本文主要结合Spark-1.6.0的源码,对Spark中任务调度模块的执行过程进行分析。Spark Application在遇到Action操作时才会真正的提交任务并进行计算。这时Spark会根据Action操作之前一系列Transform操作的关联关系,生成一个DAG,在后续的操作中,对DAG进行Stage划分,生成Task并最终运行。整个过程如下图所示,DAGScheduler用于对Application进行分析,然后根据各RDD之间的依赖关系划分Stage,根据这些划分好的Stage,对应每个Stage会生成一组Task,将Task Set提交到TaskScheduler后,会由TaskScheduler启动Executor进行任务的计算。
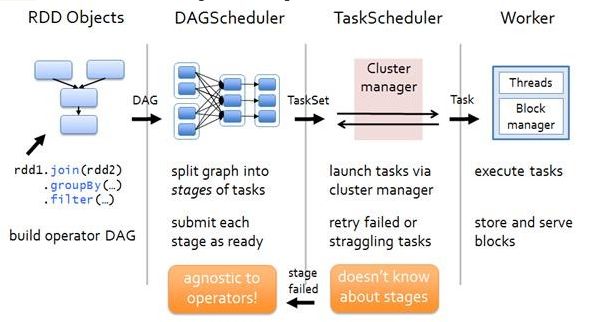
在任务调度模块中最重要的三个类是:
1. org.apache.spark.scheduler.DAGScheduler
2. org.apache.spark.scheduler.SchedulerBackend
3. org.apache.spark.scheduler.TaskScheduler
这里面SchedulerBackend主要起到的作用是为Task分配计算资源。
由于TaskScheduler与SchedulerBackend结合比较紧密,并且从生成来看都是在同一个方法生成,所以接下来分成两篇博客对这三个主要的类进行分析,本文分析DAGScheduler的执行过程。有关SchedulerBackend和TaskScheduler的分析,可以访问Spark Scheduler模块源码分析之TaskScheduler和SchedulerBackend。
一、DAGScheduler的构建
Spark在构造SparkContext时就会生成DAGScheduler的实例。
val (sched, ts) = SparkContext.createTaskScheduler(this, master)
_schedulerBackend = sched//生成schedulerBackend
_taskScheduler = ts//生成taskScheduler
_dagScheduler = new DAGScheduler(this)//生成dagScheduler,传入当前sparkContext对象。 在生成_dagScheduler之前,已经生成了_schedulerBackend和_taskScheduler对象。这两个对象会在接下来第二和第三部分中介绍。之所以taskScheduler对象在dagScheduler对象构造之前先生成,是由于在生成DAGScheduler的构造方法中会从传入的SparkContext中获取到taskScheduler对象def this(sc: SparkContext) = this(sc, sc.taskScheduler)。
看一下DAGScheduler对象的主构造方法,
class DAGScheduler(
private[scheduler] val sc: SparkContext, // 获得当前SparkContext对象
private[scheduler] val taskScheduler: TaskScheduler, // 获得当前saprkContext内置的taskScheduler
listenerBus: LiveListenerBus, // 异步处理事件的对象,从sc中获取
mapOutputTracker: MapOutputTrackerMaster, //运行在Driver端管理shuffle map task的输出,从sc中获取
blockManagerMaster: BlockManagerMaster, //运行在driver端,管理整个Job的Block信息,从sc中获取
env: SparkEnv, // 从sc中获取
clock: Clock = new SystemClock())其中有关LiveListenerBus会在Spark-1.6.0之Application运行信息记录器JobProgressListener中有具体介绍。MapOutputTrackerMaster,BlockManagerMaster后续也会写博客进行分析。
DAGScheduler的数据结构
在DAGScheduler的源代码中,定义了很多变量,在刚构造出来时,仅仅只是初始化这些变量,具体使用是在后面Job提交的过程中了。
private[scheduler] val nextJobId = new AtomicInteger(0) // 生成JobId
private[scheduler] def numTotalJobs: Int = nextJobId.get() // 总的Job数
private val nextStageId = new AtomicInteger(0) // 下一个StageId
// 记录某个job对应的包含的所有stage
private[scheduler] val jobIdToStageIds = new HashMap[Int, HashSet[Int]]
// 记录StageId对应的Stage
private[scheduler] val stageIdToStage = new HashMap[Int, Stage]
// 记录每一个shuffle对应的ShuffleMapStage,key为shuffleId
private[scheduler] val shuffleToMapStage = new HashMap[Int, ShuffleMapStage]
// 记录处于Active状态的job,key为jobId, value为ActiveJob类型对象
private[scheduler] val jobIdToActiveJob = new HashMap[Int, ActiveJob]
// 等待运行的Stage,一般这些是在等待Parent Stage运行完成才能开始
private[scheduler] val waitingStages = new HashSet[Stage]
// 处于Running状态的Stage
private[scheduler] val runningStages = new HashSet[Stage]
// 失败原因为fetch failures的Stage,并等待重新提交
private[scheduler] val failedStages = new HashSet[Stage]
// active状态的Job列表
private[scheduler] val activeJobs = new HashSet[ActiveJob]
// 处理Scheduler事件的对象
private[scheduler] val eventProcessLoop = new DAGSchedulerEventProcessLoop(this) DAGScheduler构造完成,并初始化一个eventProcessLoop实例后,会调用其eventProcessLoop.start()方法,启动一个多线程,然后把各种event都提交到eventProcessLoop中。这个eventProcessLoop比较重要,在后面也会提到。
二、Job的提交
一个Job实际上是从RDD调用一个Action操作开始的,该Action操作最终会进入到org.apache.spark.SparkContext.runJob()方法中,在SparkContext中有多个重载的runJob方法,最终入口是下面这个:
// SparkContext.runJob
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
} 这里调用dagScheduler.runJob()方法后,正式进入之前构造的DAGScheduler对象中。在这个方法中,后续一系列的过程以此为:
1. DAGScheduler#runJob
执行过程中各变量的内容如下图所示

调用DAGScheduler.submitJob方法后会得到一个JobWaiter实例来监听Job的执行情况。针对Job的Succeeded状态和Failed状态,在接下来代码中都有不同的处理方式。
2. DAGScheduler#submitJob
进入submitJob方法,首先会去检查rdd的分区信息,在确保rdd分区信息正确的情况下,给当前job生成一个jobId,nexJobId在刚构造出来时是从0开始编号的,在同一个SparkContext中,jobId会逐渐顺延。然后构造出一个JobWaiter对象返回给上一级调用函数。通过上面提到的eventProcessLoop提交该任务,最终会调用到DAGScheduler.handleJobSubmitted来处理这次提交的Job。handleJobSubmitted在下面的Stage划分部分会有提到。
3. DAGSchedulerEventProcessLoop#post
在前面的方法中,调用post方法传入的是一个JobSubmitted实例。DAGSchedulerEventProcessLoop类继承自EventLoop类,其中的post方法也是在EventLoop中定义的。在EventLoop中维持了一个LinkedBlockingDeque类型的事件队列,将该Job提交事件存入该队列后,事件线程会从队列中取出事件并进行处理。
private val eventQueue: BlockingQueue[E] = new LinkedBlockingDeque[E]() // 事件队列
def post(event: E): Unit = {
eventQueue.put(event) // 将JobSubmitted,Job提交事件存入该队列中
}4、EventLoop#run
该方法从eventQueue队列中顺序取出event,调用onReceive方法处理事件
val event = eventQueue.take()
try {
onReceive(event)
}5、DAGSchedulerEventProcessLoop#onReceive
在onReceive方法中,进一步调用doOnReceive方法
override def onReceive(event: DAGSchedulerEvent): Unit = {
val timerContext = timer.time()
try {
doOnReceive(event)
} finally {
timerContext.stop()
}
}6、DAGSchedulerEventProcessLoop#doOnReceive
在该方法中,根据事件类别分别匹配不同的方法进一步处理。本次传入的是JobSubmitted方法,那么进一步调用的方法是DAGScheduler.handleJobSubmitted。这部分的逻辑,以及还可以处理的其他事件,都在下面的源代码中。
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
// 处理Job提交事件
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
// 处理Map Stage提交事件
case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>
dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)
// 处理Stage取消事件
case StageCancelled(stageId) =>
dagScheduler.handleStageCancellation(stageId)
// 处理Job取消事件
case JobCancelled(jobId) =>
dagScheduler.handleJobCancellation(jobId)
// 处理Job组取消事件
case JobGroupCancelled(groupId) =>
dagScheduler.handleJobGroupCancelled(groupId)
// 处理所以Job取消事件
case AllJobsCancelled =>
dagScheduler.doCancelAllJobs()
// 处理Executor分配事件
case ExecutorAdded(execId, host) =>
dagScheduler.handleExecutorAdded(execId, host)
// 处理Executor丢失事件
case ExecutorLost(execId) =>
dagScheduler.handleExecutorLost(execId, fetchFailed = false)
case BeginEvent(task, taskInfo) =>
dagScheduler.handleBeginEvent(task, taskInfo)
case GettingResultEvent(taskInfo) =>
dagScheduler.handleGetTaskResult(taskInfo)
// 处理完成事件
case completion @ CompletionEvent(task, reason, _, _, taskInfo, taskMetrics) =>
dagScheduler.handleTaskCompletion(completion)
// 处理task集失败事件
case TaskSetFailed(taskSet, reason, exception) =>
dagScheduler.handleTaskSetFailed(taskSet, reason, exception)
// 处理重新提交失败Stage事件
case ResubmitFailedStages =>
dagScheduler.resubmitFailedStages()
}7、DAGScheduler#handleJobSubmitted
当Job提交后,JobSubmitted事件会被eventProcessLoop捕获到,然后进入本方法中。开始处理Job,并执行Stage的划分。这一部分会衔接下一节,所以这个方法的源码以及Stage如何划分会在下一节中详细描述。
三、Stage的划分
Stage的划分过程中,会涉及到宽依赖和窄依赖的概念,宽依赖是Stage的分界线,连续的窄依赖都属于同一Stage。

比如上图中,在RDD G处调用了Action操作,在划分Stage时,会从G开始逆向分析,G依赖于B和F,其中对B是窄依赖,对F是宽依赖,所以F和G不能算在同一个Stage中,即在F和G之间会有一个Stage分界线。上图中还有一处宽依赖在A和B之间,所以这里还会分出一个Stage。最终形成了3个Stage,由于Stage1和Stage2是相互独立的,所以可以并发执行,等Stage1和Stage2准备就绪后,Stage3才能开始执行。
Stage有两个类型,最后的Stage为ResultStage类型,除此之外的Stage都是ShuffleMapStage类型。
1、DAGScheduler#handleJobSubmitted
这个方法的具体代码如下所示,前面提到了Stage的划分是从最后一个Stage开始逆推的,每遇到一个宽依赖处,就分裂成另外一个Stage,依此类推直到Stage划分完毕为止。并且,只有最后一个Stage的类型是ResultStage类型。
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
// Stage划分过程是从最后一个Stage开始往前执行的,最后一个Stage的类型是ResultStage
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
//为该Job生成一个ActiveJob对象,并准备计算这个finalStage
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job // 该job进入active状态
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post( // 向LiveListenerBus发送Job提交事件
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage) //提交当前Stage
submitWaitingStages()
}2、DAGScheduler#newResultStage
在这个方法中,会根据最后调用Action的那个RDD,以及方法调用过程callSite,生成的jobId,partitions等信息生成最后那个Stage。
private def newResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
// 获取当前Stage的parent Stage,这个方法是划分Stage的核心实现
val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, jobId)
val stage = new ResultStage(id, rdd, func, partitions, parentStages, jobId, callSite)// 创建当前最后的ResultStage
stageIdToStage(id) = stage // 将ResultStage与stageId相关联
updateJobIdStageIdMaps(jobId, stage) // 更新该job中包含的stage
stage
}3、DAGScheduler#getParentStagesAndId
这个方法主要是为当前的RDD向前探索,找到宽依赖处划分出parentStage,并为当前RDD所属Stage生成一个stageId。在这个方法中,getParentStages的调用链最终递归调用到了这个方法,所以,最后一个Stage的stageId最大,越往前的stageId就越小,stageId小的Stage先执行。
private def getParentStagesAndId(rdd: RDD[_], firstJobId: Int): (List[Stage], Int) = {
val parentStages = getParentStages(rdd, firstJobId) // 传入rdd和jobId,生成parentStage
// 生成当前stage的stageId。同一Application中Stage初始编号为0
val id = nextStageId.getAndIncrement()
(parentStages, id)
}4、DAGScheduler#getParentStages
从当前rdd开始往前探索父rdd,在每一个宽依赖处生成一个parentStage,而窄依赖的rdd,继续压入栈中,等待下一轮分析窄依赖父rdd的父rdd,一直找到宽依赖生成新的stage,或者直到第一个rdd为止。同时,使用一个HashSet来保存访问过的rdd,后面分析时遇到重复依赖时也能保证每个rdd只被分析了一次。一个Job中,除了最后一个Stage是ResultStage类型之外,他的Stage都是ShuffleMapStage结构。
private def getParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
val parents = new HashSet[Stage] // 存储当前stage的所有parent stage
val visited = new HashSet[RDD[_]] // 存储访问过的rdd
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new Stack[RDD[_]] // 一个栈,保存未访问过的rdd,先进后出
def visit(r: RDD[_]) {
if (!visited(r)) { // 如果栈中弹出的rdd被未访问过
visited += r // 首先将其标记为已访问
// Kind of ugly: need to register RDDs with the cache here since
// we can't do it in its constructor because # of partitions is unknown
for (dep <- r.dependencies) { // 读取当然rdd的依赖
dep match {
case shufDep: ShuffleDependency[_, _, _] => // 如果是宽依赖,则获取依赖rdd所在的ShuffleMapStage
parents += getShuffleMapStage(shufDep, firstJobId)
case _ =>
// 如果是窄依赖,将依赖的rdd也压入栈中,下次循环时会探索该rdd的依赖情况,直到找到款依赖划分新的stage为止
waitingForVisit.push(dep.rdd)
}
}
}
}
waitingForVisit.push(rdd) // 将当前rdd压入栈中
while (waitingForVisit.nonEmpty) { // 如果栈中有未被访问的rdd
visit(waitingForVisit.pop()) //
}
parents.toList
}5、DAGScheduler.newOrUsedShuffleStage
这里会为当前Shuffle生成一个ShuffleMapStage,并且会与MapOutputTracker打交道,记录本次Shuffle的一些信息。
private def newOrUsedShuffleStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
val rdd = shuffleDep.rdd
val numTasks = rdd.partitions.length // 根据当前rdd的paritions个数,计算出当前Stage的task个数。
// 为当前rdd生成ShuffleMapStage
val stage = newShuffleMapStage(rdd, numTasks, shuffleDep, firstJobId, rdd.creationSite)
if (mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
// 如果当前shuffle已经在MapOutputTracker中注册过
val serLocs = mapOutputTracker.getSerializedMapOutputStatuses(shuffleDep.shuffleId)
val locs = MapOutputTracker.deserializeMapStatuses(serLocs)
(0 until locs.length).foreach { i => // 更新Shuffle的Shuffle Write路径
if (locs(i) ne null) {
// locs(i) will be null if missing
stage.addOutputLoc(i, locs(i))
}
}
} else { // 如果当前Shuffle没有在MapOutputTracker中注册过
// Kind of ugly: need to register RDDs with the cache and map output tracker here
// since we can't do it in the RDD constructor because # of partitions is unknown
logInfo("Registering RDD " + rdd.id + " (" + rdd.getCreationSite + ")")
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length) // 注册
}
stage
}6、DAGScheduler#getShuffleMapStage
为当前宽依赖的Map端生成一个新的ShuffleMapStage类型的Stage。同时也为当前Shuffle的父Shuffle生成一个Stage。通过DAGScheduler.getAncestorShuffleDependencies获取当前Shuffle的父Shuffle,这个方法的逻辑和上面的DAGScheduler.getParentStages获取当前Stage的父Stage类似。
private def getShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
shuffleToMapStage.get(shuffleDep.shuffleId) match { // 从Shuffle和Stage映射中取出当前Shuffle对应的Stage
case Some(stage) => stage // 如果该shuffle已经生成过stage,则直接返回
case None => // 否则为当前shuffle生成新的stage
// We are going to register ancestor shuffle dependencies
getAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
// 为当前shuffle的父shuffle都生成一个ShuffleMapStage
shuffleToMapStage(dep.shuffleId) = newOrUsedShuffleStage(dep, firstJobId)
}
// Then register current shuffleDep
val stage = newOrUsedShuffleStage(shuffleDep, firstJobId) // 为当前shuffle生成一个ShuffleMapStage
shuffleToMapStage(shuffleDep.shuffleId) = stage // 更新Shuffle和Stage的映射关系
stage
}
}7、DAGScheduler#newShuffleMapStage
这个和2类似,不同的是2是生成最终的ResultStage,而这里是生成ShuffleMapStage,不过这两者都会调用方法3,最终形成了一个递归调用。
private def newShuffleMapStage(
rdd: RDD[_],
numTasks: Int,
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int,
callSite: CallSite): ShuffleMapStage = {
// 获取当前rdd的父Stage和stageId
val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, firstJobId)
// 生成新的ShuffleMapStage
val stage: ShuffleMapStage = new ShuffleMapStage(id, rdd, numTasks, parentStages,
firstJobId, callSite, shuffleDep)
stageIdToStage(id) = stage // 将ShuffleMapStage与stageId相关联
updateJobIdStageIdMaps(firstJobId, stage) // 更新该job中包含的stage
stage
}四、Stage的提交
这部分主要梳理Stage生成后如何提交,任务的提交和生成入口在前面DAGScheduler#handleJobSubmitted方法中。
1、DAGScheduler#handleJobSubmitted
这个方法的代码可以到第三节中查看。生成了finalStage后,就会为该Job生成一个ActiveJob对象了,并准备计算这个finalStage。
ActiveJob对象中的信息比较少,可以看其类定义
private[spark] class ActiveJob(
val jobId: Int,
val finalStage: Stage,
val callSite: CallSite,
val listener: JobListener,
val properties: Properties) {
/**
* 该Job需要计算的partitions个数
*/
val numPartitions = finalStage match {
case r: ResultStage => r.partitions.length
case m: ShuffleMapStage => m.rdd.partitions.length
}
/** 一个Boolean类型的数组,初始值为false
* 数组长度为partitions个数,哪个partition被计算了,则对应的
* 值标记为true
*/
val finished = Array.fill[Boolean](numPartitions)(false)
// 处理完成的partition个数
var numFinished = 0
} 在DAGScheduler.handleJobSubmitted方法的最后,调用了DAGScheduler.submitStage方法,在提交finalSate的前面,会通过listenerBus的post方法,把Job开始的事件提交到Listener中。
2、DAGScheduler#submitStage
提交Job的提交,是从最后那个Stage开始的。如果当前stage已经被提交过,处于waiting或者waiting状态,或者当前stage已经处于failed状态则不作任何处理,否则继续提交该stage。
在提交时,需要当前Stage需要满足依赖关系,其前置的Parent Stage都运行完成后才能轮得到当前Stage运行。如果还有Parent Stage未运行完成,则优先提交Parent Stage。通过调用方法DAGScheduler.getMissingParentStages方法获取未执行的Parent Stage。
如果当前Stage满足上述两个条件后,调用DAGScheduler.submitMissingTasks方法,提交当前Stage。
/** Submits stage, but first recursively submits any missing parents. */
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage) // 获取当前提交Stage所属的Job
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
// 首先判断当前stage的状态,如果当前Stage不是处于waiting, running以及failed状态
// 则提交该stage
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) { //如果所有的parent stage都以及完成,那么就会提交该stage所包含的task
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get) //过程见下面的方法描述
} else { //否则递归的去提交未完成的parent stage
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage //当前stage进入等待队列
}
}
} else { //如果jobId没被定义,即无效的stage则直接停止
abortStage(stage, "No active job for stage " + stage.id, None)
}
}2.1 DAGScheduler#getMissingParentStage
这个方法用于获取stage未执行的Parent Stage。在上面方法中,获取到Parent Stage后,递归调用上面那个方法按照StageId小的先提交的原则,这个方法的逻辑和DAGScheduler#getParentStages方法类似,这里不再分析了。总之就是根据当前Stage,递归调用其中的visit方法,依次对每一个Stage追溯其未运行的Parent Stage。
3、DAGScheduler.submitMissingTasks
当Stege的Parent Stage都运行完毕,才能调用这个方法真正的提交当前Stage中包含的Task。这个方法涉及到了Task,会在Spark Scheduler模块源码分析之TaskScheduler和SchedulerBackend中进一步分析。
到这里,本文主要分析了Scheduler模块中DAGScheduler的作用,构成,以及Stage划分和Stage最终的提交过程,仔细观察这一部分的主要代码中,在多处都会看到listenerBus.post方法的调用,针对不同的Stage事件,会将这个事件提交到LiveListenerBus中,将Stage事件相关过程进行记录,并使得Spark其他部分能够及时获取到Stage的最新状态。这一部分可以参考Spark-1.6.0之Application运行信息记录器JobProgressListener。