前言
haproxy透传用户ip到服务器端, 已经有非常成熟的技术,网上有非常多的资料,很多是可以work的。但是如果你踩得坑足够多,你就会知道,将网上的方案应用于生成环境,一定要慎之又慎;而作为一个严肃的IAAS基础设施研发人员(UCloud云数据库团队),搞清楚这些配置和方法背后的道理,是很有必要的。为了解决haproxy透传用户Ip的问题,我花了几天时间,了解了其中最主流的一种技术(linux tproxy)的原理和实现,并总结出了一个可能是最精简的配置方法。下面是详细的内容。
1. 方法
主要参考的一些资料:
http://www.360doc.com/content/17/0204/11/36792569_626412598.shtml
http://www.360doc.com/content/13/0821/17/13047933_308812287.shtml
http://kb.snapt-ui.com/wp-content/uploads/2012/03/Snapt-HAProxy-TPROXY.pdf
http://forlinux.blog.51cto.com/8001278/1415350
https://www.nginx.com/blog/ip-transparency-direct-server-return-nginx-plus-transparent-proxy/
1.1 重新编译haproxy
wget http://haproxy.1wt.eu/download/1.4/src/haproxy-1.4.25.tar.gz
tar zxvf haproxy-1.4.25.tar.gz
cd haproxy-1.4.25
yum install gcc gcc-c++ autoconf automake -y
make TARGET=linux2628 arch=x86_64 USE_LINUX_TPROXY=1
make install
这一步的关键在于make时,指定TARGET=linux2628 arch=x86_64 USE_LINUX_TPROXY=1 选项,来打开透传用户IP的代码。
1.2 配置haproxy.cfg
在haproxy.cfg配置文件的代理配置分节中, 增加配置项:source 0.0.0.0 usesrc clientip。来指定对所有的用户ip做ip透传。更详细的配置示例如下:
listen ICE01 10.10.46.198:3306
mode tcp
maxconn 2000
balance roundrobin
source 0.0.0.0 usesrc clientip
server ice-10.10.1.109 10.10.1.109:3306 check inter 5000 fall 1 rise 2
1.3 配置返回包路由
通过1.1和1.2两步配置,即可对用户ip进行透传,但这样还不够: 由于后端server拿到的源ip,是客户端ip而非proxyip, 如此后端server在回包时,则无法走正常路径。此时,需要利用Linux的tproxy补丁,结合iptables/netfileter 来对回包进行处理。
1.3.1 后端server的路由配置
route add -net 10.10.0.0/16 gw 10.10.46.198
通过添加这条路由,让后端server,将返回包路由到proxy节点,10.10.46.198为proxy的Ip。
1.3.2 Proxy路由配置
/sbin/iptables -F
/sbin/iptables -t mangle -N DIVERT
/sbin/iptables -t mangle -A PREROUTING -p tcp -m socket -j DIVERT
/sbin/iptables -t mangle -A DIVERT -j MARK --set-mark 1
/sbin/iptables -t mangle -A DIVERT -j ACCEPT
/sbin/ip rule add fwmark 1 lookup 100
/sbin/ip route add local 0.0.0.0/0 dev lo table 100
通过以上配置,将所有发往Proxy的tcp包,重定向到本地环路(lo)上。然后由TProxy内核补丁来对这些网络包进行处理,进而成功将后端server返回包路由回源客户端。
注: 1.3.2 步,在将用户Ip透传环节,亦起到作用。将这一节放到最后,是为了方便大家由易到难,更好地理解和操作。
2. 原理
结合haproxy的代码,和tproxy作者的一个slice,以及网上对tproxy代码的分析:
http://people.netfilter.org/hidden/nfws/nfws-2008-tproxy_slides.pdf
http://www.360doc.com/content/17/0204/11/36792569_626412598.shtml
大致搞懂了基于tproxy进行用户Ip透传的原理。总结如下:
2.1 haproxy如何透传用户Ip?
这一步其实非常简单。haproxy进程只需要拿到用户ip,然后在创建到后端server的tcp连接时,做两件事情:
- 创建和后端server通信的socket,并调用setsockopt函数, 将socket设置为IP_TRANSPARENT或IP_FREEBIND
- 调用bind函数,将用户ip绑定到该socket,绑定后后端server看到的该tcp连接ip,即为用户源ip。
haproxy相关代码:
int tcpv4_bind_socket(int fd, int flags, struct sockaddr_in *local, struct sockaddr_in *remote)
{
struct sockaddr_in bind_addr;
int foreign_ok = 0;
int ret;
#ifdef CONFIG_HAP_LINUX_TPROXY
static int ip_transp_working = 1;
if (flags && ip_transp_working) {
if (setsockopt(fd, SOL_IP, IP_TRANSPARENT, (char *) &one, sizeof(one)) == 0
|| setsockopt(fd, SOL_IP, IP_FREEBIND, (char *) &one, sizeof(one)) == 0)
foreign_ok = 1;
else
ip_transp_working = 0;
}
#endif
if (flags) {
memset(&bind_addr, 0, sizeof(bind_addr));
bind_addr.sin_family = AF_INET;
if (flags & 1)
bind_addr.sin_addr = remote->sin_addr;
if (flags & 2)
bind_addr.sin_port = remote->sin_port;
}
setsockopt(fd, SOL_SOCKET, SO_REUSEADDR, (char *) &one, sizeof(one));
if (foreign_ok) {
ret = bind(fd, (struct sockaddr *)&bind_addr, sizeof(bind_addr));
if (ret < 0)
return 2;
}
else {
ret = bind(fd, (struct sockaddr *)local, sizeof(*local));
if (ret < 0)
2.2 haproxy如何正确处理后端server返回包?
后端server的返回包, 要通过haproxy正确转发并返回到客户端,需要解决两个问题:
后端server能够将返回包, 发送到Haproxy所在机器(而不是根据根据源ip地址,直接返回到客户端。由于客户端不存在对应的tcp状态机,直接返回亦将出错)。
haproxy所在机器,在收到后端server返回包后,能够将该返回包正确路由给haproxy进程进行处理。最终由Haproxy返回到客户端。
对于问题1, 解决方法很简单,只需要在后端server中配置一个路由:
route add -net 10.10.0.0/16 gw 10.10.46.198
配置该路由后, 后端server所在机器,将把所有目的地为10.10.0.0/16的包,路由到10.10.46.198这台机器。
而问题2的解决,则需要linux tproxy出场了。
2.2.1 linux tproxy简介
linux tproxy是linux内核支持透明代理的一技术,在linux内核2.6.28版本后, tproxy已经成为linux内核的一部分。
tproxy的核心原理, 是承接netfilter(通过iptables配置)路由过来的网络包, 然后对网络包进行处理。处理的结果之一,是将一个目的地为非本地ip(用户ip)的网络包, 递交给本地进程(haproxy)进行处理,最终由haproxy将该返回包返回到客户端。
在下面一节,将结合tproxy的源码,分析tproxy如何将目的地为用户ip的网络包, 递交到haproxy。
2.2.2 tproxy如何处理目的地为非本地ip(用户ip)的网络包?
- tproxy处理【目的地为非本地ip网络包】的流程示意图:
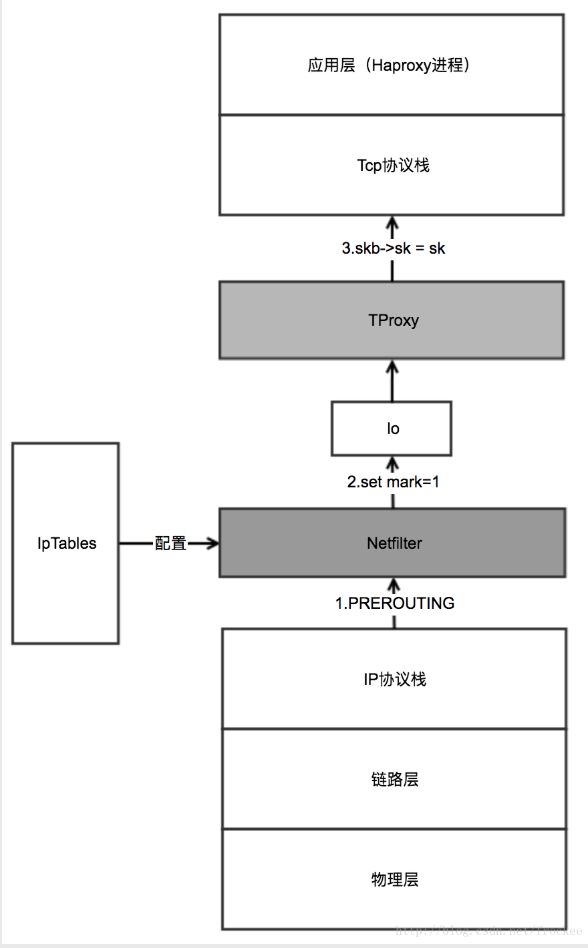
一些背景知识:
a. linux内核分层处理后端server返回的网络包,网络包经由链路层(网卡驱动)、Ip层、Tcp层,最终递交到应用层的Haproxy;
b.数据包在各层传递过程中, 在linux内核中,统一表示为一个结构:struct sk_buff,或称之为socket buffer,简写为skb;
c.skb在递交给tcp层时, 由skb->sk 标明该网络包,对应的应用层socket套接字是哪个,tcp层将根据skb->sk这个信息,将网络包放入到某个应用进程创建的套接字中,供应用层处理该网络包
d.为此,处理【目的地为非本地ip网络包】的关键, 在于在ip层,将skb中的sk,指定为haproxy进程创建的socket套接字
在网络层,tproxy结合netfilter/iptables, 是这么干的:
1.通过iptables配置ip层的路由规则, 将所有基于tcp的网络包(skb),打上标记(--set-mark 1),并将这些打了标记的包, 重定向到本地环路:
/sbin/iptables -F
/sbin/iptables -t mangle -N DIVERT
/sbin/iptables -t mangle -A PREROUTING -p tcp -m socket -j DIVERT
/sbin/iptables -t mangle -A DIVERT -j MARK --set-mark 1
/sbin/iptables -t mangle -A DIVERT -j ACCEPT
/sbin/ip rule add fwmark 1 lookup 100
/sbin/ip route add local 0.0.0.0/0 dev lo table 100
2.tproxy从本地环路上抓取网络包(skb),然后提取出网络包中的源ip/port,目的ip/port,根据这些信息,从内核中查找出对应的套接字句柄sk,然后进行赋值: skb->sk = sk(勘误:网上资料都是skb->sock=sk 但从linux内核的skb的定义来看,应该是sk而不是sock)。 赋值后将该包递交给上一层:tcp层。tcp层将根据skb->sk这个句柄,决定将该网络包递交给haproxy进程创建的socket套接字进行处理。
tproxy该处理逻辑相关的代码如下:
static unsigned int
tproxy_tg4(struct sk_buff *skb, __be32 laddr, __be16 lport, u_int32_t mark_mask, u_int32_t mark_value)
{
struct udphdr _hdr, *hp;
struct sock *sk;
hp = skb_header_pointer(skb, ip_hdrlen(skb), sizeof(_hdr), &_hdr);//获得传输头
if (hp == NULL) {
pr_debug("TPROXY: packet is too short to contain a transport header, dropping\n");
return NF_DROP;
}
//根据数据包的内容,向tcp已建立的队列查找skb属于的struct sock
//如果客户端与代理服务器已经建立连接,该数据包属于的sock将存在
sk = nf_tproxy_get_sock_v4(dev_net(skb->dev), iph->protocol,
iph->saddr, iph->daddr,
hp->source, hp->dest,
skb->dev, NFT_LOOKUP_ESTABLISHED);
...
more code see:
http://web.mit.edu/kolya/.f/root/net.mit.edu/sipb.mit.edu/contrib/linux/net/netfilter/xt_TPROXY.c
...
if (sk && nf_tproxy_assign_sock(skb, sk)) {
//运行至此,说明客户端已经与服务器端建立了三次握手,即sk存在;
//则通过nf_tproxy_assign_sock函数,将当前数据包的skb与代理服务器的监听socket建立联系,即skb->sk = sk
//最后,将数据包打上比较,待策略路由转发到loobackshang
/* This should be in a separate target, but we don't do multiple targets on the same rule yet */
skb->mark = (skb->mark & ~mark_mask) ^ mark_value;
pr_debug("TPROXY: redirecting: proto %u %08x:%u -> %08x:%u, mark: %x\n",
iph->protocol, ntohl(iph->daddr), ntohs(hp->dest),
ntohl(laddr), ntohs(lport), skb->mark);
return NF_ACCEPT;
}
}
...
more code see:
http://web.mit.edu/kolya/.f/root/net.mit.edu/sipb.mit.edu/contrib/linux/net/netfilter/xt_TPROXY.c
...
代码中核心的操作其实就三步:
1.从网络包(skb)中提取出源和目的地址:
const struct iphdr *iph = ip_hdr(skb);
2.调用nf_tproxy_get_sock_v4函数,
sk = nf_tproxy_get_sock_v4(dev_net(skb->dev), iph->protocol,
iph->saddr, iph->daddr,
hp->source, hp->dest,
skb->dev, NFT_LOOKUP_ESTABLISHED);
去内核中,获得该网络包对应的socket套接字。该套接字为什么能够获得到呢? 因为haproxy进程,在发送请求到后端server时,就已经在和后端的套接字中,通过bind,绑定了用户ip和port作为源地址,后端server作为目标地址。 这就保证了,在处理后端server所回的这个skb时,linux能够根据skb的源和目的地址,找到对应的套接字。
- 将sk复制给skb的sk指针:
if (sk && nf_tproxy_assign_sock(skb, sk))
3. 总结
为了透传用户ip到后端server, proxy机器需要解决两个问题:
1.在创建到后端server的套接字时, 将用户ip作为套接字的源ip,从而让后端server看到;
2.后端server在回包时, 能够将目的地为用户ip的回包,返回给proxy机器,而proxy机器能够将该包,从网卡驱动(链路层)收下来,并正确递交给应用层的haproxy进程
为了解决这两个问题,haproxy进程和所在机器需要做三个事情:
1.haproxy进程在创建到后端server的tcp套接字时,开启IP_TRANSPARENT选项, 并绑定用户ip为源ip;
2.后端server修改路由规则,将目的地为用户ip的回包,路由给proxy机器;
3.proxy机器在处理回包时, 在ip层, 由TProxy通过结合netfilter/iptables, 对该回包做一些小动作,将该回包的skb->sk = sk(sk为haproxy进程创建的对应套接字),从而让tcp层能够根据skb->sk, 将该回包递交给haroxy进程进行处理,最终返回给客户端。