可解释性论文阅读(三)--Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
中间隔了一天,但是我也有看英语论文的。而且我发现自己有变化了,并且我很喜欢这种变化。以前我看论文总是喜欢扫看,但是英语不行,所以看英语论文的时候,我感觉自己变得沉静了。
还有一点,我不排斥英文论文了。遇到英文的文字,也很自然地开始读了起来。(此处插入一个女大学生欣慰的笑容~~)
进入正文:Grad-CAM也是很经典的方法啦~
不过我要改改笔记方法,写得好的原文我就在我论文里标记好了。这里只写自己的理解。
Abstract
2.我们的可视化可以:
1.适用范围广:不需要改变结构以及重新训练。
2.提供洞察一些CNN模型的失效模式(显示,看似不合理的预测的合理解释),以及CNN+LSTM在区分图像区域上表现很好。
3.通过发现数据集的偏差,诊断故障模型。
4.模型决策的文本解释
5.帮助未经训练的用户成功地区分“更强”的网络和“更弱”的网络,即使两者做出的预测完全相同。
6.弱监督定位,就是说fast-scnn、ssd、yolo-v3这些模型用于目标检测,但是都是用标注数据集做的,但是这种激活图的方法也可以框出目标大概的位置,在CAM的论文里讲了这一点,并且作者还做了实验,虽然效果比强监督的差一些,但是也很好了。
一个“良好”的视觉解释,从模型中证明任何目标类别应该具有:
(a)类区分性(即在图像中定位类别)
(b)高分辨率(即捕捉细粒度的细节)
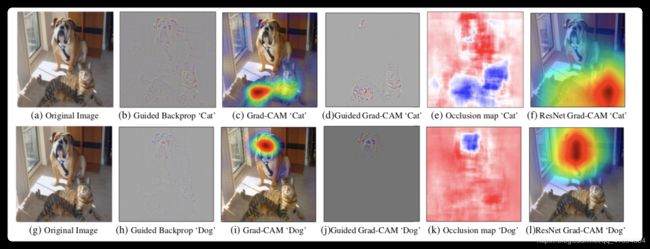
图1:分别是对狗和猫的可视化。可是第2列虽然有很好的细节(b),但是没有区分度(不能区分出猫和狗,两种方法很相似),但是看第3列,我们的方法类别区分是很明显的。同时如果我们把grad-cam融合像素空间梯度可视化的方法就可以,既有类区分性同时也有高分辨率,看第4列。
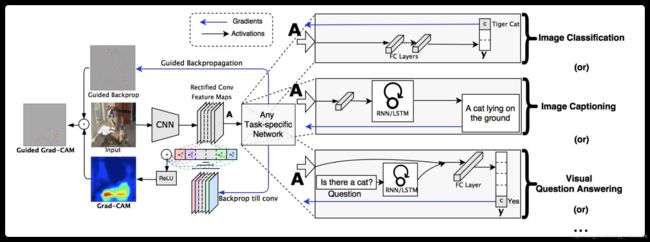
图2:Grad-CAM概述,给一个图片和一个感兴趣的类,比如上图中input和猫,然后将这个通过一些带relu的卷积层,也就是特征提取,提取后可以接不同形式的图像分类任务等等。但是对于特征提取的A,我们将猫类别的梯度改为1,其他类别为0,反向传播到特征图中,通过特征图计算可以得到上图中的蓝色热图。同时A用引导反向传播得到一个具有细节的图,然后这两个图点乘就可以得到,既具有细节,同时具有类别区分度的图。
要理解Grad-CAM,可以先对比一下CAM。
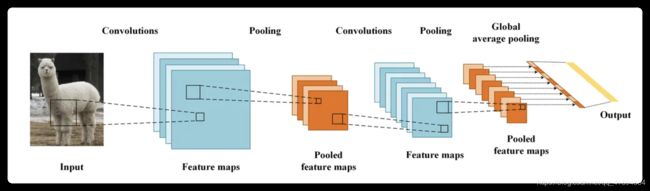
最后一层卷积层很重要,含有很多信息,所以从这一层下手。CAM的思想 是去掉全连接,加一层GAP也就是对最后一层池化层的每一个特征图求均值。GAP到softmax层的每一个权重w,和每一个特征图对应相乘相加,然后上采样回原来的图片大小。
但是它最大的问题就是,它修改了原模型的结构,要求把全连接层去掉,换成GAP,然后直接跟softmax输出,因此导致了模型需要重新训练。
我之前一直不理解为什么要重新训练,因为我感觉自始至终都只有最后一层的feature map起作用了。但是我去看了论文里面关于两种方法的等价性证明,实际上,这个w是GAP全连接到softmax的权重~~
好了,对比CAM理解Grad-CAM:
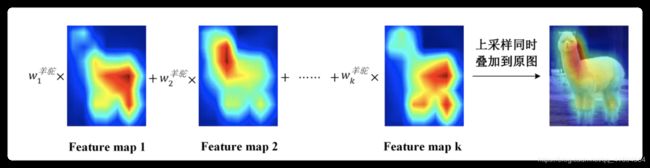
在CAM里面使用的GAP作为权值,在Grad-CAM里面使用的是:
输出概率(softmax层之前的)关于特征图的导数,经过长和宽的全局平均池化,可以得到该神经元的重要性。
然后也是用这些权值和特征图相加(图2),但是这里通过了一个relu,只关注对该类别有正影响的区域。
接着证明了Grad-CAM与CAM在理论上的等价,并且比CAM更加泛化。
Evaluating Localization Ability of Grad-CAM
1.弱监督定位
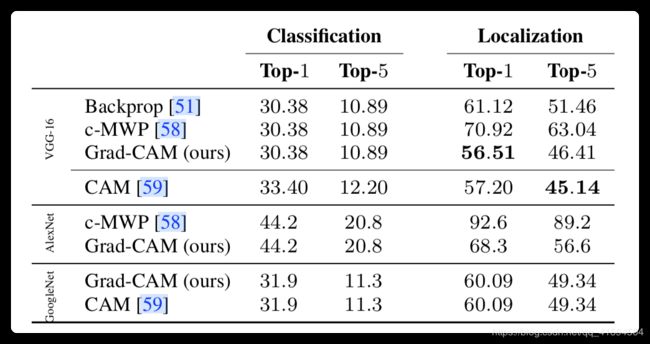
三种不同的网络,第1列是分类效果,第2列是定位效果。
科普一下;
TOP-1错误率
对一个图片,只判断概率最大的结果是否是正确答案。
Top-5错误率
对一个图片,判断概率排名前五中是否包含正确答案。
2.弱监督图像分割

使用Grad-CAM作为SEC的弱监督定位种子,在VGG16网络上,达到的iou(一个指标)比CAM要高。
Pointing Game
用这个评价方法(评价目标定位的不同可视化方法的辨别力),提取热图上最大作用点,评估是否位于一个带注释的实例中,用命中率评价。实验显示,
Grad-CAM outperforms c-MWP by a significant margin (70.58% vs. 60.30%)
5 Evaluating Visualizations
1.类别区分性
看表2的第1列结果就可以了~
2.可信赖度

后用两种方法引导反向传播和guide-grad-cam结合,然后找人问哪个更可靠,得到的结果如表2,就可以知道,它可以用来评估这个模型值不值得被信赖了~
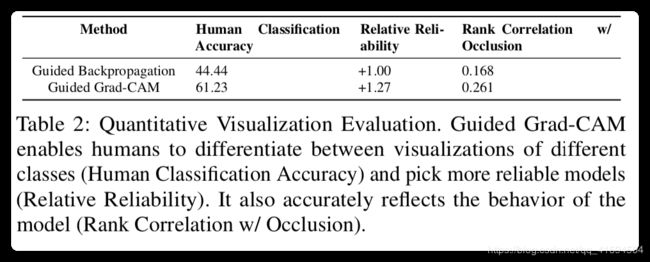
3.忠诚度
就是指该方法对模型的忠诚度,采用图像遮挡的方式,CNN的识别准确率会变化,同时这个可视化结果也会,然后发现grad-CAM比其他方法对于遮挡的相关度都大。看表2第三列。
6.Diagnosing image classification CNNs with Grad-CAM

这个图好懂,看图就知道了。
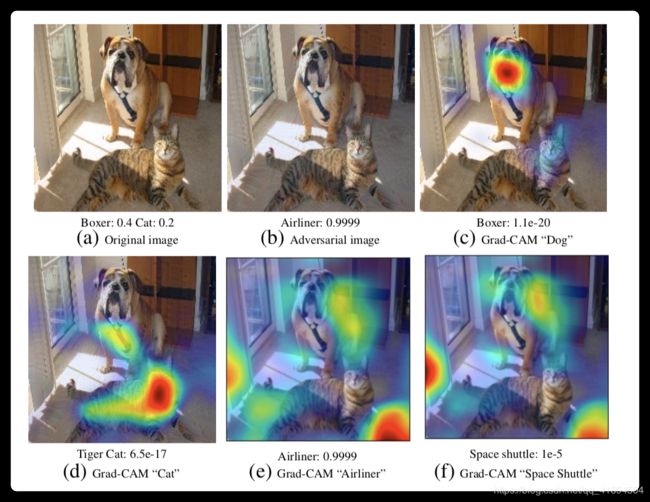
这个图是说有时候,为了扰动分类效果,会认为添加噪声,但是又看不出来。比如(b).但是如果按类别(哪怕概率很小),也可以可视化出来(c)和(d),同时可视化排名前2的两张图,可以看到关注于背景。

这个图讲的数据的均衡与不均衡会导致模型在识别的时候出现一些问题。比如说大部分的医生都是男的,所以不均衡数据的模型在第2列就会把识别成护士。
7 Textual Explanations with Grad-CAM
前两行是成功的案例,最后一行是失败的案例。这个是讲文本解释的,这些词是每个neuron看起来像什么,对预测这个图的类别输出权重最大的5个图,和最小的5个图,用文本解释这个图被预测为这样的原因。
8 Grad-CAM for
and VQA
VQA是智能问答的缩写
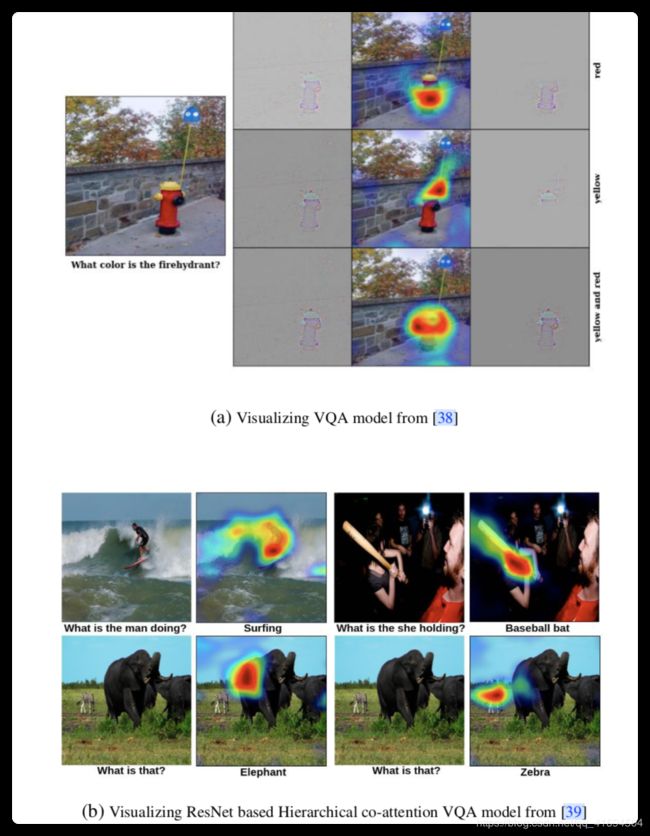
还是看图就懂了,都是这个方法的应用,不得不说,作者花了好多篇幅,介绍这个。
但是抓住一个重点,就是这种方法很具有类别区分性,所以可以应用到这些领域喽~~
这篇文章就到这里啦~
今天又是开心的一天,每天都是~