HttpClient和Jsoup爬虫实例
最近学习了一个爬虫项目,用到的是HttpClient+Jsoup实现,然后我就学习了一下HttpClient和Jsoup的内容,代码在最下面有地址:
HttpClient学习:https://blog.csdn.net/qq_42969074/article/details/85618628
Jsoup学习:https://blog.csdn.net/qq_42969074/article/details/85562751
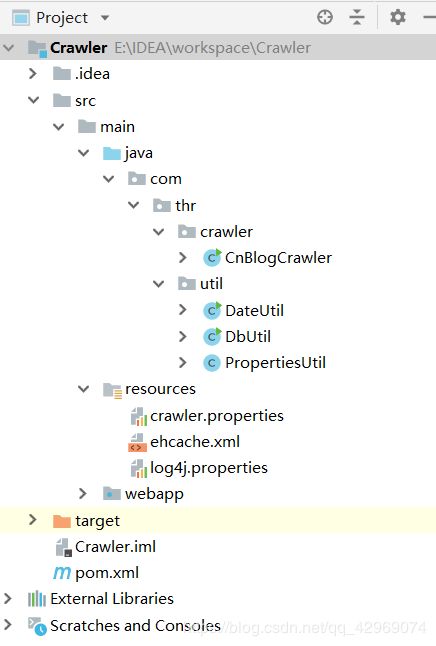
我的项目目录如下:
1.首先创建一个数据库:
/*
Navicat MySQL Data Transfer
Source Server : localhost_3306
Source Server Version : 50720
Source Host : localhost:3306
Source Database : db_blogcrawler
Target Server Type : MYSQL
Target Server Version : 50720
File Encoding : 65001
Date: 2019-01-03 17:21:21
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for `t_blog`
-- ----------------------------
DROP TABLE IF EXISTS `t_blog`;
CREATE TABLE `t_blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(100) DEFAULT NULL,
`content` text,
`crawlerDate` datetime DEFAULT NULL,
`oldUrl` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=20 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of t_blog
-- ----------------------------2. 然后在C盘创建一个ehcache.xml,内容如下:
3.主要代码如下:
package com.thr.crawler;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import java.util.UUID;
import org.apache.commons.io.FileUtils;
import org.apache.http.HttpEntity;
import org.apache.http.ParseException;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.apache.log4j.Logger;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.thr.util.DateUtil;
import com.thr.util.DbUtil;
import com.thr.util.PropertiesUtil;
import net.sf.ehcache.Cache;
import net.sf.ehcache.CacheManager;
import net.sf.ehcache.Status;
/**
* @author Tang Haorong
* @description 主体类
*/
public class CnBlogCrawler {
private static Logger logger=Logger.getLogger(CnBlogCrawler.class);
private static final String URL="http://www.cnblogs.com/";
private static Connection con=null;
private static CacheManager manager=null; // cache管理器
private static Cache cache=null; // cache缓存对象
/**
* 解析主页
*/
private static void parseHomePage(){
while(true){
logger.info("开始爬取"+URL+"网页");
manager= CacheManager.create(PropertiesUtil.getValue("cacheFilePath"));
cache=manager.getCache("cnblog");
CloseableHttpClient httpClient= HttpClients.createDefault(); // 获取HttpClient实例
HttpGet httpget=new HttpGet(URL); // 创建httpget实例
RequestConfig config=RequestConfig.custom().setSocketTimeout(100000) // 设置读取超时时间
.setConnectTimeout(5000) // 设置连接超时时间
.build();
httpget.setConfig(config);
CloseableHttpResponse response=null;
try {
response=httpClient.execute(httpget);
} catch (ClientProtocolException e) {
logger.error(URL+"-ClientProtocolException",e);
} catch (IOException e) {
logger.error(URL+"-IOException",e);
}
if(response!=null){
HttpEntity entity=response.getEntity(); // 获取返回实体
// 判断返回状态是否为200
if(response.getStatusLine().getStatusCode()==200){
String webPageContent=null;
try {
webPageContent= EntityUtils.toString(entity, "utf-8");
parseHomeWebPage(webPageContent);
} catch (ParseException e) {
logger.error(URL+"-ParseException",e);
} catch (IOException e) {
logger.error(URL+"-IOException",e);
}
}else{
logger.error(URL+"-返回状态非200");
}
}else{
logger.error(URL+"-连接超时");
}
try{
if(response!=null){
response.close();
}
if(httpClient!=null){
httpClient.close();
}
}catch(Exception e){
logger.error(URL+"Exception", e);
}
if(cache.getStatus()== Status.STATUS_ALIVE){
cache.flush(); // 把缓存写入文件
}
manager.shutdown();
try {
Thread.sleep(1*60*1000); // 每隔10分钟抓取一次网页数据
} catch (InterruptedException e) {
logger.error("InterruptedException", e);
}
logger.info("结束爬取"+URL+"网页");
}
}
/**
* 解析首页内容 提取博客link
* @param webPageContent
*/
private static void parseHomeWebPage(String webPageContent){
if("".equals(webPageContent)){
return;
}
Document doc= Jsoup.parse(webPageContent);
Elements links=doc.select("#post_list .post_item .post_item_body h3 a");
for(int i=0;i imgUrlList=new LinkedList();
for(int i=0;i0){
Map replaceImgMap=downLoadImages(imgUrlList);
String newContent=replaceWebPageImages(content,replaceImgMap);
content=newContent;
}
// 插入数据库
String sql="insert into t_blog values(null,?,?,now(),?)";
try {
PreparedStatement pstmt=con.prepareStatement(sql);
pstmt.setString(1, title);
pstmt.setString(2, content);
pstmt.setString(3, link);
if(pstmt.executeUpdate()==1){
logger.info(link+"-成功插入数据库");
cache.put(new net.sf.ehcache.Element(link, link));
logger.info(link+"-已加入缓存");
}else{
logger.info(link+"-插入数据库失败");
}
} catch (SQLException e) {
logger.error("SQLException",e);
}
}
/**
* 把原来的网页图片地址换成本地新的
* @param content
* @param replaceImgMap
* @return
*/
private static String replaceWebPageImages(String content, Map replaceImgMap) {
for(String url:replaceImgMap.keySet()){
String newPath=replaceImgMap.get(url);
content=content.replace(url, newPath);
}
return content;
}
/**
* 下载图片到本地
* @param imgUrlList
* @return
*/
private static Map downLoadImages(List imgUrlList) {
Map replaceImgMap=new HashMap();
RequestConfig config=RequestConfig.custom().setSocketTimeout(10000) // 设置读取超时时间
.setConnectTimeout(5000) // 设置连接超时时间
.build();
CloseableHttpClient httpClient=HttpClients.createDefault(); // 获取HttpClient实例
for(int i=0;i 还有一些工具类没有写出来,可以下面的地址下载。
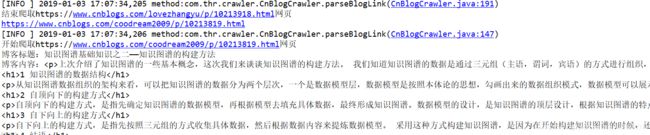
4.运行后的效果;
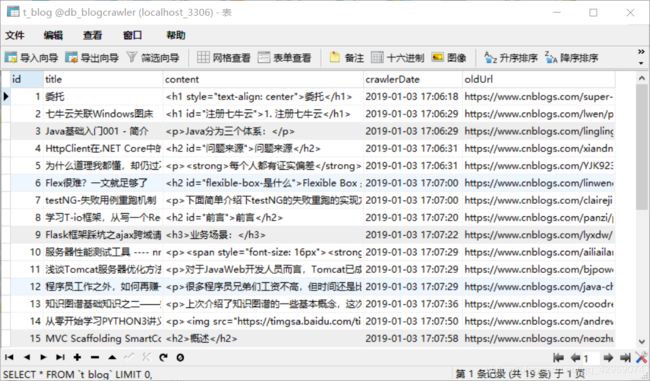
数据库里面数据:
然后图片也有:
GitHub地址:https://github.com/tanghaorong/Crawler