << endl;
++dit;
}
cout << endl; 以前我们在遍历容器的时候还要这样遍历,好麻烦呀,还容易写错,现在我们这样就可以轻松搞定。
auto dit2 = dict.begin();
while (dit2 != dict.end())
{
cout << dit2->first << ":" << dit2->second << endl;
++dit2;
}这好像也没好到哪里去呀,接下来,来演示最简易版的遍历容器的代码
for (auto kv : dict)
{
cout << kv.first << ":" << kv.second << endl;
}auto加上for循环让代码的简洁性得到了很大的提高(这好像和python大法有点像了呢)
auto这么好,那它有没有什么缺点呢?肯定有!!它让我们代码的可读性变差了
使用auto需要注意以下几点:
1.auto变量必须在声明的时候对它进行初始化,在编译期编译器要根据初始表达式来推导auto的实际类型,因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编译期会将auto替换为变量实际的类型。
2.auto不能做函数的形参
3.auto不能定义类的非静态成员变量
4. 不能用auto来声明数组
5.不能用auto来实例化模板
6.对于具有const属性的变量,auto可以带不过来这个属性(如:const int a=10; auto b=a;)b不具备a的const属性
7.对于valatile修饰的变量,auto可以带走这个属性
8.想要用auto在一行同时声明多个变量,这些变量必须具有相同类型,否则编译器会报错
总结一下上述内容:使用auto的好处就是使代码变得简洁,坏处是违背了传统C语言用法,可读性较差
接下来我们来了解一下decltype,C++11中auto推导的出现,给程序的书写提供了许多方便,但auto使用的前提是:必须要对auto声明的类型进行初始化,否则编译器无法推导出auto的实际类型。但有时候可能需要使用表达式运行完成之后结果的类型.再比如:有时候我们的程序中存在一些匿名对象,我们想知道它的类型却束手无策,那么我们可以这样来:
struct {
int a;
char b;
}p;
int main()
{
decltype(p) a;
cout<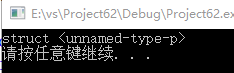
decltype可以用来推导函数的返回类型:1. 如果没有带参数,推导函数的类型
2.如果带参数列表,推导的是函数返回值的类型
decltype推导的四个规则
1.单个标记符表达式和类成员访问符,推导为本类型
2.将亡值,推导为类的引用
3.左值,推导为类型的引用
4.以上都不是,推导为本类型
3.lambda表达式
在计算机科学领域,lambda被用来表示一种匿名的函数。lambda函数跟普通函数相比不需要定义函数名,取而代之的多了一对方括号[],此外lambda函数还采用了追踪返回值类型的方式声明其返回值。
lambda表达式的定义格式如下:
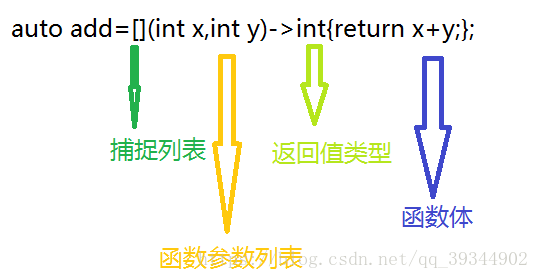
最简单的lambda表达式可以这样来写:auto lam=[]{};什么事也做不了,参数列表和返回值类型可以省略
关于lambda表达式的说明:1.捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为 lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。
2.参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略
3.可以在->之前添加mutable关键字:默认情况下,lambda函数总是一个const函数,mutable可
以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)
4.返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类 型明确情况下,也可省略,由编译器对返回类型进行推导。
5.函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
捕捉列表描述了上下文中那些数据可以被lambda使用,以及使用的方式传值还是传引用。 捕捉列表有以下形式:
[var]:表示值传递方式捕捉变量var
[=]:表示值传递方式捕获所有父作用域中的变量(包括this)
[&var]:表示引用传递捕捉变量var
[&]:表示引用传递捕捉所有父作用域中的变量(包括this)
[this]:表示值传递方式捕捉当前的this指针
注意:这里的父作用域指包含lambda函数的语句块
语法上捕捉列表可由多个捕捉项组成,并以逗号分割。比如:
[=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量
[&,a, this]:值传递方式捕捉变量a和this,引用方式捕捉其他变量
注意:捕捉列表不运行变量重复传递,否则就会导致编译错误。
[=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复
lambda函数的使用场景比较特殊:比如打印一些内容状态,或者进行一些内部操作,这些功能不能与其他的代码共享,却要在一个函数中多次重用。在lambda没有引入前,我们只能封装函数来实现,出于函数作用域及运行效率考虑,此函数通常还需加上static和inline关键字。但lambda的引入,其捕捉列表的功能,使我们不用考虑参数个数以及传递方式,而且主调函数结束函数,lambda函数也结束,不会影响命名空间中的其他东西,使代码的实现更加简答,可读性更高。
说了这么多,我来举一个简单的例子用lambda表达式来实现两个数的简单运算以及交换
double rate = 1.2;
// 最简单的lambda表达式
auto lam = []{};
auto add3 = [](int x, int y, double rate)->double{return (x + y)*rate; };
cout << add3(1, 2, rate) << endl;
//auto add4 = [=](int x, int y)->double{return (x + y)*rate; };
//auto add4 = [&](int x, int y)->double{return (x + y)*rate; };
auto add4 = [rate](int x, int y)->double{return (x + y)*rate; };
//auto add4 = [&rate](int x, int y)->double{return (x + y)*rate; };
cout << add4(1, 2) << endl;
int a = 10, b = 20;
auto swap1 = [](int& x1, int& x2){int x = x1; x1 = x2; x2 = x; };
swap1(a, b);
cout << a << " " << b << endl;
auto swapab = [&a,&b](){int x = a; a = b; b = x; };
swapab();
cout << a << " " << b << endl;
auto swap3 = [&](){int x = a; a = b; b = x; };
swap3();
cout << a << " " << b << endl;
3.默认函数的控制
有时候我们可能会遇到这样一个情况
#include
#pragma warning(disable:4996)
using namespace std;
class String{
public:
String(const char* str)
:_str(new char[strlen(str)+1])
{
strcpy(_str,str);
}
private:
char* _str;
};
int main()
{
String s1("hello");
String s2;
system("pause");
return 0;
}
我们都知道,这个代码肯帝是编不过的,为什么呢?因为我们自己实现了一个构造函数出来,就不会去调用系统默认生成的构造函数了,并且没给这个函数指定默认的参数,所以我们想去定义S2这样一个没有参数的对象的时候,编译器会给我们报下面的错误。

现在我们不想看到这个报错怎么办呢?在C++11中提供了这样一个东西,显式缺省函数,可以在默认函数定义或者声明时加上=default,从而显式的指示编译器生成该函数的默认版本,用=default修饰的函数称为显式缺省函数。
如下:
String()=default;显式缺省不仅可以在类中修饰成员函数,也可以在类定义外修饰成员函数。这样做的好处是:可以对一个类实现多个版本,程序员可以选择所需要的版本进行编译。
另一方面,程序员可能想要限制某些默认函数的生成,最典型的可能想要禁止生成默认的拷贝构造函数。在C++98中,是将拷贝构造函数设置成private的,只声明不给定义,这样只要其他人想要调用就会报错。 在C++11中,有更简单的方法,即在函数定义或者声明时加上=delete,该语法指示编译器不生成对应函数的默认版本,称=delete修饰的函数为删除函数。
class A
{
public:
A(int a)
: _a(a)
{}
A(const A&) = delete;
private:
int _a;
};C++11致力于消除C++中的模糊定义,明确程序员与编译器之间的交流。通常情况下,将基类中的某些成员函数声明成虚函数,然后派生类对其进行重写,即可实现多态。但有时候我们并不想让其在派生类中被重写,那C++98没有很好的解决方式,C++11中提出了final关键字 当final修饰虚函数时,子类就不可以再重写这个虚函数。final修饰类时,表明该类不能被继承;
有时候,在重写基类的某些虚函数时,如果不小心(比如:参数不小心写错),或者类继承比较多,设计比较复杂,可能会造成同名隐藏或者函数名字书写错误而造成重写失败。为了确保子类方法就是对基类某个方法的重写,C++11引入了override关键字。
class Base
{
public:
virtual void Func1()
{
1.
2.
3.
4.
5.
override的出现,在重写时如果出现拼写错误,类型与基类不同,重写了
基类的非虚函数等,override可以保证编译器辅助的做一些检查。
注意:final/override也可以定义为正常的变量名,只有出现在类和函数
之后才表示不能被继承或者是否正确重写。这样设计C++98的代码就可以
通过编译,但是建议尽可能避免这样的变量名称。
继承构造函数
C++中自定义类型类是C++面向对象的基石,类具有可派生性,派生类可
以继承基类的成员变量和成员函数。但基类中有些函数却难以继承,比如
构造函数。如果派生类要使用基类的构造函数,必须在其构造函数初始化
列表位置显式调用。
cout << "Base::Func1()" << endl;
}
void Func2()
{
cout << "Base::Func2()" << endl;
}
};
class Derived : public Base
{
public:
virtual void Func1(int)override
{
cout << "Derived::Func1()" << endl;
}
virtual void FunC()override
{
cout << "Derived::FunC()" << endl;
}
void Func2()override
{
cout << "Derived::Func2()" << endl;
}
};override的出现,在重写时如果出现拼写错误,类型与基类不同,重写了基类的非虚函数等,override可以保证编译器辅助的做一些检查。
注意:final/override也可以定义为正常的变量名,只有出现在类和函数之后才表示不能被继承或者是否正确重写。这样设计C++98的代码就可以通过编译,但是建议尽可能避免这样的变量名称。