spark部署standalone集群
spark官网文档:http://spark.apache.org/docs/latest/spark-standalone.html
环境
- linux centos
- spark-1.3.1-bin-hadoop2.6
- jdk1.7
- python2.6
可以用tar.gz这种离线包解压后再配置环境变量,修改/etc/profile或者~/.bashrc文件并使用source命令使之生效。(本次仅仅是测试standalone模式集群,不配置貌似也没事)
步骤
1.准备master主机和worker分机
- cluster1机器:10.35.20.238 启动master、worker和-application
- cluster2机器:10.35.57.10 启动worker(本机是运行于windows上的linux虚拟机,用NAT网络地址转换了,实际IP是10.0.2.15)
确保这两台机器互相之间可以联网,局域网和广域网均可。
2.启动master
在cluster1机器上,切换到spark安装目录,进入sbin目录
[root@localhost spark-1.3.1-bin-hadoop2.6]#cd sbin
该目录下有很多用于脚本用于启动或者停止集群节点。此处启动master
[root@localhost sbin]# ./start-master.sh
出现如下提示,部署成功
starting org.apache.spark.deploy.master.Master, logging to /opt/spark-1.3.1-bin-hadoop2.6/sbin/../logs/spark-root-org.apache.spark.deploy.master.Master-1-BEJL-SCTSRCH14B.out
log打印到了制定文件夹,可以查看输出信息。
Spark Command: /usr/java/jdk1.7.0_21//bin/java -cp /opt/spark-1.3.1-bin-hadoop2.6/sbin/../conf:/opt/spark-1.3.1-bin-hadoop2.6/lib/spark-assembly-1.3.1-hadoop2.6.0.jar:/opt/spark-1.3.1-bin-hadoop2.6/lib/datanucleus-api-jdo-3.2.6.jar:/opt/spark-1.3.1-bin-hadoop2.6/lib/datanucleus-rdbms-3.2.9.jar:/opt/spark-1.3.1-bin-hadoop2.6/lib/datanucleus-core-3.2.10.jar -XX:MaxPermSize=128m -Dspark.akka.logLifecycleEvents=true -Xms512m -Xmx512m org.apache.spark.deploy.master.Master --ip BEJL-SCTSRCH14B --port 7077 --webui-port 8080
========================================
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/05/06 04:46:30 INFO Master: Registered signal handlers for [TERM, HUP, INT]
15/05/06 04:46:31 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/05/06 04:46:31 INFO SecurityManager: Changing view acls to: root
15/05/06 04:46:31 INFO SecurityManager: Changing modify acls to: root
15/05/06 04:46:31 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
15/05/06 04:46:31 INFO Slf4jLogger: Slf4jLogger started
15/05/06 04:46:31 INFO Remoting: Starting remoting
15/05/06 04:46:31 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkMaster@BEJL-SCTSRCH14B:7077]
15/05/06 04:46:31 INFO Remoting: Remoting now listens on addresses: [akka.tcp://sparkMaster@BEJL-SCTSRCH14B:7077]
15/05/06 04:46:31 INFO Utils: Successfully started service 'sparkMaster' on port 7077.
15/05/06 04:46:32 INFO Server: jetty-8.y.z-SNAPSHOT
15/05/06 04:46:32 INFO AbstractConnector: Started SelectChannelConnector@BEJL-SCTSRCH14B:6066
15/05/06 04:46:32 INFO Utils: Successfully started service on port 6066.
15/05/06 04:46:32 INFO StandaloneRestServer: Started REST server for submitting applications on port 6066
15/05/06 04:46:32 INFO Master: Starting Spark master at spark://BEJL-SCTSRCH14B:7077
15/05/06 04:46:32 INFO Master: Running Spark version 1.3.1
15/05/06 04:46:32 INFO Server: jetty-8.y.z-SNAPSHOT
15/05/06 04:46:32 INFO AbstractConnector: Started SelectChannelConnector@0.0.0.0:8080
15/05/06 04:46:32 INFO Utils: Successfully started service 'MasterUI' on port 8080.
15/05/06 04:46:32 INFO MasterWebUI: Started MasterWebUI at http://BEJL-SCTSRCH14B:8080
15/05/06 04:46:32 INFO Master: I have been elected leader! New state: ALIVE成功启动了master,日志显示该master的URL为spark://BEJL-SCTSRCH14B:7077,对应的webUI的地址:端口是http://BEJL-SCTSRCH14B:8080,我们可以直接用任何一台主机的浏览器查看这个web界面,输入http://10.35.20.238:8080,注意如果用主机地址的话要改hosts文件做ip和主机名的映射,所以这里直接用http://IP:port的形式访问。

可以看到web页面中显示,当前master的状态,还没有任何worker节点,也没有运行的任务。
3.连接worker
在启动之前要做意见很重要的事:改hosts文件
在cluster2机器上,/etc/hosts文件里面添加一行
10.35.20.238 BEJL-SCTSRCH14B
然后在cluster2机器上,同样切换到spark安装目录下
[root@localhost spark-1.3.1-bin-hadoop2.6]# ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://BEJL-SCTSRCH14B:7077
(此处的主机名就是master的主机名并且已经在hosts文件里面做了ip映射,此处不可以用IP地址)
terminal里出现如下信息则连接正常。
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/05/06 12:14:30 INFO Worker: Registered signal handlers for [TERM, HUP, INT]
15/05/06 12:14:30 WARN Utils: Your hostname, localhost resolves to a loopback address: 127.0.0.1; using 10.0.2.15 instead (on interface eth0)
15/05/06 12:14:30 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
15/05/06 12:14:31 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/05/06 12:14:32 INFO SecurityManager: Changing view acls to: root
15/05/06 12:14:32 INFO SecurityManager: Changing modify acls to: root
15/05/06 12:14:32 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
15/05/06 12:14:33 INFO Slf4jLogger: Slf4jLogger started
15/05/06 12:14:33 INFO Remoting: Starting remoting
15/05/06 12:14:33 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkWorker@10.0.2.15:54446]
15/05/06 12:14:33 INFO Remoting: Remoting now listens on addresses: [akka.tcp://sparkWorker@10.0.2.15:54446]
15/05/06 12:14:33 INFO Utils: Successfully started service 'sparkWorker' on port 54446.
15/05/06 12:14:33 INFO Worker: Starting Spark worker 10.0.2.15:54446 with 1 cores, 722.0 MB RAM
15/05/06 12:14:33 INFO Worker: Running Spark version 1.3.1
15/05/06 12:14:33 INFO Worker: Spark home: /opt/spark-1.3.1-bin-hadoop2.6
15/05/06 12:14:34 INFO Server: jetty-8.y.z-SNAPSHOT
15/05/06 12:14:34 INFO AbstractConnector: Started SelectChannelConnector@0.0.0.0:8081
15/05/06 12:14:34 INFO Utils: Successfully started service 'WorkerUI' on port 8081.
15/05/06 12:14:34 INFO WorkerWebUI: Started WorkerWebUI at http://10.0.2.15:8081
15/05/06 12:14:34 INFO Worker: Connecting to master akka.tcp://sparkMaster@BEJL-SCTSRCH14B:7077/user/Master...
15/05/06 12:14:35 INFO Worker: Successfully registered with master spark://BEJL-SCTSRCH14B:7077
同理,在cluster1的机器上还可以启动worker节点。
此时查看master的webui发现多了两个worker节点
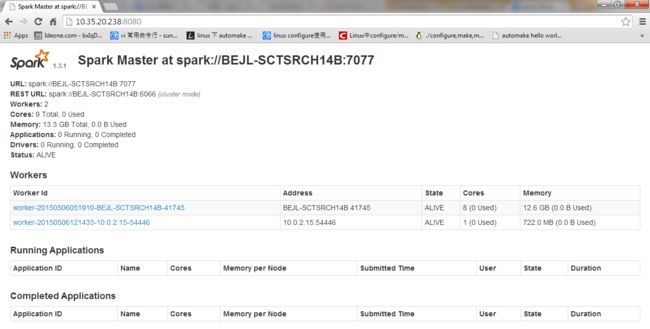
至此,standalone模式的集群部署完毕。
如果需要停掉这个集群,在master所在的主机里运行sbin目录下的stop-master.sh就可以了。
应用测试
1.集成shell环境测试
在master所在的主机里,切换到spark的bin目录
[root@localhost spark-1.3.1-bin-hadoop2.6]#./pyspark --master spark://BEJL-SCTSRCH14B:7077进入运行在集群上的spark的python集成调试环境。
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 1.3.1
/_/
Using Python version 2.7.6 (default, Dec 3 2014 09:12:42)
SparkContext available as sc, HiveContext available as sqlContext.
>>> 15/05/06 07:11:18 INFO SparkDeploySchedulerBackend: Registered executor: Actor[akka.tcp://sparkExecutor@BEJL-SCTSRCH14B:40308/user/Executor#2142464266] with ID 0
15/05/06 07:11:18 INFO BlockManagerMasterActor: Registering block manager BEJL-SCTSRCH14B:57537 with 265.0 MB RAM, BlockManagerId(0, BEJL-SCTSRCH14B, 57537)
15/05/06 07:11:21 INFO SparkDeploySchedulerBackend: Registered executor: Actor[akka.tcp://[email protected]:44494/user/Executor#2004585778] with ID 1
15/05/06 07:11:22 INFO BlockManagerMasterActor: Registering block manager 10.0.2.15:53011 with 267.3 MB RAM, BlockManagerId(1, 10.0.2.15, 53011)
下达任务,此处以统计文本行数为例:
>>> textFile=sc.textFile("../README.md")
15/05/06 14:51:04 INFO AppClient$ClientActor: Executor updated: app-20150506075245-0001/0 is now EXITED (Command exited with code 1)
15/05/06 14:51:04 INFO SparkDeploySchedulerBackend: Executor app-20150506075245-0001/0 removed: Command exited with code 1
15/05/06 14:51:04 ERROR SparkDeploySchedulerBackend: Asked to remove non-existent executor 0
15/05/06 14:51:04 INFO AppClient$ClientActor: Executor added: app-20150506075245-0001/2 on worker-20150506074818-BEJL-SCTSRCH14B-55279 (BEJL-SCTSRCH14B:55279) with 8 cores
15/05/06 14:51:04 INFO SparkDeploySchedulerBackend: Granted executor ID app-20150506075245-0001/2 on hostPort BEJL-SCTSRCH14B:55279 with 8 cores, 512.0 MB RAM
15/05/06 14:51:04 INFO AppClient$ClientActor: Executor updated: app-20150506075245-0001/2 is now LOADING
15/05/06 14:51:04 INFO AppClient$ClientActor: Executor updated: app-20150506075245-0001/2 is now RUNNING
15/05/06 14:51:04 INFO MemoryStore: ensureFreeSpace(182921) called with curMem=0, maxMem=280248975
15/05/06 14:51:04 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 178.6 KB, free 267.1 MB)
15/05/06 14:51:04 INFO MemoryStore: ensureFreeSpace(25432) called with curMem=182921, maxMem=280248975
15/05/06 14:51:04 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 24.8 KB, free 267.1 MB)
15/05/06 14:51:04 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 10.0.2.15:42206 (size: 24.8 KB, free: 267.2 MB)
15/05/06 14:51:04 INFO BlockManagerMaster: Updated info of block broadcast_0_piece0
15/05/06 14:51:04 INFO SparkContext: Created broadcast 0 from textFile at NativeMethodAccessorImpl.java:-2
>>> textFile.count()
15/05/06 14:51:11 INFO FileInputFormat: Total input paths to process : 1
15/05/06 14:51:11 INFO SparkContext: Starting job: count at :1
15/05/06 14:51:11 INFO DAGScheduler: Got job 0 (count at :1) with 2 output partitions (allowLocal=false)
15/05/06 14:51:11 INFO DAGScheduler: Final stage: Stage 0(count at :1)
15/05/06 14:51:11 INFO DAGScheduler: Parents of final stage: List()
15/05/06 14:51:11 INFO DAGScheduler: Missing parents: List()
15/05/06 14:51:11 INFO DAGScheduler: Submitting Stage 0 (PythonRDD[2] at count at :1), which has no missing parents
15/05/06 14:51:11 INFO MemoryStore: ensureFreeSpace(5568) called with curMem=208353, maxMem=280248975
15/05/06 14:51:11 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 5.4 KB, free 267.1 MB)
15/05/06 14:51:11 INFO MemoryStore: ensureFreeSpace(4089) called with curMem=213921, maxMem=280248975
15/05/06 14:51:11 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 4.0 KB, free 267.1 MB)
15/05/06 14:51:11 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 10.0.2.15:42206 (size: 4.0 KB, free: 267.2 MB)
15/05/06 14:51:11 INFO BlockManagerMaster: Updated info of block broadcast_1_piece0
15/05/06 14:51:11 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:839
15/05/06 14:51:11 INFO DAGScheduler: Submitting 2 missing tasks from Stage 0 (PythonRDD[2] at count at :1)
15/05/06 14:51:11 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
15/05/06 14:51:11 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, 10.0.2.15, PROCESS_LOCAL, 1309 bytes)
15/05/06 14:51:12 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 10.0.2.15:36887 (size: 4.0 KB, free: 267.3 MB)
15/05/06 14:51:14 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 10.0.2.15:36887 (size: 24.8 KB, free: 267.2 MB)
15/05/06 14:51:15 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, 10.0.2.15, PROCESS_LOCAL, 1309 bytes)
15/05/06 14:51:15 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 4445 ms on 10.0.2.15 (1/2)
15/05/06 14:51:16 INFO DAGScheduler: Stage 0 (count at :1) finished in 5.151 s
15/05/06 14:51:16 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 834 ms on 10.0.2.15 (2/2)
15/05/06 14:51:16 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
15/05/06 14:51:16 INFO DAGScheduler: Job 0 finished: count at :1, took 5.335692 s
98
可以在master的web界面里面看到任务执行情况

也可以在worker的web界面里面看单个worker的情况
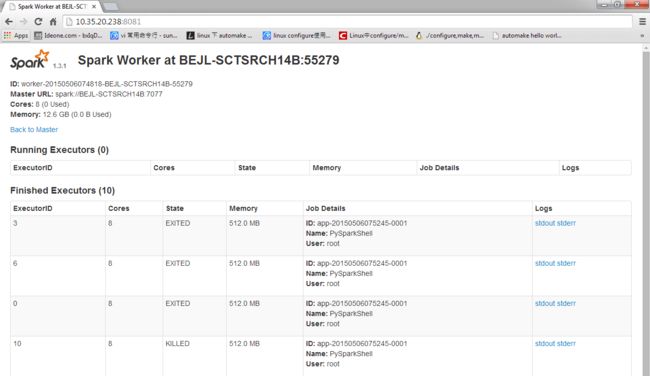
2.提交application测试
在任意一个master机器或者worker机器,切换到spark的bin目录下
新建一个python文件
./spark-submit --master spark://10.35.20.238:7077 simpleApp.py其中python文件为
"""SimpleApp.py"""
#count the 'a' and 'b' in README.md file
from pyspark import SparkContext
logFile = "../README.md" # Should be some file on your system
sc = SparkContext("local", "Simple App")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print "Lines with a: %i, lines with b: %i" % (numAs, numBs)执行结果
[root@localhost bin]# ./spark-submit --master spark://10.35.20.238:7077 simpleApp.py
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/05/06 15:00:55 INFO SparkContext: Running Spark version 1.3.1
15/05/06 15:00:55 WARN Utils: Your hostname, localhost resolves to a loopback address: 127.0.0.1; using 10.0.2.15 instead (on interface eth0)
15/05/06 15:00:55 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
15/05/06 15:00:56 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/05/06 15:00:56 INFO SecurityManager: Changing view acls to: root
15/05/06 15:00:56 INFO SecurityManager: Changing modify acls to: root
15/05/06 15:00:56 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
15/05/06 15:00:57 INFO Slf4jLogger: Slf4jLogger started
15/05/06 15:00:57 INFO Remoting: Starting remoting
15/05/06 15:00:58 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@10.0.2.15:37369]
15/05/06 15:00:58 INFO Utils: Successfully started service 'sparkDriver' on port 37369.
15/05/06 15:00:58 INFO SparkEnv: Registering MapOutputTracker
15/05/06 15:00:58 INFO SparkEnv: Registering BlockManagerMaster
15/05/06 15:00:58 INFO DiskBlockManager: Created local directory at /tmp/spark-9c9e78c2-c830-4144-a693-da4766fe85c4/blockmgr-859a9f63-dfca-4fd3-9729-00583951fd2e
15/05/06 15:00:58 INFO MemoryStore: MemoryStore started with capacity 267.3 MB
15/05/06 15:00:58 INFO HttpFileServer: HTTP File server directory is /tmp/spark-327ddcd4-3580-4afa-9788-a68adce50321/httpd-247ee4a8-38fe-4312-ad9a-9f2abb81cb62
15/05/06 15:00:58 INFO HttpServer: Starting HTTP Server
15/05/06 15:00:58 INFO Server: jetty-8.y.z-SNAPSHOT
15/05/06 15:00:58 INFO AbstractConnector: Started SocketConnector@0.0.0.0:56614
15/05/06 15:00:58 INFO Utils: Successfully started service 'HTTP file server' on port 56614.
15/05/06 15:00:58 INFO SparkEnv: Registering OutputCommitCoordinator
15/05/06 15:00:59 INFO Server: jetty-8.y.z-SNAPSHOT
15/05/06 15:00:59 INFO AbstractConnector: Started SelectChannelConnector@0.0.0.0:4040
15/05/06 15:00:59 INFO Utils: Successfully started service 'SparkUI' on port 4040.
15/05/06 15:00:59 INFO SparkUI: Started SparkUI at http://10.0.2.15:4040
15/05/06 15:01:00 INFO Utils: Copying /opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py to /tmp/spark-d7776b2b-7e51-416a-8775-75e6dd402ebf/userFiles-312cdc31-f56f-4a43-b904-e3a9630666a9/simpleApp.py
15/05/06 15:01:00 INFO SparkContext: Added file file:/opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py at file:/opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py with timestamp 1430895660185
15/05/06 15:01:00 INFO Executor: Starting executor ID on host localhost
15/05/06 15:01:00 INFO AkkaUtils: Connecting to HeartbeatReceiver: akka.tcp://sparkDriver@10.0.2.15:37369/user/HeartbeatReceiver
15/05/06 15:01:01 INFO NettyBlockTransferService: Server created on 43240
15/05/06 15:01:01 INFO BlockManagerMaster: Trying to register BlockManager
15/05/06 15:01:01 INFO BlockManagerMasterActor: Registering block manager localhost:43240 with 267.3 MB RAM, BlockManagerId(, localhost, 43240)
15/05/06 15:01:01 INFO BlockManagerMaster: Registered BlockManager
15/05/06 15:01:02 INFO MemoryStore: ensureFreeSpace(255188) called with curMem=0, maxMem=280248975
15/05/06 15:01:02 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 249.2 KB, free 267.0 MB)
15/05/06 15:01:02 INFO MemoryStore: ensureFreeSpace(36168) called with curMem=255188, maxMem=280248975
15/05/06 15:01:02 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 35.3 KB, free 267.0 MB)
15/05/06 15:01:02 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:43240 (size: 35.3 KB, free: 267.2 MB)
15/05/06 15:01:02 INFO BlockManagerMaster: Updated info of block broadcast_0_piece0
15/05/06 15:01:02 INFO SparkContext: Created broadcast 0 from textFile at NativeMethodAccessorImpl.java:-2
15/05/06 15:01:02 INFO FileInputFormat: Total input paths to process : 1
15/05/06 15:01:02 INFO SparkContext: Starting job: count at /opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py:8
15/05/06 15:01:03 INFO DAGScheduler: Got job 0 (count at /opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py:8) with 1 output partitions (allowLocal=false)
15/05/06 15:01:03 INFO DAGScheduler: Final stage: Stage 0(count at /opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py:8)
15/05/06 15:01:03 INFO DAGScheduler: Parents of final stage: List()
15/05/06 15:01:03 INFO DAGScheduler: Missing parents: List()
15/05/06 15:01:03 INFO DAGScheduler: Submitting Stage 0 (PythonRDD[2] at count at /opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py:8), which has no missing parents
15/05/06 15:01:03 INFO MemoryStore: ensureFreeSpace(5992) called with curMem=291356, maxMem=280248975
15/05/06 15:01:03 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 5.9 KB, free 267.0 MB)
15/05/06 15:01:03 INFO MemoryStore: ensureFreeSpace(4422) called with curMem=297348, maxMem=280248975
15/05/06 15:01:03 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 4.3 KB, free 267.0 MB)
15/05/06 15:01:03 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:43240 (size: 4.3 KB, free: 267.2 MB)
15/05/06 15:01:03 INFO BlockManagerMaster: Updated info of block broadcast_1_piece0
15/05/06 15:01:03 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:839
15/05/06 15:01:03 INFO DAGScheduler: Submitting 1 missing tasks from Stage 0 (PythonRDD[2] at count at /opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py:8)
15/05/06 15:01:03 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
15/05/06 15:01:03 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, PROCESS_LOCAL, 1371 bytes)
15/05/06 15:01:03 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
15/05/06 15:01:03 INFO Executor: Fetching file:/opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py with timestamp 1430895660185
15/05/06 15:01:03 INFO Utils: /opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py has been previously copied to /tmp/spark-d7776b2b-7e51-416a-8775-75e6dd402ebf/userFiles-312cdc31-f56f-4a43-b904-e3a9630666a9/simpleApp.py
15/05/06 15:01:04 INFO CacheManager: Partition rdd_1_0 not found, computing it
15/05/06 15:01:04 INFO HadoopRDD: Input split: file:/opt/spark-1.3.1-bin-hadoop2.6/README.md:0+3629
15/05/06 15:01:04 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
15/05/06 15:01:04 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
15/05/06 15:01:04 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
15/05/06 15:01:04 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
15/05/06 15:01:04 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
15/05/06 15:01:04 INFO MemoryStore: ensureFreeSpace(3021) called with curMem=301770, maxMem=280248975
15/05/06 15:01:04 INFO MemoryStore: Block rdd_1_0 stored as bytes in memory (estimated size 3.0 KB, free 267.0 MB)
15/05/06 15:01:04 INFO BlockManagerInfo: Added rdd_1_0 in memory on localhost:43240 (size: 3.0 KB, free: 267.2 MB)
15/05/06 15:01:04 INFO BlockManagerMaster: Updated info of block rdd_1_0
15/05/06 15:01:05 INFO PythonRDD: Times: total = 1596, boot = 1227, init = 364, finish = 5
15/05/06 15:01:05 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2439 bytes result sent to driver
15/05/06 15:01:05 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 2029 ms on localhost (1/1)
15/05/06 15:01:05 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
15/05/06 15:01:05 INFO DAGScheduler: Stage 0 (count at /opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py:8) finished in 2.096 s
15/05/06 15:01:05 INFO DAGScheduler: Job 0 finished: count at /opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py:8, took 2.255150 s
15/05/06 15:01:05 INFO SparkContext: Starting job: count at /opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py:9
15/05/06 15:01:05 INFO DAGScheduler: Got job 1 (count at /opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py:9) with 1 output partitions (allowLocal=false)
15/05/06 15:01:05 INFO DAGScheduler: Final stage: Stage 1(count at /opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py:9)
15/05/06 15:01:05 INFO DAGScheduler: Parents of final stage: List()
15/05/06 15:01:05 INFO DAGScheduler: Missing parents: List()
15/05/06 15:01:05 INFO DAGScheduler: Submitting Stage 1 (PythonRDD[3] at count at /opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py:9), which has no missing parents
15/05/06 15:01:05 INFO MemoryStore: ensureFreeSpace(5992) called with curMem=304791, maxMem=280248975
15/05/06 15:01:05 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 5.9 KB, free 267.0 MB)
15/05/06 15:01:05 INFO MemoryStore: ensureFreeSpace(4422) called with curMem=310783, maxMem=280248975
15/05/06 15:01:05 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 4.3 KB, free 267.0 MB)
15/05/06 15:01:05 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost:43240 (size: 4.3 KB, free: 267.2 MB)
15/05/06 15:01:05 INFO BlockManagerMaster: Updated info of block broadcast_2_piece0
15/05/06 15:01:05 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:839
15/05/06 15:01:05 INFO DAGScheduler: Submitting 1 missing tasks from Stage 1 (PythonRDD[3] at count at /opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py:9)
15/05/06 15:01:05 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks
15/05/06 15:01:05 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, PROCESS_LOCAL, 1371 bytes)
15/05/06 15:01:05 INFO Executor: Running task 0.0 in stage 1.0 (TID 1)
15/05/06 15:01:05 INFO BlockManager: Found block rdd_1_0 locally
15/05/06 15:01:05 INFO PythonRDD: Times: total = 374, boot = 372, init = 1, finish = 1
15/05/06 15:01:05 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 1870 bytes result sent to driver
15/05/06 15:01:05 INFO DAGScheduler: Stage 1 (count at /opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py:9) finished in 0.433 s
15/05/06 15:01:05 INFO DAGScheduler: Job 1 finished: count at /opt/spark-1.3.1-bin-hadoop2.6/bin/simpleApp.py:9, took 0.524992 s
15/05/06 15:01:05 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 426 ms on localhost (1/1)
15/05/06 15:01:05 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
Lines with a: 60, lines with b: 29
理论上是把任务分片到不同的节点上分布式执行,如果是从HDFS上面读取文件,一个地址是可以被不同机器的worker读取到的。如果是读本地local path的话,那么你要自己把文件内容分派到不同的worker机器上去,这样效果就大打折扣。
最后,其实standalone也可以写一个脚本,一次启动整个集群所有节点。太懒,以后弄~