xml两种解析方式(封装了获得文档和回写)
开始时间:2018年10月6日13:16:37
结束时间:2018年10月6日14:26:25
累计时间:1
xml解析:
这一篇挺好 https://blog.csdn.net/CristianoJason/article/details/51777853
但我习惯自己写,对自己提升帮助更大,再者对他做一个补充吧。
xml的解析有两种: dom 解析: sax 解析:
1:dom解析:原理: (图解)
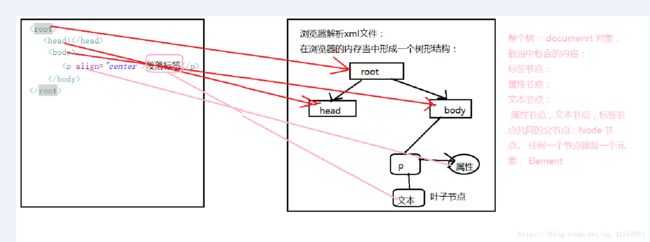
将xml 根据xml的层级结构,将xml文档在内存当中分配成一个树形结构。
把每个标签,属性, 文本都封装成了一个对象。
有了对象就可以使用对象的属性和方法来解析xml文档,步骤如下:
sun: jaxp dom解析:
(1)元素节点的查询操作: 查询所有的。
(2)节点元素的添加操作: (内存当中完成,document 回写)
(3)节点的删除操作:
步骤:
a:解析器的工厂: DocumentBuilderFactory
b:获得解析器: DocumentBuilder
c:解析: 获得整个文档: Document
d:获得要删除的节点:
e:获得删除节点的父节点:
f:父节点执行删除操作:
g: 回写:
(4)节点元素的修改: 内容的修饰: 51---15
步骤:
a:通过工具类 获得整个文档:
b:获得要修改的节点:
c:调用对方法 对内容进行修改。
d: 回写
(5) 节点元素的替换操作: age ---> school
a: 工具类获得文档: document
b: 获得要替换的元素的节点:
C: 创建一个新的节点:
创建文本节点:
将文本节点追加到新节点。
D: 获得要是替换节点的父节点。
e: 父节点执行替换操作:
f: 回写:
2: 解析器:
不同的公司 厂商提供了不同的解析器:
sun: 针对dom解析和sax解析 提供jaxp (JDK)
jdom 针对dom 和 sax 提供的解析器: jdom
dom4J: 针对dom 和 sax 供的解析器 : dom4J(重点) 主流
3: 针对sun公司提供的jaxp、解析器实现对xml的解析
解析步骤:
(1) 创建一个xml文件: persons xml文件
(2)解析persons文件:
a: 获得解析器: 查看JDK的文档: javax.xml.parsers 包当中:
DocumentBuilder : dom解析的解析器: 抽象的类,不能直接实例化。 通过 工厂获得实例
DocumentBuilderFactory: 解析器的工厂类:抽象类: 通过静态方法获得实例。
Document: 文档对象:
NodeList: 节点的集合对象:
Node : 节点: 父对象:
需求: 节点内容的查找
节点内容的添加
删除
实现代码如下:
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.junit.Test;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.w3c.dom.Text;
/*
* 使用sun公司提供的jaxp、
* 解析器进行解析 xml文件:
*
* //需求: 查询所有的name的值:
*
* 步骤:
* 1: 获得解析器工厂。 DocumentBuilderFactory.newInstance()
* 2: 通过工厂获得解析器: DocumentBuilder
* 3: 获得Document对象: 通过解析器的parse(String url )
* 4: 通过document对象的方法:获得所有的name 节点: 返回的是NodeList
* 5: 遍历NodeList 获得每一个Node 。
* 6: 使用Node API方法获得文本的内容: getTextContent()
*/
public class DomParsers {
//获得了persons 当中所有name的值:
@Test
public void test01()throws Exception{
//获得解析器的工厂:L
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//获得一个解析器:
DocumentBuilder builder = factory.newDocumentBuilder();
// 获得整个Document文档: 获得了整个树 就获得了树当中所有的节点:
Document document = builder.parse("src/persons.xml");
//使用doucment对象的API方法: 获得所有的name节点,返回的是一个list集合:
NodeList list = document.getElementsByTagName("name");
//遍历集合:
for(int i=0; i
@Test
public void test03()throws Exception{
//获得解析器的工厂:L
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//获得一个解析器:
DocumentBuilder builder = factory.newDocumentBuilder();
// 获得整个Document文档: 获得了整个树 就获得了树当中所有的节点:
Document document = builder.parse("src/persons.xml");
//创建一个新的节点:
Element sexEle = document.createElement("sex");//在内存当中形成了:
//文件文本节点:
Text text = document.createTextNode("weizhi");// weizhi
//将文本节点追加到 sexEle后L
sexEle.appendChild(text); // weizhi
//获得第一个person对象:
Node personFirst = document.getElementsByTagName("person").item(0);
// 将创建的新标签追加在 personFirst 后:
personFirst.appendChild(sexEle);
//===================================以上所有的操作都是在内存当中完成: 需要将内存的document 写出到外部的文件当中:
// 获得工厂:TransFormerFactory、
TransformerFactory f = TransformerFactory.newInstance();
Transformer transFormer = f.newTransformer();
//调用api 实现document的回写: transform(Source xmlSource, Result outputTarget)
transFormer.transform(new DOMSource(document), new StreamResult("src/persons.xml") );
}
}
二: dom 和 sax 解析的区别:
dom: 整个文档封装成一棵树形结构, 把文档当中所有的内容都封装了对象。
使用对象的方法和属性对树进行进行操作。
所有的内容:
标签节点:
属性节点:
文档节点:
优点: 方便节点元素的增删改查操作。
弊端: 当xml文件过大,全部加载到内存当中,容易造成内存溢出。
sax解析: 原理: 采用事件驱动的形式进行解析》
特点: 边读边解析。
优点: 不会造成内存溢出。 采用事件驱动的形式,边读边解析。
弊端: 只能查询操作,不能进行增删改操作。
sax解析的步骤:
解析器:
SAXParser 抽象类,不能直接实例化。 通过工厂获得。
SAXParserFactory 获得解析器的工厂类, 抽象的类,不能直接实例化。 通过本类的静态方法获得。
例子如下:
import java.io.IOException;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.junit.Test;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
/*
* 使用 sax 解析 解析文档:
*/
public class SaxParseDoc {
private static final String PATH ="src/persons.xml";
//读取了文件的内容:
@Test
public void test01() throws ParserConfigurationException, SAXException, IOException{
//获得解析器工厂:
SAXParserFactory factory = SAXParserFactory.newInstance();
//获得解析器:
SAXParser parser = factory.newSAXParser();
//解析文档: 第一个参数是一个来源: 对谁进行解析:
// 参数二: 是一个事件处理器:
parser.parse(PATH, new MyDefaultHander());
}
//获取所有的name的值:
@Test
public void test02() throws ParserConfigurationException, SAXException, IOException{
//获得解析器工厂:
SAXParserFactory factory = SAXParserFactory.newInstance();
//获得解析器:
SAXParser parser = factory.newSAXParser();
//解析文档: 第一个参数是一个来源: 对谁进行解析:
// 参数二: 是一个事件处理器:
parser.parse(PATH, new MyDefaultHander());
}
}
//MyDefaultHander 具备处理器的功能:
class MyDefaultHander extends DefaultHandler{
//定义一个标志位:
private boolean flag= false;
//定义一个计数器:
int count=0;
//子类对父类进行方法的重写:
//用来读取开始标签
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
// qName : 标签的名称:
if("name".equals(qName)){
flag=true;
count++;
}
}
// 用来读取文本内容的: 将读取的文本的内容封装到了字符数组当中
public void characters(char[] ch, int start, int length)
throws SAXException {
if(flag && count==1){
System.out.print(new String(ch, start, length));
}
}
// 用来读取结束标签:
public void endElement(String uri, String localName, String qName)
throws SAXException {
flag=false;
}
}
其中 获得文档对象和回写操作多次用到,对其进行封装:
(工具类封装一般在util包下面)
package com.yidongxueyuan.util;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.TransformerFactoryConfigurationError;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.xml.sax.SAXException;
/**
* 针对sun公司提供的 jaxp 解析器 提供的工具类:
* (1) 获得Document文档: 、
* (2)回写的方法:
* @author Mrsun
*
*/
public class JaxpUtils {
/**
* 获得整个document文档对象:
* @return 文档对象:
*/
public static Document getDocument(String path){
try {
//获得解析器的工厂:L
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//获得一个解析器:
DocumentBuilder builder = factory.newDocumentBuilder();
// 获得整个Document文档: 获得了整个树 就获得了树当中所有的节点:
Document document = builder.parse(path);
return document;
} catch (Exception e) {
throw new RuntimeException("解析文档失败");
}
}
/**
* 将内存当中的树写出到外部的文件当中:
* @param document 文档对象
* @param path 指定的目的:
*/
public static void writer2File(Document document, String path ){
try {
TransformerFactory f = TransformerFactory.newInstance();
Transformer transFormer = f.newTransformer();
//调用api 实现document的回写: transform(Source xmlSource, Result outputTarget)
transFormer.transform(new DOMSource(document), new StreamResult(path) );
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}