Java集合之HashMap源码分析
前面我们提到了集合,今天我们就具体来了解一下Java集合中具体的组成部分!

以下源码均为jdk1.7
HashMap概述
HashMap是基于哈希表的Map接口的非同步实现. 提供所有可选的映射操作, 并允许使用null值和null健. 此类不保证映射的顺序.
需要注意的是: HashMap不是同步的.
哈希表
哈希表定义: 哈希表是一种根据关键码去寻找值的数据映射结构, 该结构通过把关键码映射的位置去寻找存放值的地方.
举个例子, 最典型的例子就是字典, 如果想要在字典中查找"按"字, 通常会根据拼音 an 去查找拼音索引(当然也可以是偏旁索引), 然后找到 ti 在字典中的位置, 得到第一个拼音为 an 的字 "安". 这个过程就是键码映射, 即 通过 key 查找 f(key). 其中 key为关键字, f()是哈希函数, 哈希函数的结果就是哈希值.
哈希冲突: 那么问题来了, 我们要查找的是"按",而不是"安", 但他们的拼音都是一样的. 通过关键字 an "按"和"安"可以映射到一样的字典页码4的位置, 这就是哈希冲突(也叫哈希碰撞), 在公式上表达就是 key1 != key2, 但f(key1)=f(key2).
key 为值, f(key)计算得出数组中存储地址, 这样就会出现两个元素的地址相同的情况. 这时, 哈希函数的设计就至关重要了, 好的哈希函数会尽可能的保证 计算简单和散列地址分布均匀, 但是, 数组是一个连续的固定长度的内存空间, 再好的哈希函数也不能保证得到的存储地址绝不发生冲突.
哈希冲突的解决方案有多种: 开放定址法(发生冲突, 寻找下一个), 再散列函数法, 链地址法.
HashMap就是采用了链地址发, 也就是 数组+链表 的方式.
HashMap的实现原理
最基本的数据结构有两种: 数组和指针, HashMap就是通过这两个数据结构实现的, 是数组和链表的结合体.
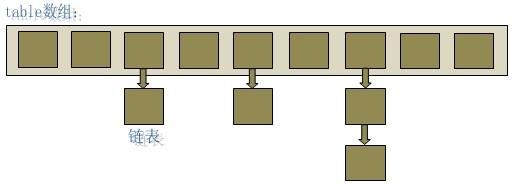
从图中可以看出, HashMap底层是一个数组结构, 数组中的每一项是一个链表. 当新建HashMap时, 会初始化一个数组.
HashMap的主干是一个Entry数组.

Entry是一个静态内部类, 包含 key-value.

HashMap存储的整体结构如下:
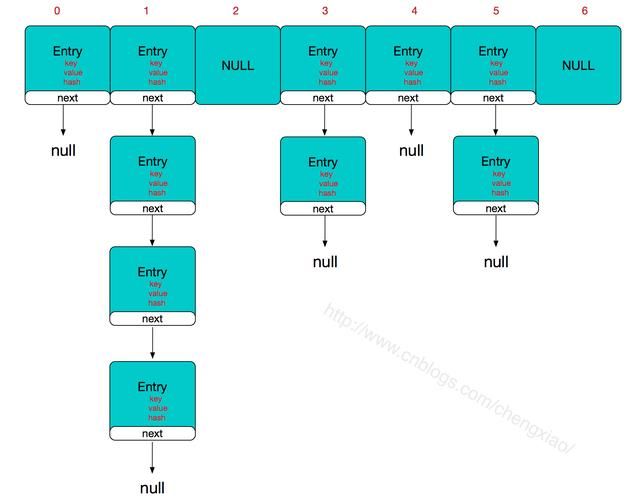
简单说, HashMap有数组+链表组成, 数组是HashMap的主体, 链表是为了解决哈希冲突而存在的, 如果定位到数组位置不含链表(当前entry的next指向null), 那么对于查找,添加等操作很快, 仅需一次寻址即可; 如果定位到的数组包含链表, 那么添加操作就要遍历链表, 然后通过key的equals方法进行逐一对比, 存在即覆盖, 不存在则新增, 而查找操作也需遍历链表.
所以, 性能考虑, HashMap中的链表出现越少, 性能越好.
HasmMap几个重要的字段:

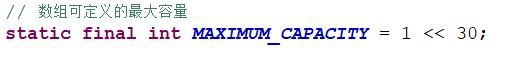



HashMap的构造函数:

从上面代码中可以看出, 在常规构造器中, 没有为数组 table 分配内存空间(有个参数为map的构造器除外), 而是在执行 put操作时才真正构建table数组

再来看 inflateTable()方法源码:

重量级角色, 哈希函数出场:

indexFor()函数实现如下:

h&(length - 1)保证获取的index一定在数组的范围内, 例如: 容量为16, length-1=15, h=18, 进行计算为:

得出index=2.
故而, 最终存储位置的确定为如下流程:

最后看下 addEntry 的实现:

通过 addEntry 的代码可以看出, 当发生哈希冲突并且size大于阈值时, 需要进行数组扩容, 扩容时, 需要新建一个长度为之前2倍的新数组, 最后将当前的Entry数组中元素全部传过去, 扩容后的新数组长度为之前的2倍, 所以扩容相对来说是一个耗资源的操作.
下面看get方法就简单得多了:

然后是getEntry()源码:

可以看出, get方法的实现相当简单, 流程为: key(hashcode)-->hash-->indexFor-->最终索引位置, 找到对应位置table[i], 在查看是否有链表, 遍历链表, 通过key的equals方法比对查找对应的记录.
在getEntry方法中, 定位到数组位置之后遍历链表的时候, e.hash==hash这个判断是否有必要. 试想如下场景, 如果传入的key对象重写了equals方法却没有重写hashCode, 而恰巧此对象定位到这个数组位置, 如果仅仅用equals判断可能是相等的, 但其hashCode和当前对象不一致, 这种情况, 根据Object的hashCode的约定, 不能返回当前对象, 而应该返回null.
重写equals方法要同时重写hashCode方法
为什么重写equals时也要同时重写hashCode? 下面举个小例子:

实际输出结果:
结果: null
现在我们已经对HashMap的原理有了一定了解, 这个结果就不难理解了. 尽管我们在进行get和put操作的时候, 使用的key从逻辑上讲是等值的, 但由于没有重写hashCode方法, 在进行put操作时: key(hashcod1)-->hash-->indexFor-->最终索引位置; 而通过key去除value时: key(hashcode2)-->hash-->indexFor-->最终索引位置, 由于hashcode1和hashcode2不相等, 最终得出的数组索引页不一样而返回null(也可能碰巧定位到了一个数组位置, 但是也会判断其entry的hash值是否相等, 上面get方法中有提到)
所以, 在重写equals方法时, 必须注意重写hashCode方法, 同时还要保证equals判断相等的两个对象, 调用hashCode方法要返回同样的整数值, 而equals判断不相等的两个对象, 其hashCode可以相同, 只是会发生哈希冲突, 应该尽量避免.
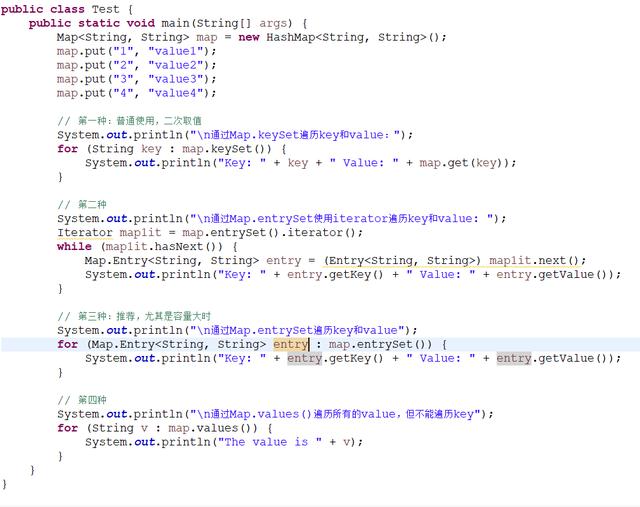
HashMap的遍历
总结
HashMap底层将key-value当成一个整体处理, 这个整体就是Entry对象. HashMap底层采用一个Entry[]数组来保存所有的key-value对, 当需要存储一个Entry对象时, 会根据hash算法来决定其在数组中的位置, 再根据equals方法决定其在该数组位置上的链表中的存储位置; 当需要取出一个Entry时, 也会根据hash算法找到其在数组中的存储位置, 再根据equals方法从该位置上的链表中取出该Entry.
Java。大家都知道,我们是学Java全栈的,大家就肯定以为我有全套的Java系统教程。没错,我是有Java全套系统教程,进扣裙【47】974【9726】所示,!~

“我们相信人人都可以成为一个程序员,现在开始,找个师兄,带你入门,学习的路上不再迷茫。这里是ja+va修真院,初学者转行到互联网行业的聚集地。"