hadoop-hive本地和伪分布式模式的安装
前言:关于虚拟机安装hive,hadoop的资料林林总总,对于初学者很难甄别;
如下是按照官方doc,一步步经过实践的一种方法,思路比我搜到网上的帖子更清晰;
初学,难免有错误的地方,敬请指正。
一、虚拟机hadoop的安装
1.虚拟机安装linux-redhat操作系统,虚拟机网络类型设置为网桥模式,保证虚拟机可以访问Internet外网
2.安装jdk:
解压jdk文件(我的jdk是jdk1.8.0_05)至某个目录:如/software下面
#add by clark,20160525
export JAVA_HOME=/software/jdk1.8.0_05
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
3.下载hadoop-2.7.3
[1]安装wget
Yum install wget
| 注:yum的配置:
[1]将redhat的安装ISO镜像文件挂载或者复制到/iso目录下面 [2]配置yum源,创建ios.repo文件 [root@m01 yum.repos.d]# vi /etc/yum.repos.d/ios.repo [ios] name=ios baseurl=file:///ios enabled=1 gpgcheck=0 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release |
[2]下载hadoop-2.7.3
wget http://mirrors.cnnic.cn/apache/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
[3]解压安装包
tar -zxvf hadoop-2.7.3.tar.gz 解压到当前目录或者其他目录下面
[4]配置环境变量
echo ‘export HADOOP_HOME=/software/hadoop-2.7.3’ >>/etc/profile
echo ‘export PATH=$PATH:$HADOOP_HOME/bin’>>/etc/profile
4.使用本地模式
[1]参考:http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/SingleCluster.html
[2]测试:
| [root@m01 hadoop-2.7.3]# mkdir input [root@m01 hadoop-2.7.3]# cp etc/hadoop/*.xml input [root@m01 hadoop-2.7.3]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output 'dfs[a-z.]+' [root@m01 hadoop-2.7.3]# cat output/* 1 dfsadmin |
5.使用伪分布式模式
[1]修改etc/hadoop/core-site.xml
| [root@m01 hadoop-2.7.3]# tail -n 6 etc/hadoop/core-site.xml
|
[2]修改 etc/hadoop/hdfs-site.xml
| [root@m01 hadoop-2.7.3]# tail -n 6 etc/hadoop/hdfs-site.xml
|
[3]修改 etc/hadoop/hadoop-env.sh 增加JAVA_HOME
| [root@m01 hadoop-2.7.3]# find -name hadoop-env.sh ./etc/hadoop/hadoop-env.sh [root@m01 hadoop-2.7.3]# echo "export JAVA_HOME=/software/jdk1.8.0_05" >>etc/hadoop/hadoop-env.sh 注: 如果不配置JAVA_HOME,则执行sbin/start-dfs.sh报错 Starting namenodes on [localhost] localhost: Error: JAVA_HOME is not set and could not be found. localhost: Error: JAVA_HOME is not set and could not be found. |
[4]配置本身的ssh互信
| [root@m01 hadoop-2.7.3]# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa Generating public/private rsa key pair. Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: 82:c9:b0:f9:3a:0b:e0:4a:ee:e8:ea:df:e4:ee:3d:c4 root@m01 The key's randomart image is: +--[ RSA 2048]----+ | | | | | . | | = o | |. o + o S | |o . E | |.o ... | |=...+ .. | |O=++o= .. | +-----------------+ [root@m01 hadoop-2.7.3]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys [root@m01 hadoop-2.7.3]# chmod 0600 ~/.ssh/authorized_keys [root@m01 hadoop-2.7.3]# ssh localhost Last login: Sat Oct 15 22:48:35 2016 from localhost |
[5]namenode format
| [root@m01 hadoop-2.7.3]# hdfs namenode -format 16/10/15 22:52:48 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = m01/192.168.1.6 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.7.3 |
[6]启动hdfs
| [root@m01 hadoop-2.7.3]# sbin/start-dfs.sh Starting namenodes on [localhost] localhost: starting namenode, logging to /software/hadoop-2.7.3/logs/hadoop-root-namenode-m01.out localhost: starting datanode, logging to /software/hadoop-2.7.3/logs/hadoop-root-datanode-m01.out ./start-dfs.sh Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /software/hadoop-2.7.3/logs/hadoop-root-secondarynamenode-m01.out
注:事先修改etc/hadoop/hadoop-env.sh 配置JAVA_HOME环境变量 |
6.网络浏览器查看hdfs运行情况:
http://ip:50070
截图如下:
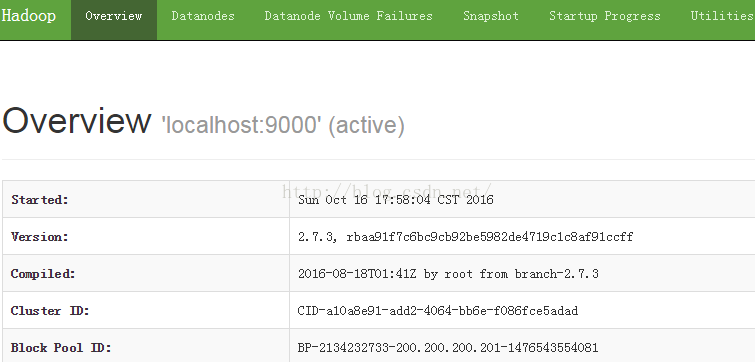
二、虚拟机HIVE的安装
1.首先在虚拟机上安装部署好hadoop
2.下载hive:
http://mirrors.cnnic.cn/apache/hive/hive-2.1.0/apache-hive-2.1.0-bin.tar.gz
| [root@m01 software]# wget http://mirrors.cnnic.cn/apache/hive/hive-2.1.0/apache-hive-2.1.0-bin.tar.gz --2016-10-15 23:24:29-- http://mirrors.cnnic.cn/apache/hive/hive-2.1.0/apache-hive-2.1.0-bin.tar.gz Resolving mirrors.cnnic.cn... 218.241.113.17 Connecting to mirrors.cnnic.cn|218.241.113.17|:80... connected. HTTP request sent, awaiting response... 200 OK Length: 149599799 (143M) [application/octet-stream] Saving to: “apache-hive-2.1.0-bin.tar.gz”
100%[======================================================================================================================>] 149,599,799 2.97M/s in 50s
2016-10-15 23:25:19 (2.87 MB/s) - “apache-hive-2.1.0-bin.tar.gz” saved [149599799/149599799] |
3.解压(假设在/software目录下面)
[root@m01 software]# tar -zxvf apache-hive-2.1.0-bin.tar.gz
4.配置环境变量
[root@m01 apache-hive-2.1.0-bin]# echo "export HIVE_HOME=`pwd`" >> /etc/profile
[root@m01 apache-hive-2.1.0-bin]# echo ‘export PATH=$HIVE_HOME/bin:$PATH’>>/etc/profile
[root@m01 apache-hive-2.1.0-bin]# source /etc/profile
5.创建HIVE的工作目录
| [root@m01 software]# hadoop fs -mkdir /tmp [root@m01 software]# hadoop fs -mkdir /user/hive/warehouse mkdir: `/user/hive/warehouse': No such file or directory [root@m01 software]# hadoop fs -mkdir /user mkdir: `/user': File exists [root@m01 software]# hadoop fs -mkdir /user/hive [root@m01 software]# hadoop fs -mkdir /user/hive/warehouse [root@m01 software]# hadoop fs -chmod g+w /tmp [root@m01 software]# hadoop fs -chmod g+w /user/hive/warehouse |
6.设置hive metadata
注:
Starting from Hive 2.1, we need to run the schematool command below as an initialization step. For example, we can use "derby" as db type.
$ $HIVE_HOME/bin/schematool -dbType
默认使用derby数据库作为元数据数据库
| [root@m01 lib]# schematool -dbType derby -initSchema which:no hbase in (/software/apache-hive-2.1.0-bin/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/software/jdk1.8.0_05/bin:/software/jdk1.8.0_05/jre/bin:/root/bin:/software/jdk1.8.0_05/bin:/software/jdk1.8.0_05/jre/bin:/software/hadoop-2.7.3/bin:/software/jdk1.8.0_05/bin:/software/jdk1.8.0_05/jre/bin:/software/hadoop-2.7.3/bin) SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/software/apache-hive-2.1.0-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/software/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver Metastore connection User: APP Starting metastore schema initialization to 2.1.0 Initialization script hive-schema-2.1.0.derby.sql Initialization script completed schemaTool completed |
7.开始使用hive
| [root@m01 lib]# hive which: no hbase in (/software/apache-hive-2.1.0-bin/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/software/jdk1.8.0_05/bin:/software/jdk1.8.0_05/jre/bin:/root/bin:/software/jdk1.8.0_05/bin:/software/jdk1.8.0_05/jre/bin:/software/hadoop-2.7.3/bin:/software/jdk1.8.0_05/bin:/software/jdk1.8.0_05/jre/bin:/software/hadoop-2.7.3/bin) SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/software/apache-hive-2.1.0-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/software/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/software/apache-hive-2.1.0-bin/lib/hive-common-2.1.0.jar!/hive-log4j2.properties Async: true Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. hive> |