Lucene的使用,Lucene入门
本文主要介绍几个方面,为什么使用Lucene使用场景,解决的问题,Lucene的入门使用,以及Lucene一些语法(增删改查)。
一简述Lucene概念:磁盘上的一些邮件,文档等各种文件,通过工具,把其变得有结构性,就是他们的信息扫描,记录位置,记录内容,建成索引。这样你就可以通过这些索引快速找到这些文件位置以及想要的内容。就像查字典一样,字典的拼音表和部首检字表就相当于字典的索引,按着拼音或者偏旁部首查,会很快,不用自己从头找到尾......,Lucene就是这样的一个工具,他帮我们建了字典的查询目录,就是索引。我们把这个技术叫做全文检索。
二:一些使用场景:Lucene是apache下的一个开放源代码的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能。对于数据量大、数据结构不固定的数据可采用全文检索方式搜索,比如百度、Google等搜索引擎、博客,论坛站内搜索、电商网站站内搜索等。
三:Lucene实现索引检索的流程:
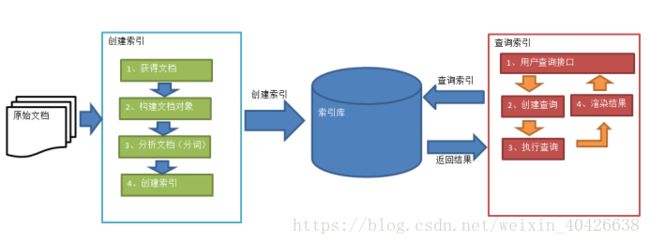
绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,就是通过获取原始文件信息,创建索引,把索引放到索引库,这个索引库需要你自己制定存放目录:索引过程包括:确定原始内容(即要搜索的内容),采集文档,创建文档,分析文档,索引文档 。
红色表示搜索过程,从索引库中搜索内容,搜索过程包括:用户通过搜索界面创建查询执行搜索,从索引库搜索渲染搜索结果。这里的搜索界面Lucene并不提供,不过有很多这种客户端。我们一般通过程序实现索引的搜索。
四:使用Java实现Lucene的增删改查,(这里不需要安装Lucene客户端),只需代码操作,如图引入相关jar包,包括中文分词,Lucene搜索语法用的包,测试包等:
编写创建索引的代码:
@Test
public void createIndex() throws Exception {
//指定索引库存放的路径//D:\temp\0108\index
Directory directory = FSDirectory.open(new File("D:\\lucene\\index"));
//创建一个标准分析器
Analyzer analyzer = new StandardAnalyzer();
//创建indexwriterCofig对象,第一个参数: Lucene的版本信息,可以选择对应的lucene版本也可以使用LATEST
//第二根参数:分析器对象
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);
//创建indexwriter对象
IndexWriter indexWriter = new IndexWriter(directory, config);
//原始文档的路径
File dir=new File("D:\\data\\lucene\\资料");
for (File f : dir.listFiles()) {
//文件名
String fileName = f.getName();
//文件内容
String fileContent = FileUtils.readFileToString(f);
//文件路径
String filePath = f.getPath();
//文件的大小
long fileSize = FileUtils.sizeOf(f);
//创建文件名域
//第一个参数:域的名称,第二个参数:域的内容,第三个参数:是否存储
Field fileNameField = new TextField("filename", fileName, Store.YES);
//文件内容域
Field fileContentField = new TextField("content", fileContent, Store.YES);
//文件路径域(不分析、不索引、只存储)
Field filePathField = new StoredField("path", filePath);
//文件大小域
Field fileSizeField = new LongField("size", fileSize, Store.YES);
//创建document对象
Document document = new Document();
document.add(fileNameField);
document.add(fileContentField);
document.add(filePathField);
document.add(fileSizeField);
//创建索引,并写入索引库
indexWriter.addDocument(document);
}
//关闭indexwriter
indexWriter.close();
}实现简单搜索测试
private IndexSearcher getIndexSearcher() throws Exception {
//指定索引库存放的路径
Directory directory = FSDirectory.open(new File("C:\\temp\\index"));
//创建一个IndexReader对象
IndexReader indexReader = DirectoryReader.open(directory);
//创建IndexSearcher对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
return indexSearcher;
}
private void printResult(IndexSearcher indexSearcher, Query query) throws Exception {
//查询索引库
TopDocs topDocs = indexSearcher.search(query, 100);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
System.out.println("查询结果总记录数:" + topDocs.totalHits);
//遍历查询结果
for (ScoreDoc scoreDoc : scoreDocs) {
int docId = scoreDoc.doc;
//通过id查询文档对象
Document document = indexSearcher.doc(docId);
//取属性
System.out.println(document.get("name"));
System.out.println(document.get("size"));
System.out.println(document.get("content"));
System.out.println(document.get("path"));
}
//关闭索引库
indexSearcher.getIndexReader().close();
}索引的删除与修改
@Test
public void deleteAllIndex() throws Exception {
Directory directory = FSDirectory.open(new File("D:\\data\\资料\\lucene&solr\\index"));
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, new IKAnalyzer());
// 创建一个indexwriter对象
IndexWriter indexWriter = new IndexWriter(directory, config);
// 删除全部索引
indexWriter.deleteAll();
// 关闭indexwriter
indexWriter.close();
}
// 根据查询条件删除索引
@Test
public void deleteIndexByQuery() throws Exception {
Directory directory = FSDirectory.open(new File("D:\\data\\index"));
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, new IKAnalyzer());
// 创建一个indexwriter对象
IndexWriter indexWriter = new IndexWriter(directory, config);
// 创建一个查询条件
Query query = new TermQuery(new Term("filename", "apache"));
// 根据查询条件删除
indexWriter.deleteDocuments(query);
// 关闭indexwriter
indexWriter.close();
}
//修改索引库
@Test
public void updateIndex() throws Exception {
Directory directory = FSDirectory.open(new File("D:\\dataindex"));
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, new IKAnalyzer());
// 创建一个indexwriter对象
IndexWriter indexWriter = new IndexWriter(directory, config);
//创建一个Document对象
Document document = new Document();
//向document对象中添加域。
//不同的document可以有不同的域,同一个document可以有相同的域。
document.add(new TextField("filename", "要更新的文档", Store.YES));
document.add(new TextField("content", "2013年11月18日 - Lucene 简介 Lucene 是一个基于 Java 的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。", Store.YES));
indexWriter.updateDocument(new Term("content", "java"), document);
//关闭indexWriter
indexWriter.close();
}Lucene的查询
private IndexSearcher getIndexSearcher() throws Exception {
//指定索引库存放的路径
Directory directory = FSDirectory.open(new File("C:\\temp\\index"));
//创建一个IndexReader对象
IndexReader indexReader = DirectoryReader.open(directory);
//创建IndexSearcher对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
return indexSearcher;
}
private void printResult(IndexSearcher indexSearcher, Query query) throws Exception {
//查询索引库
TopDocs topDocs = indexSearcher.search(query, 100);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
System.out.println("查询结果总记录数:" + topDocs.totalHits);
//遍历查询结果
for (ScoreDoc scoreDoc : scoreDocs) {
int docId = scoreDoc.doc;
//通过id查询文档对象
Document document = indexSearcher.doc(docId);
//取属性
System.out.println(document.get("name"));
System.out.println(document.get("size"));
System.out.println(document.get("content"));
System.out.println(document.get("path"));
}
//关闭索引库
indexSearcher.getIndexReader().close();
}
@Test
public void testMatchAllDocsQuery() throws Exception {
//指定索引库存放的路径
Directory directory = FSDirectory.open(new File("C:\\temp\\index"));
//创建一个IndexReader对象
IndexReader indexReader = DirectoryReader.open(directory);
//创建IndexSearcher对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//创建一个Query对象
Query query = new MatchAllDocsQuery();
System.out.println(query);
//查询索引库
TopDocs topDocs = indexSearcher.search(query, 100);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
System.out.println("查询结果总记录数:" + topDocs.totalHits);
//遍历查询结果
for (ScoreDoc scoreDoc : scoreDocs) {
int docId = scoreDoc.doc;
//通过id查询文档对象
Document document = indexSearcher.doc(docId);
//取属性
System.out.println(document.get("name"));
System.out.println(document.get("size"));
System.out.println(document.get("content"));
System.out.println(document.get("path"));
}
//关闭索引库
indexReader.close();
}
@Test
public void testNumericRangeQuery() throws Exception {
//创建一个数值范围查询对象
//参数1:要查询的域 参数2:最小值 参数3:最大值 参数4:是否包含最小值 参数5:是否包含最大值
Query query = NumericRangeQuery.newLongRange("size", 1000l, 10000l, false, true);
System.out.println(query);
//打印结果
printResult(getIndexSearcher(), query);
}
@Test
public void testBooleanQuery() throws Exception {
//创建一个BooleanQuery对象
BooleanQuery query = new BooleanQuery();
//创建子查询,文件大于1000小于10000
// Query query1 = NumericRangeQuery.newLongRange("size", 1000l, 10000l, true, true);
Query query1 = new TermQuery(new Term("name", "lucene"));
//文件名中包含mybatis关键字
Query query2 = new TermQuery(new Term("name", "apache"));
//添加到BooleanQuery对象中
query.add(query1, Occur.MUST);
query.add(query2, Occur.MUST_NOT);
System.out.println(query);
//执行查询
printResult(getIndexSearcher(), query);
}
@Test
public void testQueryParser() throws Exception {
//创建一个QueryParser对象。参数1:默认搜索域 参数2:分析器对象。
QueryParser queryParser = new QueryParser("content", new IKAnalyzer());
//调用parse方法可以获得一个Query对象
//参数:要查询的内容,可以是一句话。先分词在查询
Query query = queryParser.parse("mybatis is a apache project");
// Query query = queryParser.parse("name:lucene OR name:apache");
System.out.println(query);
printResult(getIndexSearcher(), query);
}
@Test
public void testMultiFileQueryParser() throws Exception {
//指定默认搜索域
String[] fields ={"name", "content"};
MultiFieldQueryParser queryParser = new MultiFieldQueryParser(fields, new IKAnalyzer());
Query query = queryParser.parse("mybatis is a apache project");
System.out.println(query);
printResult(getIndexSear