Hadoop技术(三)数据仓库工具Hive
数据仓库工具Hive
- 第一章 hive是什么
- 一 数据仓库工具Hive
- 二 hive架构
- 三 Hive执行流程
- 第二章 Hive的搭建
- 一 Hive的搭建模式介绍
- 二 单用户模式搭建
- 三 多用户模式搭建
- 第三章 Hive语法
- 一 DDL操作
- 二 DML操作
- Insert
- Update
- Other DML
- 三 内部表
- 四 外部表
- 五 Hive分区(静态)
- 单分区
- 单分区中的DML操作
- 双分区
- 双分区中的DML操作
- 六 Hive SerDe(序列化与反序列化)
- 七 Hive Beeline
- 八 Hive JDBC
- 第四章 Hive函数
- 一 常用函数
- 二 自定义函数(案例: 数据脱敏)
- 三 案例补充:
- No1. 实现struct例子(根据要求,在创建表时插入struct类型的数据并查询)
- No2. 基站掉话率:找出掉线率最高的前10基站
- No3. 使用hive实现wordcount
- 第五章 拓展功能
- 一 Hive 参数
- hive参数初始化配置
- hive历史操作命令集
- 二 hive 动态分区
- 三 hive 分桶
- 四 hive Lateral View
- 五 hive View视图
- 六 Hive index索引
- 第六章 Hive运行方式:
- 一 命令行方式
- 二 脚本方式
- 三 JDBC方式:hiveserver2
- 四 Hive Web GUI接口
- 第七章 Hive 权限管理
- 一 三种授权模型
- 二 Hive - SQL Standards Based Authorization in HiveServer2
- Hive权限管理
- 角色管理
- 管理对象权限
- 第八章 Hive优化
- 一 Hive抓取策略:
- 二 Hive运行方式:
- 本地模式
- 集群模式
- 并行计算
- 严格模式
- 三 Hive排序
- 四 Hive Join
- 五 大表join大表
- 六 Map-Side聚合
- 七 合并小文件
- 八 控制Hive中Map以及Reduce的数量
- 九 Hive - JVM重用
- 十 相关资料分享
第一章 hive是什么
博客用到的所有资料都会分享至底部百度云
一 数据仓库工具Hive
背景
hadoop生态系统就是为处理大数据集而产生的一个合乎成本效益的解决方案。hadoop的MapReduce可以将计算任务分割成多个处理单元然后分散到家用的或服务器级别的硬件上,降低成本并提供水平伸缩性。
问题 : 用户如何从一个现有的数据基础架构转移到hadoop上,而这个基础架构是基于传统关系型数据库和SQL的?
介绍
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。Hive官方网址
特点
hive提供了HiveQL方言来查询存储在hadoop集群中的数据。hive可以将大多数的查询转换为MapReduce作业。 eg : select * from tb_user
- hive最适合于数据仓库,使用数据仓库进行相关静态数据分析,而不需要快速响应出结果,而且数据本身不会频繁变化。
- hive不是一个完整的数据库。其中最大的限制就是hive不支持记录级别的更新、插入或者删除操作。 但是可以将查询生成新表或者将查询结果导入到文件中。
- hive查询延时比较严重。
- hive不支持事务。
- HiveQL并不符合ANSI SQL标准,和Oracle、MySQL、SQL Server支持的常规SQL方言在很多方面存在差异,不过HiveQL和MySQL提供的SQL方言最接近。
- Apache Hive™数据仓库软件有助于读取,编写和管理驻留在分布式存储中的大型数据集,并使用SQL语法进行查询。
Hive构建于Apache Hadoop™之上,提供以下功能:
- 通过SQL轻松访问数据的工具,从而实现数据仓库任务,如提取/转换/加载(ETL),报告和数据分析。
- 一种在各种数据格式上强加结构的机制
- 访问直接存储在Apache HDFS™或其他数据存储系统(如Apache HBase™)中的文件 hdfs dfs -ls /
- 通过Apache Tez™,Apache Spark™或MapReduce执行查询
- 使用HPL-SQL的过程语言
- 通过Hive LLAP,Apache YARN和Apache Slider进行亚秒级查询检索。
注意:
- Hive不适用于联机事务处理(OLTP)工作负载。它最适用于传统的数据仓库任务。
- Hive旨在最大限度地提高可伸缩性(通过动态添加到Hadoop集群中的更多计算机扩展),性能,可扩展性,容错性以及与其输入格式的松耦合。
- Hive的SQL也可以通过用户定义的函数(UDF),用户定义的聚合(UDAF)和用户定义的表函数(UDTF)使用用户代码进行扩展。
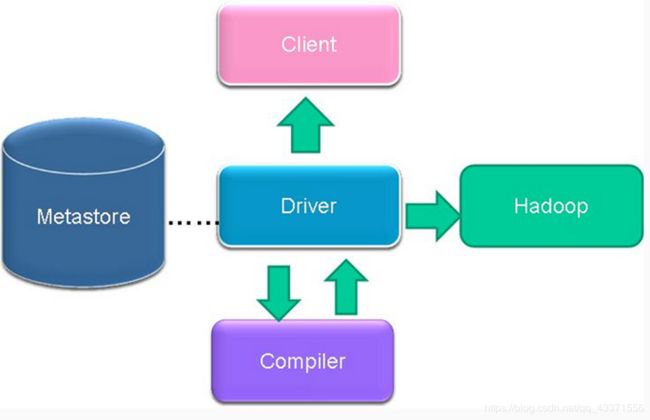
二 hive架构
用户接口主要有三个:CLI,Client 和 WebUI(hwi)。
- CLI: 最常用,Cli启动的时候,会同时启动一个Hive副本。
- Client : Hive的客户端,用户连接至Hive Server。在启动 Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。
- WebUI是可以通过浏览器访问Hive的图形化界面。
在Hadoop 1.x中Hive的架构图
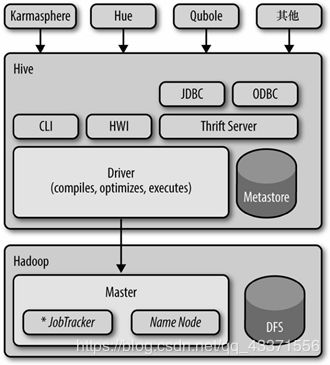
架构解释
- Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
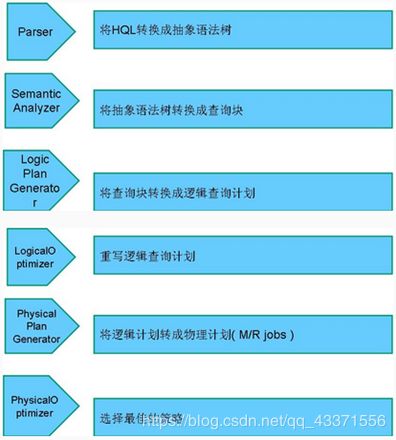
- 解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
- Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tb不会生成MapRedcue任务)
- 注意
① 编译器将一个Hive SQL转换操作符
② 操作符是Hive的最小的处理单元
③ 每个操作符代表HDFS的一个操作或者一个MapReduce作业
在Hadoop 2.x中Hive的架构图
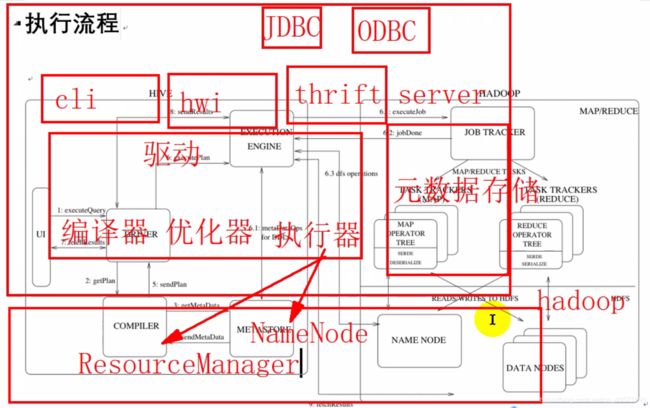
Hive的架构简图
在这里可以回顾一下Hadoop的相关知识:
1.x job tracker 既管资源调度又管任务分配
2.x 分为ResourceManager(资源分配)和DataManager(任务分配)
牢记Hadoop 1.x与2.x架构图
三 Hive执行流程
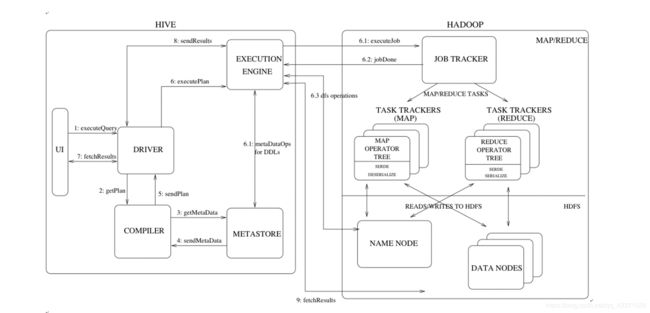
- UI调用驱动程序的执行接口(图1中的步骤1)。
- 驱动程序为查询创建会话句柄,并将查询发送到编译器以生成执行计划(步骤2)。
- 编译器从Metastore获取必要的元数据(步骤3和4)。此元数据用于检查查询树中的表达式以及基于查询谓词的修剪分区。
- 由编译器生成的计划(步骤5)是阶段的DAG(有向无环图),其中每个阶段是mapreduce作业或者元数据操作或者对HDFS的操作。对于map/reduce阶段,计划包含map运算符树(在mapper上执行的运算符树)和reduce运算符树(用于需要reducer的操作)。
- 执行引擎将这些阶段提交给适当的组件(步骤6,6.1,6.2和6.3)。在每个任务(Mapper/Reducer)中,与表或中间输出相关联的反序列化器用于从HDFS文件中读取行,这些行通过关联的运算符树传递。生成输出后,它将通过序列化程序写入临时HDFS文件(如果操作不需要reducer,则会在mapper中发生)。临时文件用于向计划的后续mapreduce阶段提供数据。对于DML操作,最终临时文件将移动到表的位置。此方案用于确保不读取脏数据(文件重命名是HDFS中的原子操作)。
- 对于查询,执行引擎直接从HDFS读取临时文件的内容,作为来自驱动程序的查询的一部分(步骤7,8和9)。
antlr词法语法分析工具解析hql
第二章 Hive的搭建
一 Hive的搭建模式介绍
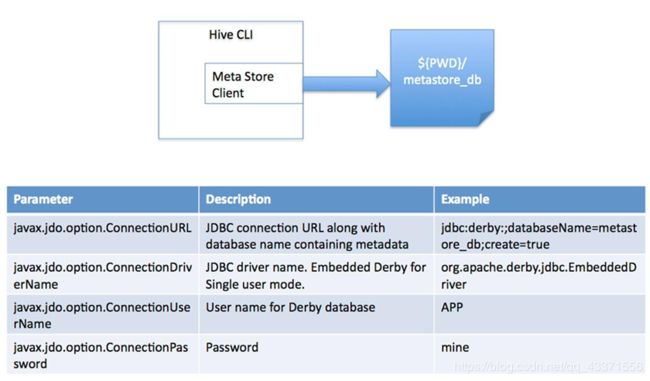
1.内嵌式
此模式连接到一个In-memory 的数据库Derby,一般用于Unit Test。(不常用)
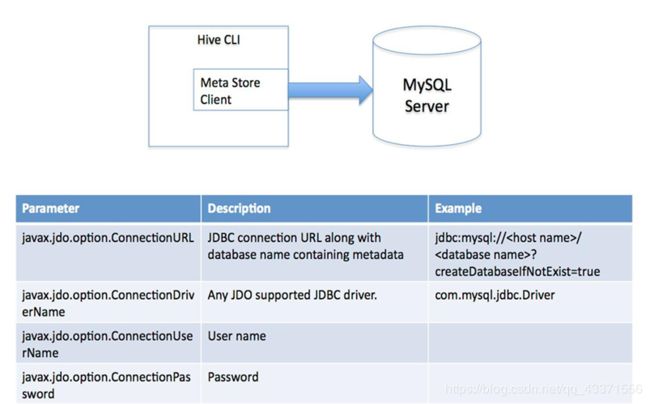
2.单用户模式
又称远程数据库模式 ,hive(node2)和数据库(node1)不在同一个节点 . 通过网络连接到一个数据库中,是最经常使用到的模式
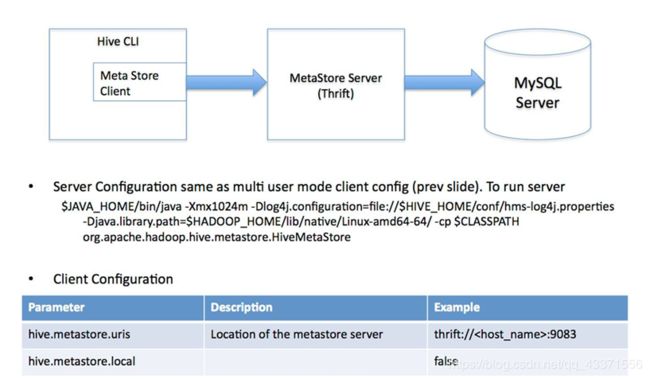
3.多用户模式
又称远程数据库服务模式, 用于非Java客户端访问元数据库,在服务器端启动MetaStoreServer,
客户端利用Thrift协议通过MetaStoreServer访问元数据库
二 单用户模式搭建
node1 :数据源
noed2 :客户端
# 1. node1安装mysql
yum install -y mysql-server
# 启动mysql服务
service mysqld start
# 进入mysql服务
mysql
# 通过yum安装的本机可以直接进入而不需要密码, 所以要修改密码
# 查看所有系统数据库
show database;
# 选择mysql数据库
use mysql;
# 查看mysql数据库下的所有系统表(图1)
show tables;
# 查询mysql系统用户表信息(图2) ,我们要根据这里修改权限信息 . 但是不要直接update修改表,因为这里的显示密码都是被加密后的字符
select host,user,password from user;
# 授权(让其他节点能通过 账号root密码123 远程访问mysql)
grant all privileges on *.* to 'root'@'%' identified by '123' with grant option;
# 删除本地可以无密码访问的账号(作用是让我们只能通过账号密码才能登陆),然后再次查询这个表(图3)
delete from user where host!='%';
# 刷新权限
flush privileges;
# 退出,重新登,使用mysql进行无密码登陆测试,然后通过账号密码登陆测试
quit;
mysql
mysql -uroot -p123
# 2. 启动hdfs+zookeeper+yarn集群环境
# 启动zookeeper(node2,3,4)
zKserver.sh start
# 启动hdfs服务(node1)
start-all.sh
# 启动yarn集群(node1)
start-yarn.sh
# 启动resourcemanager(node3,node4主机节点, 并且注意datanode是否启动)
yarn-daemon.sh start resourcemanager
# 3.安装Hive
# 解压并安装到node2节点 ( 软件见底部,此后都在node2操作 )
# 配置环境变量 (目的: 1找到可执行文件; 2:方便其他软件找到hive服务)
export HIVE_HOME=/opt/chy/apache-hive-1.2.1-bin
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin
# 重载
. /etc/profile
# 测试环境变量配置是否生效
hive + tab +tab
eg:
[root@node2 apache-hive-1.2.1-bin]# hive
hive hive-config.sh hiveserver2
# 4.修改配置文件(conf目录下, 配置文件必须改名才能生效)
# 一定要注意修改自己mysql的地址jdbc:mysql://node1:3306/hive_remote?createDatabaseIfNotExist=true
# /user/hive_remote/warehouse :生成的数据库表存放的hdfs中的目录
mv hive-default.xml.template hive-site.xml
vi hive-site.xml
-----------------在vi hive-site.xml的configuration标签中添加如下内容-----------------
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1:3306/hive_remote?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123</value>
</property>
-----------------在vi hive-site.xml的configuration标签中添加如下内容-----------------
# 5.将jdbc连接驱动包放入hive的lib目录下 ( 分享jar见底部 )
cp mysql-connector-java-5.1.32-bin.jar /opt/chy/apache-hive-1.2.1-bin/lib/
# 6.在命令行输入 hive ,测试能否启动成功,如果出现下面的异常 ,这说明自己hive的jline和hadoop的jline的jar版本不一致
Exception in thread "main" java.lang.IncompatibleClassChangeError: Found class jline.Terminal, but interface was expected
# 7.解决办法: 将高版本的jar复制到低版本的jar上, 并删除低版本的jar
cd /opt/chy/apache-hive-1.2.1-bin/lib/ #hive的jar所在目录
cd /opt/chy/hadoop/share/hadoop/yarn/lib/ #hadoop的jar所在目录
# 图5,图6可以看出hadoop中的 jline-0.9.94.jar 比hive 中的低, 因此删除hadoop中的jline,并将高版本的jline复制到低版本的jline
rm -f jline-0.9.94.jar
cp /opt/chy/apache-hive-1.2.1-bin/lib/jline-2.12.jar /opt/chy/hadoop/share/hadoop/yarn/lib/
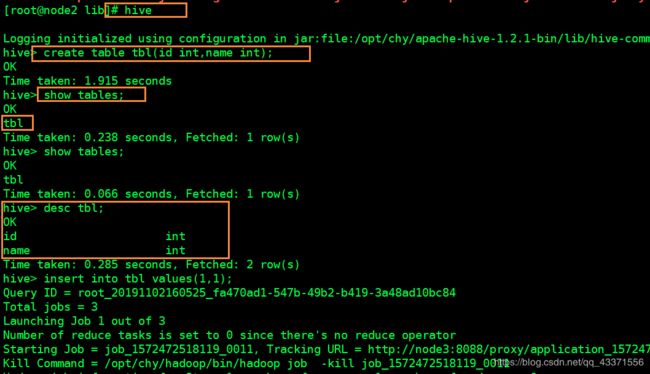
# 8. 测试是否成功(图7),也可以通过hdfs的可视化界面查看
hive
图1
图2
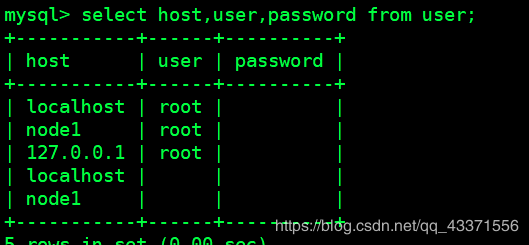
图3 :可以看到只有一个root用户了
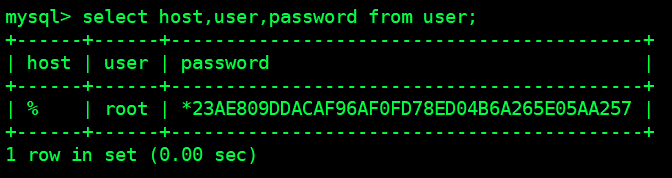
图4
图5
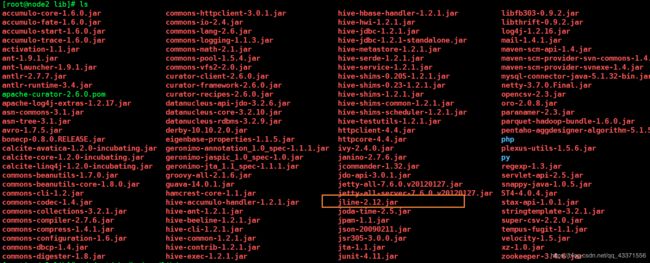
图6

图7
三 多用户模式搭建
node1 :MySQL数据库
node3 服务端
node4 客户端
在单用户模式的基础上搭建,但是与node2上的hive客户端无关
官方安装文档
# 0. 前提
需要安装mysql数据库并启动数据库服务 service mysqld start
# 1. 在单用户模式的基础上, 将配置好的hive的整个文件夹从node2分发到node3,node4对应目录下
scp -r apache-hive-1.2.1-bin/ node3:`pwd`
scp -r apache-hive-1.2.1-bin/ node4:`pwd`
# 2. 在node3,node4中
## 配置环境变量 (目的: 1找到可执行文件; 2:方便其他软件找到hive服务)
export HIVE_HOME=/opt/chy/apache-hive-1.2.1-bin
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin
## 重载
. /etc/profile
## 测试环境变量配置是否生效
hive + tab +tab
eg:hive +tab键+tab键
[root@node3 apache-hive-1.2.1-bin]# hive
hive hive-config.sh hiveserver2
# 3. 修改node3的hive配置文件
# 为了便于在hdfs中区分,修改了hive.metastore.warehouse.dir和javax.jdo.option.ConnectionURL下面的路径,加上了当前节点名称
-------------------------hive-site.xml--------------------------
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote_node3/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1:3306/hive_remote_node3?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123</value>
</property>
-------------------------hive-site.xml--------------------------
# 4. 修改node4的hive配置文件.configuration标签下只有这些内容
-------------------------hive-site.xml--------------------------
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote_node4/warehouse</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node3:9083</value>
</property>
-------------------------hive-site.xml--------------------------
# 5. 启动node3 中的hive ,将其作为源数据, 但是这种启动方式是前置启动 ,占用当前窗口
hive --service metastore
## 我们可以另起一个shell窗口.查看端口9083 是否运行 (图1)
ss -nal
# 6.在node4中,在命令行输入 hive ,测试能否启动成功,如果出现下面的异常 ,这说明自己hive的jline和hadoop的jline的jar版本不一致
Exception in thread "main" java.lang.IncompatibleClassChangeError: Found class jline.Terminal, but interface was expected
# 6.1.将高版本的jar复制到低版本的jar上
cd /opt/chy/apache-hive-1.2.1-bin/lib/ #hive的jar所在目录
ls
cd /opt/chy/hadoop/share/hadoop/yarn/lib/ #hadoop的jar所在目录
ls
# 6.2 可以看出hadoop中的 jline-0.9.94.jar 比hive 中的低, 因此删除hadoop中的jline,并将高版本的jline复制到低版本的jline
rm -f jline-0.9.94.jar
cp /opt/chy/apache-hive-1.2.1-bin/lib/jline-2.12.jar /opt/chy/hadoop/share/hadoop/yarn/lib/
# 6.3 测试是否安装成功,并建表(图2)
hive
# 6.4 我们可以访问hdfs中namenode的图形化界面查看我们新建的表所存放在哪里(图3)
# 6.5 我们可以在表中插入数据然后访问hdfs中namenode的图形化界面查看我们新建的表中的数据(数据插入时间很漫长~~~后面会优化)
图1
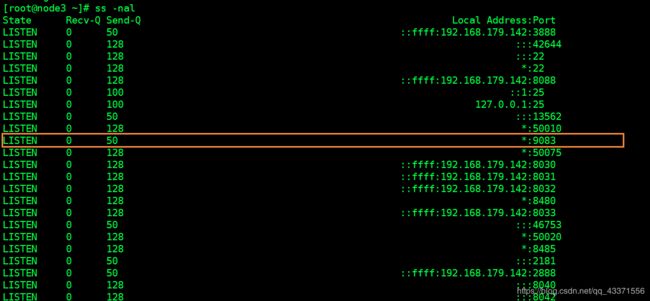
图2
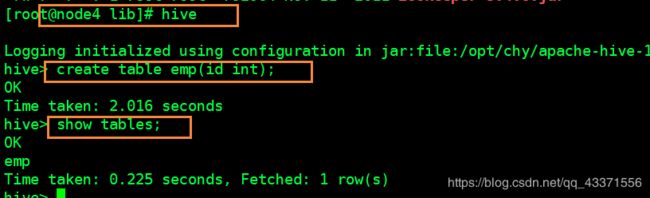
图3

第三章 Hive语法
在第二章中选择单用户模式搭建和多用户模式搭建中的任意一种,进行学习 ,语法基本同数据库一致
官网语法介绍
一 DDL操作
建库语法
# 查看所有数据库
show databases;
# 创建数据库
create database 数据库名;
# 使用当前数据库
use 数据库名;
# 删除数据库
drop database 数据库名;
建表语法
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later)
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| JSONFILE -- (Note: Available in Hive 4.0.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
column_constraint_specification:
: [ PRIMARY KEY|UNIQUE|NOT NULL|DEFAULT [default_value]|CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
default_value:
: [ LITERAL|CURRENT_USER()|CURRENT_DATE()|CURRENT_TIMESTAMP()|NULL ]
constraint_specification:
: [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE
[, CONSTRAINT constraint_name UNIQUE (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
建表举例
# 创建表psn (内部表)
create table tn_emp
(
id int,
name string,
likes array<string>, -- 爱好采用数组类型
address map<string,string> -- 地址采取map类型
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
# 查看表结构以及表信息( 图1, 可以看到不同类型属性之间的分隔符 )
desc formatted 表名
# 插入指定目录下文件的数据(避免使用insert插入数据带来的数据缓慢的问题)
load data local inpath '/root/data/data' into table tb_emp;# local :指定的是本地文件目录
# 创建指定目录文件data
mkdir /root.data
vi data
-------------------data---------------------------
1,小海,dnf-wzry-programer,csdn:timepause-ah:suzhou
2,小海2,dnf-wzry-programer,csdn:timepause-ah:suzhou
3,小海3,dnf-wzry-programer,csdn:timepause-ah:suzhou
4,小海4,dnf-wzry-programer,csdn:timepause-ah:suzhou
5,小海5,dnf-wzry-programer,csdn:timepause-ah:suzhou
6,小海7,dnf-wzry-programer,csdn:timepause-ah:suzhou
8,小海8,dnf-wzry-programer,csdn:timepause-ah:suzhou
8,小海8,dnf-wzry-programer,csdn:timepause-ah:suzhou
9,小海9,dnf-wzry-programer,csdn:timepause-ah:suzhou
-------------------data---------------------------
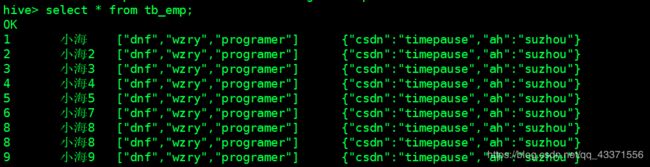
# 查看插入的结果( 图2 )
select * from tb_emp;
图1
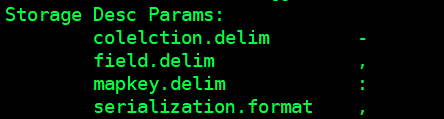
图2
二 DML操作
官方文档 : DML操作
Insert
注意:
load data local inpath +本地url into table 表名; 将本地文件数据插入到数据表
load data inpath +hdfs_url into table 表名; 将hdfs文件数据插入到数据表
向数据库表插入数据的两种方式
# 1. 通过load data local
load data local inpath '本地文件路径' into table 表名;
# 2. 通过 from...insert...select
from 有数据的列名
insert overwrite table 无数据的表名(但列名是有数据列的一个或多个)
select 列1,列2...
insert into 另一个无数据的表名
select 列1,列2...
# 举例:
## 含有数据的表 (通过上面第一种方式插入数据)
create table tb_emp
(
id int,
name string,
likes array<string>, -- 爱好采用数组类型
address map<string,string> -- 地址采取map类型
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
## 第一个无数据的表
create table tb_emp6
(
id int,
name string
)
row format delimited
fields terminated by ',';
## 第二个无数据的表
create table tb_emp7
(
id int,
likes array<string>
)
row format delimited
fields terminated by ','
collection items terminated by '-';
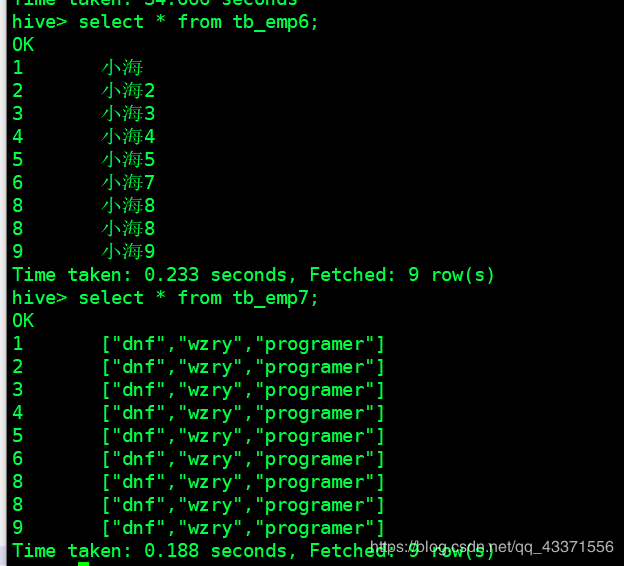
## 利用第二种方式插入数据(图1)
from tb_emp
insert overwrite table tb_emp6
select id,name
insert into tb_emp7
select id,likes
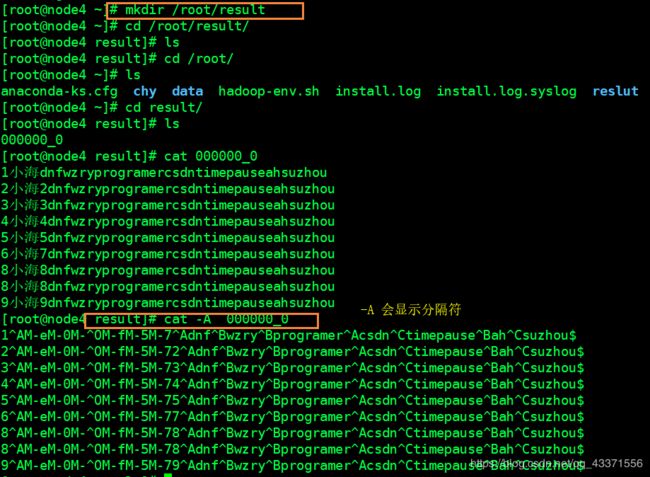
将数据表中的数据写入到本地文件中
这样做的目的是形成目录 ,然后通过目录在构建数据表 ,不建议使用 ,了解即可
# 要写入的文件目录一定不能是 /root , 不然会将 /root下的文件覆盖 ,可以写成/root/xx
insert overwrite local directory '要写入的文件目录' select * from 表名;
# 举例(下图)
hive> insert overwrite local directory '/root/result'
> select * from tb_emp;
Update
默认不支持事务 ,因此对update操作不友好
我们可以认为不支持update ,如果想开启需要手动配置
但是一般不会这样做 ,都会采用追加并覆盖的方式
Other DML
- 清空数据库表
truncate table 表名(不经过事务) - 我们需要知道的是, Hive的所有DML操作都必须经过事务 , 而想要开启事务必须经过相关的配置,但是不建议开启
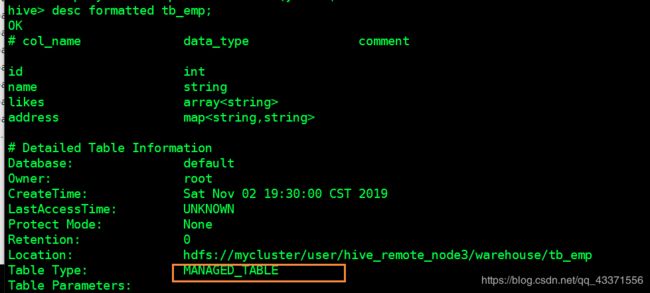
三 内部表
我们可以看到上面例子中我们创建( 正常方式创建 )的就是内部表 ,如下图
四 外部表
在建表时使用关键字 external
创建外部表
# 继续使用上面的data文件 ,上传到hdfs的 /usr目录下
[root@node4 data]# hdfs dfs -mkdir /usr
[root@node4 data]# hdfs dfs -put data /usr/
# 打开hive ,创建外部表
create external table tb_emp2
(
id int,
name string,
likes array<string>, -- 爱好采用数组类型
address map<string,string> -- 地址采取map类型
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/usr/'; -- 注意: location
# 查看表的详细描述信息 (图1). EXTERNAL_TABLE 代表外部表
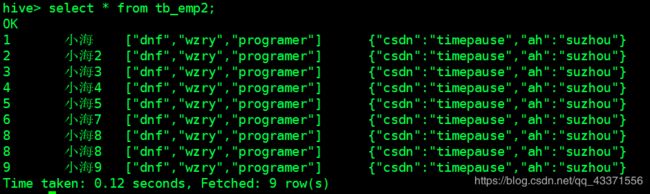
# 而且可以看到 ,通过创建表时用location 指定了表的地址 ,然后该表自动读取了我们放入这个目录下的data文件(图2)
图1
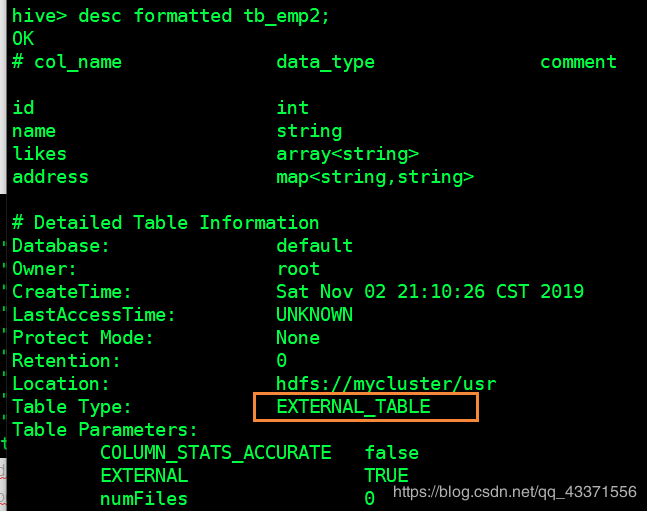
图2
删除表(包括内部表, 外部表)
drop table 表名;
区分内外部表(面试会问) :
- 创建表时 ,内部表直接存储在默认的hdfs路径 .外部表需要自己指定路径
- 删除表时 ,内部表将数据和元数据全部删除 ,外部表只删除元数据,HDFS数据不删除
- 内部表外部表使用原则
先有表,后有数据,使用内部表。先有数据,后有表,使用外部表。
注意:
- 关系数据库 写时检查( mysql / oracle,在我们向数据库中插入数据时会进行sql语句的检查 )
- Hive 读时检查(读取数据时 ,符合规则的才能被读取到 ,否则为null ; 作用: 解耦,便于数据读取)
# eg: 案例中的定义的表的规则 row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':'
五 Hive分区(静态)
注意:
- 分区表的意义在于优化查询( 例如经常按天查询, 建议按天进行分区 )。
- 查询时尽量利用分区字段。如果不使用分区字段,就会全部扫描。
- 分区属于元数据,不能通过外部表直接从 HDFS 加载 Hive 中,必须在表定义时指定对应的partition字段
- 分区列也是一个普通的列 ,也就是说我们书写了分区列后在建表中不用再写一次
元数据(Metadata),又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。元数据算是一种电子式目录,为了达到编制目录的目的,必须在描述并收藏数据的内容或特色,进而达成协助数据检索的目的。
单分区
语法
partitioned by(列名 列类型)
举例
create table tb_emp3
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(age int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
查看表的详细信息 ( 分区信息,下图 )
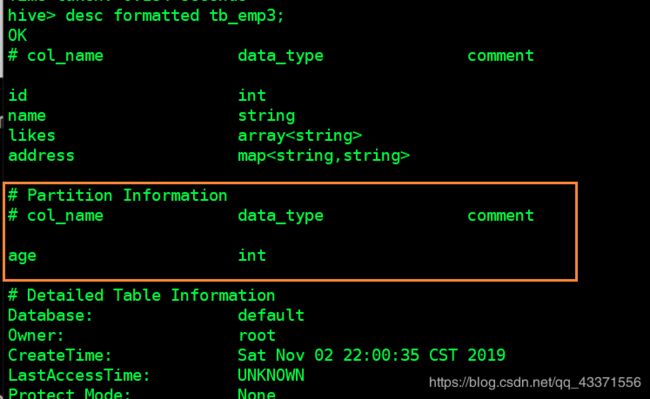
单分区中的DML操作
语法
# 向单分区的数据表中插入data文件中的数据 ,并指定年龄为10
load data local inpath '/root/data/data' into table 表名 partition(分区列名=分区列的值);
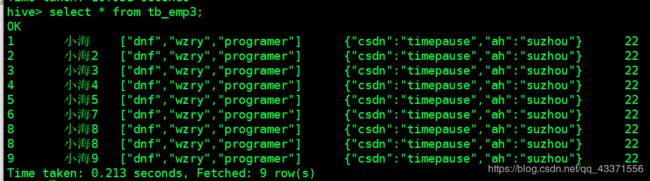
双分区
理论上分区的个数没有限制, 但是分区数越多, 在hdfs中创建的目录越多
找数据会越难找 ,因此建议将需要经常被查询的字段设置成分区
语法
partitioned by(列名 列类型,列名 列类型...)
举例
create table tb_emp4
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(age int,sex string)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
查看表结构详情
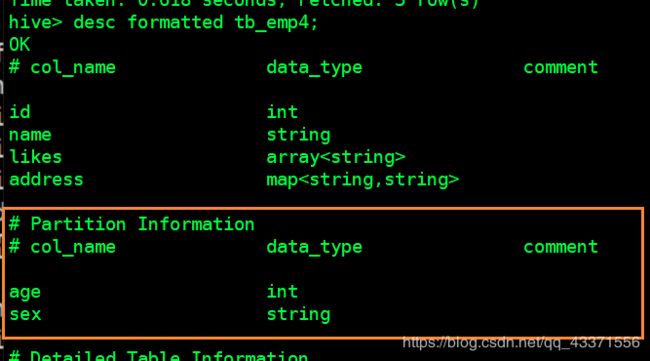
双分区中的DML操作
添加分区时, 我们必须指定两个字段
但是在删除分区, 我们至少指定一个字段即可
官方文档 : DML操作
语法
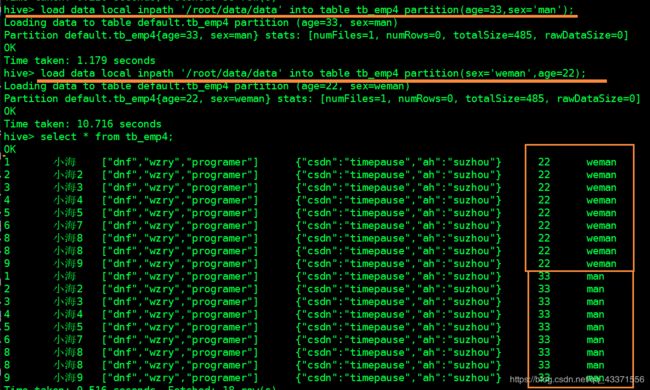
# 1.添加分区
# 为分区列赋值时,与列的顺序无关(创建目录并导入数据 )
load data local inpath '/root/data/data' into table 表名 partition(分区列名=分区列的值,分区列名=分区列的值...);
# 只创建相关分区目录,不导入数据
alter table 表名 add partition partition(分区列名=分区列的值,分区列名=分区列的值...);
# 2.删除分区 (至少指定一个字段, 但是对应赋值的都会被删除!!!)
alter table 表名 drop partition partition(分区列名=分区列的值);
1. 添加分区成功后, 查看表内容
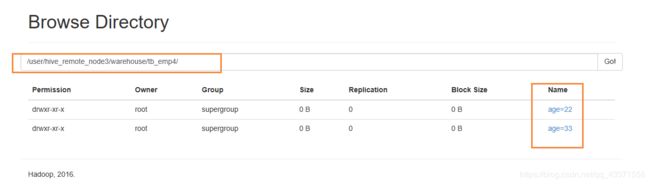
2. 在HDFS文件系统图形化界面查看分区表信息
从下图我们可以看到每个分区目录下会将我们给分区赋的值创建为它的子目录
而我们的表信息就存储在这些子目录下


六 Hive SerDe(序列化与反序列化)
Hive SerDe - Serializer and Deserializer
SerDe 用于做序列化和反序列化。
构建在数据存储和执行引擎之间,对两者实现解耦。
Hive通过ROW FORMAT DELIMITED以及SERDE进行内容的读写。
语法
row_format
: DELIMITED
[FIELDS TERMINATED BY char [ESCAPED BY char]]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char]
: SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
举例( 使用正则只是序列化反序列化的一种手段 )
# 1. 新建一个表logtbl,并指定插入数据的规则
CREATE TABLE logtbl (
host STRING,
identity STRING,
t_user STRING,
time STRING,
request STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*)\" (-|[0-9]*) (-|[0-9]*)"
)
STORED AS TEXTFILE;
# 2. 在/root/data下创建文件
# log.txt
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-upper.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-nav.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /asf-logo.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-button.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-middle.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /asf-logo.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-middle.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-button.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-nav.png HTTP/1.1" 304 -
# 3. 通过load方式加载本地文件向表中插入数据
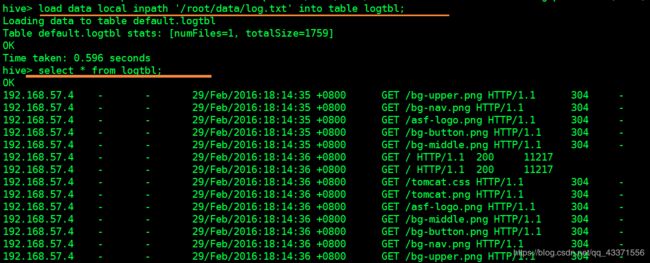
load data local inpath '/root/data/log.txt' into table logtbl;
# 4.查看数据表, 下图
七 Hive Beeline
beenline 提供了 JDBC 的访问方式, 不能用于 DML 操作,只能执行一些查询操作
Beeline和其他工具有一些不同,执行查询都是正常的SQL输入
但是如果是一些管理的命令,比如进行连接,中断,退出,执行Beeline命令需要带上“!”,不需要终止符。常用命令介绍:
# 1. beeline的可以使用在内嵌模式,也可以使用再远程模式,只需要在含有hive工具的虚拟机中启动hiveserver2便可通过jdbc访问
# 前置式启动,阻塞窗口
hiveserver2
# 2. beeline的使用 !connect jdbc:hive2://url ,url中需要有类似用户名密码的字符串,但不一定是用户名和密码
## 第一种方式
[root@node4 ~]# beeline
beeline> !connect jdbc:hive2://node3:10000/default root 123
!connect jdbc:hive2://node3:10000/default suibian 123456
### 第一次访问进入后利用hive查询当前表(show tables;)可能会报如下异常 ,解决方式是退出重新登陆一下即可
### Error: Error while compiling statement: FAILED: ParseException line 2:5 extraneous input 'tables' expecting EOF near '' (state=42000,code=40000)
## 第二种方式 beeline -u jdbc:hive2://url, url可以不用谢四类用户名和密码的字符串
beeline -u jdbc:hive2://node3:10000/default (-n root:以管理员方式访问)
## 退出
!quit # 直接退出到虚拟机的bash shell
!close # 退出到beeline shell,然后ctrl+c 退出到虚拟机的bash shell
注意:
1. beeline的可以使用在内嵌模式,也可以使用再远程模式,只需要在含有hive工具的虚拟机中启动hiveserver2便可通过jdbc访问
2. 如果想通过jdbc访问 , 同样也要有hive的相关jar包
3. 通过这种方式访问,只能查询
八 Hive JDBC
测试代码
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class HiveJdbcClient {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
Connection conn = DriverManager.getConnection("jdbc:hive2://node4:10000/default", "root", "");
Statement stmt = conn.createStatement();
String sql = "select * from tb_emp limit 5";
ResultSet res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "-" + res.getString("name"));
}
}
}
测试结果

注意 :项目的运行需要有hive的jar包支持, 如下
第四章 Hive函数
一 常用函数
hive函数:官方文档
举例
# 查看 tb_emp表中likes列中,数组值为0的列
select likes[0] from tb_emp;
# 查看 tb_emp表中address列中,mqp值为csdn的列
select address['csdn'] from tb_emp;
# 查看 tb_emp表中address列中,mqp值为csdn , ah的列
select address['csdn'],address['ah'] from tb_emp;
# size函数: 计数
select size(likes),size(address) from tb_emp;
# lpad:填充函数
hive> select lpad(name,30,'@') from tb_emp;
OK
@@@@@@@@@@@@@@@@@@@@@@@@小海
@@@@@@@@@@@@@@@@@@@@@@@小海2
@@@@@@@@@@@@@@@@@@@@@@@小海3
@@@@@@@@@@@@@@@@@@@@@@@小海4
@@@@@@@@@@@@@@@@@@@@@@@小海5
@@@@@@@@@@@@@@@@@@@@@@@小海7
@@@@@@@@@@@@@@@@@@@@@@@小海8
@@@@@@@@@@@@@@@@@@@@@@@小海8
@@@@@@@@@@@@@@@@@@@@@@@小海9
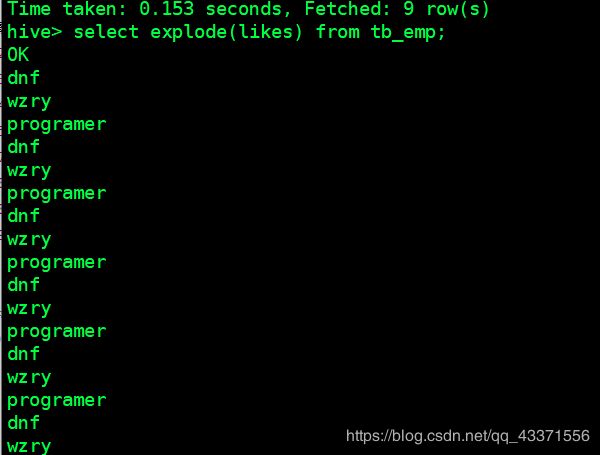
# explode: 将制定列下的值,显示成一行,然后输出( 图1 )
hive> select explode(likes) from tb_emp;
二 自定义函数(案例: 数据脱敏)
以脱敏功能为例, 演示自定义函数步骤
脱敏 对敏感数据部分进行加密处理:,使其可以被我们用来进行数据分析
三 案例补充:
No1. 实现struct例子(根据要求,在创建表时插入struct类型的数据并查询)
1.建表
create table student(id int, info struct<name:string, age:int>)
row format delimited
fields terminated by ','
collection items terminated by ':';
2.在本地创建文件
vi stu.txt
-----stu.txt----
1,chx:22
2,xhy:33
3,cxy:44
4,cxx:55
-----stu.txt----
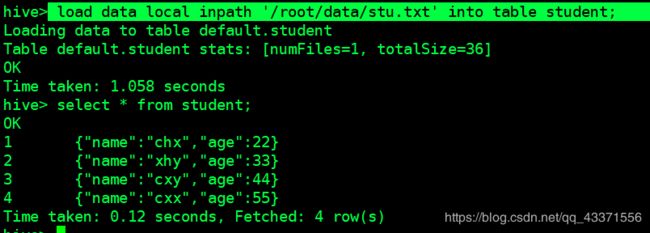
3.插入数据load data local inpath '/root/data/stu.txt' into table student;
4.查询
No2. 基站掉话率:找出掉线率最高的前10基站
record_time:通话时间
imei:基站编号
cell:手机编号
drop_num:掉话的秒数
duration:通话持续总秒数
1.创建word文本文件,并上传到hdfs上
# 文件见底部资料分享
cdr.txt
# hdfs 上传
hdfs dfs -put cdr.txt /user/root/hive/wc
2.创建基站表,存放基站信息
create external table jizhan(
record_time string,
imei string,
cell string,
ph_num int,
call_num int,
drop_num int,
duration int,
drop_rate int,
net_type string,
erl int
)
row format delimited
fields terminated by ','
location '/user/hive/cdr';
3 查看数据是否插入成功
select * from jizhan limit 10;
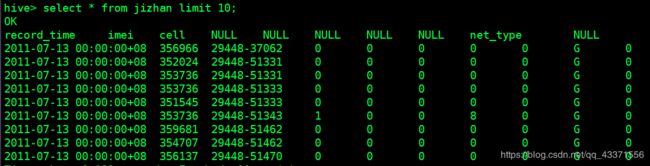
4.创建掉话率结果表
create table jizhan_result(
imei string, -- 基站数
drop_num int, -- 掉话数
duration int, --通话数
drop_rate double -- 掉话率
);
5.统计掉话数,总通话数, 掉话率信息,插入到掉话结果表中
from jizhan
insert into jizhan_result
select imei,sum(drop_num) sdrop,sum(duration) sdura,sum(drop_num)/sum(duration) drate
group by imei
order by drate desc;

No3. 使用hive实现wordcount
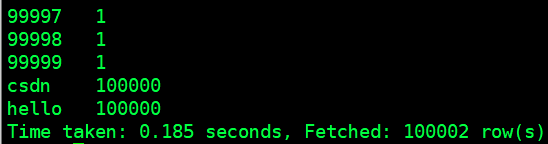
1.创建word文本文件,并上传到hdfs上
# 文件的生成(内容 hello csdn1-100000 )
for i in `seq 100000`;do echo "hello csdn $i" >> testhive.txt;done
# hdfs 上传
hdfs dfs -put testhadoop.txt /user/root/hive/wc
2.创建外部表,location指定该文件 ,作用是将内容插入到数据表中
create external table wc(
line string
)
location '/user/root/hive/wc'
3.表中所有数据平铺成一列显示
-- split分割函数. explode将函数体内的字段排成一行
select explode(split(line,' ')) from wc;
4.创建结果表,存放查询结果
create table wc_result(
word string, -- 单词
ct int --单词数
);
5.调用count()函数,对每个单词分别进行统计,然后通过word进行分组 ,将结果放入结果表
from ( select explode(split(line,' ')) word from wc ) t
insert into wc_result
select word,count(word) group by word;
1.定义函数
需要继承UDF类
该函数的作用 : 对第一个字符之后的数据进行加密, 用" * "处理
package ah.szxy.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class TuoMin extends UDF {
public Text evaluate(final Text s) {
if (s == null) {
return null;
}
//substring:包前不包后,也就是说是保留字符串前1字符,后面的用***表示
String str = s.toString().substring(0, 1) + "***";
return new Text(str);
}
}
2.打成jar包并上传到hdfs指定目录hdfs dfs -put tm.jar /usr
3.在hive中创建临时函数(通过指定目录下的jar)
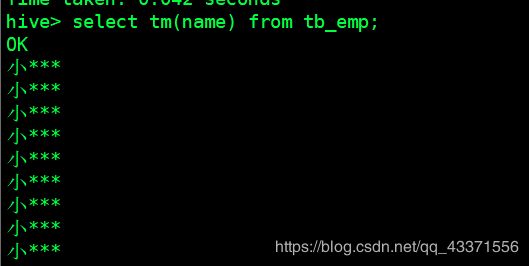
create temporary function tm as 'ah.szxy.hive.TuoMin' using jar 'hdfs://node1:8020/usr/tm.jar';
4.测试效果select tm(name) from tb_emp;
第五章 拓展功能
一 Hive 参数

注意:
- hive当中的参数、变量,都是以命名空间开头
- 通过${}方式进行引用,其中system、env下的变量必须以前缀开头
举例
# hiveconf 类似在xml配置文件进行相关配置 ,不过只在当前会话有效
## hive.cli.header=true 显示当前数据表的表头
[root@node2 ~]# hive --hiveconf hive.cli.header=true
## hive命令行下显示表头
hive> set hive.cli.print.header=true;
## 显示所有设置信息
hive> set;
# 查看相hive帮助(下图)
hive --help
hive --cli # 显示hive的cli帮助
# 在hive中未变量赋值
## 方式一
hive --d abc=1
## 方式二
hive --hivevar abc=1
hive> select * from emp where id=${abc};
hive参数初始化配置
当前用户家目录下的.hiverc文件
如: ~/.hiverc
如果没有,可直接创建该文件,将需要设置的参数写到该文件中,hive启动运行时,会加载改文件中的配置。
# 例如将这里的set语句写入~/.hiverc文件中,则运行时会自动读取该文件 ,为我们显示数据表列名信息
---------------.hiverc-----------------
set hive.cli.print.header=true;
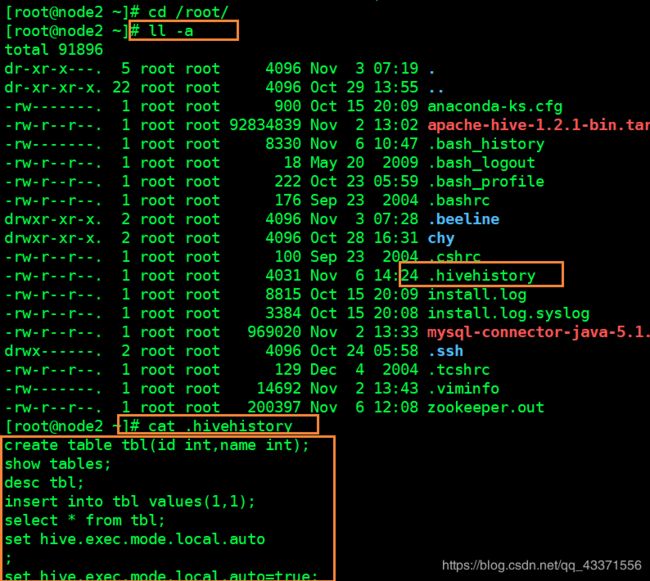
hive历史操作命令集
# 如果是root用户.则是在/root目录下
cat /root/.hivehistory
# 如果是普通用户,则是在 /home目录下
cat /home/.hivehistory
二 hive 动态分区
用于接入离线的数据 ,而不是实时数据
开启支持动态分区
- set hive.exec.dynamic.partition=true;
默认:true - set hive.exec.dynamic.partition.mode=nostrict;
默认:strict(至少有一个分区列是静态分区)
相关参数( 这些参数与硬件挂钩 )
- set hive.exec.max.dynamic.partitions.pernode;
每一个执行mr节点上,允许创建的动态分区的最大数量(100) - set hive.exec.max.dynamic.partitions;
所有执行mr节点上,允许创建的所有动态分区的最大数量(1000) - set hive.exec.max.created.files;
所有的mr job允许创建的文件的最大数量(100000)
举例
# 1.创建数据表
create table emp
(
id int,
name string,
age int,
sex string,
likes array<string>, -- 爱好采用数组类型
address map<string,string> -- 地址采取map类型
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
# 2.用于插入表的数据文件
1,小海1,12,man,dnf-wzry-programer,csdn:timepause-ah:suzhou
2,小海2,13,man,dnf-wzry-programer,csdn:timepause-ah:suzhou
3,小海3,14,man,dnf-wzry-programer,csdn:timepause-ah:suzhou
4,小海4,15,woman,dnf-wzry-programer,csdn:timepause-ah:suzhou
5,小海5,16,man,dnf-wzry-programer,csdn:timepause-ah:suzhou
6,小海7,17,man,dnf-wzry-programer,csdn:timepause-ah:suzhou
8,小海8,11,woman,dnf-wzry-programer,csdn:timepause-ah:suzhou
8,小海8,12,man,dnf-wzry-programer,csdn:timepause-ah:suzhou
9,小海9,11,woman,dnf-wzry-programer,csdn:timepause-ah:suzhou
# 3.将数据导入
load data local inpath '/root/data/data' into table emp;
# 4.创建动态分区数据表
create table emp2
(
id int,
name string,
likes array<string>, -- 爱好采用数组类型
address map<string,string> -- 地址采取map类型
)
partitioned by(age int,sex string)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
# 5,为动态分区数据表插入数据
## 方式一
from emp
insert into emp2 partition(age ,sex )
select id,name,likes,address,age,sex;
## 方式二
insert into emp2 partition(age ,sex )
select id,name,likes,address,age,sex from emp;
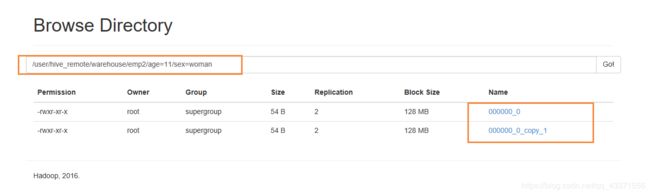
# 6.插入后,可以看到每个分区文件存放分区结果相同的数据存放到同一个文件
注意 : 我们可通过 hdfs dfs -cat 指定目录(类似下图) 查看分区下面的数据文件,保存的是分区信息相同的数据
三 hive 分桶
分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储。
对于hive中每一个表、分区都可以进一步进行分桶。
由列的哈希值除以桶的个数来决定每条数据划分在哪个桶中。
-
适用场景:
数据抽样( sampling ) -
开启支持分桶
set hive.enforce.bucketing=true;
默认:false;设置为true之后,mr运行时会根据bucket的个数自动分配reduce task个数。(用户也可以通过mapred.reduce.tasks自己设置reduce任务个数,但分桶时不推荐使用) -
注意:一次作业产生的桶(文件数量)和reduce task个数一致。
-
往分桶表中加载数据
insert into table bucket_table select columns from tbl; insert overwrite table bucket_table select columns from tbl; -
分区分桶是相互独立的, 可以单独设计
TABLESAMPLE语法:
TABLESAMPLE(BUCKET x OUT OF y)
x:表示从哪个bucket开始抽取数据
y:必须为该表总bucket数的倍数或因子
TABLESAMPLE举例

分桶案例实现
-
开启分桶
set hive.enforce.bucketing=true; -
创建数据表
CREATE TABLE stu( id INT, name STRING, age INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; -
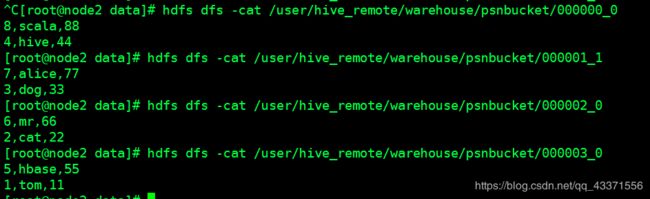
数据表中的数据
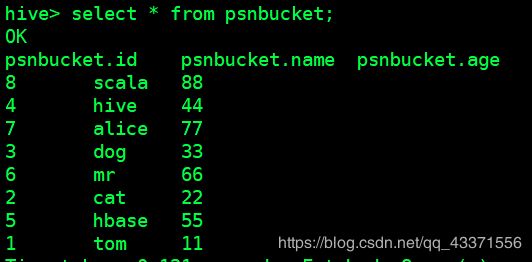
1,tom,11 2,cat,22 3,dog,33 4,hive,44 5,hbase,55 6,mr,66 7,alice,77 8,scala,88 -
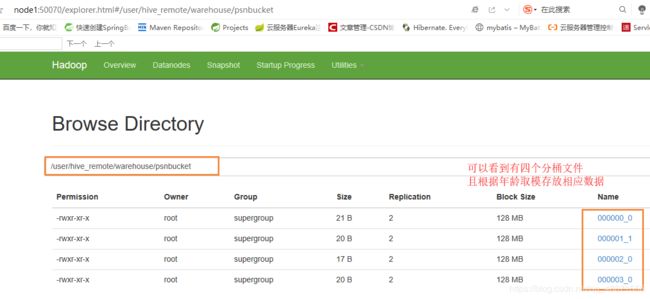
创建分桶表(指定4个分桶)
CREATE TABLE psnbucket( id INT, name STRING, age INT) CLUSTERED BY (age) INTO 4 BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; -
加载数据:
insert into table psnbucket select id, name, age from stu; -
从分桶表抽样
select id, name, age from psnbucket tablesample(bucket 2 out of 4 on age); -
测试
在dhfs中查看分桶文件
查看该文件的具体内容
分桶表信息
抽样结果

四 hive Lateral View
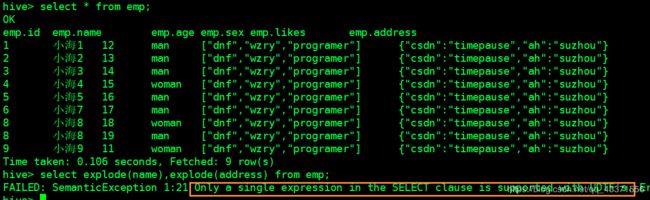
Lateral View用于和UDTF函数(explode、split)结合来使用。
首先通过UDTF函数拆分成多行,再将多行结果组合成一个支持别名的虚拟表。
主要解决在select使用UDTF做查询过程中,查询只能包含单个UDTF,不能包含其他字段、以及多个UDTF的问题
语法:
LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)
举例
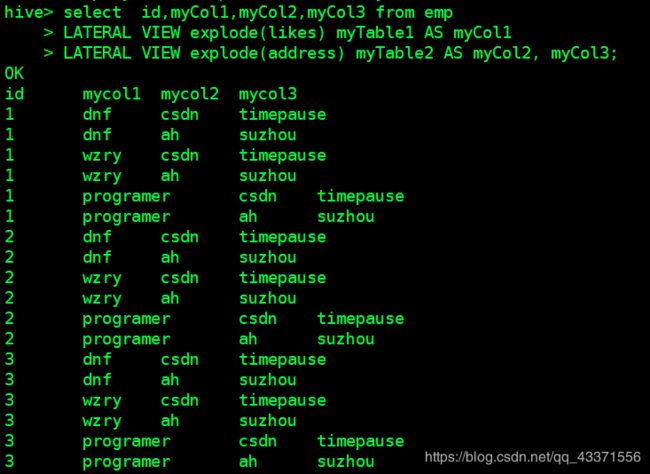
select id,myCol1,myCol2,myCol3 from emp
LATERAL VIEW explode(likes) myTable1 AS myCol1 -- myTable1 表别名, myCol1 列likes别名
LATERAL VIEW explode(address) myTable2 AS myCol2, myCol3; -- myTable2 表别名, myCol2,myCol3列address别名
五 hive View视图
和关系型数据库中的普通视图一样,hive也支持视图
特点:
- 不支持物化视图
- 只能查询,不能做加载数据操作
- 视图的创建,只是保存一份元数据,查询视图时才执行对应的子查询
- view定义中若包含了ORDER BY/LIMIT语句,当查询视图时也进行ORDER BY/LIMIT语句操作,view当中定义的优先级更高
- view支持迭代视图
View语法
-
创建视图:
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name [(column_name [COMMENT column_comment], ...) ] [COMMENT view_comment] [TBLPROPERTIES (property_name = property_value, ...)] AS SELECT ... ; -
查询视图:
select colums from view; -
删除视图:
DROP VIEW [IF EXISTS] [db_name.]view_name;
六 Hive index索引
目的:优化查询以及检索性能( 一般在数据量巨大的时候使用 )
- 创建索引:
create index t1_index on table emp(name)
as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild
in table t1_index_table;
as:指定索引器;
in table:指定索引表,若不指定默认生成在default__emp_t1_index__表中
- 查询索引
show index on emp; - 重建索引(建立索引之后必须重建索引才能生效)
ALTER INDEX t1_index ON emp REBUILD; - 删除索引
DROP INDEX IF EXISTS t1_index ON emp;( 删除索引后才能删除索引表 )
举例
-- 1.存放索引新的表格,指定表存放index
create index t1_index on table emp(name)
as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild
in table t1_index_table ;
-- 2.不指定表存放index
create index t2_index on table emp2(name)
as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild;
-- 3.令索引生效
ALTER INDEX t1_index ON emp REBUILD;
-- 4. 查询生效后的索引表( 图1)
select * from t1_index_table;
-- 5. 根据索引表的name属性查询对应的信息( 图2 )
select * from emp where name='小海1';
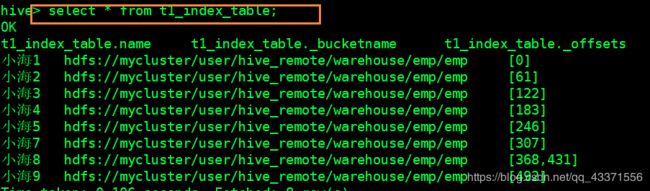
根据索引表的name属性查询对应的信息

第六章 Hive运行方式:
- 命令行方式cli:控制台模式
- 脚本运行方式(实际生产环境中用最多)
- JDBC方式:hiveserver2
- web GUI接口 (hwi、hue等)
一 命令行方式
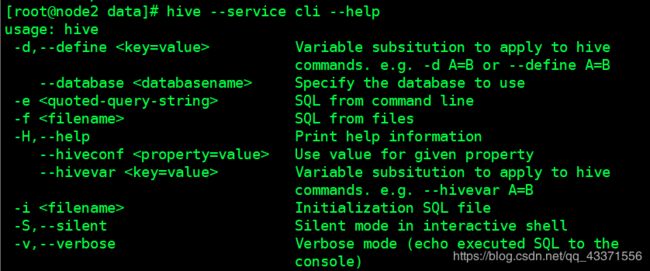
# 1. hive的cli下dfs命令
## hdfs 查询文件内容
hdfs dfs -cat /user/hive_remote/warehouse/emp/emp;
## Hive在CLI模式中与hdfs交互 ,执行执行dfs命令
hive> dfs -cat /user/hive_remote/warehouse/emp/emp;
# 2. Hive脚本运行方式:
hive -e "" # hive -e: 可以跟多个查询语句,执行命令后退出hive shell
hive -e "">aaa # 执行""内hive命令 ,输出到aaa文件
hive -S -e "">aaa # 静默模式输出,参数顺序不能改
hive -f file # 从文件中读取hive命令(例如 hiveQL语句)
hive -i /home/my/hive-init.sql # 读取初始化hive命令文件 ,执行命令后不会退出 hive shell
hive> source file (在hive cli中运行) # 在hive shell 中执行外部命令文件
二 脚本方式
举例
-
在bash shell中执行查询数据库表操作 ,并在脚本中运行
# 1.编写脚本 vim show_emp_table ----------------- show_emp_table--------------- hive -e "select * from emp;" ----------------- show_emp_table--------------- # 2.赋予执行权限 chmod +x hive.sh # 3. 运行脚本(徐图) ./show_emp_table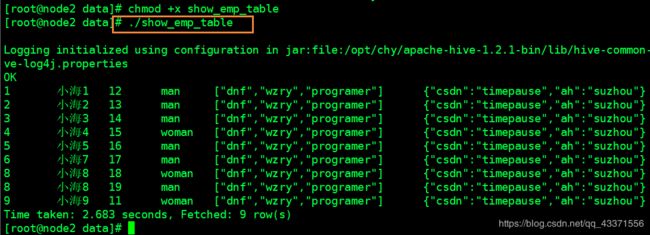
-
在bash shell中执行查询数据库表操作 ,并在脚本中运行,并在另一个文件中输出( 文本重定向 )
# 1.修改上个例子show_emp_table文件中的内容 hive -e "select * from emp;" >>a.txt # 2.运行,并查看该文件(下图)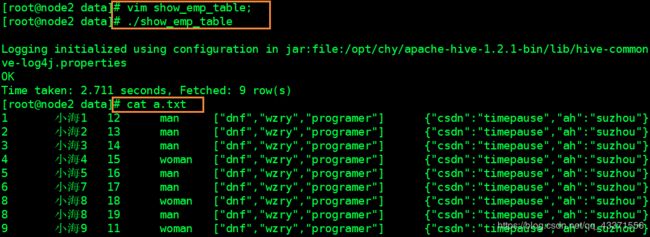
三 JDBC方式:hiveserver2
见第三章 第七节,第八节
四 Hive Web GUI接口
hwi界面安装:
这里不建议使用hwi ,因为查询结果会叠加显示,另外操作不方便
更多情况会使用 hue,hue的搭建在后面会提到
下载源码包apache-hive-*-src.tar.gz
将hwi war包放在$HIVE_HOME/lib/
制作方法:将hwi/web/*里面所有的文件打成war包
cd apache-hive-1.2.1-src/hwi/web
jar -cvf hive-hwi.war *
复制tools.jar(在jdk的lib目录下)到$HIVE_HOME/lib下
修改hive-site.xml
启动hwi服务(端口号9999)
hive --service hwi
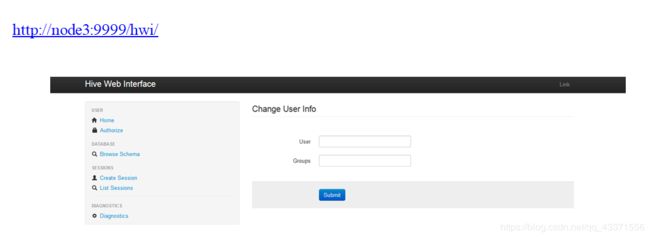
浏览器通过以下链接来访问
http://node3:9999/hwi/
修改hive配置文件hive-site.xml添加以下配置内容:
hive.hwi.listen.host
0.0.0.0
hive.hwi.listen.port
9999
hive.hwi.war.file
lib/hive-hwi.war
第七章 Hive 权限管理
hive官方文档:权限操作
一 三种授权模型
- Storage Based Authorization in the Metastore Server
基于存储的授权 - 可以对Metastore中的元数据进行保护,但是没有提供更加细粒度的访问控制(例如:列级别、行级别)。 - SQL Standards Based Authorization in HiveServer2
基于SQL标准的Hive授权 - 完全兼容SQL的授权模型,推荐使用该模式。 - Default Hive Authorization (Legacy Mode)
hive默认授权 - 设计目的仅仅只是为了防止用户产生误操作,而不是防止恶意用户访问未经授权的数据。
二 Hive - SQL Standards Based Authorization in HiveServer2
hive官方文档:基于SQL基准的权限授予语法
特点:
- 完全兼容SQL的授权模型
- 除支持对于用户的授权认证,还支持角色role的授权认证
- role可理解为是一组权限的集合,通过role为用户授权
- 一个用户可以具有一个或多个角色
- 默认包含两种角色:public、admin
限制:
- 启用当前认证方式之后,dfs, add, delete, compile, and reset等命令被禁用。
- 通过set命令设置hive configuration的方式被限制某些用户使用。
(可通过修改配置文件hive-site.xml中hive.security.authorization.sqlstd.confwhitelist进行配置) - 添加、删除函数以及宏的操作,仅为具有admin的用户开放。
- 用户自定义函数(开放支持永久的自定义函数),可通过具有admin角色的用户创建,其他用户都可以使用。
- Transform功能被禁用。
使用前提 : 在hive服务端(node3)修改配置文件hive-site.xml添加以下配置内容:
基于多用户模式环境下配置
<property>
<name>hive.security.authorization.enabledname>
<value>truevalue>
property>
<property>
<name>hive.server2.enable.doAsname>
<value>falsevalue>
property>
<property>
<name>hive.users.in.admin.rolename>
<value>rootvalue>
property>
<property>
<name>hive.security.authorization.managername>
<value>org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactoryvalue>
property>
<property>
<name>hive.security.authenticator.managername>
<value>org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticatorvalue>
property>
Hive权限管理
角色的添加、删除、查看、设置:
- CREATE ROLE role_name; – 创建角色
- DROP ROLE role_name; – 删除角色
- SET ROLE (role_name|ALL|NONE); – 设置角色
- SHOW CURRENT ROLES; – 查看当前具有的角色(所有用户可用)
- SHOW ROLES; – 查看所有存在的角色(admin/root用户可用)
使用
# 1. 启动服务端
[root@node3 conf]# hive --service metastore
# 2.另开一个shell 窗口
[root@node3 ~]# hiveserver2
# 3.通过jdbc方式登入hive的cli (使用的是普通用户abc,可以随便写)
[root@node2 ~]# beeline
beeline> !connect jdbc:hive2://node3:10000/default abc abc
# 4. 测试该角色的权限 (下图1)
show tables;
show current roles;
create roles test;
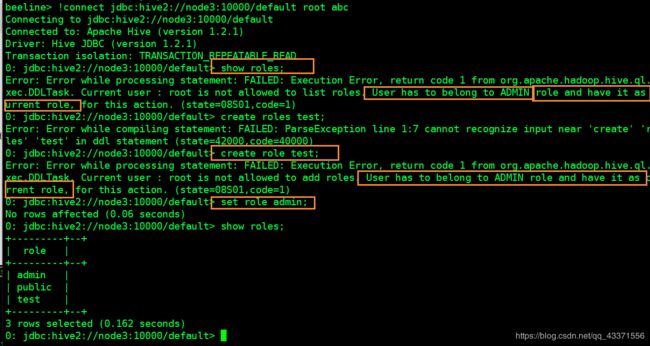
# 5.使用root用户登陆,测试相关权限(图2)
[root@node2 ~]# beeline
beeline> !connect jdbc:hive2://node3:10000/default abc abc
## 发现下面命令还是不能够执行
show roles;
create roles test;
## 虽然是admin ,但是没有设置角色所包含的权限,因此需要授予角色权限
set role admin;
## 再次测试发现成功
图1
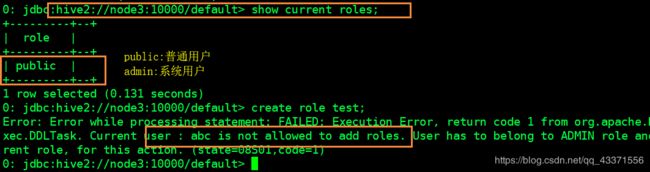
图2
角色管理
授予角色
将一个或多个角色授予其他角色或用户。
如果指定了“ WITH ADMIN OPTION”,则用户将获得将角色授予其他用户/角色的特权。
如果Grant语句最终在角色之间创建了循环关系,则该命令将失败并显示错误。
GRANT role_name [, role_name] ...
TO principal_specification [, principal_specification] ...
[ WITH ADMIN OPTION ];
principal_specification
: USER user
| ROLE role
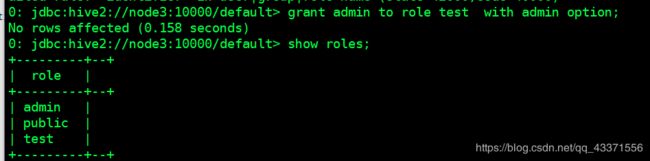
撤销角色
在FROM子句中从用户/角色撤消角色的成员资格。
从Hive 0.14.0开始,可以使用REVOKE ADMIN OPTION FOR (HIVE-6252)撤消ADMIN OPTION 。
REVOKE [ADMIN OPTION FOR] role_name [, role_name] ...
FROM principal_specification [, principal_specification] ... ;
principal_specification
: USER user
| ROLE role
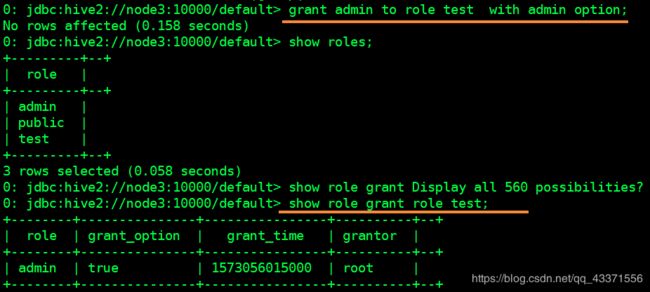
显示角色授予
列出已授予给定用户或角色的所有角色。
当前,任何用户都可以运行此命令。但这将来可能会改变,以允许用户仅查看自己的角色授予,并且需要其他特权才能查看其他用户的角色授予。
SHOW ROLE GRANT (USER|ROLE) principal_name;
principal_name用户或角色的名称在哪里。

管理对象权限
对象授权与撤销
如果授予用户对表或视图的WITH GRANT OPTION特权,则该用户还可以授予/撤消其他用户的特权以及这些对象上的角色。与标准SQL不同,在Hive中,必须在principal_specification中指定USER或ROLE。
-- 授权
GRANT
priv_type [, priv_type ] ...
ON table_or_view_name
TO principal_specification [, principal_specification] ...
[WITH GRANT OPTION];
--撤消
REVOKE [GRANT OPTION FOR]
priv_type [, priv_type ] ...
ON table_or_view_name
FROM principal_specification [, principal_specification] ... ;
principal_specification
: USER user
| ROLE role
priv_type
: INSERT | SELECT | UPDATE | DELETE | ALL
例子:
0: jdbc:hive2://localhost:10000/default> grant select on table secured_table to role my_role;
No rows affected (0.046 seconds)
0: jdbc:hive2://localhost:10000/default> revoke update, select on table secured_table from role my_role;
No rows affected (0.028 seconds)

显示授权(表)信息
当前,任何用户都可以运行此命令。但这在将来可能会改变,以允许用户仅查看自己的特权,并且需要其他特权才能查看其他用户的特权。
SHOW GRANT [principal_specification] ON (ALL | [TABLE] table_or_view_name);
principal_specification
: USER user
| ROLE role
第八章 Hive优化
面试很可能会遇到这些问题, 尽量结合真实环境去讲解
简历,设计,让面试官通过你的简历能够了解你能学到什么 ,写即为会
而且问的都是你要让他们问你的东西!!!
- 核心思想:把Hive SQL 当做Mapreduce程序去优化
- 以下SQL不会转为Mapreduce来执行
select仅查询本表字段
where仅对本表字段做条件过滤 - Explain 显示执行计划
EXPLAIN [EXTENDED] query
一 Hive抓取策略:
Hive中对某些情况的查询不需要使用MapReduce计算
抓取策略命令
Set hive.fetch.task.conversion=none/more;
# more(默认):开启此策略
# none : 关闭此策略,即每次执行简单的sql操作都会进行mr计算操作
二 Hive运行方式:
本地模式
开启本地模式:
开启本地模式后,计算会在本地,而不是在集群中
这样做的作用是提高hive查询效率(开发,测试环境常用)
使用
set hive.exec.mode.local.auto=true;
注意:
hive.exec.mode.local.auto.inputbytes.max 默认值为128M ,表示加载文件的最大值,若大于该配置仍会以集群方式来运行!
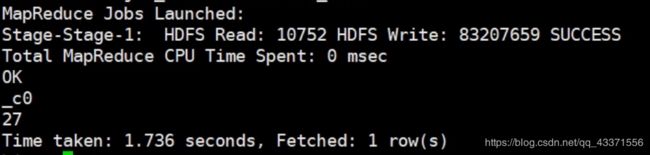
集群模式
未开启本地模式之前, 使用的就是集群模式(默认此模式)
利用集群模式进行MapReduce计算, 用时如下图

开启本地模式之后
可以看到, 开启本地模式后, sql语句的运行速率提升了很高
并行计算
通过设置以下参数开启并行模式:
set hive.exec.parallel=true;
注意:
hive.exec.parallel.thread.number;一次SQL计算中允许并行执行的job个数的最大值,默认值为8
严格模式
通过设置以下参数开启严格模式(默认为:nonstrict非严格模式):
set hive.mapred.mode=strict;
查询限制:
- 对于分区表,必须添加where对于分区字段的条件过滤(图1);
- order by语句必须包含limit输出限制(图2);
- 限制执行笛卡尔积的查询。
- 这些限制的目的是帮助我们提升查询效率
图1
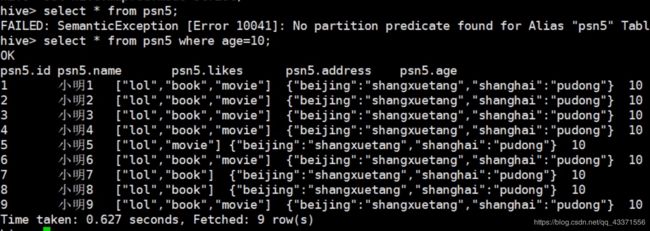
图2

三 Hive排序
- Order By - 对于查询结果做全排序,只允许有一个reduce处理
(当数据量较大时,应慎用。严格模式下,必须结合limit来使用) - Sort By - 对于单个reduce的数据进行排序
- Distribute By - 分区排序,经常和Sort By结合使用
- Cluster By - 相当于 Sort By + Distribute By(Cluster By不能通过asc、desc的方式指定排序规则;
可通过 distribute by column sort by column asc|desc 的方式)
四 Hive Join
官方文档:jion语法
- Join计算时,将小表(驱动表)放在join的左边
- Map Join:在Map端完成Join
- 大表小表依据是表文件内存大小
两种实现方式:
-
SQL方式,在SQL语句中添加MapJoin标记(mapjoin hint)
语法:SELECT /*+ MAPJOIN(smallTable) */ smallTable.key, bigTable.value FROM smallTable JOIN bigTable ON smallTable.key = bigTable.key; -
开启自动的MapJoin
通过修改以下配置启用自动的mapjoin:set hive.auto.convert.join = true;注意 :
- 该参数为true时,Hive自动对左边的表统计量,如果是小表就加入内存,即对小表使用Map join
- 尽可能使用相同的连接键(会转化为一个MapReduce作业)
相关配置参数:
- hive.mapjoin.smalltable.filesize;
(大表小表判断的阈值(约25MB),如果表的大小小于该值则会被加载到内存中运行) - hive.ignore.mapjoin.hint;
(默认值:true;是否忽略mapjoin hint 即mapjoin标记 ,手动自动冲突时 ,使用自动设置策略) - hive.auto.convert.join.noconditionaltask;
(默认值:true;将普通的join转化为普通的mapjoin时,是否将多个mapjoin转化为一个mapjoin) - hive.auto.convert.join.noconditionaltask.size;
(将多个mapjoin转化为一个mapjoin时,其表的最大值)
五 大表join大表
-Hive优化(面试可能会用)
空key过滤:
有时join超时是因为某些key对应的数据太多,而相同key对应的数据都会发送到相同的reducer上,从而导致内存不够。此时我们应该仔细分析这些异常的key,很多情况下,这些key对应的数据是异常数据,我们需要在SQL语句中进行过滤。
空key转换:
有时虽然某个key为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在join的结果中,此时我们可以表a中key为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的reducer上
六 Map-Side聚合
通过设置以下参数开启在Map端的聚合:
set hive.map.aggr=true;
相关配置参数:
- hive.groupby.mapaggr.checkinterval:
map端group by执行聚合时处理的多少行数据(默认:100000) - hive.map.aggr.hash.min.reduction:
进行聚合的最小比例(预先对100000条数据做聚合,若聚合之后的数据量/100000的值大于该配置0.5,则不会聚合) - hive.map.aggr.hash.percentmemory:
map端聚合使用的内存的最大值 - hive.map.aggr.hash.force.flush.memory.threshold:
map端做聚合操作是hash表的最大可用内容,大于该值则会触发flush - hive.groupby.skewindata
是否对GroupBy产生的数据倾斜做优化,默认为false(建议开启)
七 合并小文件
文件数目小,容易在文件存储端造成压力,给hdfs造成压力,影响效率
设置合并属性
- 是否合并map输出文件:
hive.merge.mapfiles=true - 是否合并reduce输出文件:
hive.merge.mapredfiles=true; - 合并文件的大小:
hive.merge.size.per.task=256*1000*1000
去重统计
数据量小的时候无所谓,数据量大的情况下,由于COUNT DISTINCT操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换
八 控制Hive中Map以及Reduce的数量
Map数量相关的参数
- mapred.max.split.size
一个split的最大值,即每个map处理文件的最大值 - mapred.min.split.size.per.node
一个节点上split的最小值 - mapred.min.split.size.per.rack
一个机架上split的最小值
Reduce数量相关的参数
- mapred.reduce.tasks
强制指定reduce任务的数量 - hive.exec.reducers.bytes.per.reducer
每个reduce任务处理的数据量 - hive.exec.reducers.max
每个任务最大的reduce数
九 Hive - JVM重用
适用场景:
1、小文件个数过多
2、task个数过多
-
通过
set mapred.job.reuse.jvm.num.tasks=n;设置(n为task插槽个数) -
缺点:设置开启之后,task插槽会一直占用资源,不论是否有task运行,直到所有的task即整个job全部执行完成时,才会释放所有的task插槽资源!
思维导图总结
直接查看不清晰可保存查看

十 相关资料分享
所有资料分享至百度云
链接:https://pan.baidu.com/s/1AiS2MsA7zheKQk9isXVniw
点赞私聊即可获取提取码~~~
提取码:q838
复制这段内容后打开百度网盘手机App,操作更方便哦