研究MapReduce源码之实现自定义LineRecordReader完成多行读取文件内容
TextInputFormat是Hadoop默认的数据输入格式,但是它只能一行一行的读记录,如果要读取多行怎么办?
很简单 自己写一个输入格式,然后写一个对应的Recordreader就可以了,但是要实现确不是这么简单的
首先看看TextInputFormat是怎么实现一行一行读取的
大家看一看源码
public class TextInputFormat extends FileInputFormat<LongWritable, Text> {
@Override
public RecordReader
createRecordReader(InputSplit split,
TaskAttemptContext context) {
String delimiter = context.getConfiguration().get(
"textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter)
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
return new LineRecordReader(recordDelimiterBytes);
}
//这个对文件做压缩用的
@Override
protected boolean isSplitable(JobContext context, Path file) {
final CompressionCodec codec =
new CompressionCodecFactory(context.getConfiguration()).getCodec(file);
if (null == codec) {
return true;
}
return codec instanceof SplittableCompressionCodec;
}
} 我们只要看第一个createRecordReader方法即可,从源码分析可知,它new了一个LineRecordReader,那么我们再来看看LineRecordReader的源码,看看这小子的内部世界
public class LineRecordReader extends RecordReader {
private static final Log LOG = LogFactory.getLog(LineRecordReader.class);
public static final String MAX_LINE_LENGTH =
"mapreduce.input.linerecordreader.line.maxlength";
private long start;
private long pos;
private long end;
private SplitLineReader in;
private FSDataInputStream fileIn;
private Seekable filePosition;
private int maxLineLength;
private LongWritable key;
private Text value;
private boolean isCompressedInput;
private Decompressor decompressor;
private byte[] recordDelimiterBytes;
public LineRecordReader() {
}
public LineRecordReader(byte[] recordDelimiter) {
this.recordDelimiterBytes = recordDelimiter;
}
public void initialize(InputSplit genericSplit,
TaskAttemptContext context) throws IOException {
FileSplit split = (FileSplit) genericSplit;
Configuration job = context.getConfiguration();
this.maxLineLength = job.getInt(MAX_LINE_LENGTH, Integer.MAX_VALUE);
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
// open the file and seek to the start of the split
final FileSystem fs = file.getFileSystem(job);
fileIn = fs.open(file);
CompressionCodec codec = new CompressionCodecFactory(job).getCodec(file);
if (null!=codec) {
isCompressedInput = true;
decompressor = CodecPool.getDecompressor(codec);
if (codec instanceof SplittableCompressionCodec) {
final SplitCompressionInputStream cIn =
((SplittableCompressionCodec)codec).createInputStream(
fileIn, decompressor, start, end,
SplittableCompressionCodec.READ_MODE.BYBLOCK);
in = new CompressedSplitLineReader(cIn, job,
this.recordDelimiterBytes);
start = cIn.getAdjustedStart();
end = cIn.getAdjustedEnd();
filePosition = cIn;
} else {
in = new SplitLineReader(codec.createInputStream(fileIn,
decompressor), job, this.recordDelimiterBytes);
filePosition = fileIn;
}
} else {
fileIn.seek(start);
in = new UncompressedSplitLineReader(
fileIn, job, this.recordDelimiterBytes, split.getLength());
filePosition = fileIn;
}
// If this is not the first split, we always throw away first record
// because we always (except the last split) read one extra line in
// next() method.
if (start != 0) {
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;
}
private int maxBytesToConsume(long pos) {
return isCompressedInput
? Integer.MAX_VALUE
: (int) Math.max(Math.min(Integer.MAX_VALUE, end - pos), maxLineLength);
}
private long getFilePosition() throws IOException {
long retVal;
if (isCompressedInput && null != filePosition) {
retVal = filePosition.getPos();
} else {
retVal = pos;
}
return retVal;
}
private int skipUtfByteOrderMark() throws IOException {
// Strip BOM(Byte Order Mark)
// Text only support UTF-8, we only need to check UTF-8 BOM
// (0xEF,0xBB,0xBF) at the start of the text stream.
int newMaxLineLength = (int) Math.min(3L + (long) maxLineLength,
Integer.MAX_VALUE);
int newSize = in.readLine(value, newMaxLineLength, maxBytesToConsume(pos));
// Even we read 3 extra bytes for the first line,
// we won't alter existing behavior (no backwards incompat issue).
// Because the newSize is less than maxLineLength and
// the number of bytes copied to Text is always no more than newSize.
// If the return size from readLine is not less than maxLineLength,
// we will discard the current line and read the next line.
pos += newSize;
int textLength = value.getLength();
byte[] textBytes = value.getBytes();
if ((textLength >= 3) && (textBytes[0] == (byte)0xEF) &&
(textBytes[1] == (byte)0xBB) && (textBytes[2] == (byte)0xBF)) {
// find UTF-8 BOM, strip it.
LOG.info("Found UTF-8 BOM and skipped it");
textLength -= 3;
newSize -= 3;
if (textLength > 0) {
// It may work to use the same buffer and not do the copyBytes
textBytes = value.copyBytes();
value.set(textBytes, 3, textLength);
} else {
value.clear();
}
}
return newSize;
}
public boolean nextKeyValue() throws IOException {
if (key == null) {
key = new LongWritable();
}
key.set(pos);
if (value == null) {
value = new Text();
}
int newSize = 0;
// We always read one extra line, which lies outside the upper
// split limit i.e. (end - 1)
while (getFilePosition() <= end || in.needAdditionalRecordAfterSplit()) {
if (pos == 0) {
newSize = skipUtfByteOrderMark();
} else {
newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos));
pos += newSize;
}
if ((newSize == 0) || (newSize < maxLineLength)) {
break;
}
// line too long. try again
LOG.info("Skipped line of size " + newSize + " at pos " +
(pos - newSize));
}
if (newSize == 0) {
key = null;
value = null;
return false;
} else {
return true;
}
}
@Override
public LongWritable getCurrentKey() {
return key;
}
@Override
public Text getCurrentValue() {
return value;
}
/**
* Get the progress within the split
*/
public float getProgress() throws IOException {
if (start == end) {
return 0.0f;
} else {
return Math.min(1.0f, (getFilePosition() - start) / (float)(end - start));
}
}
public synchronized void close() throws IOException {
try {
if (in != null) {
in.close();
}
} finally {
if (decompressor != null) {
CodecPool.returnDecompressor(decompressor);
}
}
}
} (里面96-97行
in = new CompressedSplitLineReader(cIn, job, this.recordDelimiterBytes);
108-109行
in = new CompressedSplitLineReader(cIn, job,this.recordDelimiterBytes);
这是用来压缩的,大家不用管,知道有这回事就行了
其实这两个类都继承自SplitLineReader,是与压缩有关的,后面我们自定义的时候不用改,粘贴复制过来就行。
)
从上面发现了一个问题,看源码的第57行
private SplitLineReader in;它引入了一个SplitLineReader 类,用这个小子来读取每一行,不信?你看源码的182-197行,如下(我的基于2.6.4版本的源码,不同的版本代码应该差别不大)
while (getFilePosition() <= end || in.needAdditionalRecordAfterSplit()) {
if (pos == 0) {
newSize = skipUtfByteOrderMark();
} else {
newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos));
pos += newSize;
}
if ((newSize == 0) || (newSize < maxLineLength)) {
break;
}
// line too long. try again
LOG.info("Skipped line of size " + newSize + " at pos " +
(pos - newSize));
}发现没有 ===》 newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos));
它用了SplitLineReader 里面的一个方法readLine来读取,所以我们就得继续跟踪去看看SplitLineReader 这个小子的庐山真面目,下面看SplitLineReader 的源码
public class SplitLineReader extends org.apache.hadoop.util.LineReader {
public SplitLineReader(InputStream in, byte[] recordDelimiterBytes) {
super(in, recordDelimiterBytes);
}
public SplitLineReader(InputStream in, Configuration conf,
byte[] recordDelimiterBytes) throws IOException {
super(in, conf, recordDelimiterBytes);
}
public boolean needAdditionalRecordAfterSplit() {
return false;
}
}发现这家伙继承自LineReader(快接近我们的目标了,坚持看下去),发现这小子里面根本就没有readLine方法,大家是不是觉得我在忽悠大家,哈哈,我没有忽悠大家,它源码里面确实没有,但是但是,它可是继承了LineReader这个类,说不定他的父类LineReader有了,好,不信我们去看看LineReader
继续跟踪到LineReader的源码
public class LineReader implements Closeable {
private static final int DEFAULT_BUFFER_SIZE = 64 * 1024;
private int bufferSize = DEFAULT_BUFFER_SIZE;
private InputStream in;
private byte[] buffer;
// the number of bytes of real data in the buffer
private int bufferLength = 0;
// the current position in the buffer
private int bufferPosn = 0;
private static final byte CR = '\r';
private static final byte LF = '\n';
// The line delimiter
private final byte[] recordDelimiterBytes;
/**
* Create a line reader that reads from the given stream using the
* default buffer-size (64k).
* @param in The input stream
* @throws IOException
*/
public LineReader(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
}
/**
* Create a line reader that reads from the given stream using the
* given buffer-size.
* @param in The input stream
* @param bufferSize Size of the read buffer
* @throws IOException
*/
public LineReader(InputStream in, int bufferSize) {
this.in = in;
this.bufferSize = bufferSize;
this.buffer = new byte[this.bufferSize];
this.recordDelimiterBytes = null;
}
/**
* Create a line reader that reads from the given stream using the
* io.file.buffer.size specified in the given
* Configuration.
* @param in input stream
* @param conf configuration
* @throws IOException
*/
public LineReader(InputStream in, Configuration conf) throws IOException {
this(in, conf.getInt("io.file.buffer.size", DEFAULT_BUFFER_SIZE));
}
/**
* Create a line reader that reads from the given stream using the
* default buffer-size, and using a custom delimiter of array of
* bytes.
* @param in The input stream
* @param recordDelimiterBytes The delimiter
*/
public LineReader(InputStream in, byte[] recordDelimiterBytes) {
this.in = in;
this.bufferSize = DEFAULT_BUFFER_SIZE;
this.buffer = new byte[this.bufferSize];
this.recordDelimiterBytes = recordDelimiterBytes;
}
/**
* Create a line reader that reads from the given stream using the
* given buffer-size, and using a custom delimiter of array of
* bytes.
* @param in The input stream
* @param bufferSize Size of the read buffer
* @param recordDelimiterBytes The delimiter
* @throws IOException
*/
public LineReader(InputStream in, int bufferSize,
byte[] recordDelimiterBytes) {
this.in = in;
this.bufferSize = bufferSize;
this.buffer = new byte[this.bufferSize];
this.recordDelimiterBytes = recordDelimiterBytes;
}
/**
* Create a line reader that reads from the given stream using the
* io.file.buffer.size specified in the given
* Configuration, and using a custom delimiter of array of
* bytes.
* @param in input stream
* @param conf configuration
* @param recordDelimiterBytes The delimiter
* @throws IOException
*/
public LineReader(InputStream in, Configuration conf,
byte[] recordDelimiterBytes) throws IOException {
this.in = in;
this.bufferSize = conf.getInt("io.file.buffer.size", DEFAULT_BUFFER_SIZE);
this.buffer = new byte[this.bufferSize];
this.recordDelimiterBytes = recordDelimiterBytes;
}
/**
* Close the underlying stream.
* @throws IOException
*/
public void close() throws IOException {
in.close();
}
/**
* Read one line from the InputStream into the given Text.
*
* @param str the object to store the given line (without newline)
* @param maxLineLength the maximum number of bytes to store into str;
* the rest of the line is silently discarded.
* @param maxBytesToConsume the maximum number of bytes to consume
* in this call. This is only a hint, because if the line cross
* this threshold, we allow it to happen. It can overshoot
* potentially by as much as one buffer length.
*
* @return the number of bytes read including the (longest) newline
* found.
*
* @throws IOException if the underlying stream throws
*/
public int readLine(Text str, int maxLineLength,
int maxBytesToConsume) throws IOException {
if (this.recordDelimiterBytes != null) {
return readCustomLine(str, maxLineLength, maxBytesToConsume);
} else {
return readDefaultLine(str, maxLineLength, maxBytesToConsume);
}
}
protected int fillBuffer(InputStream in, byte[] buffer, boolean inDelimiter)
throws IOException {
return in.read(buffer);
}
/**
* Read a line terminated by one of CR, LF, or CRLF.
*/
private int readDefaultLine(Text str, int maxLineLength, int maxBytesToConsume)
throws IOException {
/* We're reading data from in, but the head of the stream may be
* already buffered in buffer, so we have several cases:
* 1. No newline characters are in the buffer, so we need to copy
* everything and read another buffer from the stream.
* 2. An unambiguously terminated line is in buffer, so we just
* copy to str.
* 3. Ambiguously terminated line is in buffer, i.e. buffer ends
* in CR. In this case we copy everything up to CR to str, but
* we also need to see what follows CR: if it's LF, then we
* need consume LF as well, so next call to readLine will read
* from after that.
* We use a flag prevCharCR to signal if previous character was CR
* and, if it happens to be at the end of the buffer, delay
* consuming it until we have a chance to look at the char that
* follows.
*/
str.clear();
int txtLength = 0; //tracks str.getLength(), as an optimization
int newlineLength = 0; //length of terminating newline
boolean prevCharCR = false; //true of prev char was CR
long bytesConsumed = 0;
do {
int startPosn = bufferPosn; //starting from where we left off the last time
if (bufferPosn >= bufferLength) {
startPosn = bufferPosn = 0;
if (prevCharCR) {
++bytesConsumed; //account for CR from previous read
}
bufferLength = fillBuffer(in, buffer, prevCharCR);
if (bufferLength <= 0) {
break; // EOF
}
}
for (; bufferPosn < bufferLength; ++bufferPosn) { //search for newline
if (buffer[bufferPosn] == LF) {
newlineLength = (prevCharCR) ? 2 : 1;
++bufferPosn; // at next invocation proceed from following byte
break;
}
if (prevCharCR) { //CR + notLF, we are at notLF
newlineLength = 1;
break;
}
prevCharCR = (buffer[bufferPosn] == CR);
}
int readLength = bufferPosn - startPosn;
if (prevCharCR && newlineLength == 0) {
--readLength; //CR at the end of the buffer
}
bytesConsumed += readLength;
int appendLength = readLength - newlineLength;
if (appendLength > maxLineLength - txtLength) {
appendLength = maxLineLength - txtLength;
}
if (appendLength > 0) {
str.append(buffer, startPosn, appendLength);
txtLength += appendLength;
}
} while (newlineLength == 0 && bytesConsumed < maxBytesToConsume);
if (bytesConsumed > Integer.MAX_VALUE) {
throw new IOException("Too many bytes before newline: " + bytesConsumed);
}
return (int)bytesConsumed;
}
/**
* Read a line terminated by a custom delimiter.
*/
private int readCustomLine(Text str, int maxLineLength, int maxBytesToConsume)
throws IOException {
/* We're reading data from inputStream, but the head of the stream may be
* already captured in the previous buffer, so we have several cases:
*
* 1. The buffer tail does not contain any character sequence which
* matches with the head of delimiter. We count it as a
* ambiguous byte count = 0
*
* 2. The buffer tail contains a X number of characters,
* that forms a sequence, which matches with the
* head of delimiter. We count ambiguous byte count = X
*
* // *** eg: A segment of input file is as follows
*
* " record 1792: I found this bug very interesting and
* I have completely read about it. record 1793: This bug
* can be solved easily record 1794: This ."
*
* delimiter = "record";
*
* supposing:- String at the end of buffer =
* "I found this bug very interesting and I have completely re"
* There for next buffer = "ad about it. record 179 ...."
*
* The matching characters in the input
* buffer tail and delimiter head = "re"
* Therefore, ambiguous byte count = 2 **** //
*
* 2.1 If the following bytes are the remaining characters of
* the delimiter, then we have to capture only up to the starting
* position of delimiter. That means, we need not include the
* ambiguous characters in str.
*
* 2.2 If the following bytes are not the remaining characters of
* the delimiter ( as mentioned in the example ),
* then we have to include the ambiguous characters in str.
*/
str.clear();
int txtLength = 0; // tracks str.getLength(), as an optimization
long bytesConsumed = 0;
int delPosn = 0;
int ambiguousByteCount=0; // To capture the ambiguous characters count
do {
int startPosn = bufferPosn; // Start from previous end position
if (bufferPosn >= bufferLength) {
startPosn = bufferPosn = 0;
bufferLength = fillBuffer(in, buffer, ambiguousByteCount > 0);
if (bufferLength <= 0) {
if (ambiguousByteCount > 0) {
str.append(recordDelimiterBytes, 0, ambiguousByteCount);
bytesConsumed += ambiguousByteCount;
}
break; // EOF
}
}
for (; bufferPosn < bufferLength; ++bufferPosn) {
if (buffer[bufferPosn] == recordDelimiterBytes[delPosn]) {
delPosn++;
if (delPosn >= recordDelimiterBytes.length) {
bufferPosn++;
break;
}
} else if (delPosn != 0) {
bufferPosn--;
delPosn = 0;
}
}
int readLength = bufferPosn - startPosn;
bytesConsumed += readLength;
int appendLength = readLength - delPosn;
if (appendLength > maxLineLength - txtLength) {
appendLength = maxLineLength - txtLength;
}
bytesConsumed += ambiguousByteCount;
if (appendLength >= 0 && ambiguousByteCount > 0) {
//appending the ambiguous characters (refer case 2.2)
str.append(recordDelimiterBytes, 0, ambiguousByteCount);
ambiguousByteCount = 0;
// since it is now certain that the split did not split a delimiter we
// should not read the next record: clear the flag otherwise duplicate
// records could be generated
unsetNeedAdditionalRecordAfterSplit();
}
if (appendLength > 0) {
str.append(buffer, startPosn, appendLength);
txtLength += appendLength;
}
if (bufferPosn >= bufferLength) {
if (delPosn > 0 && delPosn < recordDelimiterBytes.length) {
ambiguousByteCount = delPosn;
bytesConsumed -= ambiguousByteCount; //to be consumed in next
}
}
} while (delPosn < recordDelimiterBytes.length
&& bytesConsumed < maxBytesToConsume);
if (bytesConsumed > Integer.MAX_VALUE) {
throw new IOException("Too many bytes before delimiter: " + bytesConsumed);
}
return (int) bytesConsumed;
}
/**
* Read from the InputStream into the given Text.
* @param str the object to store the given line
* @param maxLineLength the maximum number of bytes to store into str.
* @return the number of bytes read including the newline
* @throws IOException if the underlying stream throws
*/
public int readLine(Text str, int maxLineLength) throws IOException {
return readLine(str, maxLineLength, Integer.MAX_VALUE);
}
/**
* Read from the InputStream into the given Text.
* @param str the object to store the given line
* @return the number of bytes read including the newline
* @throws IOException if the underlying stream throws
*/
public int readLine(Text str) throws IOException {
return readLine(str, Integer.MAX_VALUE, Integer.MAX_VALUE);
}
protected int getBufferPosn() {
return bufferPosn;
}
protected int getBufferSize() {
return bufferSize;
}
protected void unsetNeedAdditionalRecordAfterSplit() {
// needed for custom multi byte line delimiters only
// see MAPREDUCE-6549 for details
}
}它里面有很多方法,真的有我们要的readLine方法,说明我的推断没有错,没有忽悠大家,它重载了好几个readLine方法
其他我们不去管,我们只管对我们有用的,如下
public int readLine(Text str, int maxLineLength,
int maxBytesToConsume) throws IOException {
if (this.recordDelimiterBytes != null) {
return readCustomLine(str, maxLineLength, maxBytesToConsume);
} else {
return readDefaultLine(str, maxLineLength, maxBytesToConsume);
}
}它里面调用了readCustomLine方法和readDefaultLine方法,下面看看这两个方法
private int readCustomLine(Text str, int maxLineLength, int maxBytesToConsume)
throws IOException {
str.clear();
int txtLength = 0; // tracks str.getLength(), as an optimization
long bytesConsumed = 0;
int delPosn = 0;
int ambiguousByteCount=0; // To capture the ambiguous characters count
do {
int startPosn = bufferPosn; // Start from previous end position
if (bufferPosn >= bufferLength) {
startPosn = bufferPosn = 0;
bufferLength = fillBuffer(in, buffer, ambiguousByteCount > 0);
if (bufferLength <= 0) {
if (ambiguousByteCount > 0) {
str.append(recordDelimiterBytes, 0, ambiguousByteCount);
bytesConsumed += ambiguousByteCount;
}
break; // EOF
}
}
for (; bufferPosn < bufferLength; ++bufferPosn) {
if (buffer[bufferPosn] == recordDelimiterBytes[delPosn]) {
delPosn++;
if (delPosn >= recordDelimiterBytes.length) {
bufferPosn++;
break;
}
} else if (delPosn != 0) {
bufferPosn--;
delPosn = 0;
}
}
int readLength = bufferPosn - startPosn;
bytesConsumed += readLength;
int appendLength = readLength - delPosn;
if (appendLength > maxLineLength - txtLength) {
appendLength = maxLineLength - txtLength;
}
bytesConsumed += ambiguousByteCount;
if (appendLength >= 0 && ambiguousByteCount > 0) {
//appending the ambiguous characters (refer case 2.2)
str.append(recordDelimiterBytes, 0, ambiguousByteCount);
ambiguousByteCount = 0;
// since it is now certain that the split did not split a delimiter we
// should not read the next record: clear the flag otherwise duplicate
// records could be generated
unsetNeedAdditionalRecordAfterSplit();
}
if (appendLength > 0) {
str.append(buffer, startPosn, appendLength);
txtLength += appendLength;
}
if (bufferPosn >= bufferLength) {
if (delPosn > 0 && delPosn < recordDelimiterBytes.length) {
ambiguousByteCount = delPosn;
bytesConsumed -= ambiguousByteCount; //to be consumed in next
}
}
} while (delPosn < recordDelimiterBytes.length
&& bytesConsumed < maxBytesToConsume);
if (bytesConsumed > Integer.MAX_VALUE) {
throw new IOException("Too many bytes before delimiter: " + bytesConsumed);
}
return (int) bytesConsumed;
} private int readDefaultLine(Text str, int maxLineLength, int maxBytesToConsume)
throws IOException {
str.clear();
int txtLength = 0; //tracks str.getLength(), as an optimization
int newlineLength = 0; //length of terminating newline
boolean prevCharCR = false; //true of prev char was CR
long bytesConsumed = 0;
do {
int startPosn = bufferPosn; //starting from where we left off the last time
if (bufferPosn >= bufferLength) {
startPosn = bufferPosn = 0;
if (prevCharCR) {
++bytesConsumed; //account for CR from previous read
}
bufferLength = fillBuffer(in, buffer, prevCharCR);
if (bufferLength <= 0) {
break; // EOF
}
}
for (; bufferPosn < bufferLength; ++bufferPosn) { //search for newline
if (buffer[bufferPosn] == LF) {
newlineLength = (prevCharCR) ? 2 : 1;
++bufferPosn; // at next invocation proceed from following byte
break;
}
if (prevCharCR) { //CR + notLF, we are at notLF
newlineLength = 1;
break;
}
prevCharCR = (buffer[bufferPosn] == CR);
}
int readLength = bufferPosn - startPosn;
if (prevCharCR && newlineLength == 0) {
--readLength; //CR at the end of the buffer
}
bytesConsumed += readLength;
int appendLength = readLength - newlineLength;
if (appendLength > maxLineLength - txtLength) {
appendLength = maxLineLength - txtLength;
}
if (appendLength > 0) {
str.append(buffer, startPosn, appendLength);
txtLength += appendLength;
}
} while (newlineLength == 0 && bytesConsumed < maxBytesToConsume);
if (bytesConsumed > Integer.MAX_VALUE) {
throw new IOException("Too many bytes before newline: " + bytesConsumed);
}
return (int)bytesConsumed;
}注意注意readCustomLine和readDefaultLine方法的第一句都用了一句代码(重点,后面我们自定义时要改的地方)
他们都用了str.clear();
这句代码什么意思,意思是系统每读完一行,它会清空这一行的值!!!
如果我们自定义读取多行的时候,肯定不能清空它,因为我们需要它来计数第二行的位置
比如
123,
456
789,
111
如果一次读两行的话 假如我把第一行清空了,那么我第二行的偏移量就得不到正确的值了,读出来的值本应该是
123,456
789,111
但是如果清空了的话 就读出来少了一行
变成了
456
111
所以我们只有独到最后一行才清空值,它前面的行都不能清空
这就要求我们到时候自己重载一个方法了,到时候再说,大家接着看
有没有晕了,没有? 那就好,我都说得这么清楚了,还晕的话,大家就先休息一下
我帮大家理一理:看都用到了哪些类

最开始TextInputFormat里面用到了LineRecordReader,LineRecordReader里面用到了SplitLineReader,而SplitLineReader里面用到了LineReader
自定义的时候思路按这个来
TextInputFormat–》LineRecordReader–》SplitLineReader–》LineReader
下面写第一个自定义的TextInputFormat
package com.my.input;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.SplittableCompressionCodec;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
public class myInputFormat extends FileInputFormat {
//用来压缩的
@Override
protected boolean isSplitable(JobContext context, Path file) {
final CompressionCodec codec =
new CompressionCodecFactory(context.getConfiguration()).getCodec(file);
if (null == codec) {
return true;
}
return codec instanceof SplittableCompressionCodec;
}
@Override
public RecordReader createRecordReader(InputSplit genericSplit, TaskAttemptContext context)
throws IOException, InterruptedException {
context.setStatus(genericSplit.toString());
return new MyRecordReader(context.getConfiguration());
}
} 接着写一个自定义的LineRecordReader
其中修改了182行开始的以下代码
因为我这里要实现输出多行,所以写了一个for循环,又由于我前面说得前面的行不能清空,所以要加一个boolean标志量
把
while (getFilePosition() <= end || in.needAdditionalRecordAfterSplit()) {
if (pos == 0) {
newSize = skipUtfByteOrderMark();
} else {
newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos));
pos += newSize;
}
if ((newSize == 0) || (newSize < maxLineLength)) {
break;
}
// line too long. try again
LOG.info("Skipped line of size " + newSize + " at pos " +
(pos - newSize));
}改为
boolean clear = true;
for (int i = 1; i <= 2; i++) {
if (i == 2) {
clear = false;
}
while (getFilePosition() <= end || in.needAdditionalRecordAfterSplit()) {
if (pos == 0) {
newSize = skipUtfByteOrderMark();
} else {
newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos), clear);
pos += newSize;
}
if ((newSize == 0) || (newSize < maxLineLength)) {
break;
}
// line too long. try again
LOG.info("Skipped line of size " + newSize + " at pos " + (pos - newSize));
}
}再写自定义SplitLineReader
package com.my.lingRecordReader;
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configuration;
@InterfaceAudience.Private
@InterfaceStability.Unstable
public class MySplitLineReader extends MyLineReader {
public MySplitLineReader(InputStream in, byte[] recordDelimiterBytes) {
super(in, recordDelimiterBytes);
}
public MySplitLineReader(InputStream in, Configuration conf,
byte[] recordDelimiterBytes) throws IOException {
super(in, conf, recordDelimiterBytes);
}
public boolean needAdditionalRecordAfterSplit() {
return false;
}
}最后写自定义LineReader
它重载了一个readLine(Text str, int maxLineLength, int maxBytesToConsume, boolean clear)方法来实现不清空前面读取的行的值
package com.my.lingRecordReader;
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import java.io.Closeable;
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.Text;
/**
* A class that provides a line reader from an input stream. Depending on the
* constructor used, lines will either be terminated by:
*
* - one of the following: '\n' (LF) , '\r' (CR), or '\r\n' (CR+LF).
* - or, a custom byte sequence delimiter
*
* In both cases, EOF also terminates an otherwise unterminated line.
*/
@InterfaceAudience.LimitedPrivate({ "MapReduce" })
@InterfaceStability.Unstable
public class MyLineReader implements Closeable {
private static final int DEFAULT_BUFFER_SIZE = 64 * 1024;
private int bufferSize = DEFAULT_BUFFER_SIZE;
private InputStream in;
private byte[] buffer;
// the number of bytes of real data in the buffer
private int bufferLength = 0;
// the current position in the buffer
private int bufferPosn = 0;
private static final byte CR = '\r';
private static final byte LF = '\n';
// The line delimiter
private final byte[] recordDelimiterBytes;
/**
* Create a line reader that reads from the given stream using the default
* buffer-size (64k).
*
* @param in
* The input stream
* @throws IOException
*/
public MyLineReader(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
}
/**
* Create a line reader that reads from the given stream using the given
* buffer-size.
*
* @param in
* The input stream
* @param bufferSize
* Size of the read buffer
* @throws IOException
*/
public MyLineReader(InputStream in, int bufferSize) {
this.in = in;
this.bufferSize = bufferSize;
this.buffer = new byte[this.bufferSize];
this.recordDelimiterBytes = null;
}
/**
* Create a line reader that reads from the given stream using the
* io.file.buffer.size specified in the given
* Configuration.
*
* @param in
* input stream
* @param conf
* configuration
* @throws IOException
*/
public MyLineReader(InputStream in, Configuration conf) throws IOException {
this(in, conf.getInt("io.file.buffer.size", DEFAULT_BUFFER_SIZE));
}
/**
* Create a line reader that reads from the given stream using the default
* buffer-size, and using a custom delimiter of array of bytes.
*
* @param in
* The input stream
* @param recordDelimiterBytes
* The delimiter
*/
public MyLineReader(InputStream in, byte[] recordDelimiterBytes) {
this.in = in;
this.bufferSize = DEFAULT_BUFFER_SIZE;
this.buffer = new byte[this.bufferSize];
this.recordDelimiterBytes = recordDelimiterBytes;
}
/**
* Create a line reader that reads from the given stream using the given
* buffer-size, and using a custom delimiter of array of bytes.
*
* @param in
* The input stream
* @param bufferSize
* Size of the read buffer
* @param recordDelimiterBytes
* The delimiter
* @throws IOException
*/
public MyLineReader(InputStream in, int bufferSize, byte[] recordDelimiterBytes) {
this.in = in;
this.bufferSize = bufferSize;
this.buffer = new byte[this.bufferSize];
this.recordDelimiterBytes = recordDelimiterBytes;
}
/**
* Create a line reader that reads from the given stream using the
* io.file.buffer.size specified in the given
* Configuration, and using a custom delimiter of array of
* bytes.
*
* @param in
* input stream
* @param conf
* configuration
* @param recordDelimiterBytes
* The delimiter
* @throws IOException
*/
public MyLineReader(InputStream in, Configuration conf, byte[] recordDelimiterBytes) throws IOException {
this.in = in;
this.bufferSize = conf.getInt("io.file.buffer.size", DEFAULT_BUFFER_SIZE);
this.buffer = new byte[this.bufferSize];
this.recordDelimiterBytes = recordDelimiterBytes;
}
/**
* Close the underlying stream.
*
* @throws IOException
*/
public void close() throws IOException {
in.close();
}
/**
* Read one line from the InputStream into the given Text.
*
* @param str
* the object to store the given line (without newline)
* @param maxLineLength
* the maximum number of bytes to store into str; the rest of the
* line is silently discarded.
* @param maxBytesToConsume
* the maximum number of bytes to consume in this call. This is
* only a hint, because if the line cross this threshold, we
* allow it to happen. It can overshoot potentially by as much as
* one buffer length.
*
* @return the number of bytes read including the (longest) newline found.
*
* @throws IOException
* if the underlying stream throws
*/
public int readLine(Text str, int maxLineLength, int maxBytesToConsume) throws IOException {
if (this.recordDelimiterBytes != null) {
return readCustomLine(str, maxLineLength, maxBytesToConsume);
} else {
return readDefaultLine(str, maxLineLength, maxBytesToConsume);
}
}
public int readLine(Text str, int maxLineLength, int maxBytesToConsume, boolean clear) throws IOException {
if (this.recordDelimiterBytes != null) {
return readCustomLine(str, maxLineLength, maxBytesToConsume,clear);
} else {
return readDefaultLine(str, maxLineLength, maxBytesToConsume,clear);
}
}
protected int fillBuffer(InputStream in, byte[] buffer, boolean inDelimiter) throws IOException {
return in.read(buffer);
}
private int readDefaultLine(Text str, int maxLineLength, int maxBytesToConsume, boolean clear) throws IOException {
if (clear) {
str.clear();
}
int txtLength = 0; // tracks str.getLength(), as an optimization
int newlineLength = 0; // length of terminating newline
boolean prevCharCR = false; // true of prev char was CR
long bytesConsumed = 0;
do {
int startPosn = bufferPosn; // starting from where we left off the
// last time
if (bufferPosn >= bufferLength) {
startPosn = bufferPosn = 0;
if (prevCharCR) {
++bytesConsumed; // account for CR from previous read
}
bufferLength = fillBuffer(in, buffer, prevCharCR);
if (bufferLength <= 0) {
break; // EOF
}
}
for (; bufferPosn < bufferLength; ++bufferPosn) { // search for
// newline
if (buffer[bufferPosn] == LF) {
newlineLength = (prevCharCR) ? 2 : 1;
++bufferPosn; // at next invocation proceed from following
// byte
break;
}
if (prevCharCR) { // CR + notLF, we are at notLF
newlineLength = 1;
break;
}
prevCharCR = (buffer[bufferPosn] == CR);
}
int readLength = bufferPosn - startPosn;
if (prevCharCR && newlineLength == 0) {
--readLength; // CR at the end of the buffer
}
bytesConsumed += readLength;
int appendLength = readLength - newlineLength;
if (appendLength > maxLineLength - txtLength) {
appendLength = maxLineLength - txtLength;
}
if (appendLength > 0) {
str.append(buffer, startPosn, appendLength);
txtLength += appendLength;
}
} while (newlineLength == 0 && bytesConsumed < maxBytesToConsume);
if (bytesConsumed > Integer.MAX_VALUE) {
throw new IOException("Too many bytes before newline: " + bytesConsumed);
}
return (int) bytesConsumed;
}
/**
* Read a line terminated by one of CR, LF, or CRLF.
*/
private int readDefaultLine(Text str, int maxLineLength, int maxBytesToConsume) throws IOException {
str.clear();
int txtLength = 0; // tracks str.getLength(), as an optimization
int newlineLength = 0; // length of terminating newline
boolean prevCharCR = false; // true of prev char was CR
long bytesConsumed = 0;
do {
int startPosn = bufferPosn; // starting from where we left off the
// last time
if (bufferPosn >= bufferLength) {
startPosn = bufferPosn = 0;
if (prevCharCR) {
++bytesConsumed; // account for CR from previous read
}
bufferLength = fillBuffer(in, buffer, prevCharCR);
if (bufferLength <= 0) {
break; // EOF
}
}
for (; bufferPosn < bufferLength; ++bufferPosn) { // search for
// newline
if (buffer[bufferPosn] == LF) {
newlineLength = (prevCharCR) ? 2 : 1;
++bufferPosn; // at next invocation proceed from following
// byte
break;
}
if (prevCharCR) { // CR + notLF, we are at notLF
newlineLength = 1;
break;
}
prevCharCR = (buffer[bufferPosn] == CR);
}
int readLength = bufferPosn - startPosn;
if (prevCharCR && newlineLength == 0) {
--readLength; // CR at the end of the buffer
}
bytesConsumed += readLength;
int appendLength = readLength - newlineLength;
if (appendLength > maxLineLength - txtLength) {
appendLength = maxLineLength - txtLength;
}
if (appendLength > 0) {
str.append(buffer, startPosn, appendLength);
txtLength += appendLength;
}
} while (newlineLength == 0 && bytesConsumed < maxBytesToConsume);
if (bytesConsumed > Integer.MAX_VALUE) {
throw new IOException("Too many bytes before newline: " + bytesConsumed);
}
return (int) bytesConsumed;
}
private int readCustomLine(Text str, int maxLineLength, int maxBytesToConsume, boolean clear) throws IOException {
if (clear) {
str.clear();
}
int txtLength = 0; // tracks str.getLength(), as an optimization
long bytesConsumed = 0;
int delPosn = 0;
int ambiguousByteCount = 0; // To capture the ambiguous characters count
do {
int startPosn = bufferPosn; // Start from previous end position
if (bufferPosn >= bufferLength) {
startPosn = bufferPosn = 0;
bufferLength = fillBuffer(in, buffer, ambiguousByteCount > 0);
if (bufferLength <= 0) {
if (ambiguousByteCount > 0) {
str.append(recordDelimiterBytes, 0, ambiguousByteCount);
bytesConsumed += ambiguousByteCount;
}
break; // EOF
}
}
for (; bufferPosn < bufferLength; ++bufferPosn) {
if (buffer[bufferPosn] == recordDelimiterBytes[delPosn]) {
delPosn++;
if (delPosn >= recordDelimiterBytes.length) {
bufferPosn++;
break;
}
} else if (delPosn != 0) {
bufferPosn--;
delPosn = 0;
}
}
int readLength = bufferPosn - startPosn;
bytesConsumed += readLength;
int appendLength = readLength - delPosn;
if (appendLength > maxLineLength - txtLength) {
appendLength = maxLineLength - txtLength;
}
bytesConsumed += ambiguousByteCount;
if (appendLength >= 0 && ambiguousByteCount > 0) {
// appending the ambiguous characters (refer case 2.2)
str.append(recordDelimiterBytes, 0, ambiguousByteCount);
ambiguousByteCount = 0;
// since it is now certain that the split did not split a
// delimiter we
// should not read the next record: clear the flag otherwise
// duplicate
// records could be generated
unsetNeedAdditionalRecordAfterSplit();
}
if (appendLength > 0) {
str.append(buffer, startPosn, appendLength);
txtLength += appendLength;
}
if (bufferPosn >= bufferLength) {
if (delPosn > 0 && delPosn < recordDelimiterBytes.length) {
ambiguousByteCount = delPosn;
bytesConsumed -= ambiguousByteCount; // to be consumed in
// next
}
}
} while (delPosn < recordDelimiterBytes.length && bytesConsumed < maxBytesToConsume);
if (bytesConsumed > Integer.MAX_VALUE) {
throw new IOException("Too many bytes before delimiter: " + bytesConsumed);
}
return (int) bytesConsumed;
}
/**
* Read a line terminated by a custom delimiter.
*/
private int readCustomLine(Text str, int maxLineLength, int maxBytesToConsume) throws IOException {
str.clear();
int txtLength = 0; // tracks str.getLength(), as an optimization
long bytesConsumed = 0;
int delPosn = 0;
int ambiguousByteCount = 0; // To capture the ambiguous characters count
do {
int startPosn = bufferPosn; // Start from previous end position
if (bufferPosn >= bufferLength) {
startPosn = bufferPosn = 0;
bufferLength = fillBuffer(in, buffer, ambiguousByteCount > 0);
if (bufferLength <= 0) {
if (ambiguousByteCount > 0) {
str.append(recordDelimiterBytes, 0, ambiguousByteCount);
bytesConsumed += ambiguousByteCount;
}
break; // EOF
}
}
for (; bufferPosn < bufferLength; ++bufferPosn) {
if (buffer[bufferPosn] == recordDelimiterBytes[delPosn]) {
delPosn++;
if (delPosn >= recordDelimiterBytes.length) {
bufferPosn++;
break;
}
} else if (delPosn != 0) {
bufferPosn--;
delPosn = 0;
}
}
int readLength = bufferPosn - startPosn;
bytesConsumed += readLength;
int appendLength = readLength - delPosn;
if (appendLength > maxLineLength - txtLength) {
appendLength = maxLineLength - txtLength;
}
bytesConsumed += ambiguousByteCount;
if (appendLength >= 0 && ambiguousByteCount > 0) {
// appending the ambiguous characters (refer case 2.2)
str.append(recordDelimiterBytes, 0, ambiguousByteCount);
ambiguousByteCount = 0;
// since it is now certain that the split did not split a
// delimiter we
// should not read the next record: clear the flag otherwise
// duplicate
// records could be generated
unsetNeedAdditionalRecordAfterSplit();
}
if (appendLength > 0) {
str.append(buffer, startPosn, appendLength);
txtLength += appendLength;
}
if (bufferPosn >= bufferLength) {
if (delPosn > 0 && delPosn < recordDelimiterBytes.length) {
ambiguousByteCount = delPosn;
bytesConsumed -= ambiguousByteCount; // to be consumed in
// next
}
}
} while (delPosn < recordDelimiterBytes.length && bytesConsumed < maxBytesToConsume);
if (bytesConsumed > Integer.MAX_VALUE) {
throw new IOException("Too many bytes before delimiter: " + bytesConsumed);
}
return (int) bytesConsumed;
}
/**
* Read from the InputStream into the given Text.
*
* @param str
* the object to store the given line
* @param maxLineLength
* the maximum number of bytes to store into str.
* @return the number of bytes read including the newline
* @throws IOException
* if the underlying stream throws
*/
public int readLine(Text str, int maxLineLength) throws IOException {
return readLine(str, maxLineLength, Integer.MAX_VALUE);
}
/**
* Read from the InputStream into the given Text.
*
* @param str
* the object to store the given line
* @return the number of bytes read including the newline
* @throws IOException
* if the underlying stream throws
*/
public int readLine(Text str) throws IOException {
return readLine(str, Integer.MAX_VALUE, Integer.MAX_VALUE);
}
protected int getBufferPosn() {
return bufferPosn;
}
protected int getBufferSize() {
return bufferSize;
}
protected void unsetNeedAdditionalRecordAfterSplit() {
// needed for custom multi byte line delimiters only
// see MAPREDUCE-6549 for details
}
}下面是两个帮助类,用来压缩的,自定义一下(其实是复制源码,没有改动,只改了类名,因为我改了整个继承结构,所以只能加一个压缩的)
package com.my.lingRecordReader;
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.SplitCompressionInputStream;
/**
* Line reader for compressed splits
*
* Reading records from a compressed split is tricky, as the
* LineRecordReader is using the reported compressed input stream
* position directly to determine when a split has ended. In addition the
* compressed input stream is usually faking the actual byte position, often
* updating it only after the first compressed block after the split is
* accessed.
*
* Depending upon where the last compressed block of the split ends relative
* to the record delimiters it can be easy to accidentally drop the last
* record or duplicate the last record between this split and the next.
*
* Split end scenarios:
*
* 1) Last block of split ends in the middle of a record
* Nothing special that needs to be done here, since the compressed input
* stream will report a position after the split end once the record
* is fully read. The consumer of the next split will discard the
* partial record at the start of the split normally, and no data is lost
* or duplicated between the splits.
*
* 2) Last block of split ends in the middle of a delimiter
* The line reader will continue to consume bytes into the next block to
* locate the end of the delimiter. If a custom delimiter is being used
* then the next record must be read by this split or it will be dropped.
* The consumer of the next split will not recognize the partial
* delimiter at the beginning of its split and will discard it along with
* the next record.
*
* However for the default delimiter processing there is a special case
* because CR, LF, and CRLF are all valid record delimiters. If the
* block ends with a CR then the reader must peek at the next byte to see
* if it is an LF and therefore part of the same record delimiter.
* Peeking at the next byte is an access to the next block and triggers
* the stream to report the end of the split. There are two cases based
* on the next byte:
*
* A) The next byte is LF
* The split needs to end after the current record is returned. The
* consumer of the next split will discard the first record, which
* is degenerate since LF is itself a delimiter, and start consuming
* records after that byte. If the current split tries to read
* another record then the record will be duplicated between splits.
*
* B) The next byte is not LF
* The current record will be returned but the stream will report
* the split has ended due to the peek into the next block. If the
* next record is not read then it will be lost, as the consumer of
* the next split will discard it before processing subsequent
* records. Therefore the next record beyond the reported split end
* must be consumed by this split to avoid data loss.
*
* 3) Last block of split ends at the beginning of a delimiter
* This is equivalent to case 1, as the reader will consume bytes into
* the next block and trigger the end of the split. No further records
* should be read as the consumer of the next split will discard the
* (degenerate) record at the beginning of its split.
*
* 4) Last block of split ends at the end of a delimiter
* Nothing special needs to be done here. The reader will not start
* examining the bytes into the next block until the next record is read,
* so the stream will not report the end of the split just yet. Once the
* next record is read then the next block will be accessed and the
* stream will indicate the end of the split. The consumer of the next
* split will correctly discard the first record of its split, and no
* data is lost or duplicated.
*
* If the default delimiter is used and the block ends at a CR then this
* is treated as case 2 since the reader does not yet know without
* looking at subsequent bytes whether the delimiter has ended.
*
* NOTE: It is assumed that compressed input streams *never* return bytes from
* multiple compressed blocks from a single read. Failure to do so will
* violate the buffering performed by this class, as it will access
* bytes into the next block after the split before returning all of the
* records from the previous block.
*/
@InterfaceAudience.Private
@InterfaceStability.Unstable
public class MyCompressedSplitLineReader extends MySplitLineReader {
SplitCompressionInputStream scin;
private boolean usingCRLF;
private boolean needAdditionalRecord = false;
private boolean finished = false;
public MyCompressedSplitLineReader(SplitCompressionInputStream in,
Configuration conf,
byte[] recordDelimiterBytes)
throws IOException {
super(in, conf, recordDelimiterBytes);
scin = in;
usingCRLF = (recordDelimiterBytes == null);
}
@Override
protected int fillBuffer(InputStream in, byte[] buffer, boolean inDelimiter)
throws IOException {
int bytesRead = in.read(buffer);
// If the split ended in the middle of a record delimiter then we need
// to read one additional record, as the consumer of the next split will
// not recognize the partial delimiter as a record.
// However if using the default delimiter and the next character is a
// linefeed then next split will treat it as a delimiter all by itself
// and the additional record read should not be performed.
if (inDelimiter && bytesRead > 0) {
if (usingCRLF) {
needAdditionalRecord = (buffer[0] != '\n');
} else {
needAdditionalRecord = true;
}
}
return bytesRead;
}
@Override
public int readLine(Text str, int maxLineLength, int maxBytesToConsume)
throws IOException {
int bytesRead = 0;
if (!finished) {
// only allow at most one more record to be read after the stream
// reports the split ended
if (scin.getPos() > scin.getAdjustedEnd()) {
finished = true;
}
bytesRead = super.readLine(str, maxLineLength, maxBytesToConsume);
}
return bytesRead;
}
@Override
public boolean needAdditionalRecordAfterSplit() {
return !finished && needAdditionalRecord;
}
}第二个与压缩有关的类
package com.my.lingRecordReader;
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.io.Text;
/**
* SplitLineReader for uncompressed files.
* This class can split the file correctly even if the delimiter is multi-bytes.
*/
@InterfaceAudience.Private
@InterfaceStability.Unstable
public class MyUncompressedSplitLineReader extends MySplitLineReader {
private boolean needAdditionalRecord = false;
private long splitLength;
/** Total bytes read from the input stream. */
private long totalBytesRead = 0;
private boolean finished = false;
private boolean usingCRLF;
public MyUncompressedSplitLineReader(FSDataInputStream in, Configuration conf,
byte[] recordDelimiterBytes, long splitLength) throws IOException {
super(in, conf, recordDelimiterBytes);
this.splitLength = splitLength;
usingCRLF = (recordDelimiterBytes == null);
}
@Override
protected int fillBuffer(InputStream in, byte[] buffer, boolean inDelimiter)
throws IOException {
int maxBytesToRead = buffer.length;
if (totalBytesRead < splitLength) {
maxBytesToRead = Math.min(maxBytesToRead,
(int)(splitLength - totalBytesRead));
}
int bytesRead = in.read(buffer, 0, maxBytesToRead);
// If the split ended in the middle of a record delimiter then we need
// to read one additional record, as the consumer of the next split will
// not recognize the partial delimiter as a record.
// However if using the default delimiter and the next character is a
// linefeed then next split will treat it as a delimiter all by itself
// and the additional record read should not be performed.
if (totalBytesRead == splitLength && inDelimiter && bytesRead > 0) {
if (usingCRLF) {
needAdditionalRecord = (buffer[0] != '\n');
} else {
needAdditionalRecord = true;
}
}
if (bytesRead > 0) {
totalBytesRead += bytesRead;
}
return bytesRead;
}
@Override
public int readLine(Text str, int maxLineLength, int maxBytesToConsume)
throws IOException {
int bytesRead = 0;
if (!finished) {
// only allow at most one more record to be read after the stream
// reports the split ended
if (totalBytesRead > splitLength) {
finished = true;
}
bytesRead = super.readLine(str, maxLineLength, maxBytesToConsume);
}
return bytesRead;
}
@Override
public boolean needAdditionalRecordAfterSplit() {
return !finished && needAdditionalRecord;
}
@Override
protected void unsetNeedAdditionalRecordAfterSplit() {
needAdditionalRecord = false;
}
}最后就可以来测试了
先看看测试前的文件内容

package com.my.lingRecordReader;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import com.my.input.myInputFormat;
public class myTest {
/**
*
* @author 汤高
*/
//Map过程
static int count=0;
public static class MyTestMapper extends Mapper {
/***
*
*/
@Override
protected void map(LongWritable key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
//默认的map的value是每一行,我这里自定义的是以空格分割
count++;
//String[] vs = value.toString().split(",");
//for (String v : vs) {
//写出去
context.write(new Text(value), key);
//}
System.out.println("========>"+count);
}
}
public static void main(String[] args) {
Configuration conf=new Configuration();
try {
//args从控制台获取路径 解析得到域名
String[] paths=new GenericOptionsParser(conf,args).getRemainingArgs();
if(paths.length<2){
throw new RuntimeException("必須輸出 輸入 和输出路径");
}
//得到一个Job 并设置名字
Job job=Job.getInstance(conf,"myTest");
//设置Jar 使本程序在Hadoop中运行
job.setJarByClass(myTest.class);
//设置Map处理类
job.setMapperClass(MyTestMapper.class);
job.setInputFormatClass(MyTextInputFormat.class);
//设置map的输出类型,因为不一致,所以要设置
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(paths[0]));
FileOutputFormat.setOutputPath(job, new Path(paths[1] + System.currentTimeMillis()));// 整合好结果后输出的位置
//启动运行
System.exit(job.waitForCompletion(true) ? 0:1);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} 测试结果:
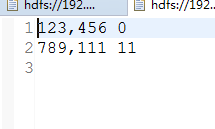
看第2列的偏移量,发现已经实现了一次读多行(我测试的是2行)
到此所有分析已经完了,研究源码真不容易,花了我一个晚上去研究hadoop的源码,然后再花了几个小时把这些内容写成博客,所以,码字不易,转载请指明出处http://blog.csdn.net/tanggao1314/article/details/51307642