线性回归、局部加权线性回归、岭回归、lasso及逐步线性回归
demo:传送门
引言
前面几篇博客,我们主要分享了一些分类算法。这一篇文章,我们将首次介绍回归算法即对连续性的数据做出预测。回归一词的来历由来已久。“回归”是由英国著名生物学家兼统计学家高尔顿(Francis Galton,1822~1911.生物学家达尔文的表弟)在研究人类遗传问题时提出来的。为了研究父代与子代身高的关系,高尔顿搜集了1078对父亲及其儿子的身高数据。他发现这些数据的散点图大致呈直线状态,也就是说,总的趋势是父亲的身高增加时,儿子的身高也倾向于增加。但是,高尔顿对试验数据进行了深入的分析,发现了一个很有趣的现象—回归效应。因为当父亲高于平均身高时,他们的儿子身高比他更高的概率要小于比他更矮的概率;父亲矮于平均身高时,他们的儿子身高比他更矮的概率要小于比他更高的概率。它反映了一个规律,即这两种身高父亲的儿子的身高,有向他们父辈的平均身高回归的趋势。对于这个一般结论的解释是:大自然具有一种约束力,使人类身高的分布相对稳定而不产生两极分化,这就是所谓的回归效应。
这里我们将详细介绍线性回归、局部加权线性回归,简单介绍岭回归、lasso回归及逐步线性回归。
线性回归
概念梳理
回归的目的就是预测数值型的目标值。最直接的办法是依据输入写出一个目标值的计算公式。假如你想要预测杭州西湖区二手房的价格,你可能会这么计算:
这就是所谓的回归方程(regression equation),其中 θ1,θ2 被称作回归系数, 求这些回归系数的过程就是回归。一旦有了这些回归系数,再给定输入,做预测就非常容易了。具体的做法就是回归系数乘以输入值,再将结果全部加在一起,就得到了预测值。说到回归一般都指线性回归。本次分享里面提到的回归与线性回归代表同一个意思。
回归系数求解
- 线性回归的概念,数学概率推导我们就不作进一步的详细阐述,具体看前面翻译的一篇博客:CS229 Lecture Note 1(监督学习、线性回归)。
现在我们有了要解决的问题了:如何从一大堆数据里求出回归方程呢?假定输入数据存放在矩阵 X 中,而回归系数存放在向量 W 中。那么对于给定的数据 X1 ,预测结果将会通过 Y1=XT1w 给出·。但是我们现在手里有一些 X 和对应的 Y ,怎样才能找到 W 呢?一个常用的方法就是找到使误差最小的 w 。
与逻辑回归类似,线性回归就是要求解使得平方误差最小的回归系数。这里平方误差可以写作:
用矩阵表示还可以写作 (y−Xw)T(y−Xw) 。对w求导,得到 X(Y−Xw) ,令其等于0,解出w如下:
w上方的小标记表示,这是当前可以估计出的w的最优解。
- Note1:
上述公式中包含 (XTX)−1 ,这是对矩阵的求逆运算,因此上述方程只在逆矩阵存在的时候适用。所以在实现代码的过程中,这个地方要加一个判断的。- Note2:
上述的最佳参数 w 的求解是统计学里的常见问题,除了矩阵方法外还有许多其他方法能求解:梯度下降,牛顿法。
实际实验
我们给出如下的散点图:

那么我们如何从上面这些散点图中,拟合出最佳直线或者换句话说如何求出回归系数 w 呢?很简单,只要应用公式求出回归系数即可。
ws = regression.standRegres(xArr,yArr)拟合的直线效果:
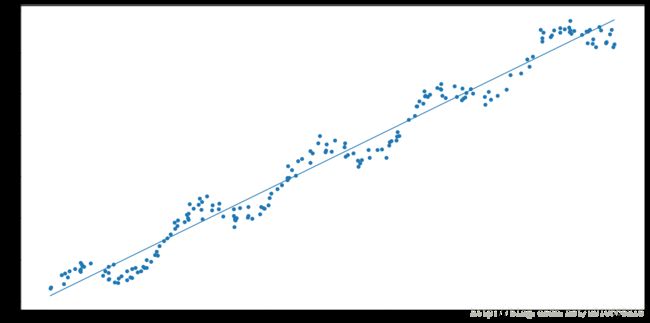
题外话:(相关系数)
前面我们应用的是普通线性回归算法,就是将数据看成是一条线性数据,并利用最佳拟合直线的方法来建模。但是从上图我们可以很容易看出来数据还存在一些其他的模式。那么如何才能利用这些模式呢?是不是有种方法能局部调整,从而使方法更优呢?接下来我们来介绍这种方法。
局部加权线性回归
概念梳理
线性回归的一个问题就是可能会出现欠拟合的现象,因为它求得是最小均方误差的无偏估计。很明显在欠拟合的情况下,模型是不能取得很好的预测效果的。所以有些方法就允许在估计中引入偏差,从而降低预测的均方误差。于是有人提出了一种局部加权线性回归(LWLR),在该算法中,我们给待预测点附近的每个点赋予一定的权重。求回归系数的方法和前面的方法一样,利用最小均方差来进行普通的回归。在预测时,这种方法就和我们前面分享的博客:KNN一样,每次预测均需要事先选取出对应的数据子集。这是为什么呢?很简单,因为这里我们需要给预测值附近的点附权重,没做一次预测就要给训练集附权重。
这种算法解出来的回归系数w的形式如下:
其中 w 是一个矩阵,用来给每个数据点赋予权重。
LWLR使用“核”(与支持向量机中的核类似)来对附近的点赋予更高的权重。最常用的核就是高斯核(绝对值及平方?),高斯核对应的权重如下:
实际实验
我们通过给高斯核函数的参数k附不同的值,从而对比拟合的效果如下所示:
k=1

k=0.01

k=0.003

很明显,局部加权线性回归可以得到比普通线性回归更好的效果,但是在选择核函数时要注意过拟合的问题。上图明显k=0.003时,过拟合了。局部加权线性回归因为每次预测必须在整个数据集上运行,这个会导致计算量的增加。如何减少计算量这是我们需要思考的问题。
到目前为止,我们介绍了两种最佳拟合直线的方法,其中局部线性回归比普通线性回归有更好的效果。接下来我们将介绍另外一种提高预测精度的方法,叫岭回归。
岭回归
在现实生活中,大部分的情况下都是样本点多于特征值的。但是如果数据的特征比样本点还多,此时是不能应用前面两种线性回归方法的,为什么呢?这是因为当数据的特征大于样本点时,输入数据矩阵为非满秩矩阵(列不满秩),非满秩矩阵在求逆会出现问题。故为了解决这个问题,统计学家引入了岭回归的方法。
核心思想就是在矩阵 XTX 上加一个 λI 从而使矩阵非奇异,其中矩阵是m*m的单位矩阵(矩阵X大小n*m)
岭回归最先用于处理特征数多于样本数的情况,现在也用于在估计中加入偏差,从而得到更好的估计。
回归系数的计算公式则如下:
岭回归最先用来处理特征数多于样本的情况,现在也用于在估计中加入偏差,从而得到更好的估计。这里通过引入 λ 来限制了所有的 w 的和,通过引入惩罚项,能够减少不重要的参数,这个技术在统计学中也叫做缩减(shrinkage)。这个方法的应用,与L2正则化很类似,大家可以参考我写的一篇调参博客: Xgboost参数调优的完整指南及实战。
lasso
lasso方法也是对回归系数做了增加约束,如下:
这种约束方式和L1正则化很类似。L1正则与L2正则的区别就是,当 λ 很小的时候,L1正则化下的某些系数会很快缩减到0。
前向逐步线性回归
前向逐步线性回归是为了解决lasso二次规划问题计算复杂而提出的一种简化算法。它属于一种贪心算法,即每一步都尽可能的减小误差。
前向逐步线性回归的工作原理是,一开始所有的权重都设为1,然后每一步所做的决策是对某个权重增加或减少一个很小的值。
总结
这次分享主要介绍了标准线性回归算法,然后引入局部平滑技术,来更好地拟合数据。接下来,我们有简要介绍了回归在“欠拟合”情况下的缩减技术:引入了“岭回归”(L2)、lasso回归(L1)方法。因为lasso回归的计算比较复杂,因此我们有简单提出了一种前向逐步线性回归的算法。本次分享介绍的这几种算法其实挺好用的。但是当预测值与特征值之间是非线性关系时,这种情况使用线性的模型就难以拟合了。就需要其他算法来支持。