看了中国大学慕课网上嵩天老师的课,里面有一个实战项目是爬取百度股票个股信息。今天自己试试看能不能爬下来。思路和嵩天老师一样:
1.从东方财富网上面获取股票代码,存进列表;
2.对股票代码列表内每个元素进行抽取,构建个股信息的url
3.解析个股信息。
4.将个股信息保存至本地。
东方财富网股票网址:http://quote.eastmoney.com/stocklist.html
百度股票:https://gupiao.baidu.com/stock/
1:从东方财富网上面获取股票代码,存进列表。
这里先构造一个获取网页源码的函数,方便后面解析个股信息时调用。
在这里推进大家一个好用的软件:postman,可以很方便地构造请求头部信息。
a.打开postman,选择get,这里有许多的选择,我也在摸索中:
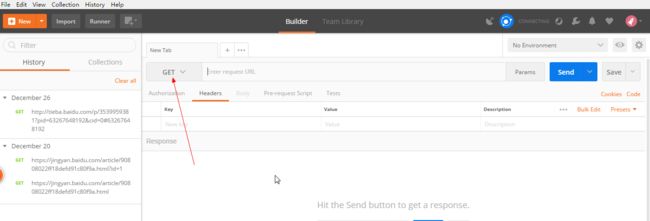
b.输入网址,点击右侧箭头处按钮:
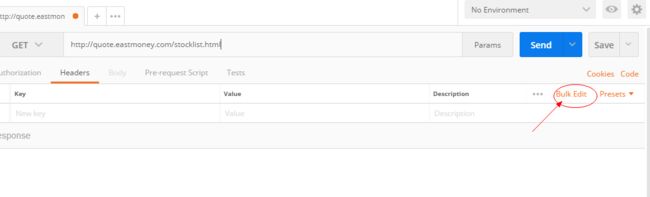
c.找到你浏览器对应的request header,复制到postman中:
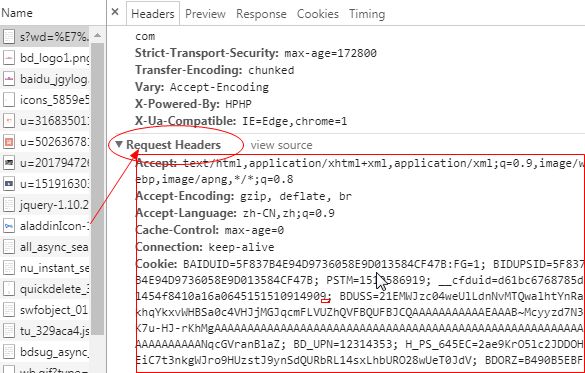
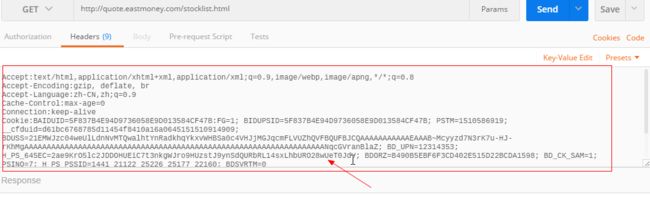
d.点击右侧key-value edit,变成下面这样子:
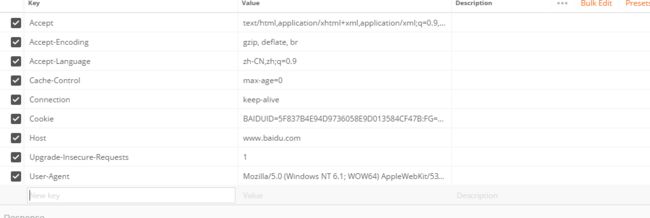
e.点击右侧code,选择python编码方式:
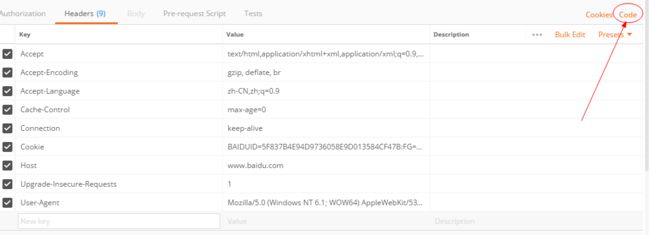
接下来就是复制代码啦,看到没有,hin标准~
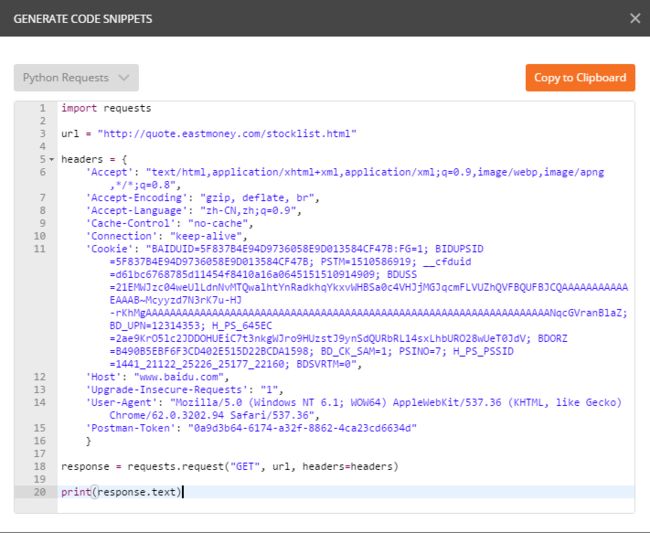
里面有些信息可以不要~这些信息的作用分别是什么我现在也搞不清楚,只知道cookies和UA, 要注意,如果你把全部的头部信息复制到到代码里的话,爬取过程经常会304,所以我只保留了UA。
接下来就简单了:
import re
from bs4 import BeautifulSoup
import requests
import traceback
from lxml import etree
def gethtml(url):
headers = {'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"}
response = requests.request("GET", url, headers=headers)
print(response.status_code)
response.encoding = 'utf-8'
html = response.text
return html
2.解析并获取股票列表:
def getstockslist(url, stockslist):
html = gethtml(url)
soup = BeautifulSoup(html, "html.parser")
node = soup.find("div", attrs={'id': 'quotesearch'})
for i in node.find_all('a'):
href = i.get('href')
info = re.findall(r's[hz]\d{6}', str(href))
for a in info:
stockslist.append(a)
print(stockslist)
这里用靓汤和正则,主要是股票的代号在href属性里面,xpath不是很好提取(我菜我承认--)
最后灵(lan)活(duo)的我先把解析个股数据和保存本地都放在main函数里了--
def main():
url = "http://quote.eastmoney.com/stocklist.html"
infourl = "https://gupiao.baidu.com/stock/"
slist = []
getstockslist(url, slist)
for stock in slist:
stockurl = infourl + stock + ".html"
print(stockurl)
r = gethtml(stockurl)
try:
if r == "":
continue
stockdict = {}
selector = etree.HTML(r)
stockdict = {}
nameinfo = selector.xpath('//a[@class="bets-name"]')[0]
name = nameinfo.xpath('string(.)').strip()
stockdict['股票名称:'] = name
print(name)
if selector.xpath('//div[@class="bets-content"]')[0]:
infos = selector.xpath('//div[@class="bets-content"]')[0]
keys = infos.xpath('./div/dl/dt')
for key in keys:
print(key)
vals = infos.xpath('./div/dl/dd')
for val in vals:
print(val)
print(stockdict)
else:
print("未找到相关数据,请检查是否有数据或者xpath解析是否有问题")
except:
traceback.print_exc()
要记录一下分析页面的过程,简直一把辛酸一把泪,我好菜啊。。。。。
一开始是在main函数调用getstockslist()方法时,把参数传错了,本来定义的时候是(url, list), 我却在调用时弄成(list, url), 还在这里纠结了很久为什么拼接不成url??
然后是用xpath解析个股信息,股票名字是有了,其他的信息每次都获取不到,明明在网页上用xpath helper是可以获得数据的,上网看博客,有筒子说是因为浏览器会自动把HTML代码补齐,而lxml不会,因此有些时候同一个xpath语句在网页上可以解析出数据,而在lxml里不行。给自己提个醒,以后用xpath不可以贪图方便就直接复制谷歌浏览器给出的xpath路径,出来混总是要还的。。。。。
再说上面的那个错误,解析不出来数据我就很纳闷,但是程序也没报错,几百个股票跑起来还是可以拿到名字,具体的信息那里就是空的,我xpath改了N遍,还是回到重头那里,确认自己的xpath 没写错的!!偶然间在程序跑起来的时间里我去喝水,回来后看到有些股票可以提取到信息,我往回翻看,前面的信息都只有名字,但是到了后面有开始看到有其他信息出现。我才幡然醒悟,尼玛,不是有些股票页面是没有我想提取的信息的吧?!!!随便点进去看一个,果然没有!写了一大堆文字,好累啊,先回去撸会代码~
更新:
大中午的没睡午觉,来继续代码优化完整:
# -*- coding: utf-8 -*-
import re
from bs4 import BeautifulSoup
import requests
import traceback
from lxml import etree
def gethtml(url):
headers = {'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"}
try:
response = requests.request("GET", url, headers=headers)
print("连接状态: " + response.status_code)
response.encoding = 'utf-8'
html = response.text
return html
except:
print("链接失败")
def getstockslist(url, stockslist):
html = gethtml(url)
soup = BeautifulSoup(html, "html.parser")
node = soup.find("div", attrs={'id': 'quotesearch'})
for i in node.find_all('a'):
href = i.get('href')
info = re.findall(r's[hz]\d{6}', str(href))
for a in info:
stockslist.append(a)
print(stockslist)
def main():
url = "http://quote.eastmoney.com/stocklist.html"
infourl = "https://gupiao.baidu.com/stock/"
slist = []
getstockslist(url, slist)
for stock in slist:
stockdict = {}
stockurl = infourl + stock + ".html"
stockdict["股票链接"] = stockurl
print("----------------------------华丽丽的分割线-----------------------------")
r = gethtml(stockurl)
try:
if r == "":
continue
selector = etree.HTML(r)
if selector.xpath('//a[@class="bets-name"]'):
nameinfo = selector.xpath('//a[@class="bets-name"]')[0]
name = nameinfo.xpath('string(.)').strip()
stockdict['股票名称:'] = name
else:
print("未找到股票名称")
continue
if selector.xpath('//div[@class="bets-content"]'):
infos = selector.xpath('//div[@class="bets-content"]')[0]
keys = infos.xpath('./div/dl/dt/text()')
vals = infos.xpath('./div/dl/dd/text()')
for i in range(0, len(keys)):
key = keys[i]
val = vals[i]
stockdict[key] = val
with open('stockinfos.txt', 'a', encoding='utf-8') as f:
f.write(str(stockdict) + '\n')
print("该股票抽取完成")
else:
print("未找到相关数据,请检查是否有数据或者xpath解析是否有问题")
continue
except:
traceback.print_exc()
main()
写给自己的话:
1.多练练代码封装,提高代码复用率(看起来会有逼格点)
2.学习数据库的使用啦,还有,想想办法,怎么把提取的信息保存的更好看。
3.学习多线程,多进程。
4.暂时只想到这么多