逻辑回归算法分析
逻辑回归可以解决分类问题,属于监督学习。
一、sigmoid函数
定义: σ ( x ) = 1 1 + e − x , x ϵ R \sigma(x) = \frac{1}{1 + e^{-x}}, \ \ x \epsilon \mathbb{R} σ(x)=1+e−x1, xϵR,其值范围为(0, 1),函数图形如下图所示:
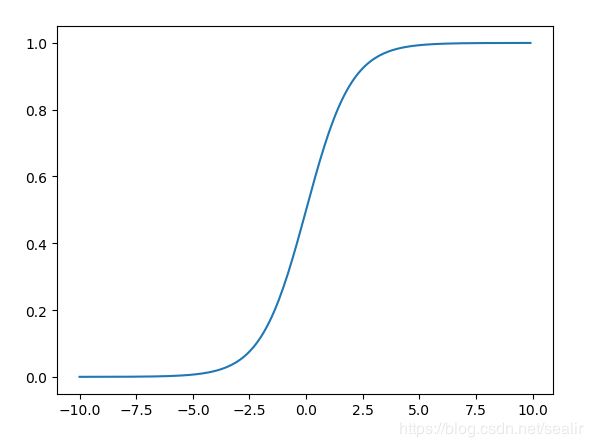
sigmoid函数有以下的性质:
1、 σ ′ ( x ) = σ ( x ) [ 1 − σ ( x ) ] \sigma'(x) = \sigma(x)[1 - \sigma(x)] σ′(x)=σ(x)[1−σ(x)]
2、 σ ( x ) + σ ( − x ) = 1 \sigma(x) + \sigma(-x) = 1 σ(x)+σ(−x)=1
3、 [ l o g σ ( x ) ] ′ = σ ′ ( x ) σ ( x ) = 1 − σ ( x ) [log\sigma(x)]' = \frac{\sigma'(x)}{\sigma(x)} = 1 - \sigma(x) [logσ(x)]′=σ(x)σ′(x)=1−σ(x)
4、 [ l o g ( 1 − σ ( x ) ) ] ′ = − σ ′ ( x ) 1 − σ ( x ) = − σ ( x ) [log(1 - \sigma(x))]' = \frac{-\sigma'(x)}{1 - \sigma(x)} = - \sigma(x) [log(1−σ(x))]′=1−σ(x)−σ′(x)=−σ(x)
二、二分类
设 X = { x 1 , x 2 , ⋯ , x n } X=\left \{ x_1, x_2, \cdots, x_n \right \} X={x1,x2,⋯,xn},可以把 X X X理解成某种对象, x 1 , x 2 , ⋯ , x n x_1, x_2, \cdots, x_n x1,x2,⋯,xn是对象的特征。
引入分类向量 θ = { θ 1 , θ 2 , ⋯ , θ n } \theta=\left \{ \theta_1, \theta_2, \cdots, \theta_n \right \} θ={θ1,θ2,⋯,θn}
定义: σ ( X ∣ θ ) = 1 1 + e − X T θ \sigma(X|\theta) = \frac{1}{1 + e^{-X^T\theta}} σ(X∣θ)=1+e−XTθ1,在给定 θ \theta θ时, σ \sigma σ函数可以将 X X X映射到(0,1)之间,如果将 σ ( x ) > 0.5 \sigma(x) > 0.5 σ(x)>0.5视为正类, σ ( x ) < 0.5 \sigma(x) < 0.5 σ(x)<0.5视为负类,则可以将sigmoid函数用于解决分类问题。
在 σ ( X ∣ θ ) \sigma(X|\theta) σ(X∣θ)函数中,有一个 θ \theta θ参数,如果已知这个参数,那么该函数可以用于分类。但如果只有数据集 { x 1 , x 2 , ⋯ , x n } \left \{ x_1, x_2, \cdots, x_n \right \} {x1,x2,⋯,xn},并已经数据集的分类标签 { y 1 , y 2 , ⋯ , y n } \left \{ y_1, y_2, \cdots, y_n \right \} {y1,y2,⋯,yn},那么怎样得到参数 θ \theta θ呢?这就是训练问题了。
三、逻辑回归训练
给定样本集 X = { x 1 , x 2 , ⋯ , x n } X = \left \{ x_1, x_2, \cdots, x_n \right \} X={x1,x2,⋯,xn}和样本对应的分类标签 { y 1 , y 2 , ⋯ , y n } , y i ϵ { 0 , 1 } \left \{ y_1, y_2, \cdots, y_n \right \}, y_i \epsilon \left \{ 0, 1 \right \} {y1,y2,⋯,yn},yiϵ{0,1},怎样从样本集中训练得到 θ \theta θ参数呢?
定义:
极大似然函数: ∏ x ϵ X p ( y ∣ x , θ ) \prod_{x \epsilon X}p(y|x, \theta) ∏xϵXp(y∣x,θ),将其取对数后得到:
极大对数似然函数: £ = ∑ x ϵ X l o g p ( y ∣ x , θ ) \pounds = \sum_{x \epsilon X} log \ p(y|x, \theta) £=∑xϵXlog p(y∣x,θ)
条件概率: p ( y ∣ x , θ ) = { σ ( x T θ ) , y = 1 1 − σ ( x T θ ) , y = 0 p(y|x, \theta) = \left\{\begin{matrix}\sigma (x^T \theta), \quad \quad \ \ y = 1 & \\ & \\ 1 - \sigma (x^T \theta), \quad y = 0 & \end{matrix}\right. p(y∣x,θ)=⎩⎨⎧σ(xTθ), y=11−σ(xTθ),y=0
怎么理解上面的极大似然呢?考虑到分类的目的,最理想的结果是:分类器将样本集分成两类,一类包含全部的正类,一类包含全部的负类。但由于样本集存在噪声,这种理想结果是不可能达到的,在这种情况下,分类器的最优结果是:将更多的真实的正类样本标记为正类,将更多的真实的负类样本标记为负类。
所以在优化的过程中,采用梯度上升法,对 θ \theta θ进行优化,让 ∏ x ϵ X p ( y ∣ x , θ ) \prod_{x \epsilon X}p(y|x, \theta) ∏xϵXp(y∣x,θ)到达极大值。
将 p ( y ∣ x , θ ) p(y|x, \theta) p(y∣x,θ)写成整体得: p ( y ∣ x , θ ) = [ σ ( x T θ ) ] y ⋅ [ 1 − σ ( x T θ ) ] 1 − y p(y|x, \theta) = [\sigma (x^T \theta)]^{y} \cdot [1 - \sigma (x^T \theta)]^{1 - y} p(y∣x,θ)=[σ(xTθ)]y⋅[1−σ(xTθ)]1−y,代入对数似然函数得:
£ = ∑ x ϵ X l o g p ( y ∣ x , θ ) \pounds = \sum_{x \epsilon X} log \ p(y|x, \theta) £=∑xϵXlog p(y∣x,θ)
= ∑ x ϵ X l o g [ σ ( x T θ ) ] y ⋅ [ 1 − σ ( x T θ ) ] 1 − y =\sum_{x \epsilon X} log \ [\sigma (x^T \theta)]^{y} \cdot [1 - \sigma (x^T \theta)]^{1 - y} =∑xϵXlog [σ(xTθ)]y⋅[1−σ(xTθ)]1−y
= ∑ x ϵ X { y ⋅ log [ σ ( x T θ ) ] + [ 1 − y ] ⋅ l o g [ 1 − σ ( x T θ ) ] } =\sum_{x \epsilon X}\left \{ y \cdot \log [\sigma (x^T \theta)] + [1 - y] \cdot log [1 - \sigma (x^T \theta)] \right \} =∑xϵX{y⋅log[σ(xTθ)]+[1−y]⋅log[1−σ(xTθ)]}
函数中只有一个参数 θ \theta θ, £ \pounds £关于 θ \theta θ的梯度:
∂ £ ∂ θ = ∂ ∂ θ { y ⋅ l o g [ σ ( x T θ ) ] + [ 1 − y ] ⋅ l o g [ 1 − σ ( x T θ ) ] } \frac{\partial \pounds}{\partial \theta} = \frac{\partial }{\partial \theta}\left \{ y \cdot log [\sigma (x^T \theta)] + [1 - y] \cdot log [1 - \sigma (x^T \theta)] \right \} ∂θ∂£=∂θ∂{y⋅log[σ(xTθ)]+[1−y]⋅log[1−σ(xTθ)]}
= y ⋅ [ 1 − σ ( x T θ ) ] x − [ 1 − y ] ⋅ [ σ ( x T θ ) ] x = y \cdot [1 - \sigma (x^T \theta)] x - [1 - y] \cdot [\sigma (x^T \theta)] x =y⋅[1−σ(xTθ)]x−[1−y]⋅[σ(xTθ)]x
= { y ⋅ [ 1 − σ ( x T θ ) ] − [ 1 − y ] ⋅ [ σ ( x T θ ) ] } x = \left \{ y \cdot [1 - \sigma (x^T \theta)] - [1 - y] \cdot [\sigma (x^T \theta)] \right \}x ={y⋅[1−σ(xTθ)]−[1−y]⋅[σ(xTθ)]}x
= [ y − σ ( x T θ ) ] x = [ y - \sigma (x^T \theta) ]x =[y−σ(xTθ)]x
按梯度上升法, θ \theta θ的更新可写为:
θ : = θ + η [ y − σ ( x T θ ) ] x \theta \ := \ \theta + \eta [y - \sigma (x^T \theta) ] x θ := θ+η[y−σ(xTθ)]x
在机器学习中 η \eta η为学习率。
在给定样本集 { X : Y } = { ( x 1 : y 1 ) , ( x 2 : y 2 ) , ⋯ , ( x n : y n ) } \left \{X:Y \right \} = \left \{ (x_1:y_1), \ (x_2:y_2), \cdots, (x_n:y_n) \right \} {X:Y}={(x1:y1), (x2:y2),⋯,(xn:yn)},训练伪代码如下:
F O R ( x : y ) = ( x 1 : y 1 ) : ( x n : y n ) D O FOR \quad (x:y) = (x_1:y_1):(x_n:y_n) \quad DO FOR(x:y)=(x1:y1):(xn:yn)DO
{
y ~ = σ ( x T θ ) \tilde{y} = \sigma(x^T\theta) y~=σ(xTθ)
e = η [ y − y ~ ] x e = \eta [y - \tilde{y}]x e=η[y−y~]x
θ : = θ + e \theta := \theta + e θ:=θ+e
}
即迭代训练样本集中的每一个样本,对其进行一次二分类,将分类的误差更新到 θ \theta θ上,当迭代完成时, θ \theta θ达到最优。
当得到参数 θ \theta θ后,便可以将其运用于分类了。