hadoop本地、伪分布、真分布、HA模式实践
1、基础环境:
需要准备vmware、centos7、JDK8+、putty(ssh远程工具)、WinSCP(sftp连接工具,用于传文件到linux)、hadoop-2.9.1.tar
基础环境安装不做介绍,网上教程很多。安装完成后效果
putty通过ssh远程:

WinSCP通过SFTP远程:

2、安装jdk:
1)、安装jdk: rpm -ivh jdk-10.0.1_linux-x64_bin.rpm
2)、设置默认JDK:alternatives --config java
3)、设置环境变量:
vim /etc/profile
增加下列内容
export JAVA_HOME=/usr/java/jdk-10.0.1
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profie(永久生效,否则作用于当前会话,重启后会失效)
4)、测试jdk安装是否成功 :使用java、javac命令看是否能打印出帮助信息。
3、配置主机名称:
1)、$ vim /etc/sysconfig/network
设置
NETWORKING=yes #使用网络
HOSTNAME=server1 #设置主机名
2)、$ vim /etc/hosts
添加
192.168.0.13 server1
3)、$ vim /etc/hostname
修改
server1
4、配置hadoop:
首先介绍下hadoop的三种模式:本地模式(安装就可以,无需任何配置)、伪分布式模式(NameNode、DataNode运行在同一台机器)、真分步式模式(NameNode、DataNode运行在不同机器,至少需要3台虚拟机,1个NameNode,2个DataNode)
1)、伪分步式模式:
1、将安装包解压到/opt/modules/hadoop
2、HADOOP配置环境变量:vim /etc/profile
export HADOOP_HOME=/opt/modules/hadoop/hadoop-2.9.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
3、配置 hadoop-env.sh、mapred-env.sh、yarn-env.sh文件的JAVA_HOME参数(高版本有可能已配置,检查下)
vim ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh
修改JAVA_HOME参数为:
export JAVA_HOME=/usr/java/jdk-10.0.1
4、配置core-site.xml

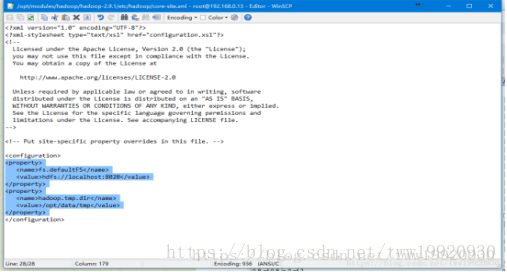
(1) fs.defaultFS参数配置的是HDFS的地址
(2)默认的hadoop.tmp.dir是/tmp/hadoop-${user.name},此时有个问题就是NameNode会将HDFS的元数据存储在这个/tmp目录下,如果操作系统重启了,系统会清空/tmp目录下的东西,导致NameNode元数据丢失,是个非常严重的问题,所有我们应该修改这个路径。
5、配置hdfs-site.xml

dfs.replication配置的是HDFS存储时的备份数量,因为这里是伪分布式环境只有一个节点,所以这里设置为1(默认是复制3份)。
6、格式化HFDS:hdfs namenode -format(注意“-”是中文格式)
启动NameNode:hadoop-daemon.sh start namenode
启动DataNode:hadoop-daemon.sh start datanode
启动SecondaryNameNode:hadoop-daemon.sh start secondarynamenode
JPS命令查看是否已经启动成功,有结果就是启动成功了。
测试hdfs:
创建文件夹:hdfs dfs -mkdir /demo
上传文件:hdfs dfs -put /opt/data/test.txt /demo
查看文件:hdfs dfs -cat /demo/test.txt
下载文件:hdfs dfs -get /demo/test.txt text2.txt
7、配置、启动YARN
1)配置mapred-site.xml:
把mapred-site.xml.template复制一份命名为mapred-site.xml,增加


2)、配置yarn-site.xml

3)、
启动Resourcemanager:yarn-daemon.sh start resourcemanager
启动nodemanager:yarn-daemon.sh start nodemanager
查看是否启动成功:jps

4)访问yarn:YARN的Web客户端端口号是8088,通过http://192.168.0.13:8088/可以查看。
8、运行MapReduce Job
上传文件:hdfs dfs -put /opt/data/test.txt /demo/
运行WordCount MapReduce Job:yarn jar /opt/modules/hadoop/hadoop-2.9.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.1.jar wordcount /demo /demo/output
查看运算结果是否存在:hdfs dfs -ls /demo(存在output目录)
查看运算结果:hdfs dfs -cat /demo/output/part-r-00000

9、开启历史记录服务
mr-jobhistory-daemon.sh start historyserver
历史记录 Web客户端:http://192.168.0.13:19888/
2)、真分步式模式:
server1 |
server2 |
server3 |
NameNode |
ResourceManage |
|
DataNode |
DataNode |
DataNode |
NodeManager |
NodeManager |
NodeManager |
|
|
SecondaryNameNode |
|
|
HistoryServer |
1、克隆server1虚拟机------------------>server2、server3
2、编辑hosts文件
$ vim /etc/hosts
添加
192.168.0.5 server1
192.168.0.13 server2
192.168.0.6 server3
注意,需要放在最前面,不然有可能会出现异常问题。
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
3、调整配置文件
core-site.xml:
hdfs-site.xml:
mapred-site.xml:
slaves(记录所有datanode主机名):
server1
server2
server3
yarn-site.xml:
4、格式化磁盘(server1(namenode节点)执行)
hdfs namenode -format
5、启动hadoop
namenode端执行(server1):
start-dfs.sh(启动namenode、secondarynamenode、datanode)
start-yarn.sh(启动nodemanager)
#start-all.sh=start-dfs.sh+start-yarn.sh
resourcemanager端执行(server2):
yarn-daemon.sh start resourcemanager
historyserver端执行(server3):
mr-jobhistory-daemon.sh start historyserver
6、查看HDFS Web页面:http://server1:50070/

7、查看YARN Web 页面:http://server2:8088/cluster
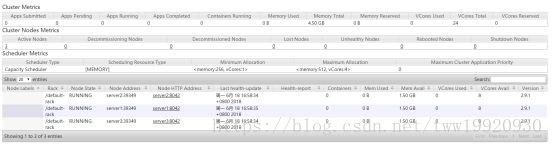
8、测试
创建文件夹:hdfs dfs -mkdir /demo
上传文件:hdfs dfs -put /opt/data/test2.txt /demo/test.txt
删除输出目录:hdfs dfs -rm -r /demo/output
测试单词计数:yarn jar /opt/modules/hadoop/hadoop-2.9.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.1.jar wordcount /demo /demo/output
3)、HA模式:
High Availability高可用,指当前工作中的机器宕机后,会自动处理这个异常,并将工作无缝地转移到其他备用机器上去,以来保证服务的高可用。
HA方式安装部署才是最常见的生产环境上的安装部署方式。Hadoop HA是Hadoop 2.x中新添加的特性,包括NameNode HA 和 ResourceManager HA。因为DataNode和NodeManager本身就是被设计为高可用的,所以不用对他们进行特殊的高可用处理。
1、配置时间服务器(NTP服务器)[直接在server3上配置]:
1)、检查ntp服务是否已经安装:sudo rpm -qa | grep ntp
2)、安装ntp:yum install -y ntp ntpdate
3)、配置NTP服务:vim /etc/ntp.conf
增加:
restrict 192.168.0.0 mask 255.155.155.0 nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 10
4)、启动服务:
--将ntp服务设为开机启动
chkconfig ntpd on
--启动ntp服务
service ntpd start
5)、配置客户端(server1、server2):
yum install -y ntp
crontab -e
添加
* * * 1 * /usr/sbin/ntpdate server3(1个月从server3同步一次时间)
参考:https://blog.csdn.net/hliq5399/article/details/78193113