2001-使用Hive+MR统计分析网站指标
1. 网站用户行为分析背景
数据源来自网站渠道用户行为日志,每天产生10G用户日志。产生的日志的特点:
(1)每小时生成一个文件,每个文件约50M,每天每台日志采集服务器产生24个文件
(2)生产环境共有8台日志采集服务器,故每天产生日志:8 * (50*24) 约为10G
(3)通过shell脚本,对每天采集服务器上的日志文件进行合并形成一个大约1G的文件,命名格式:日期.log。例如: 2015-07-05.log
1.1 数据收集
在”统计电商网站的PV“案例中,我们收集的原始日志文件部分内容如图所示。
日志文件中列与列之间用空格进行分割,每个列用双引号,每列字段具体含义如表所示。
创建日志原始Hive表data_collect代码如下:
加载数据
验证Hive表
备注:其中access_day一列是分区信息,表示当前日期。
2. 网站总体概况
2.1 PV统计(页面访问量)
(1) 基本概念
通常是衡量一个网络新闻频道或网站甚至一条网络新闻的主要指标。网页浏览数是评价网站流量最常用的指标之一,简称为PV。监测网站PV的变化趋势和分析其变化原因是很多站长定期要做的工作。 Page Views中的Page一般是指普通的html网页,也包含php、jsp等动态产生的html内容。来自浏览器的一次html内容请求会被看作一个PV,逐渐累计成为PV总数。
(2) 计算方法
用户每1次对网站中的每个网页访问均被记录1次。用户对同一页面的多次访问,访问量累计。
2.2 UV统计(网站独立访客)
(1) 基本概念
独立IP:是指独立用户/独立访客。指访问某个站点或点击某条新闻的不同IP地址的人数
(2) 计算方法
在同一天的00:00-24:00内,独立IP只记录第一次进入网站的具有独立IP的访问者,可以通过设置cookie,记录第一次访问设置新用户,后续为老用户
2.3 每天的PV|UV|人均访问页面数(PV/UV)
统计PV|UV|人均访问页面数(PV/UV)的HQL
select access_day,count(1) pv,count(distinct uid) uv,count(1)/count(distinct uid) avg_visit_page from data_collect group by access_day;
统计2015-07-05 两台日期采集服务器的PV|UV|人均访问页面数(PV/UV)
access_day pv uv avg_visit_page
20150705 4253807 428268 9.93
Time taken: 321.797 seconds, Fetched: 1 row(s)
通过1台4G内存/2CPU 虚拟机上测试2G日志数据花费5分钟, 整个过程使用Map: 8 Reduce: 3 。
2.4 平均网站停留时间
停留时间是指用户访问网站的时间长短,即用户打开商城的最后一个页面的时间点减去打开商城第一个页面的时间点.计算公式: 每个访客每天的网站停留时间=最后一次时间-首次访问时间。
统计每个用户停留时间
create table avg_stay_time_tmp
as
select access_day,uid ,max(unix_timestamp(time_local,'dd/MMM/yyyy:HH:mm:ss'))-min(unix_timestamp(time_local,'dd/MMM/yyyy:HH:mm:ss')) stay_time from data_collect group by access_day ,uid;
统计网站平均停留时间
select access_day ,ceil(sum(stay_time)/count(1)) avg_stay_time from avg_stay_time_tmp group by access_day;
统计结果为
access_day avg_stay_time
20150705 315
2.5 统计每个IP的访问量
可以分析那个IP对网站的访问最高,采用Hive平台的HQL进行统计。
select http_x_forwarded_for,count(sid) count
from data_collect
group by http_x_forwarded_for
order by count desc
limit 10;
2.5 统计每个省份页面访问量
采用Hive平台的HQL进行统计,由于用户访问日志仅有对应的IP地址,没有对应的IP,那么需要通过IP获取对应的省份,然后进行分类统计。
自定义UDF函数,将IP专为省份
自定义的验证
编写HQL语句,直接统计每个省份页面访问量
3.统计访问的top20
3.1 Hive统计网站中url访问top20
统计结果

3.2 MR统计网站中url访问top20
因为统计top20的url,原始日志表中存在大量的冗余字段,通过Hive平台进行过滤。把有效的信息放入到一张基础表。
执行MR程序
hadoop jar urlTopN.jar hdfs://mycluster:9000/user/hive/warehouse/jfyun.db/top_n hdfs://mycluster:9000/topN

4.用户环境
用户环境是对访问用户的操作系统及浏览器等信息进行统计展示。
具体用户环境统计信息包括:“浏览器比例分析”、“操作系统比例分析”、“屏幕颜色”、“屏幕尺寸”及“网络属性”。
4.1 屏幕颜色访问量
通过屏幕分辨率的访问情况,采用Hive平台表进行统计,统计Top3的数据
4.2 屏幕大小使用情况
通过屏幕大小的访问情况,采用Hive平台表进行统计,统计Top10的数据。
数据源来自网站渠道用户行为日志,每天产生10G用户日志。产生的日志的特点:
(1)每小时生成一个文件,每个文件约50M,每天每台日志采集服务器产生24个文件
(2)生产环境共有8台日志采集服务器,故每天产生日志:8 * (50*24) 约为10G
(3)通过shell脚本,对每天采集服务器上的日志文件进行合并形成一个大约1G的文件,命名格式:日期.log。例如: 2015-07-05.log
1.1 数据收集
在”统计电商网站的PV“案例中,我们收集的原始日志文件部分内容如图所示。
| "05/Jul/2015:00:01:04 +0800" "GET" "http%3A//jf.10086.cn/m/" "HTTP/1.1" "200" "http://jf.10086.cn/m/subject/100000000000009_0.html" "Mozilla/5.0 (Linux; U; Android 4.4.2; zh-cn; Lenovo A3800-d Build/LenovoA3800-d) AppleWebKit/533.1 (KHTML, like Gecko)Version/4.0 MQQBrowser/5.4 TBS/025438 Mobile Safari/533.1 MicroMessenger/6.2.0.70_r1180778.561 NetType/cmnet Language/zh_CN" "10.139.198.176" "480x854" "24" "%u5927%u7C7B%u5217%u8868%u9875_%u4E2D%u56FD%u79FB%u52A8%u79EF%u5206%u5546%u57CE" "0" "3037487029517069460000" "3037487029517069460000" "1" "75"
"05/Jul/2015:00:01:04 +0800"
"GET" "http%3A//jf.10086.cn/portal/ware/web/SearchWareAction%3Faction%3DsearchWareInfo%26pager.offset%3D144" "HTTP/1.1" "200" "http://jf.10086.cn/portal/ware/web/SearchWareAction?action=searchWareInfo&pager.offset=156" "Mozilla/5.0 (Linux; U; Android 4.4.2; zh-CN; HUAWEI MT2-L01 Build/HuaweiMT2-L01) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 UCBrowser/10.5.2.598 U3/0.8.0 Mobile Safari/534.30" "223.73.104.224" "720x1208" "32" "%u641C%u7D22_%u4E2D%u56FD%u79FB%u52A8%u79EF%u5206%u5546%u57CE" "0" "3046252153674140570000" "3046252153674140570000" "1" "2699"
"05/Jul/2015:00:01:04 +0800"
"GET" "" "HTTP/1.1" "200" "http://jf.10086.cn/" "Mozilla/5.0 (Linux; Android 4.4.4; vivo Y13L Build/KTU84P) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/33.0.0.0 Mobile Safari/537.36 baiduboxapp/5.1 (Baidu; P1 4.4.4)" "10.154.210.240" "480x855" "32" "%u9996%u9875_%u4E2D%u56FD%u79FB%u52A8%u79EF%u5206%u5546%u57CE" "0" "3098781670304015290000" "3098781670304015290000" "0" "831"
|
日志文件中列与列之间用空格进行分割,每个列用双引号,每列字段具体含义如表所示。
|
序号
|
字段名称
|
字段类型
|
列含义
|
举例
|
|
0
|
time_local
|
string
|
访问日期
|
05/Jul/2015:05:01:05 +0800
|
|
1
|
request_method
|
string
|
请求方法
|
GET
|
|
2
|
arg_referrerPage
|
string
|
当前页面前一个页面
|
http%3A//wap.jf.10086.cn/
|
|
3
|
server_protocol
|
string
|
协议
|
HTTP/1.1
|
|
4
|
status
|
string
|
响应状态
|
200
|
|
5
|
http_referer
|
string
|
请求页面
|
http://jf.10086.cn/
|
|
6
|
http_user_agent
|
string
|
请求代理
|
Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) AppleWebKit/537.51.2 (KHTML, like Gecko) Mobile/11D257
|
|
7
|
http_x_forwarded_for
|
string
|
用户IP地址
|
117.95.112.54
|
|
8
|
screenSize
|
string
|
屏幕分辨率
|
320x568
|
|
9
|
screenColor
|
string
|
颜色
|
32
|
|
10
|
pageTitle
|
string
|
页面标题
|
%u9996%u9875_%u4E2D%u56FD%u79FB%u52A8%u79EF%u5206%u5546%u57CE
|
|
11
|
siteType
|
string
|
渠道 (0-网站端,1-移动端) |
0
|
|
12
|
uid
|
string
|
用户访问唯一标示(uid)
|
3011949129193080000000
|
|
13
|
sid
|
string
|
用户会话标示(sid)
|
3011949129193080000000
|
|
14
|
sflag
|
string
|
会话 (1-新增,0-更新) |
1
|
|
15
|
onloadTotalTime
|
string
|
页面访问时长
|
452
|
|
16
|
access_day
|
string
|
分区表
|
|
创建日志原始Hive表data_collect代码如下:
| create external table data_collect(
time_local string,
request_method string ,
referrerPage string,
server_protocol string,
status string ,
http_referer string,
http_user_agent string,
http_x_forwarded_for string,
screenSize string,
screenColor string,
pageTitle string ,
siteType string,
uid string,
sid string ,
sflag string ,
onloadTotalTime string
)partitioned by(access_day string)
row format SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'input.regex'='"(.*?)[\\s][+0-9]*"[\\s]*"(.*?)"[\\s]*"(.*?)"[\\s]*"(.*?)"[\\s]*"(.*?)"[\\s]*"(.*?)"[\\s]*"(.*?)"[\\s]*"(.*?)"[\\s]*"(.*?)"[\\s]*"(.*?)"[\\s]*"(.*?)"[\\s]*"(.*?)"[\\s]*"(.*?)"[\\s]*"(.*?)"[\\s]*"(.*?)"[\\s]*"(.*?)"[\\s]*',
'output.format.string' = '%1$s %2$s %3$s %4$s %5$s %6$s %7$s %8$s %9$s %10$s %11$s %12$s %13$s %14$s %15$s %16$s')
STORED AS TEXTFILE;
|
加载数据
|
load data local inpath '/home/hadoop/20150705' overwrite into table data_collect partition(access_day=20150705)
|
| hive (jfyun)> add jar /home/hadoop/app/hive/lib/hive-contrib-0.13.0.jar;
hive (jfyun)> select time_local ,request_method,onloadTotalTime ,access_day from data_collect;
time_local request_method onloadtotaltime access_day 06/Jul/2015:00:01:04 +0800 GET 75 20150706 06/Jul/2015:01:01:04 +0800 GET 2699 20150706 06/Jul/2015:02:01:04 +0800 GET 831 20150706 06/Jul/2015:03:01:07 +0800 GET 135 20150706 |
备注:其中access_day一列是分区信息,表示当前日期。
2. 网站总体概况
2.1 PV统计(页面访问量)
(1) 基本概念
通常是衡量一个网络新闻频道或网站甚至一条网络新闻的主要指标。网页浏览数是评价网站流量最常用的指标之一,简称为PV。监测网站PV的变化趋势和分析其变化原因是很多站长定期要做的工作。 Page Views中的Page一般是指普通的html网页,也包含php、jsp等动态产生的html内容。来自浏览器的一次html内容请求会被看作一个PV,逐渐累计成为PV总数。
(2) 计算方法
用户每1次对网站中的每个网页访问均被记录1次。用户对同一页面的多次访问,访问量累计。
2.2 UV统计(网站独立访客)
(1) 基本概念
独立IP:是指独立用户/独立访客。指访问某个站点或点击某条新闻的不同IP地址的人数
(2) 计算方法
在同一天的00:00-24:00内,独立IP只记录第一次进入网站的具有独立IP的访问者,可以通过设置cookie,记录第一次访问设置新用户,后续为老用户
2.3 每天的PV|UV|人均访问页面数(PV/UV)
统计PV|UV|人均访问页面数(PV/UV)的HQL
select access_day,count(1) pv,count(distinct uid) uv,count(1)/count(distinct uid) avg_visit_page from data_collect group by access_day;
统计2015-07-05 两台日期采集服务器的PV|UV|人均访问页面数(PV/UV)
access_day pv uv avg_visit_page
20150705 4253807 428268 9.93
Time taken: 321.797 seconds, Fetched: 1 row(s)
通过1台4G内存/2CPU 虚拟机上测试2G日志数据花费5分钟, 整个过程使用Map: 8 Reduce: 3 。
2.4 平均网站停留时间
停留时间是指用户访问网站的时间长短,即用户打开商城的最后一个页面的时间点减去打开商城第一个页面的时间点.计算公式: 每个访客每天的网站停留时间=最后一次时间-首次访问时间。
统计每个用户停留时间
create table avg_stay_time_tmp
as
select access_day,uid ,max(unix_timestamp(time_local,'dd/MMM/yyyy:HH:mm:ss'))-min(unix_timestamp(time_local,'dd/MMM/yyyy:HH:mm:ss')) stay_time from data_collect group by access_day ,uid;
统计网站平均停留时间
select access_day ,ceil(sum(stay_time)/count(1)) avg_stay_time from avg_stay_time_tmp group by access_day;
统计结果为
access_day avg_stay_time
20150705 315
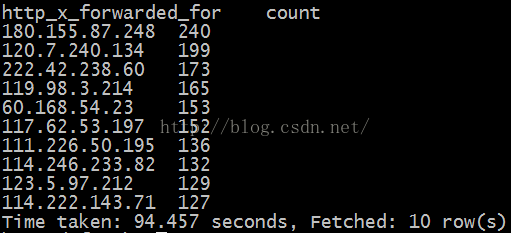
2.5 统计每个IP的访问量
可以分析那个IP对网站的访问最高,采用Hive平台的HQL进行统计。
select http_x_forwarded_for,count(sid) count
from data_collect
group by http_x_forwarded_for
order by count desc
limit 10;
2.5 统计每个省份页面访问量
采用Hive平台的HQL进行统计,由于用户访问日志仅有对应的IP地址,没有对应的IP,那么需要通过IP获取对应的省份,然后进行分类统计。
自定义UDF函数,将IP专为省份
public class IpToProv extends UDF {
public static Map map = new HashMap();
static {
map.put("100", "北京");
map.put("200", "广东");
map.put("210", "上海");
map.put("220", "天津");
map.put("230", "重庆");
map.put("240", "辽宁");
map.put("250", "江苏");
map.put("270", "湖北");
map.put("280", "四川");
map.put("290", "陕西");
map.put("311", "河北");
map.put("351", "山西");
map.put("371", "河南");
map.put("431", "吉林");
map.put("451", "黑龙江");
map.put("471", "内蒙古");
map.put("531", "山东");
map.put("551", "安徽");
map.put("571", "浙江");
map.put("591", "福建");
map.put("731", "湖南");
map.put("771", "广西");
map.put("791", "江西");
map.put("851", "贵州");
map.put("871", "云南");
map.put("891", "西藏");
map.put("898", "海南");
map.put("931", "甘肃");
map.put("951", "宁夏");
map.put("971", "青海");
map.put("991", "新疆");
}
/**
* IP转为省份
*
* @param ip
* @return
*/
public String evaluate(String ip) {
IPSeeker ipSeeker = new IPSeeker();
String lookup = ipSeeker.lookup(ip, "999");
return map.get(lookup) == null ? "北京" : map.get(lookup);
}
public static void main(String[] args) {
IpToProv area = new IpToProv();
String evaluate = area.evaluate("180.155.87.248");
System.out.println(evaluate);
}
} 自定义的验证
add jar /home/hadoop/IpToProv.jar
create temporary function ipToProv as 'cn.hive.IpToProv';
select ipToProv(http_x_forwarded_for) from data_collect limit 1 ;编写HQL语句,直接统计每个省份页面访问量
select ipToProv(http_x_forwarded_for) province_name ,count(sid) count
from data_collect
group by ipToProv(http_x_forwarded_for)
order by count desc;
limit 10;|
序号
|
编码
|
名称
|
|
1
|
100
|
北京
|
|
2
|
200
|
广东
|
|
3
|
210
|
上海
|
|
4
|
220
|
天津
|
|
5
|
230
|
重庆
|
|
6
|
240
|
辽宁
|
|
7
|
250
|
江苏
|
|
8
|
270
|
湖北
|
|
9
|
280
|
四川
|
|
10
|
290
|
陕西
|
|
11
|
311
|
河北
|
|
12
|
351
|
山西
|
|
13
|
371
|
河南
|
|
14
|
431
|
吉林
|
|
15
|
451
|
黑龙江
|
|
16
|
471
|
内蒙古
|
|
17
|
531
|
山东
|
|
18
|
551
|
安徽
|
|
19
|
571
|
浙江
|
|
20
|
591
|
福建
|
|
21
|
731
|
湖南
|
|
22
|
771
|
广西
|
|
23
|
791
|
江西
|
|
24
|
851
|
贵州
|
|
25
|
871
|
云南
|
|
26
|
891
|
西藏
|
|
27
|
898
|
海南
|
|
28
|
931
|
甘肃
|
|
29
|
951
|
宁夏
|
|
30
|
971
|
青海
|
|
31
|
991
|
新疆
|
3.统计访问的top20
3.1 Hive统计网站中url访问top20
select t.access_day,t.http_referer,t.count
from
(select access_day,http_referer,count(1) count from data_collect where access_day='20150705' group by access_day, http_referer) t
order by t.count desc
limit 20;统计结果
3.2 MR统计网站中url访问top20
因为统计top20的url,原始日志表中存在大量的冗余字段,通过Hive平台进行过滤。把有效的信息放入到一张基础表。
create external table top_n(
access_day string,
time_local string,
http_referer string,
uid string,
sid string,
loadtotaltime int
)
row format delimited
fields terminated by '\t';
insert overwrite table top_n
select access_day ,time_local,http_referer,uid,sid,onloadtotaltime from data_collect where access_day='20150705';/**
* 统计每天每隔URL的TOPN
*
* 集群运行命令: hadoop jar urlTopN.jar hdfs://mycluster:9000/user/hive/warehouse/jfyun.db/top_n hdfs://mycluster:9000/topN
* @author shenfl
*
*/
public class URLTopN extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapreduce.output.basename", "topN");// 修改Reduce生产文件的名称
conf.set("mapreduce.output.textoutputformat.separator", "$$");// reduce输出结果分隔符修改
conf.set("N", "20");// 设置topN
Job job = Job.getInstance(conf, URLTopN.class.getSimpleName());
job.setJarByClass(URLTopN.class);
FileInputFormat.setInputDirRecursive(job, true);
FileInputFormat.setInputPaths(job, new Path(args[0]));
job.setMapperClass(URLTopNMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setReducerClass(URLTopNReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
Path outputDir = new Path(args[1]);
deleteOutDir(conf, outputDir);
FileOutputFormat.setOutputPath(job, outputDir);
boolean waitForCompletion = job.waitForCompletion(true);
return waitForCompletion ? 0 : 1;
}
/**
* @param conf
* @param outputDir
* @throws IOException
*/
public void deleteOutDir(Configuration conf, Path outputDir) throws IOException {
FileSystem fs = FileSystem.get(conf);
if (fs.exists(outputDir)) {
fs.delete(outputDir, true);
}
}
public static void main(String[] args) {
try {
int run = ToolRunner.run(new Configuration(), new URLTopN(), args);
System.exit(run);
} catch (Exception e) {
e.printStackTrace();
}
}
public static class URLTopNMapper extends Mapper {
Text k2 = new Text();
LongWritable v2 = new LongWritable();
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
String line = v1.toString();
String[] splited = line.split("\t");
k2.set(splited[2]);
v2.set(1);
context.write(k2, v2);
}
}
public static class URLTopNReducer extends Reducer {
LongWritable v3 = new LongWritable();
LogInfoWritable logInfo;
public static Integer topN = Integer.MIN_VALUE;
/**
* 存储每个 url访问的次数,并且必须使用TreeMap,默认k升序,可以自己订单k的对象,使用降序排序
*/
TreeMap logMap = new TreeMap();
/**
* ReduceTask任务启动时候调用一次
*/
@Override
protected void setup(Reducer.Context context) throws IOException,
InterruptedException {
Configuration conf = context.getConfiguration();
topN = Integer.parseInt(conf.get("N"));
}
@Override
protected void reduce(Text k2, Iterable v2s, Context context) throws IOException,
InterruptedException {
long sum = 0;
for (LongWritable v : v2s) {
sum += v.get();
}
logInfo = new LogInfoWritable();
logInfo.set(k2.toString(), sum);
logMap.put(logInfo, NullWritable.get());
}
/**
* 执行完所有的reduce后,调用cleanup方法.输出前访问量top10的 url 要求:
* logMap中的value按照从从到到小输出,这样才能获取访问量top10url
*/
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
int count = 0;
for (Map.Entry entry : logMap.entrySet()) {
if (++count <= topN) {
context.write(new Text(entry.getKey().getUrl()), new LongWritable(entry.getKey().getSum()));
}
}
}
}
public static class LogInfoWritable implements WritableComparable {
private String url;
private long sum;
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public long getSum() {
return sum;
}
public void setSum(long sum) {
this.sum = sum;
}
public void set(String url, long sum) {
this.url = url;
this.sum = sum;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(url);
out.writeLong(sum);
}
@Override
public void readFields(DataInput in) throws IOException {
this.url = in.readUTF();
this.sum = in.readLong();
}
//从大到小排序
@Override
public int compareTo(LogInfoWritable o) {
return this.sum-o.sum>0?-1:1;
}
@Override
public String toString() {
return this.url + "\t" + this.sum;
}
}
} 执行MR程序
hadoop jar urlTopN.jar hdfs://mycluster:9000/user/hive/warehouse/jfyun.db/top_n hdfs://mycluster:9000/topN
4.用户环境
用户环境是对访问用户的操作系统及浏览器等信息进行统计展示。
具体用户环境统计信息包括:“浏览器比例分析”、“操作系统比例分析”、“屏幕颜色”、“屏幕尺寸”及“网络属性”。
4.1 屏幕颜色访问量
通过屏幕分辨率的访问情况,采用Hive平台表进行统计,统计Top3的数据
select screencolor,count(distinct uid) count
from data_collect
where access_day='20150705'
group by screencolor
order by count desc
limit 3;
4.2 屏幕大小使用情况
通过屏幕大小的访问情况,采用Hive平台表进行统计,统计Top10的数据。
select screensize,count(distinct uid) count
from data_collect
where access_day='20150705'
group by screensize
order by count desc;