KD-tree的原理以及构建与查询操作的python实现
前几天小组讨论会上展示了kd-tree(k-dimension tree),感觉这玩意儿还挺有用的,所以学习了一下它的原理,然后把其中的构建kd-tree以及对应的查询操作实现了一下,现在跟大家分享一下
首先说一下什么是kd-tree把
不过首先得说一下bst(二叉查找树),递归定义如下:如果左子树上的节点存储的数值都小于根节点中存储的数值,并且右子树上的节点存储的数值都大于根节点中存储的数值,那么这样的二叉树就是一颗二叉查找树
有了bst的概念,那么kd-tree就 容易理解多了,首先kd-tree的节点中存储的数值是一个k维的数据点,而bst的节点中存储的可以视为是1维的数据点,kd-tree与bst不同的地方在于进行分支决策的时候,还需要选择一个维度的值进行比较,选择哪个维度呢?每个节点还需要维护一个split变量,表示进行分支决策的时候,选择哪个维度的值进行比较,现在给出一个kd-tree节点的定义
class KD_node:
def __init__(self, point=None, split=None, LL = None, RR = None):
"""
point:数据点
split:划分域
LL, RR:节点的左儿子跟右儿子
"""
self.point = point
self.split = split
self.left = LL
self.right = RRpoint就代表节点存储的k维数据点,left,right分别代表指向左右儿子的指针,split代表划分维度,在节点进行划分之前,我们需要确定划分维度,那么怎么选择划分维度呢,这又要从kd-tree的用途开始说起了
kd-tree是一种对高维空间的数据点进行划分的特殊数据结构,主要应用就是高维空间的数据查找,如:范围搜索和K近邻(knn)搜索,范围搜索就是给定查询点和距离阈值,获取在阈值范围内的所有数据点;knn搜索就是给定查询点和搜索点的数目n,查找出到搜索点最近的n个点的数目;
以上这两种搜索如果通过传统方法来实现,那么最坏情况下可能会穷举 数据急中的所有点,这种方法的缺点就是完全没有利用到数据集中蕴藏的结构信息,当数据点很多时,搜索效率不高;
事实上,实际数据集中的点一般时呈簇状分布的,所以,很多点我们是完全没有必要遍历的,索引树的方法就是对将要搜索的点进行空间划分,空间划分可能会有重叠,也可能没有重叠,kd-tree就是划分空间没有重叠的索引树
这样说可能有一点乱,那我还是以“二分查找”作为引入吧
如果给你一组数据 9 1 4 7 2 5 0 3 8
让你查找8,如果你挨个查找,那么将会把数据集都遍历一遍,
如果你排一下序那现在数据集就变成了:0 1 2 3 4 5 6 7 8 9,其实我们进行了很多没有必要的查找,
如果我以5为分界点,那么数据点就被分为了 两个“簇” (0 1 2 3 4)和(6 7 8 9),如果我要查找8,我根本久没有必要进入第一个簇,直接进入第二个簇进行查找,经过2次操作之后,就可以找到8了
把二分查找中的数据点换成k维数据点,这样的划分就变成了我们刚才说的空间划分,所以在这里要搞清楚,空间划分就是把数据点分类,“挨得近”的数据点就在一个空间里面
好 现在回到刚才的划分维度的选择上,因为我要尽可能将相似的点放在一颗子树里面,所以kd-tree采取的思想就是计算所有数据点在每个维度上的数值的方差
然后方差最大的维度就作为当前节点的划分维度,这样做的原理其实就是:方差越大,说明这个维度上的数据波动越大,也就说明了他们就越不可能属于同一个空间,需要在这个维度上对点进行划分,这就是kd-tree节点选择划分维度的原理
先贴一张kd-tree的图
途中每个节点代表划分点,标示维黑体的维度就是节点的划分维度,可以看到对于任意节点来说,如果给定划分维度split, 它的左子树上的节点在split维度上的值一定比它在split维度上的值要小,右子树上的节点在split维度上的值一定相应要大,所以说kd-tree实际上就是bst在多维空间上的拓展
好,扯了那么多废话,举个例子来说一下kd-tree的构造
现在假设我有若干个二维空间的数据点(横向为x轴,纵向为y轴)

通过第一次方差的计算,我们发现x维度上的方差比较大,所以,我们先选x轴为划分维度,得到下面的点,黄色的点代表分割点,这里要说明一下,分割点(也就是节点存储的数据节点)一般取在分割维度上的值为中间值的点,下图就是选了x维度上的值为中值的点作为切割点
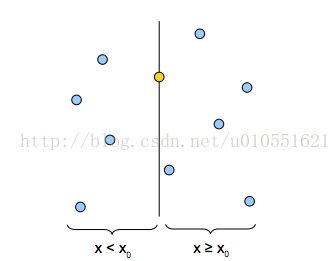
现在我们又对x

我们按照上面的方法,持续对空间中的点进行划分,直到每个空间中只有一个点,这样,一棵kd-tree就构成了
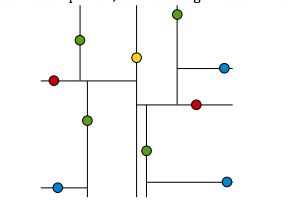
根据上面的介绍,黄色的节点就代表kd-tree的根节点,也就是第一个分割点;红色的点代表位于第二层上的节点,剩下的以此类推
好了,现在附上创建kd-tree的python代码
def createKDTree(root, data_list):
"""
root:当前树的根节点
data_list:数据点的集合(无序)
return:构造的KDTree的树根
"""
LEN = len(data_list)
if LEN == 0:
return
#数据点的维度
dimension = len(data_list[0])
#方差
max_var = 0
#最后选择的划分域
split = 0;
for i in range(dimension):
ll = []
for t in data_list:
ll.append(t[i])
var = computeVariance(ll)
if var > max_var:
max_var = var
split = i
#根据划分域的数据对数据点进行排序
data_list.sort(key=lambda x: x[split])
#选择下标为len / 2的点作为分割点
point = data_list[LEN / 2]
root = KD_node(point, split)
root.left = createKDTree(root.left, data_list[0:(LEN / 2)])
root.right = createKDTree(root.right, data_list[(LEN / 2 + 1):LEN])
return root
def computeVariance(arrayList):
"""
arrayList:存放的数据点
return:返回数据点的方差
"""
for ele in arrayList:
ele = float(ele)
LEN = len(arrayList)
array = numpy.array(arrayList)
sum1 = array.sum()
array2 = array * array
sum2 = array2.sum()
mean = sum1 / LEN
#D[X] = E[x^2] - (E[x])^2
variance = sum2 / LEN - mean**2
return variance说完了kd-tree的构建,现在再来说一下如何利用kd-tree进行最近邻的查找
基本的查找思路是这样的:
1.二叉查找:从根节点开始进行查找,直到叶子节点;在这个过程中,记录最短的距离,和对应的数据点;同时维护一个栈,用来存储经过的节点
2.回溯查找:通过计算查找点到分割平面的距离(这个距离比较的是分割维度上的值的差,并不是分割节点到分割平面上的距离,虽然两者的值是相等的)与当前最短距离进行比较,决定是否需要进入节点的相邻子空间进行查找,为什么需要这个判断呢,我举一个例子就大家可能就能明白了
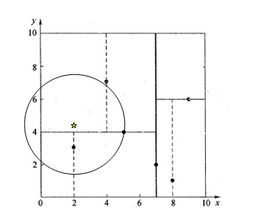
途中的黑点为kd-tree中的数据点,五角星为查询点,我们通过kd-tree的分支决策会将它分到坐上角的那部分空间,但并不是意味着它到那个空间中的点的距离最近
我们首先扫描到叶子节点,扫描的过程中记录的最近点为p(5,4),最短距离为d, 现在开始回溯,假设分割的维度为ss,其实回溯的过程就是确定是否有必要进入相邻子空间进行搜索,确定的依据就是当前点到最近点的距离d是否大于当前点到分割面(在二维空间中实际上就是一条线)的距离L,如果d < L,那么说明完全没有必要进入到另一个子空间进行搜索,直接继续向上一层回溯;如果有d > L,那么说明相邻子空间中可能有距查询点更近的点
python实现的代码如下:
def findNN(root, query):
"""
root:KDTree的树根
query:查询点
return:返回距离data最近的点NN,同时返回最短距离min_dist
"""
#初始化为root的节点
NN = root.point
min_dist = computeDist(query, NN)
nodeList = []
temp_root = root
##二分查找建立路径
while temp_root:
nodeList.append(temp_root)
dd = computeDist(query, temp_root.point)
if min_dist > dd:
NN = temp_root.point
min_dist = dd
#当前节点的划分域
ss = temp_root.split
if query[ss] <= temp_root.point[ss]:
temp_root = temp_root.left
else:
temp_root = temp_root.right
##回溯查找
while nodeList:
#使用list模拟栈,后进先出
back_point = nodeList.pop()
ss = back_point.split
print "back.point = ", back_point.point
##判断是否需要进入父亲节点的子空间进行搜索
if abs(query[ss] - back_point.point[ss]) < min_dist:
if query[ss] <= back_point.point[ss]:
temp_root = back_point.right
else:
temp_root = back_point.left
if temp_root:
nodeList.append(temp_root)
curDist = computeDist(query, temp_root.point)
if min_dist > curDist:
min_dist = curDist
NN = temp_root.point
return NN, min_dist
def computeDist(pt1, pt2):
"""
计算两个数据点的距离
return:pt1和pt2之间的距离
"""
sum = 0.0
for i in range(len(pt1)):
sum = sum + (pt1[i] - pt2[i]) * (pt1[i] - pt2[i])
return math.sqrt(sum)为了验证创建的树是否正确以及最后的距离度量是否正确,我分别使用了树的前序遍历和knn来对比运行的结果
def preorder(root):
"""
KDTree的前序遍历
"""
print root.point
if root.left:
preorder(root.left)
if root.right:
preorder(root.right)
def KNN(list, query):
min_dist = 9999.0
NN = list[0]
for pt in list:
dist = computeDist(query, pt)
if dist < min_dist:
NN = pt
min_dist = dist
return NN, min_dist代码写得比较急,而且测试的数据也比较简单,所以难免会有bug,欢迎大家积极给我指出来
参考文献:http://web.stanford.edu/class/cs106l/handouts/assignment-3-kdtree.pdf