2019独角兽企业重金招聘Python工程师标准>>> 
先初步介绍一下内存组成:
java进程占用内存 约等于 Java永久代 + Java堆(新生代和老年代) + 线程栈+ Java NIO,其它部分占用内存较小,
详细可以参考这篇文章 https://my.oschina.net/haitaohu/blog/1830582
第一步:获取异常进程pid
通过ps 或者 jps获取 pid
第二步:基本内存分配查询 jmap -heap pid
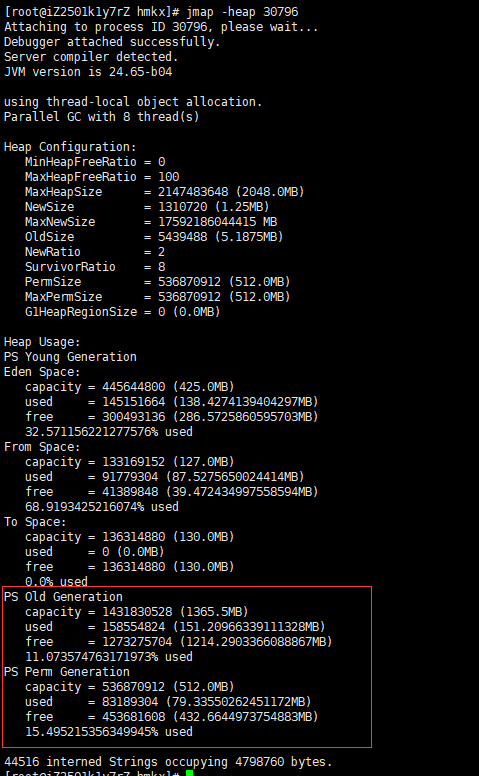
注意:着重看一下永久区和 老年区 是否够用,因为前面的都是中转区域,这两个是最终落地区域和gc相关
第三步:分析gc是否正常执行
jstat -gccause pid 2000 //每两秒执行一下

S0 — Heap上的 Survivor space 0 区已使用空间的百分比
S1 — Heap上的 Survivor space 1 区已使用空间的百分比
E — Heap上的 Eden space 区已使用空间的百分比
O — Heap上的 Old space 区已使用空间的百分比
P — Perm space 区已使用空间的百分比
YGC — 从应用程序启动到采样时发生 Young GC 的次数
YGCT– 从应用程序启动到采样时 Young GC 所用的时间(单位秒)
FGC — 从应用程序启动到采样时发生 Full GC 的次数
FGCT– 从应用程序启动到采样时 Full GC 所用的时间(单位秒)
GCT — 从应用程序启动到采样时用于垃圾回收的总时间(单位秒)
LGCC - 进行GC的原因(低版本jdk可能没有这一列)从这里观察gc是否异常,也可以根据这个进行jvm内存分配调优,来提高性能降低gc对性能的损耗
如果上面流程还是观察不出内存异常的问题,可能就属于堆外内存问题了,一般出现在io相关操作、 redis、数据库的连接等
最明显的特征:java进程占用内存超过你设置的jvm内存最大值
第四步: pmap -x pid 如果需要排序 | sort -n -k3
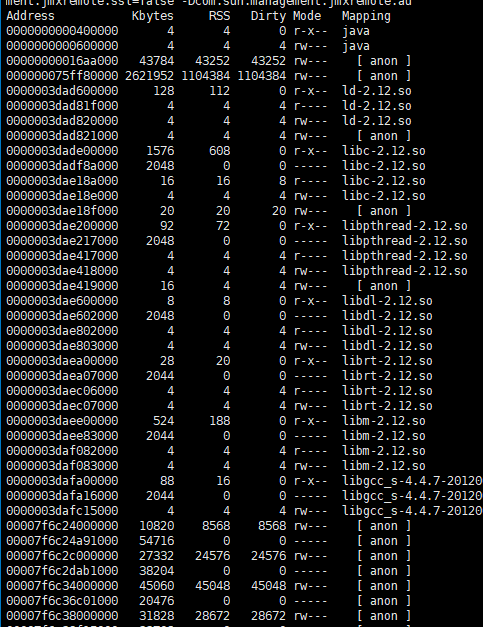
主要观察第一列Address和第三列Rss,看哪些内存占用较大,可以在第五步确认
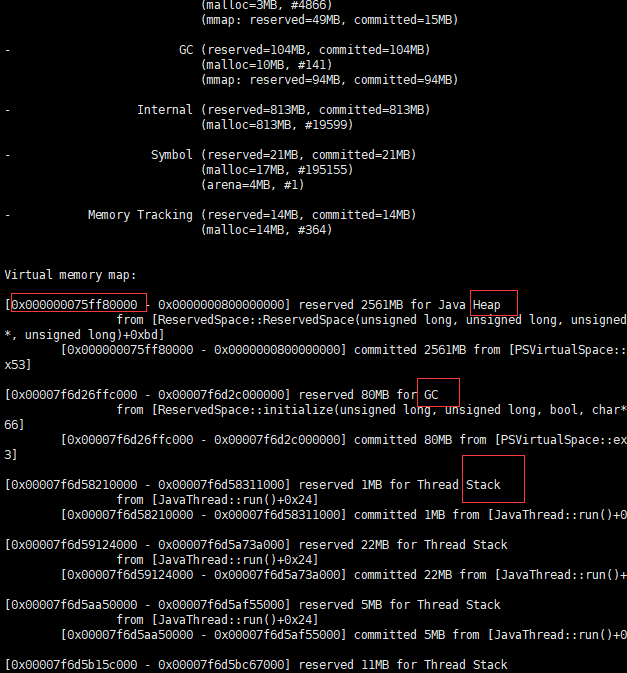
第五部:开启Native Memory Tracker (NMT)进行排查
在启动参数上加入-XX:NativeMemoryTracking=detail ,重启java(tomcat)等
启动后,通过命令 jcmd 30796 VM.native_memory detail scale=MB >temp.txt 查看内存分配情况
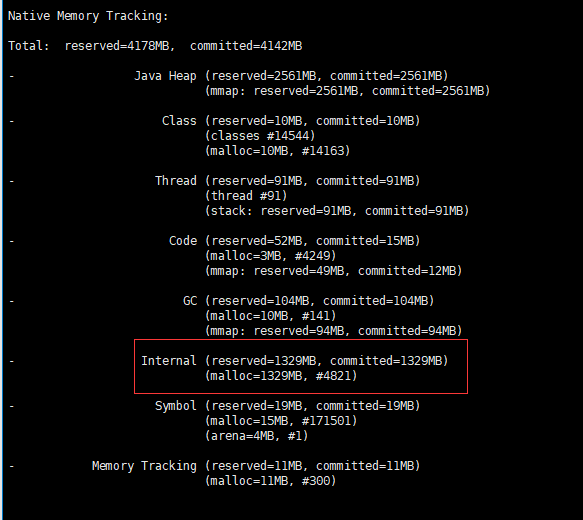
然后根据上图看哪部分占用内存较高、结合第四步中占用内存高的部分进行搜索查看明细,就在这个文档的明细部分
第六步:使用 perf record -g -p 55 开启监控栈函数调用。运行一段时间后Ctrl+C结束,会生成一个文件perf.data
执行perf report -i perf.data查看报告
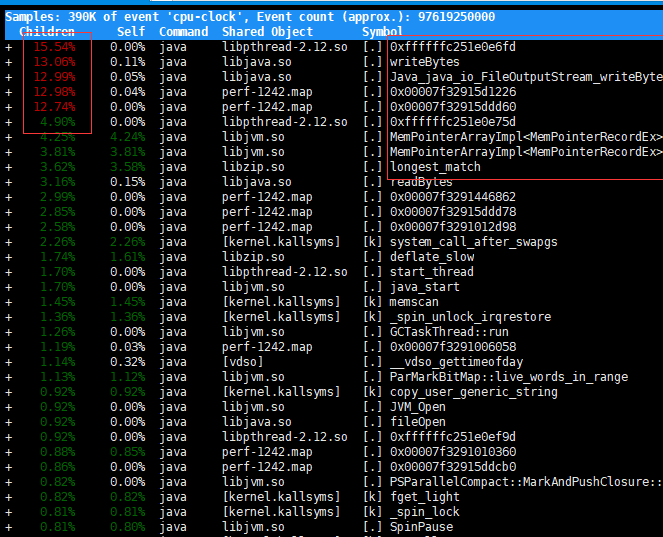
如果这里还不能定位分析初问题,可以借助下一步
第七步:对外内存排查工具google-perftools ,安装可以参考 https://my.oschina.net/haitaohu/blog/3024095
注意:多个文件同时分析
gperftools-2.5/bin/pprof --text /data/jdk1.7.0_65/bin/java /data/java/deploy/google-perftools/local/gzip/gzip.*.heap > tmp.txt1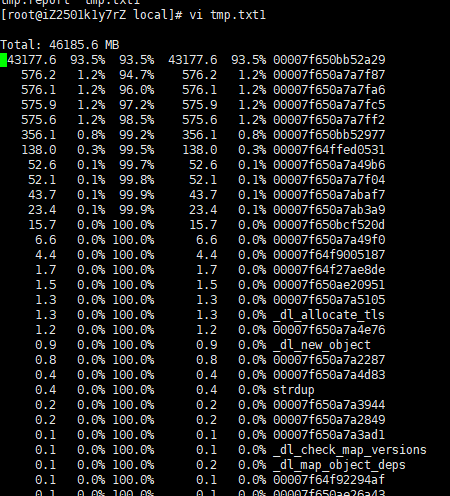
Analyzing Text Output
Text mode has lines of output that look like this:
14 2.1% 17.2% 58 8.7% std::_Rb_tree::find
Here is how to interpret the columns:
1.Number of profiling samples in this function
2.Percentage of profiling samples in this function
3.Percentage of profiling samples in the functions printed so far
4.Number of profiling samples in this function and its callees
5.Percentage of profiling samples in this function and its callees
6.Function name
第一列代表这个函数调用本身直接使用了多少内存,第二列表示第一列的百分比,第三列是从第一行到当前行的所有第二列之和,第四列表示这个函数调用自己直接使用加上所有子调用使用的内存总和,第五列是第四列的百分比如果文本分析不够明显,也可以导出pdf文件
yum -y install ghostscript
yum -y install graphviz
gperftools-2.5/bin/pprof --pdf /data/jdk1.7.0_65/bin/java /data/java/deploy/google-perftools/local/gzip/gzip.*.heap > tmp.pdf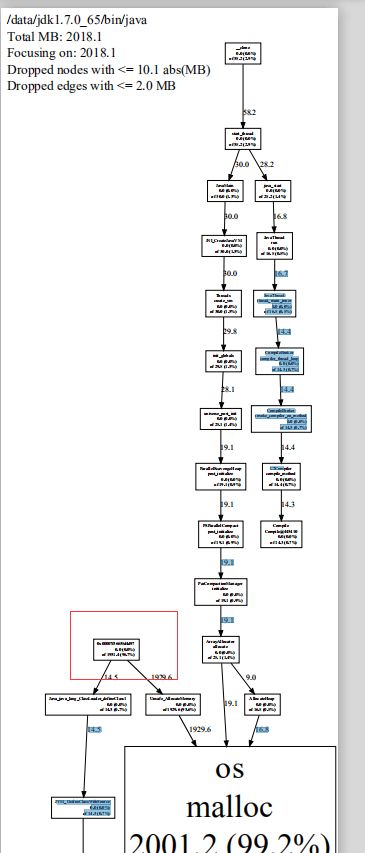
这样就很明显的看到异常点了,无上级节点,通过Unsafe分配使用堆外内存
最终定位的问题为:direct buffer 通过 unsafe分配直接内存导致,这时候堆内存一直没有达到fullgc的条件,同时direct buffer没有设置上限导致的, 通过-XX:MaxDirectMemorySize=1024m 设置一下最大值
第八步:jstack -m -l pid (这一步可以提前,如果能发现某些异常线程信息)当然也有很多界面工具查看更清晰一些,我这里用的Jprofiler
从这几步一般能看出问题来了,这是一次排查后的总结,有些步骤可能是多余的,但基本这些就能定位分析初问题所在了,后续会持续补充,有错误欢迎指出或者提供更好的办法,感谢