京东手机爬虫
拖延症晚期的我终于于于于于于于又来更新博客了。国庆自己写了个京东手机的爬虫,爬取了京东商城所有手机的名称,价格,配置,属性等信息,算是实现了预期的功能。这里mark一下,以后遇到类似的项目都可以借鉴。
这次的京东手机爬虫和以往的都不太相同,之前爬取的都是静态网页,所有需要的内容都可以在一个页面中找到,比较基础。这次的爬虫涉及到动态加载的网页,具体的话参加后面的详细说明。
在开始具体的爬虫之前,我想先总结一下编写简单爬虫的思路。首先,秉承“万物皆可爬”的理念,我们能找到的URL都是可以爬取的(如果是某些大型的网站可能会有反爬措施,相应的会有特殊的手段进行爬取。当然,爬和反爬就像矛与盾的关系,身为菜鸟的我在爬京东时总是战战兢兢,生怕什么时候就把我的IP封了=.=)。带着这种舍我其谁的勇气,我们来试试吧~
简单梳理一下之前做过的小爬虫,大概分为以下几个步骤:
1. 俗话说,“巧妇难为无米之炊”,我们先要找到需要爬取的网页地址,这是我们一切工作的前提。(URL可能有多个哦)
2. 对于URL,通过解析将其转换为网页文本。这里我用的是Python3中的requests库,提交一个包含URL的request请求,会返回一个包含网页内容的response响应。在这个response对象中就可以获取网页文本。
3. 得到网页文本后通过一定的工具对其进行解析,得到我们感兴趣的内容(“弱水三千,我只取一瓢”那么多内容都爬下来也理解不了啊。)这里我用过的工具主要有三种,适用于不同的网页。
(1) 对于简单一点的网页(内容不多,格式也不是标准的html格式),使用正则表达式库re,将网页视为一个超级长的字符串,匹配得到相应的内容。
(2) 大型网站的网页,有时候用正则就会显得力不从心。另一方面,这些网页通常都是标准的html格式,而Python第三方库BeautifulSoup非常适合解决这类的问题。BeautifulSoup将整个html文档解析为以标签为节点的树形结构,并提供访问这些节点的API,这对于爬取我们关心的网页内容来讲是非常便利的。
(3) JSON或者类JSON类型的网页,这些网页的数据全部或者大部分是以JSON格式保存的,而json库可以方便地从这些类型的网页中获取键值对等信息。
(4) 未完待续….
有了思路后,马上进行京东手机爬取的内容吧~
1. 进入京东的首页,选择手机后的界面是这样式儿的:
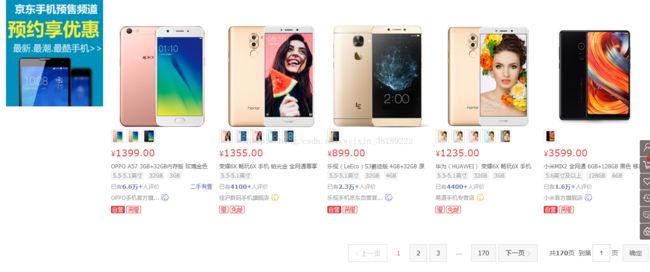
得到这些URL后,先选择某一页查看源代码找到我们关心的内容:
好,170页,这就是我们的目标。而我们更关心每页的URL,这就有点像找规律了…
第1页:
https://list.jd.com/list.html?cat=9987,653,655&page=1&sort=sort%5Frank%5Fasc&trans=1&JL=6_0_0#J_main
第2页:
https://list.jd.com/list.html?cat=9987,653,655&page=2&sort=sort%5Frank%5Fasc&trans=1&JL=6_0_0#J_main
第3页:
https://list.jd.com/list.html?cat=9987,653,655&page=3&sort=sort%5Frank%5Fasc&trans=1&JL=6_0_0#J_main
…
第170页:
https://list.jd.com/list.html?cat=9987,653,655&page=170&sort=sort%5Frank%5Fasc&trans=1&JL=6_0_0#J_main
看到这么有规律的URL对于程序的循环抓取来讲可是太开心了,所以京东手机预览界面的URL格式为:
https://list.jd.com/list.html?cat=9987,653,655&page=?&sort=sort%5Frank%5Fasc&trans=1&JL=6_0_0#J_main
其中?代表页码,这里就是1-170。
这对应的代码为:
def getAllPages():
allPagesUrlList = []
singlePageUrl = ''
for page in range(1, 171):
if page == 2:
singlePageUrl = 'https://list.jd.com/list.html?cat=9987,653,655&page=' \
+ str(page) + '&sort=sort%5Frank%5Fasc&trans=1&JL=6_0_0&ms=6#J_main'
singlePageUrl = 'https://list.jd.com/list.html?cat=9987,653,655&page=' \
+ str(page) + '&sort=sort%5Frank%5Fasc&trans=1&JL=6_0_0#J_main'
allPagesUrlList.append(singlePageUrl)
return allPagesUrlList得到这些URL后,先选择某一页查看源代码找到我们关心的内容:

这里每一页都有N多个手机,我们在人工点击一个手机时会跳转到手机详情界面,而这个链接在上图的href标签内。这里采用BeautifulSoup库获取该标签的内容。代码如下:
def getPhonesUrl(pageUrl):
phonesUrlList = []
html = getHtmlText(pageUrl)
soup = BeautifulSoup(html, 'html.parser')
items = soup.find_all('div',attrs={'class':'p-name'})
for item in items:
phonesUrlList.append('https:' + item.a.get('href'))
return phonesUrlList查看手机详情界面的源文件可以看到,我们关心的手机名称,价格,配置,评论分别在哪呢?
手机名称的位置:
可以看到手机名称在
标签下,以下是获取手机名称的代码:手机配置的位置:

在浏览器显示界面看到的内容:

为了在爬取时顺序不会乱,这里用字典类型保存这些配置信息,代码如下:
def getPhoneName(phoneurl):
infoText = getHtmlText(phoneurl)
soup = BeautifulSoup(infoText, 'html.parser')
name = soup.find('div', attrs={'class': 'sku-name'}).get_text().strip()
return namedef getPhoneProperties(phoneurl):
phoneProperties = {}
list_value = []
list_name = []
infoText = getHtmlText(phoneurl)
soup = BeautifulSoup(infoText, 'html.parser')
proSection = soup.findAll('div', attrs={'class': 'Ptable-item'})
for pro in proSection:
# 既然找不到直接去除有属性标签的方法就取个差集吧
list_all = pro.find_all('dd')
list_extracted = pro.find_all('dd', {'class': 'Ptable-tips'})
list_chosen = [i for i in list_all if i not in list_extracted]
for dd in list_chosen:
list_value.append(dd.string)
for dt in pro.find_all('dt'):
list_name.append(dt.string)
for i in range(0, len(list_name)):
phoneProperties.update({list_name[i]: list_value[i]})
return phoneProperties爬取图片:
首先查看网页源代码:

这些蓝色的链接就是图片下载地址,只需保存在列表中,再进行下载即可。代码如下:
def getPhoneImages(phoneurl):
infoText = getHtmlText(phoneurl)
soup = BeautifulSoup(infoText, 'html.parser')
imgDiv = soup.find('div', attrs={'class': 'spec-items'})
phoneImageLink = []
for img in imgDiv.findAll('img'):
phoneImageLink.append('https:' + img.get('src'))
return phoneImageLink这时候,开始提到的那个问题出现了,这个界面没有价格信息,只有一小部分评论信息。经过查询了解到价格信息和评论信息是通过JS动态加载的,初始静态页面不显示或者显示不全。解决方法是使用浏览器的开发者模式打开页面(之前一直用的360浏览器,找了半天没找到开发者工具,坑啊……后来用了搜狗还挺方便的~)在Network里搜索price会出现获取价格的JS响应,但是拿出来的响应链接是这样的:
https://p.3.cn/prices/mgets?callback=jQuery768325&type=1&area=1_2800_2849_0.138043016&pdtk=
&pduid=933088261&pdpin=%25E4%25BD%25A0%25E6%2598%25AFsunshine%25E4%25B9%2588
&pin=%E4%BD%A0%E6%98%AFsunshine%E4%B9%88&pdbp=0&skuIds=J_3846673%2CJ_3882469
%2CJ_5005731%2CJ_3458011%2CJ_3893499%2CJ_5114365%2CJ_3728945%2CJ_4241985
%2CJ_3479621%2CJ_3882469%2CJ_5005731%2CJ_2967927%2CJ_3882453%2CJ_3355143
%2CJ_3907423%2CJ_4241985%2CJ_3479621%2CJ_3846673%2CJ_4460283%2CJ_3882469
%2CJ_4095237&ext=11000000&source=item-pc
有一点点…夸张?通过网上查询找到了个更简洁的API入口:
https://p.3.cn/prices/mgets?skuIds=J_?
其中?表示的就是京东手机的itemId。任意找个价格网址打开,内容是这样的:
这么…….简单直白的网页还是少见哈哈。这种的话用正则表达式匹配就最合适了,p标签里面的值”999.00”就是我们关心的价格啦~用正则表达式把它揪出来吧:
pattern =re.compile('"p":"(.*?)"')
price = re.findall(pattern, priceText)[0]
(这里简单说明一下:由于re.findall()方法返回的是由所有匹配的字符串组成的列表,这里只有第一个元素,故取索引[0]得到目标字符串,否则将得到只有一个字符串的列表。)
到这里剩下商品的评论列表的爬取了。同样的,所有评论信息也是动态加载的,同样在开发者模式下,Network里搜索price,下拉到评论页面,会出现一个productPageComments.action…的响应,点击进去进入评论网页:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv43344&productId=2888224&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
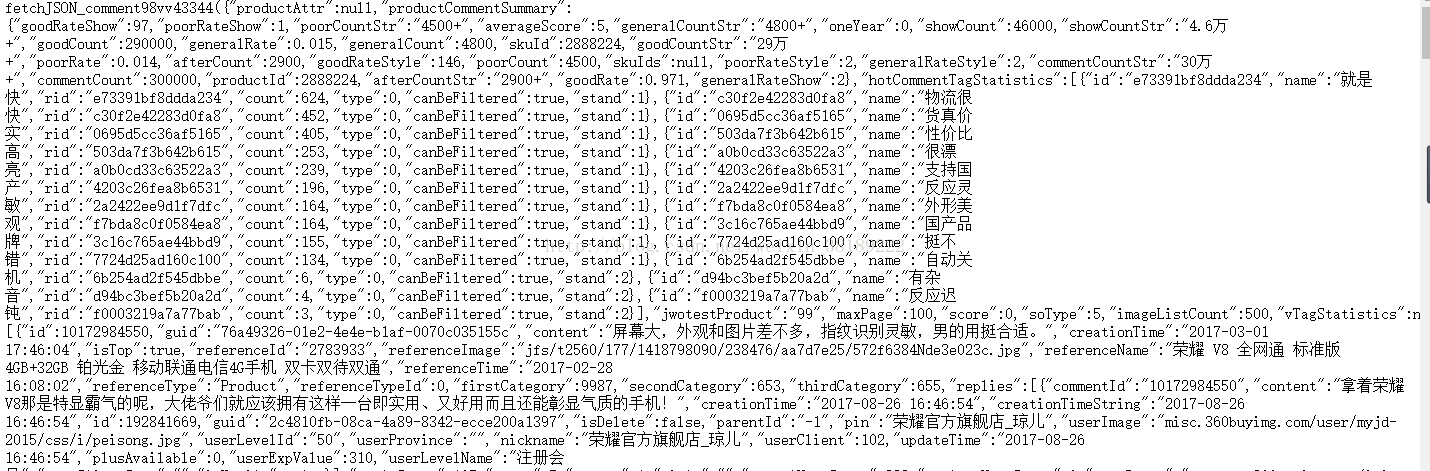
评论网页分为:1.评论摘要(好评数,就、好评率等等)2.用户的详细评论信息。这是个类json格式展现的网页(剔除前面和后面的文字),因此用json库进行信息提取是最合适的。这里的思路是:首先提取评论摘要信息,保存在字典中;其次,爬取所有具体的评论信息,每个用户的评论(包括用户昵称,评论时间,评论内容等等)保存在字典中,所有用户的评论保存在列表中。以下是代码:
def getPhoneComments(phoneurl):
phoneId = phoneurl[20:-5]
commentStartUrl = 'https://club.jd.com/comment/productPageComments.action?callback=' \
'fetchJSON_comment98vv10636&productId=' + phoneId + '&score=0&sortType=5&page=0&pageSize=10'
htmlText = getHtmlText(commentStartUrl)
jsonText = json.loads(htmlText[27:-2])
# 获取最大页面数便于爬取
maxPage = jsonText['maxPage']
# 手机评价信息概览
commentSummaryDict = {}
commentSummary = jsonText['productCommentSummary']
commentSummaryDict.update({'好评率': str(commentSummary['goodRateShow']) + '%'})
commentSummaryDict.update({'评论数': commentSummary['commentCountStr']})
commentSummaryDict.update({'晒图': jsonText['imageListCount']})
commentSummaryDict.update({'追评数': commentSummary['afterCountStr']})
commentSummaryDict.update({'好评数': commentSummary['goodCountStr']})
commentSummaryDict.update({'中评数': commentSummary['generalCountStr']})
commentSummaryDict.update({'差评数': commentSummary['poorCountStr']})
# 获取全部的评价内容
userCommentList = []
for commentPage in range(0, maxPage):
commentPageUrl = 'https://club.jd.com/comment/productPageComments.action?callback=' \
'fetchJSON_comment98vv10636&productId=' + phoneId + '&score=0&sortType=5&' \
'page=' + str(commentPage) + '&pageSize=10'
commentHtmlText = getHtmlText(commentPageUrl)
# 评论可多可少,出错就直接跳过
try:
commentJsonText = json.loads(commentHtmlText[27:-2])
comments = commentJsonText['comments']
for comment in comments:
commentsInfo = {}
commentsInfo.update({'昵称': comment['nickname']})
commentsInfo.update({'用户等级': comment['userLevelName']})
commentsInfo.update({'评论星级': str(comment['score']) + '星'})
commentsInfo.update({'内容': comment['content']})
commentsInfo.update({'机型': comment['productColor'] + ',' + comment['productSize']})
commentsInfo.update({'发表时间': comment['creationTime']})
commentsInfo.update({'点赞数': comment['usefulVoteCount']})
commentsInfo.update({'评论回复次数': comment['replyCount']})
commentsInfo.update({'是否推荐': changeRecommnedType(comment['recommend'])})
commentsInfo.update({'客户端': comment['userClientShow']})
userCommentList.append(commentsInfo)
except:
continue
print('******正在爬取第'+str(commentPage)+'页评论')
return commentSummaryDict, userCommentList我们需要的内容都已经获取完毕,接下来就是保存到文件里面,为将来数据分析做准备:
创建一个根目录,一级子目录生成以手机名称命名的文件夹,所有手机信息爬取完毕后再生成包含所有手机信息的csv文件。每个手机文件夹下的二级子目录保存评论信息和配置信息的csv文件,以及存放图片的文件夹,该文件夹下的三级子目录存放下载的手机图片。以下是结构图:

讲了这么多,再用一张图理一下思路:

最后附上所有代码:
import requests
from bs4 import BeautifulSoup
import re
import json
import csv
import os
import sys
import io
import time
from collections import OrderedDict
# 通过URL获取网页文本
def getHtmlText(url):
proxies = {'http': '114.217.129.128 8998'}
# 使用伪装浏览器和代理IP(被封了就惨了)
r = requests.get(url, headers={'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64)'}, proxies = proxies)
r.encoding = r.apparent_encoding
return r.text
# 将网页原生的是否推荐的True和False替换为是和否
def changeRecommnedType(inputBool):
if inputBool == True:
return '是'
else:
return '否'
# 生成手机1-170页的url列表(最初调用一次,全局使用)
def getAllPages():
allPagesUrlList = []
singlePageUrl = ''
for page in range(1, 171):
if page == 2:
singlePageUrl = 'https://list.jd.com/list.html?cat=9987,653,655&page=' \
+ str(page) + '&sort=sort%5Frank%5Fasc&trans=1&JL=6_0_0&ms=6#J_main'
singlePageUrl = 'https://list.jd.com/list.html?cat=9987,653,655&page=' \
+ str(page) + '&sort=sort%5Frank%5Fasc&trans=1&JL=6_0_0#J_main'
allPagesUrlList.append(singlePageUrl)
return allPagesUrlList
# 在手机概览界面网页获取手机详细信息链接
def getPhonesUrl(pageUrl):
phonesUrlList = []
html = getHtmlText(pageUrl)
soup = BeautifulSoup(html, 'html.parser')
items = soup.find_all('div',attrs={'class':'p-name'})
for item in items:
phonesUrlList.append('https:' + item.a.get('href'))
return phonesUrlList
# 获取手机价格
def getPhonePrice(phoneurl):
# 由于价格不在主页面显示,通过抓包找到显示价格的网址,以物品编号为区别特征
priceUrl = 'https://p.3.cn/prices/mgets?skuIds=J_' + phoneurl[20:-5]
priceText = getHtmlText(priceUrl)
pattern = re.compile('"p":"(.*?)"')
price = re.findall(pattern, priceText)[0]
return price
# 获取手机名称
def getPhoneName(phoneurl):
infoText = getHtmlText(phoneurl)
soup = BeautifulSoup(infoText, 'html.parser')
name = soup.find('div', attrs={'class': 'sku-name'}).get_text().strip()
return name
# 获取手机图片链接(-----还要加下载的方法-----)
def getPhoneImages(phoneurl):
infoText = getHtmlText(phoneurl)
soup = BeautifulSoup(infoText, 'html.parser')
imgDiv = soup.find('div', attrs={'class': 'spec-items'})
phoneImageLink = []
for img in imgDiv.findAll('img'):
phoneImageLink.append('https:' + img.get('src'))
return phoneImageLink
# 获取手机的属性信息
def getPhoneProperties(phoneurl):
phoneProperties = {}
list_value = []
list_name = []
infoText = getHtmlText(phoneurl)
soup = BeautifulSoup(infoText, 'html.parser')
proSection = soup.findAll('div', attrs={'class': 'Ptable-item'})
for pro in proSection:
# 既然找不到直接去除有属性标签的方法就取个差集吧
list_all = pro.find_all('dd')
list_extracted = pro.find_all('dd', {'class': 'Ptable-tips'})
list_chosen = [i for i in list_all if i not in list_extracted]
for dd in list_chosen:
list_value.append(dd.string)
for dt in pro.find_all('dt'):
list_name.append(dt.string)
for i in range(0, len(list_name)):
phoneProperties.update({list_name[i]: list_value[i]})
return phoneProperties
# 获取该买该手机的评论信息
def getPhoneComments(phoneurl):
phoneId = phoneurl[20:-5]
commentStartUrl = 'https://club.jd.com/comment/productPageComments.action?callback=' \
'fetchJSON_comment98vv10636&productId=' + phoneId + '&score=0&sortType=5&page=0&pageSize=10'
htmlText = getHtmlText(commentStartUrl)
jsonText = json.loads(htmlText[27:-2])
# 获取最大页面数便于爬取
maxPage = jsonText['maxPage']
# 手机评价信息概览
commentSummaryDict = {}
commentSummary = jsonText['productCommentSummary']
commentSummaryDict.update({'好评率': str(commentSummary['goodRateShow']) + '%'})
commentSummaryDict.update({'评论数': commentSummary['commentCountStr']})
commentSummaryDict.update({'晒图': jsonText['imageListCount']})
commentSummaryDict.update({'追评数': commentSummary['afterCountStr']})
commentSummaryDict.update({'好评数': commentSummary['goodCountStr']})
commentSummaryDict.update({'中评数': commentSummary['generalCountStr']})
commentSummaryDict.update({'差评数': commentSummary['poorCountStr']})
# 获取全部的评价内容
userCommentList = []
for commentPage in range(0, maxPage):
commentPageUrl = 'https://club.jd.com/comment/productPageComments.action?callback=' \
'fetchJSON_comment98vv10636&productId=' + phoneId + '&score=0&sortType=5&' \
'page=' + str(commentPage) + '&pageSize=10'
commentHtmlText = getHtmlText(commentPageUrl)
# 评论可多可少,出错就直接跳过
try:
commentJsonText = json.loads(commentHtmlText[27:-2])
comments = commentJsonText['comments']
for comment in comments:
commentsInfo = {}
commentsInfo.update({'昵称': comment['nickname']})
commentsInfo.update({'用户等级': comment['userLevelName']})
commentsInfo.update({'评论星级': str(comment['score']) + '星'})
commentsInfo.update({'内容': comment['content']})
commentsInfo.update({'机型': comment['productColor'] + ',' + comment['productSize']})
commentsInfo.update({'发表时间': comment['creationTime']})
commentsInfo.update({'点赞数': comment['usefulVoteCount']})
commentsInfo.update({'评论回复次数': comment['replyCount']})
commentsInfo.update({'是否推荐': changeRecommnedType(comment['recommend'])})
commentsInfo.update({'客户端': comment['userClientShow']})
userCommentList.append(commentsInfo)
except:
continue
print('******正在爬取第'+str(commentPage)+'页评论')
return commentSummaryDict, userCommentList
# 将手机的特征添加到一起
def getPhoneInfo(phoneurl):
phoneInfo = {}
price = getPhonePrice(phoneurl)
phoneInfo.update({'价格':price}) # 字符串
name = getPhoneName(phoneurl)
phoneInfo.update({'名称': name}) # 字符串
phoneImageLink = getPhoneImages(phoneurl)
phoneInfo.update({'图片链接':phoneImageLink}) # 字符串列表
phoneProperties = getPhoneProperties(phoneurl)
phoneInfo.update({'手机配置':phoneProperties}) # 字典
commentSummaryDict, userCommentList = getPhoneComments(phoneurl)
phoneInfo.update({'手机整体评价':commentSummaryDict}) # 字典
phoneInfo.update({'手机全部评价内容':userCommentList}) # 元素是字典的列表
return phoneInfo
if __name__ == '__main__':
url = 'https://list.jd.com/list.html?cat=9987,653,655&page=1&sort=sort%5Frank%5Fasc&trans=1&JL=6_0_0#J_main'
rootPath = 'E:/JDPhones/'
phoneInfoAll = []
phoneUrls = getPhonesUrl(url)
# 程序开始时间
startTime = time.clock()
for phoneurl in phoneUrls:
print('正在爬取第', str(phoneUrls.index(phoneurl) + 1), '部手机......')
info = getPhoneInfo(phoneurl)
phoneInfoAll.append(info)
phoneName = info['名称']
phoneImaLink = info['图片链接']
# 创建文件夹(先判断是否存在,因为有重复的手机)
dirPathToMake = rootPath + phoneName + '/' + 'images/'
if os.path.exists(dirPathToMake):
continue
else:
os.makedirs(dirPathToMake)
# 将图片下载到本地
for link in phoneImaLink:
imgHtml = requests.get(link, stream=True, headers={
'User-Agent': 'User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari'
'/537.36 SE 2.X MetaSr 1.0'}, proxies={'http': '114.217.129.128 8998'})
imgHtml.encoding = imgHtml.apparent_encoding
with open(rootPath + phoneName + '/' + 'images/'+ str(phoneImaLink.index(link)) + '.jpg', 'wb') as wimg:
wimg.write(imgHtml.content)
# 写入配置信息
phoneProperties = info['手机配置']
with open(rootPath + phoneName + '/' + 'properties.csv', 'w', newline='', encoding='gb18030') as wpro:
writer = csv.writer(wpro)
for key in phoneProperties.keys():
writer.writerow([key, phoneProperties[key]])
# 写入评论
commentsHeader = ['昵称', '用户等级', '评论星级', '内容', '机型', '发表时间', '点赞数', '评论回复次数',
'是否推荐', '客户端']
userCommentList = info['手机全部评价内容']
with open(rootPath + phoneName + '/' + 'comments.csv', 'w', newline='', encoding='gb18030') as wcom:
writer = csv.writer(wcom)
writer.writerow(commentsHeader)
for comment in userCommentList:
tempList = []
for commentInfo in commentsHeader:
tempList.append(comment[commentInfo])
writer.writerow(tempList)
# 去除列表中的重复元素(不保持顺序)
# 保持顺序的做法:phoneInfoAll = list(OrderedDict.fromkeys(phoneInfoAll))
phoneInfoAll = list(set(phoneInfoAll))
# 爬取所有手机信息后,做一个整体的统计分析
headers = ['名称', '价格', '好评率', '评论数', '晒图', '追评数', '好评数', '中评数', '差评数']
with open('E:/JDPhones/AllPhonesInfo.csv', 'a', newline='', encoding='gb18030') as file:
fwriter = csv.writer(file)
fwriter.writerow(headers)
for phone in phoneInfoAll:
# print(phone)
phoneInfoList = [phone['名称'], phone['价格'], phone['手机整体评价']['好评率'], phone['手机整体评价']['评论数'],
phone['手机整体评价']['晒图'], phone['手机整体评价']['追评数'], phone['手机整体评价']['好评数'],
phone['手机整体评价']['中评数'], phone['手机整体评价']['差评数']]
fwriter.writerow(phoneInfoList)
# 程序结束时间
endTime = time.clock()
print('所有手机爬取完毕,程序耗费的时间为:', endTime-startTime)