六、Python 组合数据类型
- 本文是网课:Python语言程序设计国家精品——(北京理工大学 嵩天 、 黄天羽 、 礼欣)的学习笔记。
目录
6.1 集合类型及操作
6.2 序列类型及操作
6.3 实例9:基本统计值计算
6.4 字典类型及操作
6.5 模块5:jieba库的使用
6.6 实例10:文本词频统计
6.1 集合类型及操作
- 集合类型定义


关于Python的元组:
- Python的元组与列表类似,不同之处在于元组的元素不能修改。
- 元组使用小括号,列表使用方括号。
- 元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
- 集合操作符


- 集合处理方法


- 集合类型应用场景
- 包含关系比较(数据是否在集合中 用 in )
- 数据去重

6.2 序列类型及操作
- 序列类型定义

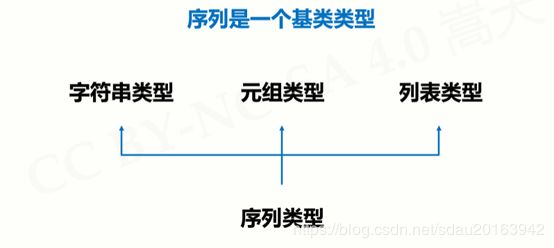
- 序列处理函数及方法
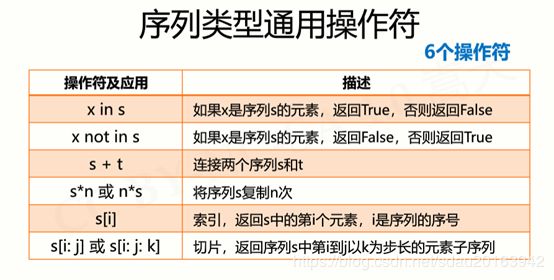

- 元组类型及操作



- 列表类型及操作

注意列表赋值只是重新命名


注意上面表中第二行,ls[i:j:k] = lt ; 其中等号两边元素个要相同否则会报错。除非切片出来的序列下标是连续的一片。
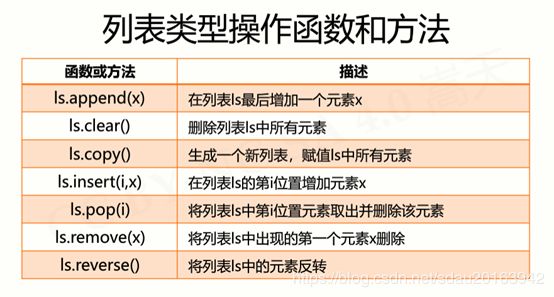
- 序列类型应用场景

6.3 实例9:基本统计值计算


代码:
#CalStatisticsV1.py
def getNum(): #获取用户不定长度的输入
nums = []
iNumStr = input("请输入数字(回车退出):")
while iNumStr != "":
nums.append(eval(iNumStr))
iNumStr = input("请输入数字(回车退出):")
return nums
def mean(numbers): #计算平均值
s = 0.0
for num in numbers:
s = s + num
return s / len(numbers)
def dev(numbers,mean): #计算方差
sdev = 0.0
for num in numbers:
sdev = sdev + (num-mean)**2
return pow(sdev / (len(numbers)-1),0.5)
def median(numbers): #计算中位数
sorted(numbers)
size = len(numbers)
if size %2 == 0:
med = (numbers[size//2-1]+numbers[size//2])/2
else:
med = numbers[size//2]
return med
n = getNum()
m = mean(n)
print("平均值:{},方差:{:.2},中位数:{}.".format(m,dev(n,m),median(n)))6.4 字典类型及操作
- 字典类型的定义



- type(变量) #检测变量类型
- 字典处理函数即方法
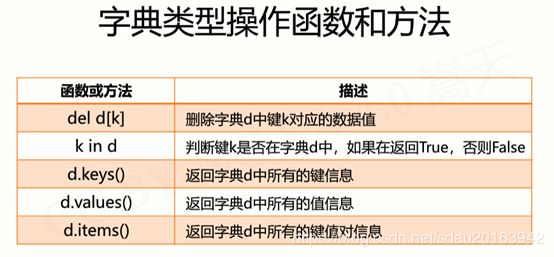
d.values()和d.keys()返回的不是列表类型,只是字典的values和keys类型,可以进行for in遍历

- 字典类型应用场景


6.5 模块5:jieba库的使用
- jieba库基本介绍
我的电脑安装pip时发现没有pip程序?解决方法如下:
首先运行安装python时的程序,幸好我的还没删,python-3.7.2-amd64.exe
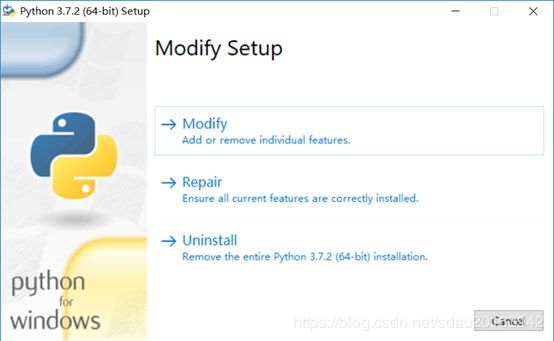
点击Modify
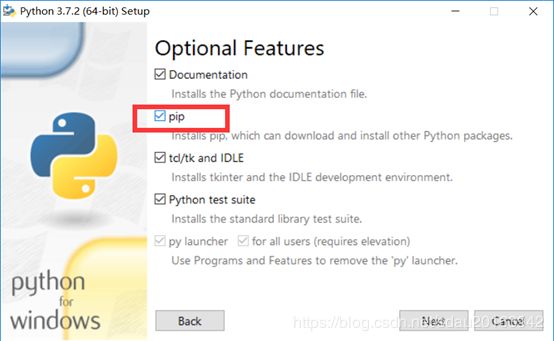
将pip前面的复选框勾上即可。


- jieba库使用说明



6.6 实例10:文本词频统计
- 一篇文章,出现了那些词,那些词出现的最多?

https://python123.io/resources/pye/hamlet.txt
https://python123.io/resources/pye/threekingdoms.txt
- “Hamlet英文词频统计”实例讲解
#CalHamletV1.py
def getText():
txt = open("D:\PyCharm 2018.3.5\PycharmProjects\Hamlet.txt", "r").read()
txt = txt.lower() #字母全变为小写
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~': #将所有符号都换为空格符
txt = txt.replace(ch, " ")
return txt
#得到所有单词间都是都好分隔的字符串
HamletTxt = getText()
#将字符串中信息用空格分隔并返回列表类型
words = HamletTxt.split()
#字典counts保存单词出现次数
counts = {}
for word in words:
counts[word] = counts.get(word, 0)+1
#字典类型转变为列表类型
items = list(counts.items())
#sort函数的参数key指定多元数据中作为排序数据的元素,reverse=True设置为降序排列
items.sort(key=lambda x: x[1], reverse=True)
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))- “《三国演义》人物出场统计”实例讲解(上)
#CalThreeKingdomsV1.py
import jieba
txt = open("D:\PyCharm 2018.3.5\PycharmProjects\ThreeKingdoms.txt", "r", encoding="utf-8").read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0)+1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(15):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))注意:
- 如果open读取txt文件时,出现UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc8 in position 0: invalid continuation byte报错。
- 可以打开原txt然后另存为新的txt,只需要在另存为时保存为utf-8编码即可。
- “《三国演义》人物出场统计”实例讲解(下)
import jieba
txt = open("D:\PyCharm 2018.3.5\PycharmProjects\ThreeKingdoms.txt", "r", encoding="utf-8").read()
words = jieba.lcut(txt)
excludes = {"将军", "却说", "荆州", "二人", "不可", "不能", "如此", "商议", "如何"}
counts = {}
for word in words:
rword = word
if len(word) == 1:
continue
elif word == "诸葛亮" or word == "孔明曰":
rword = "孔明"
elif word == "关公" or word == "云长":
rword = "关羽"
elif word == "玄德" or word == "玄德曰":
rword = "刘备"
elif word == "孟德" or word == "丞相":
rword = "曹操"
else:
rowrd = word
counts[rword] = counts.get(rword, 0)+1
for word in excludes:
del counts[word]
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))