数据分析与挖掘练习2 --kaggle比赛 House Prices 预测
题目描述:
通过79个变量(几乎)描述爱荷华州埃姆斯(Ames)住宅的每一个特征,在这个竞赛里,需要你预测每个住宅的最终价格,并最终提交。http://ww2.amstat.org/publications/jse/v19n3/Decock/DataDocumentation.txt 上述官方给的一份说明里是对数据的描述,描述了79个属性变量的具体描述以及数据类型。
The data has 82 columns which include 23 nominal, 23 ordinal, 14 discrete, and 20 continuous variables (and 2 additional observation identifiers).、
目录:
1、数据集探索
2、数据处理
3、特征工程
4、模型选择
5、模型融合

一、数据集探索
我们有1460的训练数据和1459的测试数据,数据的特征列有79个,其中35个是数值类型的,44个类别类型。
1.1导入相应的库
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
%matplotlib inline
import matplotlib.pyplot as plt # Matlab-style plotting
import seaborn as sns
color = sns.color_palette()
sns.set_style('darkgrid')
import warnings
def ignore_warn(*args, **kwargs):
pass
warnings.warn = ignore_warn #ignore annoying warning (from sklearn and seaborn)
from scipy import stats
from scipy.stats import norm, skew #for some statistics
pd.set_option('display.float_format', lambda x: '{:.3f}'.format(x)) #Limiting floats output to 3 decimal points
1.2 导入训练、测试数据
train = pd.read_csv('../input/train.csv')
test = pd.read_csv('../input/test.csv')
train.head()
test.head()

train.info() #train数据集信息展示1460行81列,--object代表了字符串类型 int整型 float浮点数类型 datetime时间类型 bool布尔类型
#还可以看到各个属性的缺失情况ID特征对分类没有影响,但最后我们得到结果以后提交的时候需要,所以需要将ID单独提取出来:
二 数据处理
离群点处理
(在后面的模型融合方案中不去掉该异常值,成绩也并没有下降,这里有点疑问,估计该属性对结果的影响系数不是太大)
在数据中会有个别离群点,他们对分类结果噪音太大,我们选择将其删掉。但是如果不是太过分的离群点,就不能删掉,因为如果删掉所有噪声会影响模型的健壮性,对测试数据的泛化能力就会下降。由一开始的说明知道,只要的异常值在GrLivArea
fig, ax = plt.subplots()
ax.scatter(x = train['GrLivArea'], y = train['SalePrice'])
plt.ylabel('SalePrice', fontsize=13)
plt.xlabel('GrLivArea', fontsize=13)
plt.show()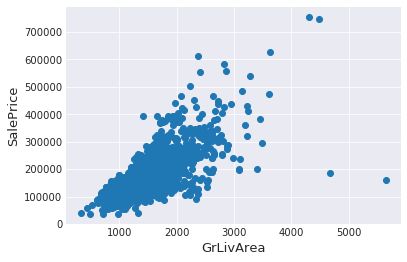
右下方的两个数据,living area特别大,但是价格又低的离谱,应该是远离市区的无人地带。对最后的分类结果没有影响的离群点(Oultliers),我们可以放心将其删除。
#Deleting outliers
train = train.drop(train[(train['GrLivArea']>4000) & (train['SalePrice']<300000)].index)
#Check the graphic again
fig, ax = plt.subplots()
ax.scatter(train['GrLivArea'], train['SalePrice'])
plt.ylabel('SalePrice', fontsize=13)
plt.xlabel('GrLivArea', fontsize=13)
plt.show()
目标值处理:
线性的模型需要正态分布的目标值才能发挥最大的作用。我们需要检测房价时候偏离正态分布。使用probplot函数,即正太概率图:
sns.distplot(train['SalePrice'] , fit=norm);
# Get the fitted parameters used by the function
(mu, sigma) = norm.fit(train['SalePrice'])
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
#Now plot the distribution
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],
loc='best')
plt.ylabel('Frequency')
plt.title('SalePrice distribution')
#Get also the QQ-plot
fig = plt.figure()
res = stats.probplot(train['SalePrice'], plot=plt)
plt.show()
按照参考文献的说法,此时正态分布明显属于右态分布,整体峰值向左偏离,并且skewness较大,需要对目标值做log转换,以恢复目标值的正态性。
注意:后面对属性都要进行偏态分析并对明显左偏或右偏的属性进行log修正。
#We use the numpy fuction log1p which applies log(1+x) to all elements of the column
train["SalePrice"] = np.log1p(train["SalePrice"])
#Check the new distribution
sns.distplot(train['SalePrice'] , fit=norm);
# Get the fitted parameters used by the function
(mu, sigma) = norm.fit(train['SalePrice'])
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
#Now plot the distribution
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],
loc='best')
plt.ylabel('Frequency')
plt.title('SalePrice distribution')
#Get also the QQ-plot
fig = plt.figure()
res = stats.probplot(train['SalePrice'], plot=plt)
plt.show()
三 特征工程
为了方便处理数据,我们将训练集和测试集先进行合并:
ntrain = train.shape[0]
ntest = test.shape[0]
y_train = train.SalePrice.values
all_data = pd.concat((train, test)).reset_index(drop=True)
# all_data =pd.concat([train['SalePrice'], train[var]], axis=1)
#all_data = train.append(test, ignore_index=True)
all_data.drop(['SalePrice'], axis=1, inplace=True)
print("all_data size is : {}".format(all_data.shape))
3.1 缺失值
all_data_na = (all_data.isnull().sum() / len(all_data)) * 100
all_data_na = all_data_na.drop(all_data_na[all_data_na == 0].index).sort_values(ascending=False)[:30]
missing_data = pd.DataFrame({'Missing Ratio' :all_data_na})
missing_data.head(20)
可视化展示全部数据属性的缺失情况
f, ax = plt.subplots(figsize=(15, 12))
plt.xticks(rotation='90')
sns.barplot(x=all_data_na.index, y=all_data_na)
plt.xlabel('Features', fontsize=15)
plt.ylabel('Percent of missing values', fontsize=15)
plt.title('Percent missing data by feature', fontsize=15)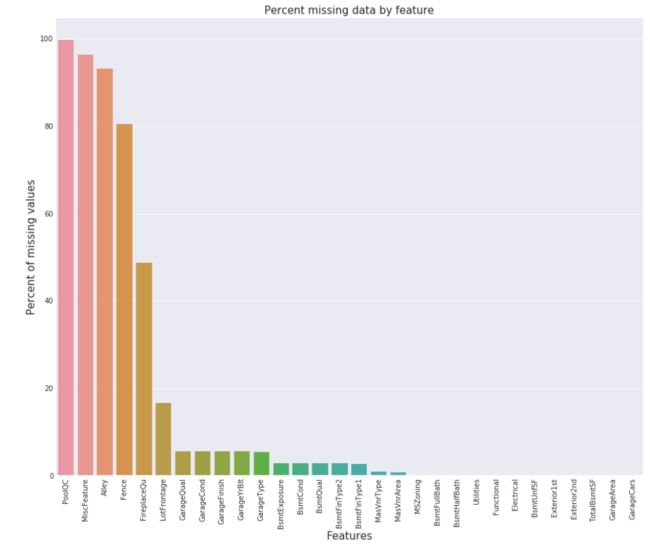
本次方案中我对缺失值的处理是 比较简单粗暴的删除做法--对缺失量多于总量1/3的属性直接剔除。。。
(后面方案也可以尝试进行填充,缺失量大的直接用‘None’--对分类型数据,‘0’--对数值型数据进行填充
缺失量少的可以考虑用平均值或众数来填充)
属性的缺失量分析,找出需要剔除的属性有:‘Alleyy’, ' FireplaceQu' , ' PoolQC' , ' Fence' ,'MiscFeature'
train = pd.read_csv("train.csv") # read train data
test = pd.read_csv("test.csv") # read test data
tables = [train,test]
print ("Delete features with high number of missing values...")
total_missing = train.isnull().sum()
to_delete = total_missing[total_missing>(train.shape[0]/3.)]
for table in tables:
table.drop(list(to_delete.index),axis=1,inplace=True)
numerical_features = test.select_dtypes(include=["float","int","bool"]).columns.values
categorical_features = train.select_dtypes(include=["object"]).columns.values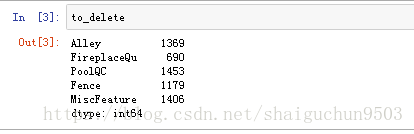
数据相关性分析
#Correlation map to see how features are correlated with SalePrice
corrmat = train.corr()
plt.subplots(figsize=(12,9))
sns.heatmap(corrmat, vmax=0.9, square=True)
查看上面属性值是数字的这些属性与‘SalePrice’的相关系数
corr_list = corr['SalePrice'].sort_values(axis=0,ascending=False).iloc[1:]
corr_list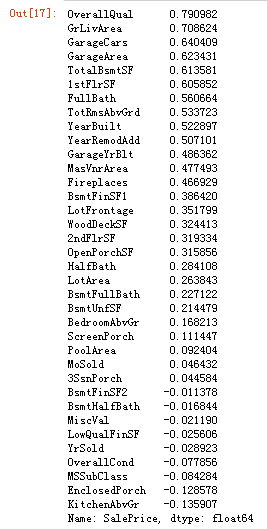
对前6个正相关性最强的属性可视化 画图验证
plt.figure(figsize=(18,8))
for i in range(6):
ii = '23'+str(i+1)
plt.subplot(ii)
feature = corr_list.index.values[i]
plt.scatter(df[feature], df['SalePrice'], facecolors='none',edgecolors='k',s = 75)
sns.regplot(x = feature, y = 'SalePrice', data = df,scatter=False, color = 'Blue')
ax=plt.gca()
ax.set_ylim([0,800000])
取一个分类型数据的属性可视化,查看其与结果的影响关系,这里取Neiborhood(住房周边情况)这一典型的认为重要因素
plt.figure(figsize = (12, 6))
sns.boxplot(x = 'Neighborhood', y = 'SalePrice', data = df)
xt = plt.xticks(rotation=45)
上面看出该属性的属性值众多,对价格的影响应该还挺大,后面需要对这种分类型数据进行哑编码处理
总结上面及下面的数据工程:
(1)异常值剔除,
(2)缺失值处理,这里我们是对缺失量大的属性进行删除,选择剩下的特征进行接下来的处理
(3)log转化偏态特征, 对所有的偏态大于0.75的进行log转换
(4)分裂特征(属性值是字符等)的处理, 使用get_dummies方法进行哑编码
四 、模型选择
五、模型融合
这里我训练得到四个基本模型,后期也需要使用集成方法(Ensemble methods)对这几个模型进行融合。四个模型分别是:Random Forest regressor, Extra Trees regressor, Gradient Boosting regressor, Extreme Gradient
Boosting regressor
最后代码如下
import numpy as np
import pandas as pd
import datetime
from sklearn.cross_validation import KFold
from sklearn.cross_validation import train_test_split
import time
from sklearn import preprocessing
from xgboost import XGBRegressor
from sklearn.ensemble import RandomForestRegressor, ExtraTreesRegressor, GradientBoostingRegressor
from sklearn.grid_search import GridSearchCV
from sklearn.cross_validation import ShuffleSplit
from sklearn.metrics import make_scorer, mean_squared_error
from sklearn.linear_model import Ridge, LassoCV,LassoLarsCV, ElasticNet
from sklearn.kernel_ridge import KernelRidge
from sklearn.neighbors import KNeighborsRegressor
from sklearn.svm import SVR
from scipy.stats import skew
def create_submission(prediction,score):
now = datetime.datetime.now()
sub_file = 'submission_'+str(score)+'_'+str(now.strftime("%Y-%m-%d-%H-%M"))+'.csv'
#sub_file = 'prediction_training.csv'
print ('Creating submission: ', sub_file)
pd.DataFrame({'Id': test['Id'].values, 'SalePrice': prediction}).to_csv(sub_file, index=False)
# train need to be test when do test prediction
def data_preprocess(train,test):
#删除之前分析的异常数据样本
# # outlier_idx = [4,11,13,20,46,66,70,167,178,185,199,
# 224,261, 309,313,318, 349,412,423,440,454,477,478, 523,540,
# 581,588,595,654,688, 691, 774, 798, 875, 898,926,970,987,1027,1109,
# 1169,1182,1239, 1256,1298,1324,1353,1359,1405,1442,1447]
# # train.drop(train.index[outlier_idx],inplace=True)
train = train.drop(train[(train['GrLivArea'] > 4000)].index) #根据参考文献说的该属性有明显的异常值
all_data = pd.concat((train.loc[:,'MSSubClass':'SaleCondition'],test.loc[:,'MSSubClass':'SaleCondition']))
#删除之前分析的缺失值超过三分之1 的属性
to_delete = ['Alley','FireplaceQu','PoolQC','Fence','MiscFeature']
all_data = all_data.drop(to_delete,axis=1)
#属性特征的偏态大于0.75的进行log化处理
train["SalePrice"] = np.log1p(train["SalePrice"])
#log transform skewed numeric features
numeric_feats = all_data.dtypes[all_data.dtypes != "object"].index
skewed_feats = train[numeric_feats].apply(lambda x: skew(x.dropna())) #compute skewness
skewed_feats = skewed_feats[skewed_feats > 0.75]
skewed_feats = skewed_feats.index
all_data[skewed_feats] = np.log1p(all_data[skewed_feats])
#对分类特征进行one-hot哑编码 转化成数值型数据
all_data = pd.get_dummies(all_data)
#剩下的缺失数据用平均值来代替
all_data = all_data.fillna(all_data.mean())
X_train = all_data[:train.shape[0]]
X_test = all_data[train.shape[0]:]
y = train.SalePrice
return X_train,X_test,y
def mean_squared_error_(ground_truth, predictions):
return mean_squared_error(ground_truth, predictions) ** 0.5
RMSE = make_scorer(mean_squared_error_, greater_is_better=False)
class ensemble(object):
def __init__(self, n_folds, stacker, base_models):
self.n_folds = n_folds
self.stacker = stacker
self.base_models = base_models
def fit_predict(self,train,test,ytr):
X = train.values
y = ytr.values
T = test.values
folds = list(KFold(len(y), n_folds = self.n_folds, shuffle = True, random_state = 0))
S_train = np.zeros((X.shape[0],len(self.base_models)))
S_test = np.zeros((T.shape[0],len(self.base_models))) # X need to be T when do test prediction
for i,reg in enumerate(base_models):
print ("Fitting the base model...")
S_test_i = np.zeros((T.shape[0],len(folds))) # X need to be T when do test prediction
for j, (train_idx,test_idx) in enumerate(folds):
X_train = X[train_idx]
y_train = y[train_idx]
X_holdout = X[test_idx]
reg.fit(X_train,y_train)
y_pred = reg.predict(X_holdout)[:]
S_train[test_idx,i] = y_pred
S_test_i[:,j] = reg.predict(T)[:]
# S_test_i[:,j] = reg.predict(X)[:]
S_test[:,i] = S_test_i.mean(1)
print ("Stacking base models...")
param_grid = {'alpha': [1e-3,5e-3,1e-2,5e-2,1e-1,0.2,0.3,0.4,0.5,0.8,1e0,3,5,7,1e1,2e1,5e1]}
grid = GridSearchCV(estimator=self.stacker, param_grid=param_grid, n_jobs=1, cv=5, scoring=RMSE)
grid.fit(S_train, y)
try:
print('Param grid:')
print(param_grid)
print('Best Params:')
print(grid.best_params_)
print('Best CV Score:')
print(-grid.best_score_)
print('Best estimator:')
print(grid.best_estimator_)
print(message)
except:
pass
y_pred = grid.predict(S_test)[:]
return y_pred, -grid.best_score_
if __name__ == '__main__':
train = pd.read_csv("../../input/train.csv") # read train data
test = pd.read_csv("../../input/test.csv") # read test data
base_models = [
RandomForestRegressor(
n_jobs=1, random_state=0,
n_estimators=500, max_features=18, max_depth=11
),
ExtraTreesRegressor(
n_jobs=1, random_state=0,
n_estimators=500, max_features=20
),
GradientBoostingRegressor(
random_state=0,
n_estimators=500, max_features=10, max_depth=6,
learning_rate=0.05, subsample=0.8
),
XGBRegressor(
seed=0,
n_estimators=500, max_depth=7,
learning_rate=0.05, subsample=0.8, colsample_bytree=0.75
),
]
ensem = ensemble(
n_folds=5,
stacker=Ridge(),
base_models=base_models
)
X_train,X_test,y_train = data_preprocess(train,test)
y_pred, score = ensem.fit_predict(X_train,X_test,y_train)
create_submission(np.expm1(y_pred),score)
