java爬虫项目实战(1)-----爬取研招网复试咨询信息
Java爬虫项目实战(1)-------爬取研招网复试咨询信息
1.简述
本科一志愿报考了某沿海经济大省的工业大学,差几分没能进入复试。因此,希望能在研招网复试咨询中找到有用的信息,及时找到招收调剂的学校。但是自己主动的去寻找调剂学校并且询问研招办老师显然费时又费力,因此就想到了通过爬虫来爬取有用的信息!

2.思路
当我们从复试咨询页面进入以后,可以看到每一页有许到的学校。随便点击一个进入该学校的主页,我们能够发现每个学校咨询的页面网络地址都又规律。
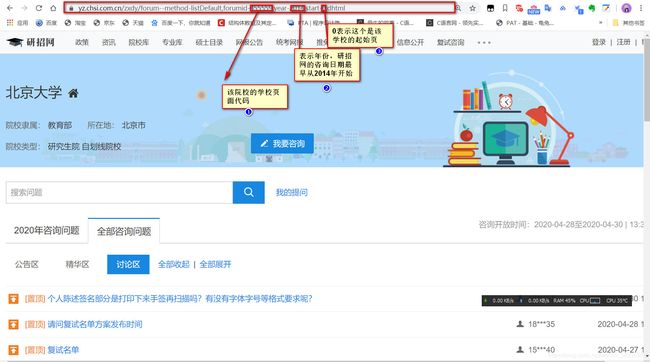
因此,我们首先可以通过爬虫爬取所有招生院校的院校代码,然后再通过拼接字符串获取自己需要年份的该院校的咨询信息。
2.1具体思路
2.1.1获取院校代码
具体过程:

每一行一共有两个学校,每一页大概25行。
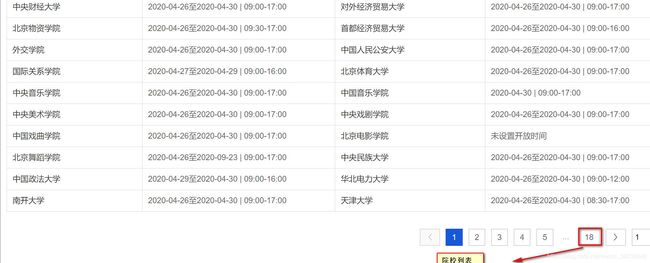
可见关于院校列表一共有18页。
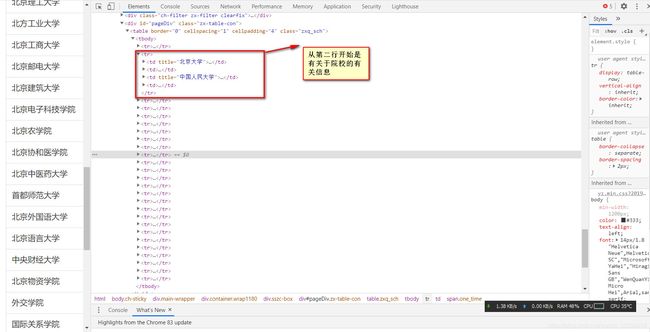

打开Chrome浏览器开发者工具,找到显示该页面的具体页面的前端代码。可以找到的每一行两个院校的具体网址。因此可以通过提取网址中的院校代码获取院校的相关信息。
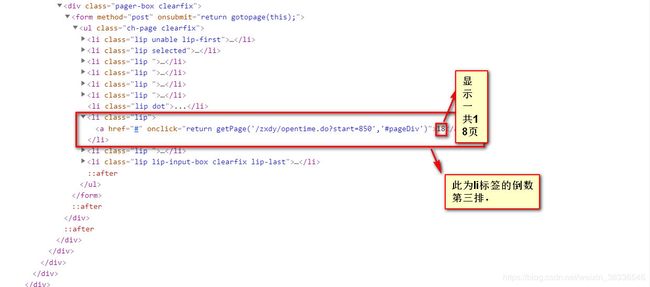
同时,我们在页面的下端,能够找到关于该关于院校列表的页面一共有18页,以及请求地址。
获取所有的院校代码和院校名称后,可以将其存入数据库中。
2.1.2获取该院校的所有咨询信息
之后,我们就可以进入每个院校的具体页面去爬取每个页面的咨询信息。
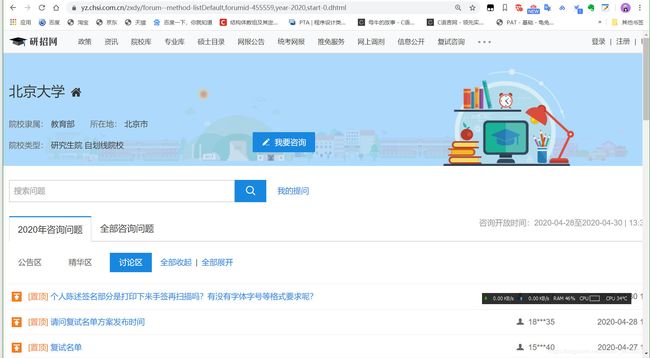

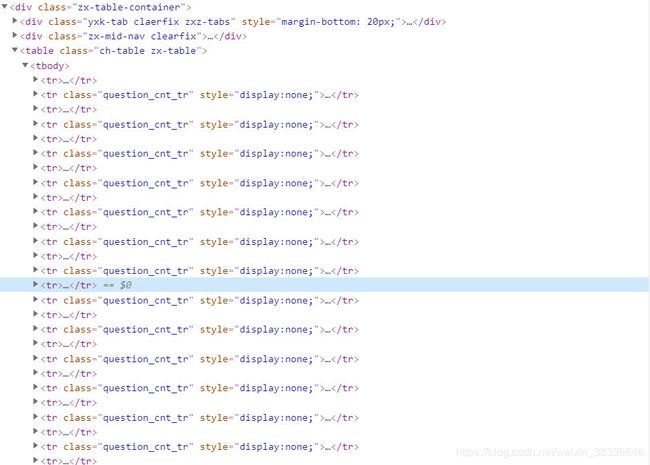
每条信息的咨询和回复隐藏tr标签元素中,因此可以通过jsoup获取每条信息的问题和回复。
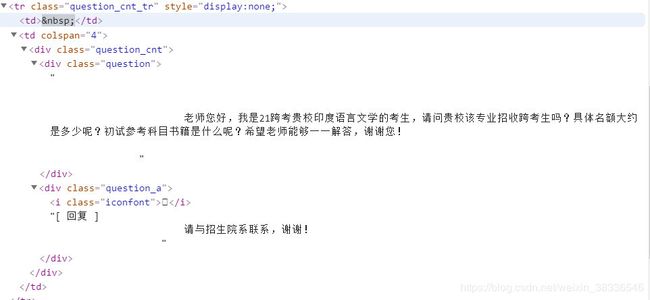
类名为question的标签内的文本内容就是询问的信息,question_a里面就是老师回复的信息。
获取每一个页面的咨询信息后,我们还要继续访问下一页。从院校的网址可以看出来,院校的咨询信息,十分有规律。
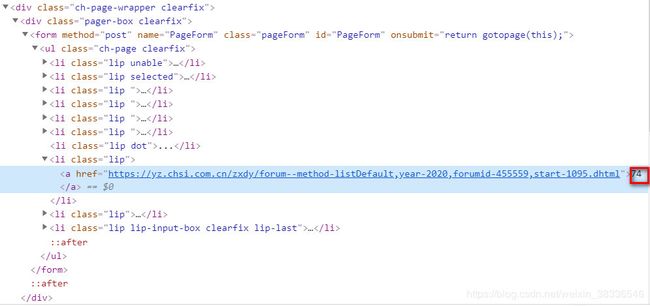
院校每一个的信息的总页面数藏在倒数第三个li标签中。从上图可以看出一共74页。start后面的数字为1095。正好74*15-15=1095.
总结起来思路为:
总结
1.获取学校代码和院校名称,存入数据库。
2.从数据库中获取要爬取院校的代码和名称,然后拼接成院校的网络地址。
3.获取院校的咨询信息,存入数据库中
3.代码
开发工具:idea、mysql、 maven jsoup
maven依赖文件:
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.13.1version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.17version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.68version>
dependency>
3.1Dao代码
DButil.java
package com.kevin.Dao;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class DButil {
static {
try {
Class.forName("com.mysql.cj.jdbc.Driver");
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static Connection con() {
Connection connection = null;
String username = "数据库用户名";
String password = "你的数据库密码";
String database = "你的数据库";
String url = "jdbc:mysql://localhost:3306/"+database+"?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false&allowPublicKeyRetrieval=true";
try {
connection = DriverManager.getConnection(url,username,password);
} catch (SQLException e) {
e.printStackTrace();
// TODO: handle exception
}
return connection;
}
public static void close(Connection conn) {
if(conn!=null) {
try {
conn.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
public static void main(String[] args) {
System.out.println("DButil");
}
}
Dao.java
public static int insertObj(String tableName,Map<String, Object> dataItem) {
// TODO Auto-generated method stub
String fieldStr = "";
String valueStr = "";
Object[] valueObjs =new Object[dataItem.size()];
int i=0;
for (String key : dataItem.keySet()) {
fieldStr = fieldStr + key + ",";
valueStr = valueStr + "?"+",";
valueObjs[i]=dataItem.get(key);
i++;
}
fieldStr = fieldStr.substring(0, fieldStr.length()-1);
valueStr = valueStr.substring(0, valueStr.length()-1);
//System.out.println(fieldStr);
//System.out.println(valueObjs);
String sqlStr = "insert into "+tableName+" ("+ fieldStr+ ") values ("+valueStr+")";
int exe = execute(sqlStr,valueObjs);
//System.out.println(exe);
return exe;
}
该代码主要是向数据库中插入数据。
3.2获取院校代码和名称具体代码
package com.kevin.Service;
import java.io.IOException;
import java.util.HashMap;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import static com.kevin.Dao.Dao.*;
public class CollectCollegeNum {
public static int cntnum =0;
public static String UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36";
public static void main(String[] args) throws IOException {
String post = "https://yz.chsi.com.cn/zxdy/opentime.do?start=";
String collegeUrl = null;
int num = 0;
for (int i = 0; i < 18; i++) {
collegeUrl = post+""+num;
getCollegeLink(collegeUrl);
num = num + 50;
}
}
public static void getCollegeLink(String url) throws IOException {
int cnt = 0;
int endIndex = 0;
String collegeUrl = null;
String collegename = null;
String num = null;
HashMap<String, Object> hashMap = new HashMap<String, Object>();
int result = 0;
Document document = Jsoup.connect(url).timeout(30000).userAgent(UserAgent).get();
// System.out.println(document);
Elements trElements = document.getElementsByTag("tr");
for (Element element : trElements) {
Elements tds=element.getElementsByTag("td");
for (Element element2 : tds) {
cnt++;
if(cnt % 2 !=0) {
collegeUrl = element2.getElementsByTag("a").attr("href");
//
collegename = element2.text();
endIndex =collegeUrl.indexOf("start");
num = collegeUrl.substring(41, endIndex-1);
System.out.println(num);
hashMap.put("collegename", collegename);
hashMap.put("collegenum", num);
result= insertObj("collegenum", hashMap);
cntnum++;
System.out.println(cntnum);
// System.out.println(cnt);
// System.out.println(collegename);
// System.out.println(collegeUrl);
// System.out.println(num);
// int startIndex = collegeUrl.indexOf("forumid-");40
// int endIndex =collegeUrl.indexOf("start");
// System.out.println(startIndex);
// System.out.println(endIndex);
}
}
}
}
}
3.3爬取具体咨询信息
package com.kevin.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import static com.kevin.Dao.Dao.*;
/**
* @author kevin xiao
* @date 2020-05
* */
public class CollectScore {
public static int cnt = 0;
public static String urlString ="https://yz.chsi.com.cn/zxdy/forum--method-listDefault,year-2014,forumid-";
public static void main(String[] args) throws IOException {
String collegename = null;
String collegenum = null;
ArrayList<HashMap<String, Object>> collegeList = new ArrayList<HashMap<String,Object>>();
/*定义sql语句查询院校的代码和名称*/
String sqlString = "select collegename,collegenum from collegenum";
/*把得到的查询结果赋值给collegeList*/
collegeList = query(sqlString);
// HashMap hashMap =collegeList.get(0);
/*遍历的到的数据*/
for (HashMap<String, Object> hashMap : collegeList) {
// System.out.println(hashMap);
/*获取院校的名称*/
collegename = (String) hashMap.get("collegename");
/*获取院校的代码*/
collegenum = (String) hashMap.get("collegenum");
// System.out.println(urlString+collegenum);
/*将的到的院校代码和之前的地址拼接在一起*/
getNextPageLink(urlString+collegenum,collegename);
}
System.out.println("结束");
}
/*获取一个学校的复试资讯页面的所有地址*/
public static void getNextPageLink(String post,String name) throws IOException {
String poString = post+",start-";
int num = 0;
String nextUrl = "";
/*得到一个院校的完整的地址*/
nextUrl = poString +num+".dhtml";
/*连接复试调剂咨询该院校的地址*/
Document document = Jsoup.connect(nextUrl).get();
String page = null;
/*得到关于页码的所有标签*/
Elements lips = document.getElementsByClass("lip");
/*获取该院校页面一共有多少页*/
if (lips.size() > 3) {
page = lips.eq(lips.size()-3).text();
} else {
page = "0";
}
/*得到该学院页面的总数*/
int cnt = Integer.parseInt(page);
/*把的到的页面完整地址赋给getInfor*/
getInfo(nextUrl,name);
for (int i = 0; i < cnt; i++) {
nextUrl = poString +num+".dhtml";
num = num + 15;
getInfo(nextUrl,name);
}
}
/*用于获得每个页面的具体考生咨询信息*/
public static void getInfo(String url,String name) throws IOException {
Document document = Jsoup.connect(url).get();
/*得到所有咨询页面问题*/
Elements question = document.getElementsByClass("question_cnt_tr");
for (Element element : question) {
cnt++;
Elements quest = element.getElementsByClass("question");
String quest_textString = quest.text();
Elements quest_a = element.getElementsByClass("question_a");
String quest_atextString = quest_a.text();
// Elements time = element.getElementsByClass("question_t ch-table-center");
HashMap<String, Object> hashMap = new HashMap<String, Object>();
hashMap.put("question", quest_textString);
hashMap.put("answer", quest_atextString);
hashMap.put("collegename", name);
int result = insertObj("score", hashMap);
}
}
}
该代码主要是爬取每个院校的具体咨询信息,存入数据库中。大概花了6个小时才爬完,大概56万条数据,效率有点点低,有进一步优化的空间。比如,将每获得一条数据就插入,改为,爬取一个页的信息后,再批量插入数据中。或者,运用多线程的方法,提供效率。
4.结束
其实最终这些信息也没有发挥太大作用,调剂还是分数为王。不过也能够算是一个能够练手的项目吧!至于考研结果,虽然遗憾与某沿海经济大省的工业大学无缘,调剂去到了隔壁省份,但是考研这一年还是收获不少东西。
再次还想说明一点的是,本人技术水平确实有限,代码的命名规范和代码的性能优化都有很大的提升空间,希望网友及时指正。还有我始终相信技术是用来服务社会的,任何事情都不能违法。此处爬取的信息,都是研招网公开的信息。
该代码主要是爬取每个院校的具体咨询信息,存入数据库中。大概花了6个小时才爬完,大概56万条数据,效率有点点低,有进一步优化的空间。比如,将每获得一条数据就插入,改为,爬取一个页的信息后,再批量插入数据中。或者,运用多线程的方法,提供效率。
[外链图片转存中...(img-XN3c6rPk-1590462508044)]
## 4.结束
其实最终这些信息也没有发挥太大作用,调剂还是分数为王。不过也能够算是一个能够练手的项目吧!至于考研结果,虽然遗憾与某沿海经济大省的工业大学无缘,调剂去到了隔壁省份,但是考研这一年还是收获不少东西。
再次还想说明一点的是,本人技术水平确实有限,代码的命名规范和代码的性能优化都有很大的提升空间,希望网友及时指正。还有我始终相信技术是用来服务社会的,任何事情都不能违法。此处爬取的信息,都是研招网公开的信息。