Hadoop完全分布式集群搭建(2.9.0)
1. 集群搭建形式
Hadoop环境搭建分为三种形式:单机模式、伪分布式模式、完全分布模式
单机模式—— 在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统。
伪分布式—— 也是在一台单机上运行,但不同的是Java进程模仿分布式运行中的各类节点。即一台机器上,既当NameNode,又当DataNode,或者说既是JobTracker又是TaskTracker。没有所谓的在多台机器上进行真正的分布式计算,故称为“伪分布式”。
完全分布式—— 真正的分布式,由3个及以上的实体机或者虚拟机组成的机群。一个Hadoop集群环境中,NameNode,SecondaryName和DataNode是需要分配在不同的节点上,也就需要三台服务器。
前两种模式一般用在开发或测试环境下,生产环境下都是搭建完全分布式模式。
从分布式存储的角度来说,集群中的节点由一个NameNode和若干个DataNode组成,另有一个SecondaryNameNode作为NameNode的备份。
从分布式应用的角度来说,集群中的节点由一个JobTracker和若干个TaskTracker组成。JobTracker负责任务的调度,TaskTracker负责并行执行任务。TaskTracker必须运行在DataNode上,这样便于数据的本地计算。JobTracker和NameNode则无须在同一台机器上。
2. 环境
操作系统:CentOS7(红帽开源版)
机器:虚拟机3台,(master 192.168.0.104, slave1 192.168.0.102, slave2 192.168.0.101)
JDK:1.8(jdk-8u162-linux-x64.tar)
Hadoop:2.9.0(http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.9.0/hadoop-2.9.0.tar.gz)
3. 搭建步骤
3.1 每台机器安装&配置JDK(1台做好后,克隆出其它机器)
1) 创建目录 mkdir /usr/java
2) 上传jdk安装包到 /usr/java/
3) 解压 tar -xvf jdk-8u162-linux-x64.tar
4) 追加环境变量 vi /etc/profile
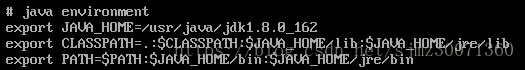
5) 使环境变量生效 source /etc/profile
6) 检测jdk正确安装 java -version

3.2 修改每台机器主机名(hostname)
hostnamectl set-hostname master (立即生效)
hostnamectl set-hostname slave1 (立即生效)
hostnamectl set-hostname slave2 (立即生效)
确认修改
![]()
3.3 修改每台机器/etc/hosts文件
vi /etc/hosts

修改其中1台,然后scp到其它机器
scp 文件名 远程主机用户名@远程主机名或ip:存放路径
scp hosts [email protected]:/etc/
scp hosts [email protected]:/etc/
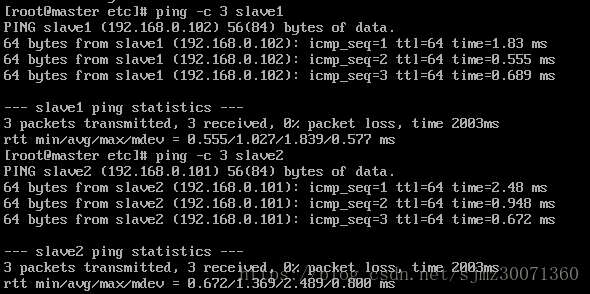
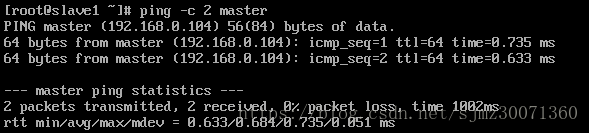
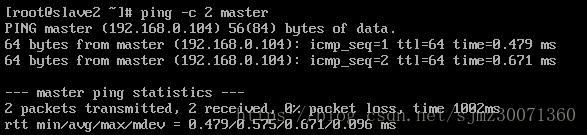
修改完之后,互ping其它机器,能互ping则说明修改OK
ping -c 3 slave1 (※ 3表示发送 3 个数据包)
3.4 配置ssh,实现无密码登录
无密码登录,效果也就是在master上,通过ssh slave1或者ssh slave2就可以登录对方机器,而不用输入密码。
1) 每台机器执行ssh-keygen -t rsa,接下来一路回车即可
执行ssh-keygen -t rsa主要是生成 密钥 和 密钥的存放路径
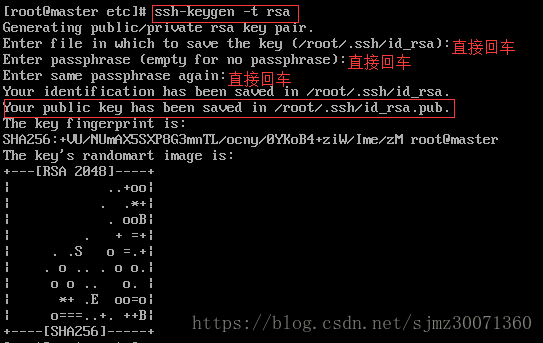
我们用的root用户,公钥私钥都会保存在~/.ssh下

2) 在master上将公钥放到authorized_keys里,命令:cat id_rsa.pub > authorized_keys
3) 将master上的authorized_keys放到其它机器上
scp authorized_keys root@slave1:~/.ssh/
scp authorized_keys root@slave2:~/.ssh/
4) 测试是否成功
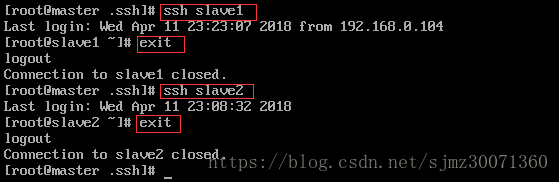
3.5 上传&配置hadoop(配置完master后,将/usr/hadoop/整个目录内容copy到其它机器)
1) 创建目录 mkdir /usr/hadoop
2) 上传hadoop安装包hadoop-2.9.0.tar.gz到 /usr/hadoop/
3) 解压 tar -xvf hadoop-2.9.0.tar.gz
4) 追加环境变量 vi /etc/profile(其它机器也要相应配置一次hadoop环境变量)

5) 使环境变量生效 source /etc/profile
6) 确认环境变量配置OK

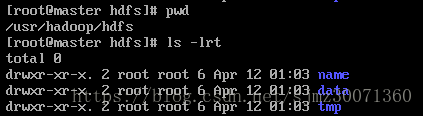
7) 创建HDFS存储目录
cd /usr/hadoop
mkdir hdfs
cd hdfs
mkdir name data tmp
/usr/hadoop/hdfs/name --存储namenode文件
/usr/hadoop/hdfs/data --存储数据
/usr/hadoop/hdfs/tmp --存储临时文件
8) 修改/usr/hadoop/hadoop-2.9.0/etc/hadoop/hadoop-env.sh文件,设置JAVA_HOME为实际路径
否则启动集群时,会提示路径找不到

9) 修改/usr/hadoop/hadoop-2.9.0/etc/hadoop/yarn-env.sh文件,设置JAVA_HOME为实际路径

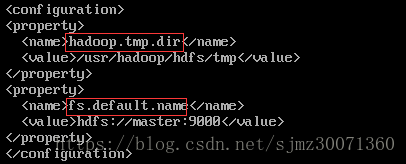
10) 配置/usr/hadoop/hadoop-2.9.0/etc/hadoop/core-site.xml
增加hadoop.tmp.dir 和 fs.default.name
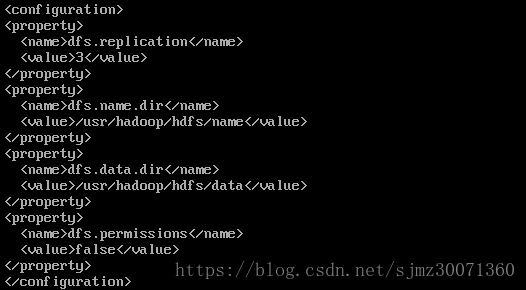
11) 配置/usr/hadoop/hadoop-2.9.0/etc/hadoop/hdfs-site.xml
dfs.replication:默认值3
dfs.permissions:默认值为true,设置为true有时候会遇到数据因为权限访问不了;设置为false可以不要检查权限就生成dfs上的文件
12) 配置/usr/hadoop/hadoop-2.9.0/etc/hadoop/mapred-site.xml
cd /usr/hadoop/hadoop-2.9.0/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
mapreduce.framework.name:指定mapreduce运行在yarn平台,默认为local

13) 配置/usr/hadoop/hadoop-2.9.0/etc/hadoop/yarn-site.xml
yarn.resourcemanager.hostname:指定yarn的resourcemanager的地址
yarn.nodemanager.aux-services:reducer获取数据的方式
yarn.nodemanager.vmem-check-enabled:意思是忽略虚拟内存的检查,如果安装在虚拟机上,这个配置很有用,配上去之后后续操作不容易出问题。如果是在实体机上,并且内存够多,可以将这个配置去掉
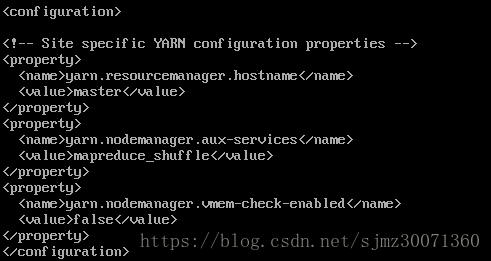
14) 配置/usr/hadoop/hadoop-2.9.0/etc/hadoop/slaves文件,将里面的localhost删除,配置后内容如下:

15) copy整个/usr/hadoop/目录到其它机器
scp -r hadoop root@slave1:/usr/
scp -r hadoop root@slave2:/usr/
3.6 启动Hadoop
1) 启动之前需要格式化一下。因为master是namenode,slave1和slave2都是datanode,所以在master上运行
hadoop namenode -format
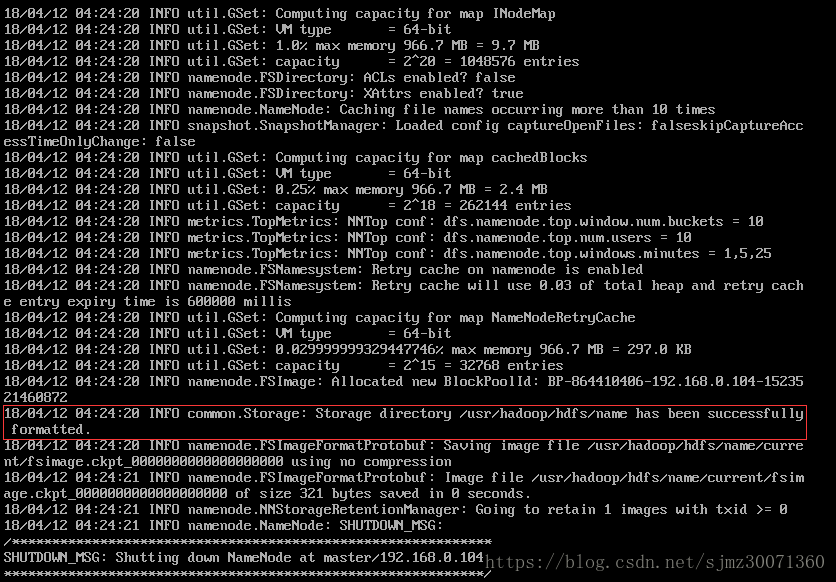
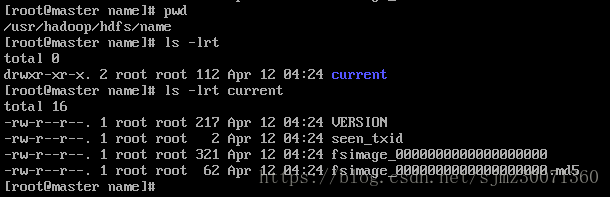
格式化成功后,可以看到在/usr/hadoop/hdfs/name目录下多了一个current目录,而且该目录下有一系列文件,如下:
2) 执行启动(namenode只能在master上启动,因为配置在master上;datanode每个节点上都可以启动)
执行 start-all.sh
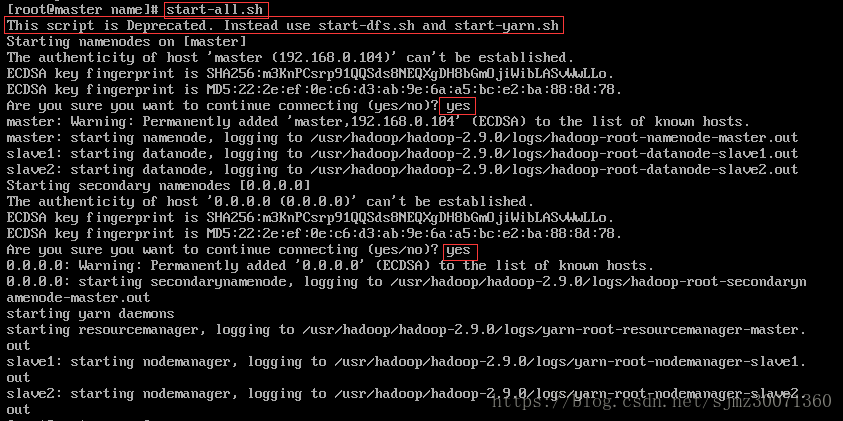
master上执行jps,会看到NameNode, SecondaryNameNode, ResourceManager
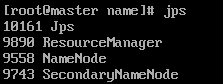
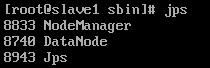
其它节点上执行jps,会看到DataNode, NodeManager
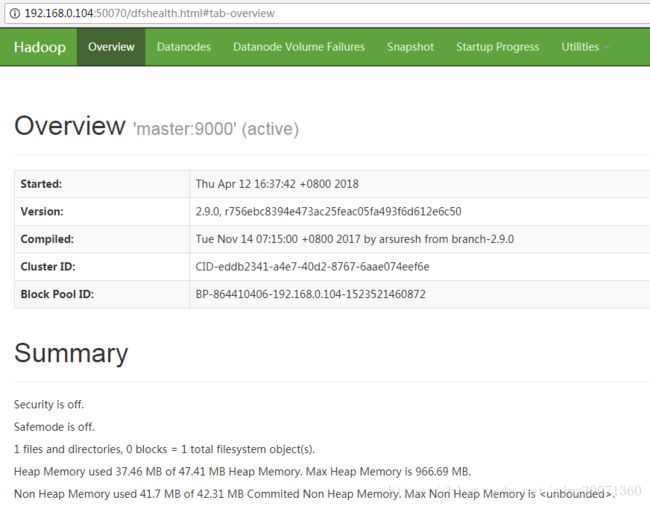
3) 在wins上打开网页,查看HDFS管理页面 http://192.168.0.104:50070查看,提示无法访问
在master上,执行以下命令关闭防火墙,即可访问(为了能够正常访问node节点,最好把其它机器的防火墙也stop了)
systemctl stop firewalld.service
HDFS管理首页
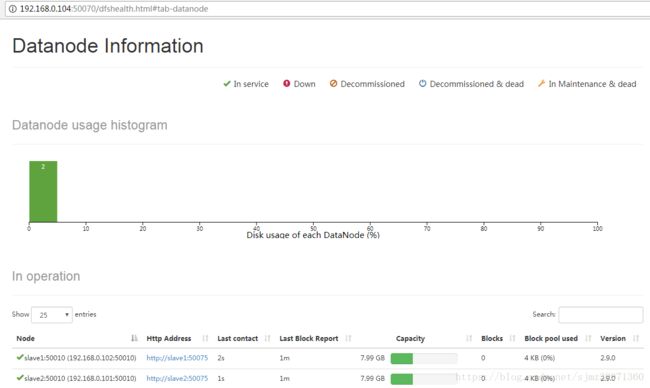
HDFS Datenodes页
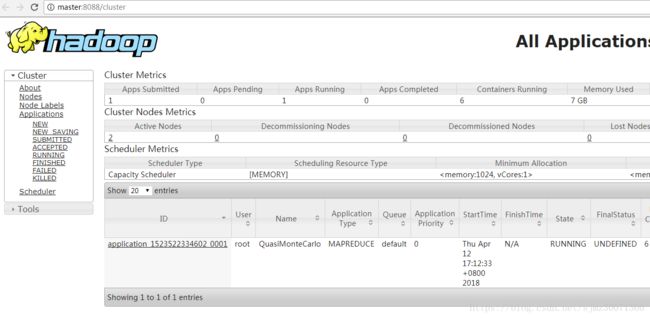
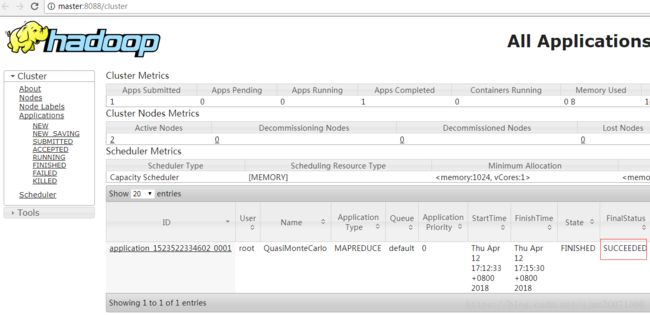
访问Yarn管理页: http://192.168.0.104:8088
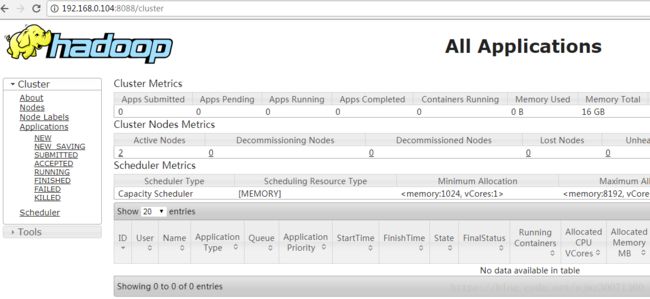
4)通过主机名也可以访问的设置
win7为例,需要将以下信息追加到C:\Windows\System32\drivers\etc\hosts文件中
192.168.0.104 master
192.168.0.102 slave1
192.168.0.101 slave2
Over!!!搭建成功!!!
4. 运行实例
cd /usr/hadoop/hadoop-2.9.0/share/hadoop/mapreduce
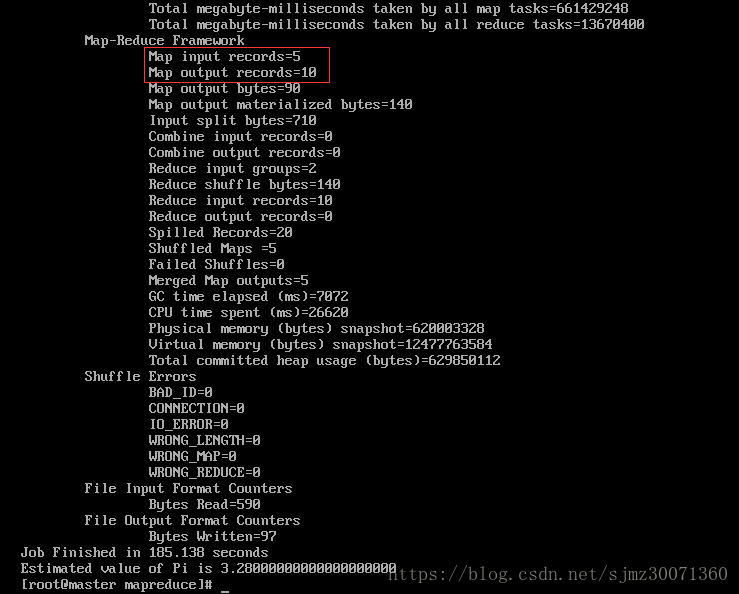
hadoop jar hadoop-mapreduce-examples-2.9.0.jar pi 5 10
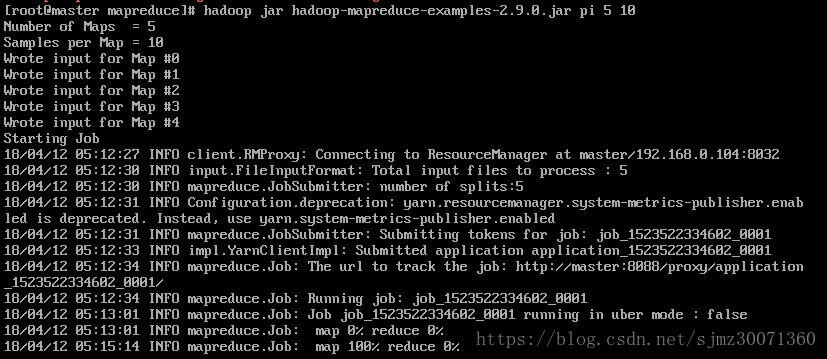
。。。。。。