MySQL(InnoDB剖析):27---B+树索引的使用(联合索引、覆盖索引、优化器不使用索引的情况、索引提示、MRR优化、ICP优化)
前言
- 在了解了B+树索引的本质和实现后,下一个需要考虑的问题是怎样正确地使用B+树索引,这不是一个简单的问题。这里所总结的可能并不适用于所有的应用场合。我所能做的只是概括一个大概的方向。在实际的生产环境使用中,每个DBA和开发人员,还是需要根据自己的具体生产环境来使用索引,并观察索引使用的情况,判断是否需要添加索引。不要盲从任何人给你的经验意见
- 根据前面的介绍,用户已经知道数据库中存在两种类型的应用,OLTP和OLAP应用
- 在OLTP应用中,查询操作只从数据库中取得一小部分数据,一般可能都在10条记录以下,甚至在很多时候只取1条记录,如根据主键值来取得用户信息,根据订单号取得订单的详细信息,这都是典型OLTP应用的查询语句。在这种情况下,B+树索引建立后,对该索引的使用应该只是通过该索引取得表中少部分的数据。这时建立B+树索引才是有意义的,否则即使建立了,优化器也可能选择不使用索引
- 对于OLAP应用,情况可能就稍显复杂了。不过概括来说,在OLAP应用中,都需要访问表中大量的数据,根据这些数据来产生查询的结果,这些查询多是面向分析的查询,目的是为决策者提供支持。如这个月每个用户的消费情况,销售额同比、环比增长的情况。因此在OLAP中索引的添加根据的应该是宏观的信息,而不是微观,因为最终要得到的结果是提供给决策者的。例如不需要在OLAP中对姓名字段进行索引,因为很少需要对单个用户进行查询。但是对于OLAP中的复杂查询,要涉及多张表之间的联接操作,因此索引的添加依然是有意义的。但是,如果联接操作使用的是 Hash Join,那么索引可能又变得不是非常重要了,所以这需要DBA或开发人员认真并仔细地研究自己的应用。不过在OLAP应用中,通常会需要对时间字段进行索引,这是因为大多数统计需要根据时间维度来进行数据的筛选
一、联合索引
- 概念:联合索引是指多表上的多个列进行索引
图示说明
- 下面创建一个表t,所以你idx_a_b是联合索引,联合的列为(a,b)
create table t( a int, b int, primary key(a), key idx_a_b(a,b) )engine=innodb;
- 从本质上说,联合索引也是一棵树,不同的是联合索引的键值的数量不是1,而是大于等于2
- 下面我们以键值的数量为2来介绍,假定两个键值的名称分别为a,b,如下图所示
- 从图中可以看到多个键值的B+树情况,其实和前面讨论的单个键值的B+数并没有区别,键值都是排序的
- 重点:如果是联合索引,索引排序是看第一个字段的值, 因此在此处键值的排序时根据a进行排序的,即(1,1)、(1,2)、(2,1)、(2,4)、(3,1)、(3,2)
- 对于下面的两种查询语句,可以使用(a,b)这个联合索引来查询,因为其实按照a进行查询的
select * from table where a=xxx and b=xxx; select * from table where a=xxx;
- 但是对于下面的查询语句就不能使用上面那颗B+索引树了,因为其是按照b字段进行查询的
select * from table where b=xxx;

演示案例
- 联合索引的第二个好处是已经对第二个键值进行了排序处理。例如,在很多情况下应用程序都需要查询某个用户的购物情况,并按照时间进行排序,最后取出最近三次的购买记录,这时使用联合索引可以避免多一次的排序操作,因为索引本身在叶子节点已经排序了
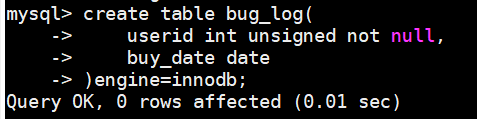
- 例如,下面创建一个测试表bug_log
create table bug_log( userid int unsigned not null, buy_date date )engine=innodb;
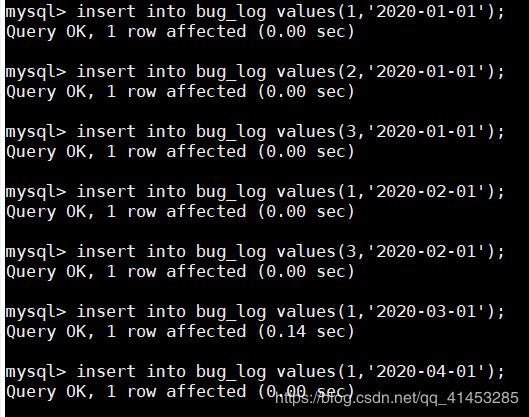
- 插入一些字段
insert into bug_log values(1,'2020-01-01'); insert into bug_log values(2,'2020-01-01'); insert into bug_log values(3,'2020-01-01'); insert into bug_log values(1,'2020-02-01'); insert into bug_log values(3,'2020-02-01'); insert into bug_log values(1,'2020-03-01'); insert into bug_log values(1,'2020-04-01');
- 对userid字段设置一个单列索引,对userid和buy_date字段同时设置一个联合字段
alter table bug_log add key(userid); alter table bug_log add key(userid,buy_date);
- 此时我们查看一下只对userid执行查询时使用到的索引。可以看到可以使用的索引有两个,但是这个查询语句只用了userid索引(因为该索引的叶子节点包含单个键值,所以理论上一个页能存放的记录应该更多)
explain select * from buy_log where userid=2;
- 现在取出userid为1的最近3次购买记录,然后查看执行计划。可以看到可以使用的索引有两个,但是这个查询语句使用了联合索引(因为在这个查询中buy_date字段已经排序好了,使用联合索引取出数据,无序再对buy_date字段再进行一次排序操作)
explain select * from bug_log where userid=1 order by buy_date desc limit 3;
- 若查询时强制使用userid索引,那么执行计划如下,可以看到在“Extra”信息中显示“Using filesort”代表需要额外的一次排序操作才能完成查询,而这次显示需要对列buy_date进行排序,因为索引userid中but_date是未排序的:
explain select * from bug_log use index for join(userid) where userid=1 order by buy_date desc limit 3;




索引排序
- 因此联合索引(a,b)是根据列a,b进行排序,因此下列语句可以直接使用联合索引得到结果
select ... from table where a=xxx order by b;
- 然而对于联合索引(a,b,c)来说,下列语句同样可以直接通过联合索引得到结果:
select ... from table where a=xxx order by b; select ... from table where a=xxx and b=xxx order by c;
- 但是对于下面的语句,联合索引不能直接得到结果,其还需要执行一次filesort排序操作,因为索引(a,c)并未排序
select ... from table where a=xxx order by c;
二、覆盖索引
- InnoDB支持覆盖索引(或索引覆盖),即从辅助索引中就可以得到查询的记录,而不需要查询聚集索引中的记录
- 使用覆盖索引的一个好处是:不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的IO操作

- 对于InnoDB的辅助索引来说,由于其包含了主键信息,因此其叶子节点存放的数据为(primary key1,primary key2,...,key1,key2,...)。例如,下列语句都可仅使用一次辅助联合索引来完成查询:

演示案例
- 覆盖索引的另一个好处是对某些统计问题而言的
- 还是对上面创建的表bug_log进行分析,分析下面的查询
explain select count(*) from bug_log;
- InnoDB并不会选择通过查询聚集索引来进行统计。由于表上还有辅助索引,而辅助索引远小于聚集索引,选择辅助索引可以减少IO操作,故优化器的选择如下图所示:
- possible_keys为NULL,但是Extra却显示了优化器进行了覆盖索引操作
- 此外,在通常情况下,诸如(a,b)的联合索引,一般是不可以选择列b中所谓的查询条件。但是如果是统计操作,并且是覆盖索引的,则优化器会进行选择,如下述语句:
- 从图中可以看到possible_keys依然为NULL,但是key却显示userid_2,即表示(userid,buy_date)的联合索引。Extra同样可以发现Using index提示,表示为覆盖索引
explain select count(*) from bug_log where buy_date>='2021-01-01' and buy_date<'2021-02-01';


三、优化器选择不使用索引的情况
- 在某些情况下,当执行explain进行SQL语句的分析时,会发现优化器并没有选择索引去查找数据,而是通过扫描聚集索引,也就是直接进行全表的扫描来得到数据。这样情况多发生于范围查找、JOIN链接操作等情况下
- 例如:
explain select * from ordertails where orderid>10000 and orderid<102000;- 上面的语句查找订单号大于10000的订单详情,通过命令show index from ordertails可以观察到如下所示的情况:
- 表中有(orderid,productid)的联合主键
- 还有对于列orderid的单个索引

- SQL语句显示的结果如下:
- 优化器没有按照orderid上的索引来查找数据
- possible_keys上可以看到查询使用primary、orderid、ordersorder_details3个索引
- 但是最后的索引使用中,优化器选择了primary聚集索引(也就是表扫描,而非orderid辅助索引扫描)
![]()
为什么选择聚集索引
- 因为用户要选择的数据是整行信息,而orderid索引不能覆盖到我们要查询的信息,因此在对orderid索引查询到指定数据后,还需要一次书签访问来查找整行数据的信息
- 虽然orderid索引中数据时顺序存放的,但是再一次进行书签查找的数据则是无序的,因此变为了磁盘上的离散操作
- 如果要求访问的数据量很小,则优化器还是会选择辅助索引,但是当访问的数据占整个表中数据的大部分时(一般是20%左右),优化器会选择通过聚集索引来查找数据
- 因此之前已经提到过,熟悉怒读要远远快于离散度
- 因此对于不能进行索引覆盖的情况,优化器选择辅助索引的情况:通过辅助索引查找的数据时少量的。这是由当前传统机械硬盘特性所决定的,即利用顺序读来替换随机读的查找
- 若用户使用的磁盘时固态硬盘,随机读操作非常快,同时有足够的自信来确认使用辅助索引可以带来更好的性能,那么可以使用关键字force index来强制使用某个索引,例如:
explain select * from ordertails force index(orderid) where orderid>10000 and orderid<102000;

四、索引提示
- MySQL数据库支持索引提示(index hint),显式地告诉优化器使用哪个索引
- 个人总结以下两种情况可能需要用到索引提示:
- MySQL数据库的优化器错误地选择了某个索引,导致SQL语句运行的很慢。这种情况在最新的MySQL数据库版本中很少见。优化器在绝大部分情况下工作得都非常有效和正确。这时有经验的DBA或开发人员可以强制优化器使用某个索引,以此提高SQL运行的速度
- 某SQL语句可以选择的索引非常多,这时优化器选择执行计划时间的开销可能会大于SQL语句本身。例如,优化器分析Range查询本身就是比较耗时的操作。这时DBA或开发人员分析最优的索引选择,通过索引提示来强制使优化器不进行各个执行路径的成本分析,直接选择指定的索引来完成查询
- 语法格式:
- USE INDEX:提示操作,提示优化器可以使用某个索引,但是实际上使用的索引还是根据优化器自己选择
- FORCE INDEX:强制操作,让优化器强制根据自己提供的索引来进行查询工作
- 使用语法如下:

演示案例
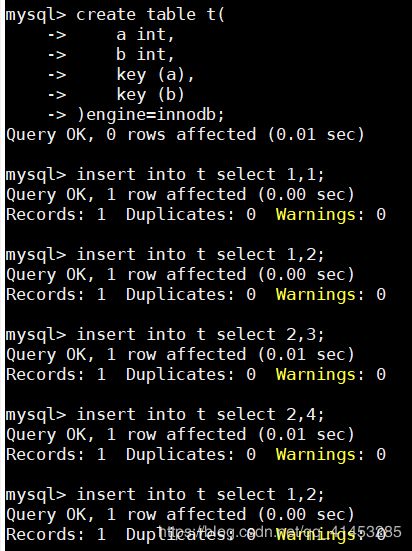
- 创建一个表t,并填入相应的数据
create table t( a int, b int, key (a), key (b) )engine=innodb;insert into t select 1,1; insert into t select 1,2; insert into t select 2,3; insert into t select 2,4; insert into t select 1,2;
- 分析下面的查询语句:
- possible_keys显示了SQL语句可使用的索引为a,b
- key显示了实际使用的索引,同样也为a和b,也就是所这个查询语句使用a和b两个索引来完成这一查询
- Extra提示的Using intersect(b,a)表示根据两个索引得到的结果进行求交的数学运行,最后得到结果
explain select * from t where a=1 and b=2;
- 现在我们使用“USE INDEX”的索引提示来使用a这个索引,结果如下:
- 虽然我们制定了使用a索引,但是优化器实际选择的是通过表扫描的方式
- 因此,USE INDEX只是高度优化器可以选择该索引,实际上优化器还是会再根据自己的判断进行选择
explain select * from t use index(a) where a=1 and b=2;
- 现在使用“FORCE INDEX”的索引提示,结果如下:
- 我们使用FORCE INDEX的索引提示之后,优化器的最终选择和用户指定的索引是已知的
explain select * from t force index(a) where a=1 and b=2;



五、Multi-Range Read(MRR)优化
- MySQL 5.6版本开始支持Multi-Range Read(MRR)优化。MRR优化的目的就是为了减少磁盘的随机访问,并且将随机访问转换为较为顺序的数据访问,这对于IO-bound类型的SQL查询语句可带来性能极大的提升
-
MRR优化的好处:
-
MRR使数据访问变得较为顺序。在查询辅助索引时,首先根据得到的查询结果按照主键进行排序,并按照主键排序的顺序进行书签查找
-
减少缓冲池中页被替换的次数
-
批量处理对键值的查询操作
-
- 对于InnoDB和MyISAM存储引擎的范围查询和JOIN查询操作,MRR工作方式如下:
- 将查询得到的辅助索引键值存放在一个缓存中,这是缓存中的数据是根据辅助索引键值排序的
- 将缓存中的键值根据RowID进行排序
- 根据RowID的排序顺序来访问实际的数据文件
- 此外,若InnoDB存储引擎或者MyISAM存储引擎的缓冲池不足够大,即不能存放下一张表中的所有数据,此时频繁的离散读操作还会导致缓存中的页被替换出缓冲池,然后有不断地被读入缓冲池。若按照主键顺序访问,则可以将重复行为降为最低
范围查询演示案例
- salary表上有一个辅助索引idx_s,因此除了通过辅助索引查询键值外,还需要通过书签查找来进行对整行数据的查询
- 有下面的SQL语句:
explain select * from slaries where salary>10000 and salary<40000;
- 当不启用MRR特性时,看到的执行如下图所示:
- 若启动MRR特性,则除了会在列Extra看到Using index condition外,还会看见Using MRR选项,如下图所示:
- 而在实际的执行中两个执行时间差距非常大,见下图
- 可见MRR将访问数据转换为顺序后查询性能得到了很大的提高




将范围查询拆分为键值对演示案例
- 此外,MRR还可以将某些范围查询,拆分为键值对,以此来进行批量的数据查询。这样做的好处是可以在拆分过程中,直接过滤一些不符合查询条件的数据
- 例如:
select * from t where key_part1>=1000 and key_part1<2000 and let_part2=10000;
- 表t中有(key_part1,key_part2)的联合索引,因此索引根据key_part1,key_part2的位置关系进行排序
- 若没有启动MRR,此时查询类型为范围查询,SQL优化器会先将key_part1大于1000且小于2000的数据都取出,即使key_part2不等于1000。待取出行数据后再根据key_part2的条件进行过滤。这会导致无用数据被取出。如果有大量的数据且其key_part2不等于1000,则启用MRR优化会使性能有巨大的提升
- 如果启用了MRR,优化器会先将查询条件进行拆分,然后再进行数据查询。就上述查询而言,优化器会将查询条件拆分为(1000,1000),(1001,1000),(1002,1000),......,(1999,1000),最后再根据这些拆分出的条件进行数据的查询
- 现在来看一个实际的例子。例如:
select * from salaeies where (from_date between '1986-01-01' and '1995-01-01') and (salary between 38000 and 40000);
- 若启用MRR优化,则执行计划如下图所示:

optimizer_switch选项
- 是否启用MRR优化可以通过这个参数中的标记(flag)来控制
- mrr标志:表示是否启用MRR优化。当为on时,表示启用MRR优化
- mrr_cost_bases标记:表示是否通过cost bases的方式来选择是否启用mrr
- 若mrr为on,mrr_cost_bases设为off,则总是启用MRR优化。
- 例如,下述语句将MRR优化总是设为开启状态
read_rnd_buffer_size参数
- 用来控制键值的缓冲区大小
- 当大于该值时,则执行期对已经缓存的数据根据RowID进行排序,并通过RowID来取得行数据
- 该值默认为256K

六、Index Condition Pushdown(ICP)优化
- 和MRR优化一样,Index Condition Pushdown同样是MySQL 5.6开始支持的一种根据索引进行查询的优化方式
- 之前的MySQL不支持ICP,当进行索引查询时,首先根据索引来查找记录,然后再根据WHERE条件来过滤条件。支持了ICP之后,MySQL会在取出索引的同时,判断是否可以进行WHERE条件的过滤,也就是讲WHERE的部分过滤操作放在了存储引擎层
- 在某些查询下,可以大大减少上层SQL层对记录的索引(fetch),从而提高数据库的整体性能
- ICP优化支持range、ref、eq_ref、ref_or_null类型的查询,当前支持MyISAM和InnoDB存储引擎
- 当优化器选择ICP优化时,可在执行计划的列Extra看到Using index condition提示

演示案例
- 假设下面的表有联合索引(zip_code,last_name,firset_name)
- 查询语句如下:
select * from people where zipcode='95054' and lastname like '%etrunia%' and address like '%Main Street%';
- 对于上述语句,MySQL可以通过索引来定位zipcode等于95054的记录,但是索引对WHERE条件的lastname和address条件没有任何帮助
- 若不支持ICP优化,则数据库需要先通过索引取出所有zipcode等于95054的记录,然后再过滤WHERE之后的两个条件
- 若支持ICP优化,则在索引取出时,就会进行WHERE条件的过滤,然后再去获取记录。这极大提高查询的效率。当然,WHERE可以过滤的条件是要该索引可以覆盖到的范围
- 现在看下面的SQL语句:
select * from salaries where (from_date between '1986-01-01' and '1995-01-01') and (salary between 38000 and 40000);
- 如果不启用MRR优化,则执行计划如下
- 可以看到Extra有Using index condition的提示。但是为什么这里的idx_s索引会使用Index Condition Pushdown优化呢?因为这张表的主键是(emp_no,from_date)的联合索引,所以idx_s索引中包含了from_date的数据,故可以使用此优化方式
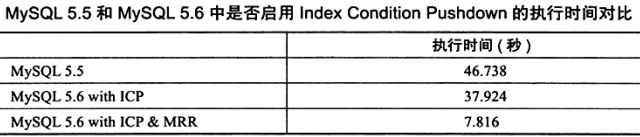
- 下表对比了在MySQL 5.5和MySQL 5.6中上述SQL语句的执行时间,并且同时比较开启MRR后的执行时间
- 上述的执行时间的比较同样是不对缓冲池做任何的预热操作。可见Index Condition Pushdown优化可以将查询效率在原有MySQL 5.5版本的技术上提高23%。而再同时启用MRR优化后,性能还能有400%的提升