Stata 中的向量自回归模型(VAR)
Source: David Schenck→ Vector autoregressions in Stata
1. 引言
在单变量回归中,一个平稳的时间序列 y t y_t yt 经常被模型化为 AR 过程:
y t = α 0 + α 1 y t − 1 + α 2 y t − 2 + ⋯ + α k y t − k + ϵ t y_t=\alpha_0+\alpha_1 y_{t-1}+\alpha_2 y_{t-2}+\dots +\alpha_k y_{t-k}+\epsilon_t yt=α0+α1yt−1+α2yt−2+⋯+αkyt−k+ϵt
当我们分析多个时间序列时,一个对 AR 模型自然的拓展就是 VAR模型, 在这个模型中一组向量里的每个时间序列被模型化为决定于自己的滞后项以及这组向量里所有其他变量的滞后项。两阶 VAR 模型如下式:
y t = α 0 + α 1 y t − 1 + α 2 x t − 1 + ϵ 1 t x t = β 0 + β 1 y t − 1 + β 2 x t − 1 + ϵ 2 t y_t = \alpha_0+\alpha_1 y_{t-1}+\alpha_2 x_{t-1}+\epsilon_{1t}\\ x_t = \beta_0+\beta_1 y_{t-1}+\beta_2 x_{t-1}+\epsilon_{2t} yt=α0+α1yt−1+α2xt−1+ϵ1txt=β0+β1yt−1+β2xt−1+ϵ2t
经济学家通常使用这种形式的模型分析宏观数据、做出因果推断并提供政策建议。
在这篇推文中,我会用美国失业率、通胀率以及名义利率估计一个三变量 VAR 模型。这个 VAR 模型类似于宏观经济中做货币政策分析的模型。这篇文章的主要关注点在于该模型的基本估计和估计结果评估,数据和 do 文件在文末提供。背景知识和理论细节可以在这篇文章中获得。
2. 数据和估计
当使用 VAR 模型进行估计时,我们需要做两个决定。第一个是需要选择将那些变量放入 VAR 模型中,这个决定一般取决于研究问题和相关文献。第二个决定是需要选择滞后阶数。决定了滞后阶数后,就可以开始估计。得到估计结果后,需要对结果进行评估分析看其是否符合模型设定。
本文使用 1995-2005 年间美国失业率、CPI和短期名义利率的季度观测值对模型进行估计,数据来源于联邦经济数据库。在 stata 数据集中,inflation为CPI,unrate 为失业率,ffr则表示利率。因此,本文估计的 VAR 模型为:
a 0 a_0 a0是由截距项组成的向量, A 1 A_1 A1 到 A K A_K AK 均为 3 × 3 3\times 3 3×3 的系数矩阵。包含这些变量的 VAR 模型或相近的模型变体经常出现在货币政策分析中。
下一步是决定一个合理的滞后阶数,我使用 varsoc 命令执行滞后结束选择测试。
. varsoc inflation unrate ffr, maxlag(8)
Selection-order criteria
Sample: 41 - 236 Number of obs = 196
+---------------------------------------------------------------------------+
|lag | LL LR df p FPE AIC HQIC SBIC |
|----+----------------------------------------------------------------------|
| 0 | -1242.78 66.5778 12.712 12.7323 12.7622 |
| 1 | -433.701 1618.2 9 0.000 .018956 4.54796 4.62922 4.74867 |
| 2 | -366.662 134.08 9 0.000 .010485 3.95574 4.09793 4.30696* |
| 3 | -351.034 31.257 9 0.000 .009801 3.8881 4.09123 4.38985 |
| 4 | -337.734 26.6 9 0.002 .009383 3.84422 4.1083 4.4965 |
| 5 | -319.353 36.763 9 0.000 .008531 3.7485 4.07351 4.5513 |
| 6 | -296.967 44.77* 9 0.000 .007447* 3.61191* 3.99787* 4.56524 |
| 7 | -292.066 9.8034 9 0.367 .007773 3.65373 4.10063 4.75759 |
| 8 | -286.45 11.232 9 0.260 .008057 3.68826 4.1961 4.94265 |
+---------------------------------------------------------------------------+
Endogenous: inflation unrate ffr
Exogenous: _cons
varsoc 展示了之后滞后阶数选择检验的主要结果,检验的细节可以通过 help varsoc 得到。似然比和 AIC 都推荐选择六阶滞后,因此本文选择六阶滞后。
有了变量和滞后阶数,需要估计系数矩阵和误差项的协方差矩阵。系数估计可以通过对 VAR 模型中的每个等式做 OLS 回归得到,误差项的协方差矩阵则需要根据样本残差的协方差矩阵进行估计。var命令可以同时实现这两个矩阵的估计,其结果中系数矩阵会默认给出,误差项的协方差矩阵则可以 e(Sigma) 中找到:
. var inflation unrate ffr, lags(1/6) dfk small
Vector autoregression
Sample: 39 - 236 Number of obs = 198
Log likelihood = -298.8751 AIC = 3.594698
FPE = .0073199 HQIC = 3.97786
Det(Sigma_ml) = .0041085 SBIC = 4.541321
Equation Parms RMSE R-sq F P > F
----------------------------------------------------------------
inflation 19 .430015 0.9773 427.7745 0.0000
unrate 19 .252309 0.9719 343.796 0.0000
ffr 19 .795236 0.9481 181.8093 0.0000
----------------------------------------------------------------
------------------------------------------------------------------------------
| Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
inflation |
inflation |
L1. | 1.37357 .0741615 18.52 0.000 1.227227 1.519913
L2. | -.383699 .1172164 -3.27 0.001 -.6150029 -.1523952
L3. | .2219455 .1107262 2.00 0.047 .0034489 .440442
L4. | -.6102823 .1105383 -5.52 0.000 -.8284081 -.3921565
L5. | .6247347 .1158098 5.39 0.000 .3962065 .8532629
L6. | -.2352624 .0719141 -3.27 0.001 -.3771708 -.093354
|
unrate |
L1. | -.4638928 .1386526 -3.35 0.001 -.7374967 -.1902889
L2. | .6567903 .2370568 2.77 0.006 .1890049 1.124576
L3. | -.271786 .2472491 -1.10 0.273 -.759684 .2161119
L4. | -.4545188 .2473079 -1.84 0.068 -.9425328 .0334952
L5. | .6755548 .2387697 2.83 0.005 .2043893 1.14672
L6. | -.1905395 .136066 -1.40 0.163 -.4590393 .0779602
|
ffr |
L1. | .1135627 .0439648 2.58 0.011 .0268066 .2003187
L2. | -.1155366 .0607816 -1.90 0.059 -.2354774 .0044041
L3. | .0356931 .0628766 0.57 0.571 -.0883817 .1597678
L4. | -.0928074 .0620882 -1.49 0.137 -.2153263 .0297116
L5. | .0285487 .0605736 0.47 0.638 -.0909816 .1480789
L6. | .0309895 .0436299 0.71 0.478 -.0551055 .1170846
|
_cons | .3255765 .1730832 1.88 0.062 -.0159696 .6671226
-------------+----------------------------------------------------------------
unrate |
inflation |
L1. | .0903987 .0435139 2.08 0.039 .0045326 .1762649
L2. | -.1647856 .0687761 -2.40 0.018 -.3005019 -.0290693
L3. | .0502256 .064968 0.77 0.440 -.0779761 .1784273
L4. | .0919702 .0648577 1.42 0.158 -.036014 .2199543
L5. | -.0091229 .0679508 -0.13 0.893 -.1432106 .1249648
L6. | -.0475726 .0421952 -1.13 0.261 -.1308366 .0356914
|
unrate |
L1. | 1.511349 .0813537 18.58 0.000 1.350814 1.671885
L2. | -.5591657 .1390918 -4.02 0.000 -.8336363 -.2846951
L3. | -.0744788 .1450721 -0.51 0.608 -.3607503 .2117927
L4. | -.1116169 .1451066 -0.77 0.443 -.3979565 .1747227
L5. | .3628351 .1400968 2.59 0.010 .0863813 .639289
L6. | -.1895388 .079836 -2.37 0.019 -.3470796 -.031998
|
ffr |
L1. | -.022236 .0257961 -0.86 0.390 -.0731396 .0286677
L2. | .0623818 .0356633 1.75 0.082 -.0079928 .1327564
L3. | -.0355659 .0368925 -0.96 0.336 -.1083661 .0372343
L4. | .0184223 .0364299 0.51 0.614 -.0534651 .0903096
L5. | .0077111 .0355412 0.22 0.828 -.0624226 .0778449
L6. | -.0097089 .0255996 -0.38 0.705 -.0602247 .040807
|
_cons | .187617 .1015557 1.85 0.066 -.0127834 .3880173
-------------+----------------------------------------------------------------
ffr |
inflation |
L1. | .1425755 .1371485 1.04 0.300 -.1280603 .4132114
L2. | .1461452 .2167708 0.67 0.501 -.2816098 .5739003
L3. | -.0988776 .2047683 -0.48 0.630 -.502948 .3051928
L4. | -.4035444 .2044208 -1.97 0.050 -.8069291 -.0001598
L5. | .5118482 .2141696 2.39 0.018 .0892262 .9344702
L6. | -.1468158 .1329922 -1.10 0.271 -.40925 .1156184
|
unrate |
L1. | -1.411603 .2564132 -5.51 0.000 -1.917585 -.9056216
L2. | 1.525265 .4383941 3.48 0.001 .660179 2.39035
L3. | -.6439154 .4572429 -1.41 0.161 -1.546195 .2583646
L4. | .8175053 .4573517 1.79 0.076 -.0849893 1.72
L5. | -.344484 .4415619 -0.78 0.436 -1.21582 .5268524
L6. | .0366413 .2516297 0.15 0.884 -.459901 .5331835
|
ffr |
L1. | 1.003236 .0813051 12.34 0.000 .8427961 1.163676
L2. | -.4497879 .1124048 -4.00 0.000 -.6715968 -.2279789
L3. | .4273715 .1162791 3.68 0.000 .1979173 .6568256
L4. | -.0775962 .114821 -0.68 0.500 -.3041731 .1489807
L5. | .259904 .1120201 2.32 0.021 .0388542 .4809538
L6. | -.2866806 .0806857 -3.55 0.000 -.445898 -.1274631
|
_cons | .2580589 .3200865 0.81 0.421 -.3735695 .8896873
------------------------------------------------------------------------------
. matlist e(Sigma)
| inflation unrate ffr
-------------+---------------------------------
inflation | .1849129
unrate | -.0064425 .0636598
ffr | .0788766 -.09169 .6324
var命令的报告结果以矩阵形式报告,每个方程以其因变量的名字命名,因此会报告三个方程:通胀方程、失业率方程以及利率方程。 e(Sigma) 中则保存 VAR 模型估计残差的协方差矩阵。注意各个方程的残差相关。
如你所见,估计系数表格非常长。即使不考虑常数项,一个有 n n n 个变量和 k k k 阶滞后的 VAR 模型中也会有 k n 2 kn^2 kn2 个系数。我们的 3 变量,6 阶滞后的 VAR 则有将近 60 个系数,但是我们却仅有 198 个观测。 选项 dfk 和 small 将对默认情形下报告的大样本统计量进行小样本调整。虽然结果会报告系数、标准误、 t t t 统计量、 p p p统计量等,但是并不能给我们直观的信息含量,因此很多论文甚至都不会报告这些系数表格,但是他们会报告一些更有信息量的统计量。接下来的两部分将会介绍两个 VAR 结果分析中常用的统计手段:格兰杰因果检验和脉冲响应函数。
3. 评价 VAR 结果:格兰杰因果检验
如果给定 y t y_t yt 的滞后阶数, x t x_t xt的滞后滞后项在以 y t y_t yt 为因变量的方程中联合统计显著,则称 x t x_t xt 是 y t y_t yt 的格兰杰原因 。例如,如果利率滞后项对失业率是联合显著的,则可以称利率是失业率的格兰杰原因。vargranger 命令可以进行格兰杰因果检验。
. quietly var inflation unrate ffr, lags(1/6) dfk small
. vargranger
Granger causality Wald tests
+------------------------------------------------------------------------+
| Equation Excluded | F df df_r Prob > F |
|--------------------------------------+---------------------------------|
| inflation unrate | 3.5594 6 179 0.0024 |
| inflation ffr | 1.6612 6 179 0.1330 |
| inflation ALL | 4.6433 12 179 0.0000 |
|--------------------------------------+---------------------------------|
| unrate inflation | 2.0466 6 179 0.0618 |
| unrate ffr | 1.2751 6 179 0.2709 |
| unrate ALL | 3.3316 12 179 0.0002 |
|--------------------------------------+---------------------------------|
| ffr inflation | 3.6745 6 179 0.0018 |
| ffr unrate | 7.7692 6 179 0.0000 |
| ffr ALL | 5.1996 12 179 0.0000 |
+------------------------------------------------------------------------+
像之前一样,方程之间通过被解释变量进行区分。对于每个方程,vargranger 都可以先单独检验每个变量在 VAR 模型中的因果关系,然后检验所有变量整体的格兰杰因果关系。在对失业率方程进行的格兰杰因果检验中,如上表所示,“ffr excluded” 检验的原假设是所有利率及其滞后项的系数在对失业率的预测中均为 0 ,备择假设是至少有一个不为 0 。 p p p 值为 0.27 并未落在 5% 显著性水平的拒绝域内,因此我们不能拒绝利率不会影响失业率的原假设,也就是说我们的数据和模型不支持利率是失业率的格兰杰原因的假设。相反地,在利率方程中,通胀和失业率的滞后项都是统计显著的,因此可以说通胀和失业率是利率的格兰杰原因。
每个方程中“all excluded” 行都剔除了全部的滞后项,在方程中只留了自相关系数,这是一个对方程中其他所有滞后项的统计显著性的检验,它可以被当做是一个纯粹的自回归模型设定(原假设)和 VAR 模型设定(备择假设)之间的检验。
你可以通过对每个方程跑 OLS 回归然后使用 test 命令检验相应的原假设来得到与格兰杰因果检验相同的结果,其结果与 vargranger 命令得到的结果应该是匹配的:
. quietly regress unrate l(1/6).unrate l(1/6).ffr l(1/6).inflation
. test l1.inflation=l2.inflation=l3.inflation
> =l4.inflation=l5.inflation=l6.inflation=0
( 1) L.inflation - L2.inflation = 0
( 2) L.inflation - L3.inflation = 0
( 3) L.inflation - L4.inflation = 0
( 4) L.inflation - L5.inflation = 0
( 5) L.inflation - L6.inflation = 0
( 6) L.inflation = 0
F( 6, 179) = 2.05
Prob > F = 0.0618
. test l1.ffr=l2.ffr=l3.ffr=l4.ffr=l5.ffr=l6.ffr=0
( 1) L.ffr - L2.ffr = 0
( 2) L.ffr - L3.ffr = 0
( 3) L.ffr - L4.ffr = 0
( 4) L.ffr - L5.ffr = 0
( 5) L.ffr - L6.ffr = 0
( 6) L.ffr = 0
F( 6, 179) = 1.28
Prob > F = 0.2709
4. 评价 VAR 模型结果:脉冲响应分析
评价 VAR 模型结果的第二个统计手段是对系统施加一些外生冲击,然后看这些冲击对于内生变量的影响。但是需要记住系统的每个方程的冲击之间并不是相互独立的,因此就我们现有模型而言,当我们讨论一个对通胀的冲击时,其结果常常是模糊的,因为这个冲击也会同时影响该方程中利率和失业率及其滞后项。
. matlist e(Sigma)
| inflation unrate ffr
-------------+---------------------------------
inflation | .1849129
unrate | -.0064425 .0636598
ffr | .0788766 -.09169 .6324
解决这个问题的一个方法是假设存在一个结构性冲击向量 u t u_t ut ,定义其其分量相互独立,并且这个冲击向量与原来的冲击之间存在如下关系:
ϵ t = A u t E ( u t u t ′ ) = I \epsilon_t=A u_t\\ E(u_t u'_t)=I ϵt=AutE(utut′)=I
如果我们定义误差项的协方差矩阵为 Σ \Sigma Σ ,则矩阵 A 与 Σ \Sigma Σ 之间的关系为:
Σ = E ( ϵ t ϵ t ′ ) = E ( A u t u t ′ A ′ ) = A E ( u t u t ′ ) A ′ = A A ′ \Sigma = E(\epsilon_t \epsilon'_t)=E(A u_t u'_t A')=AE(u_t u'_t )A'=AA' Σ=E(ϵtϵt′)=E(Autut′A′)=AE(utut′)A′=AA′
因为我们有从样本估计出的协方差矩阵 Σ ^ \hat{\Sigma} Σ^ ,我们于是可以由以上等式构造出 A ^ \hat{A} A^ :
(1) Σ ^ = A ^ A ′ ^ \hat{\Sigma} = \hat{A} \hat{A'} \tag{1} Σ^=A^A′^(1)
很多 A A A 矩阵都满足方程 (1) 。一种可能的方法是假设 A A A 是一个下三角矩阵,则 A A A 即可以通过对 Σ \Sigma Σ 进行 Cholesky 分解得到。这种分解方法非常常见,因此使用 var 命令时可以直接指定使用 Cholesky 分解。
对矩阵 A A A 做出下三角的假设在 VAR 模型的变量的顺序做出了要求,因为不同的顺序将会得到不同的 A A A 。变量顺序的经济学含义是对任意一个方程,其因变量都会被顺序在其之前变量的冲击影响,而不会被顺序在其之后的变量影响。对于这篇推文,我会对我们所用变量的顺序做出如下的设定:通胀冲击可以同期影响所有三个变量;失业率冲击只会同期影响利率,但不会影响通胀;利率冲击顺序在最后,因此既不会同期影响失业率,也不会同期影响通胀。
有了 A A A ,我们就可以制造方程间相互独立的冲击并且在 VAR 模型中观察这些冲击对变量施加的影响了。我们可以通过 irf create 命令建立脉冲响应方程,然后使用 irf graph 命令对脉冲响应结果画图。
. quietly var inflation unrate ffr, lags(1/6) dfk small
. irf create var1, step(20) set(myirf) replace
(file myirf.irf now active)
(file myirf.irf updated)
. irf graph oirf, impulse(inflation unrate ffr) response(inflation unrate ffr)
> yline(0,lcolor(black)) xlabel(0(4)20) byopts(yrescale)
在跑出 VAR 之后,irf create 命令会创建一个 .irf 文件来保存 VAR 模型的结果。多个不同的 VAR 结果会被分别保存在不同的文件找那个,因此我们需要给每个 VAR 命名,在我们的例子中我们命名为 var1 。 set( ) 选项给 .irf’ 文件命名并将该文件设置为“活动的”。 .irf’ 文件将在之后的分析中使用。 step(20) 选项则指定 irf create 命令去获得 20 期的脉冲响应结果。
irf graph 命令根据 .irf’ 文件中的某些统计量画图。在该文件中的众多统计量中,我们对正交脉冲响应方程最感兴趣,因此我们在 irf graph 命令后指定 oirf。impulse( ) 和 response( ) 选项则分别指定对以哪些方程为自变量的方程造成冲击,以及对哪些变量需要绘图,这里我们将对所有变量进行冲击并绘图,脉冲响应图如下:
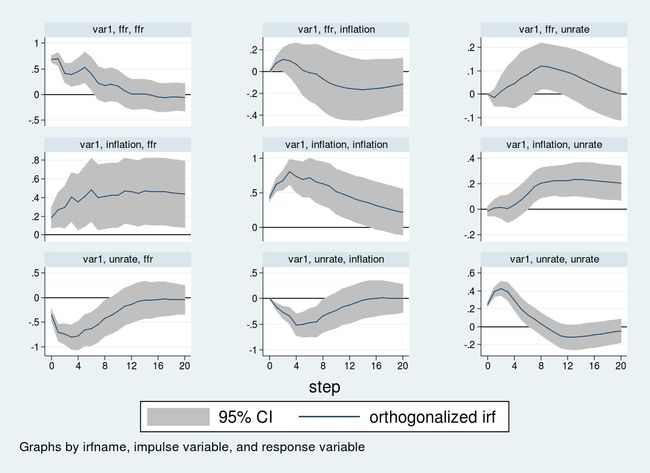
脉冲响应图每行放置同一冲击的影响,每列放置同一受冲击影响的变量。每张图的横轴是 VAR 的时间轴,在这里时间单位为季度,因此这里显示的是冲击在未来 20 个季度之内的影响。纵轴为 VAR 模型中的变量,由于数据中每个变量都使用百分比来衡量,因此在所有面板中纵轴表示的都是百分比的变化。
第一行表示的是一个单位的利率冲击对系统的影响。对利率的影响是持续的,并且在冲击开始后的 12 个季度内都保持在较高的水平;通胀在 8 个季度后有轻微下降,但是该冲击对通胀的影响在任意时间段内都是不显著的;失业率在12个月后有轻微下降,在下降之前最高会有 0.2% 的增加。
第二行则给出了通胀冲击对系统的影响。一个未预期到的通胀冲击将给失业率和利率带来持续正的影响,并且该冲击的影响在冲击发生 5 年后依然显著。
最后,第三行展示了失业率冲击对系统的影响。失业率冲击将会导致通胀率在冲击发生后一年内下降约 0.5 个百分点,利率则在同样时间段内下降约 1 个百分点。
这里使用的 VAR 和顺序都很清楚。所有的推断都基于 A A A 矩阵,也就是 VAR 模型中变量的顺序。不同的顺序会产生不同的 A A A 矩阵,从而得到不同的脉冲响应结果。此外,除了简单地指定变量顺序外,还有别的识别策略,我将在知乎的推文中讨论。
结论
在这篇推文中,我们估计了一个 VAR 模型并讨论了该模型中两个常见的统计工具:格兰杰因果检验和脉冲响应分析。在我们的下一篇推文中,我们会对脉冲响应方程进行更深的讨论并给出对 VAR 模型进行结构推断的其他方法。