利用DTW算法对声音信号的MFCC特征矢量矩阵进行模式匹配
利用DTW算法对声音信号的MFCC特征矢量矩阵进行模式匹配
该部分主要阐述了完整的语音信号处理的算法内容,其中包括语音信号预处理(信号分帧),端点检测,预加重,加窗,计算MFCC矩阵以及进行声音的识别匹配的DTW算法。接下来将按处理的流程进行阐释:
一、预处理
预处理的内容包括:
1、对于声音信号,人为的设定每一帧的帧时长fram_time(一般为20ms~40ms,本程序中设定为20ms)以及帧移系数fram_mov_rito(即相邻帧之间重叠的时长,本程序中设定帧移系数为0.5即10ms)。既定的声音信号的采样率fs(由录音设备决定,算法中初始定义为8000HZ)将决定每一帧应该包含多少个采样点。根据帧长与帧移可知,信号总点数L有L=K*1-fram_mov_rito*fram_time*fs=80*K
即总点数应该是80个采样点的整数倍。
然而由于读取的声音信号长度不为整,因此需要对长度进行修剪修剪为最接近80的整数倍的值。考虑到声音可能在结束的时候未停止,即包含的尾音,因此从声音信号的起始点进行剪裁。代码处理如下:
fscanf_s(fp, "%d", &voice_end);
useless= fgetc(fp);
for (con = 0;con
{
fscanf_s(fp, "%lf", (y+ con));
useless = fgetc(fp);
}
//声音信号结束点为voice_end
for (voice_length = voice_end;voice_length % 160 != 0;voice_length--);
voice_start = voice_end - voice_length;
//声音信号长度为voice_length起始点为voice_start
y1 = y + voice_start - 1; //将声音起始指针指向起始点
2、录制的声音信号都不可避免的会有噪音干扰。为了能够不让噪声影响声音信号的端点检测以及特征向量的提取,必须在处理信号之前进行降噪处理。由于在无录音人人身时的背景噪音基本属于高斯白噪声,因此可以对噪声段进行时域均值滤波即可达到不不错的降噪效果。在这,本算法的改动在于,这里的“降噪”并不是真正意义上的将噪声降为0,而是通过对噪声的幅值计算均值(并不是信号的算术均值),并且将信号区分正负后加上(或减去)幅值的均值,可以通过Matlab的plot输出发现,噪声都被强行拉至一个相对平稳的水平,这对于之后的端点检测有很大帮助。另外,本算法设定取10帧即200ms的语音时长为噪声段,在提取噪声的时候从第2480个采样点开始计算,刻意规避了在录音设备刚启动时带来的噪声。代码处理如下
效果图:

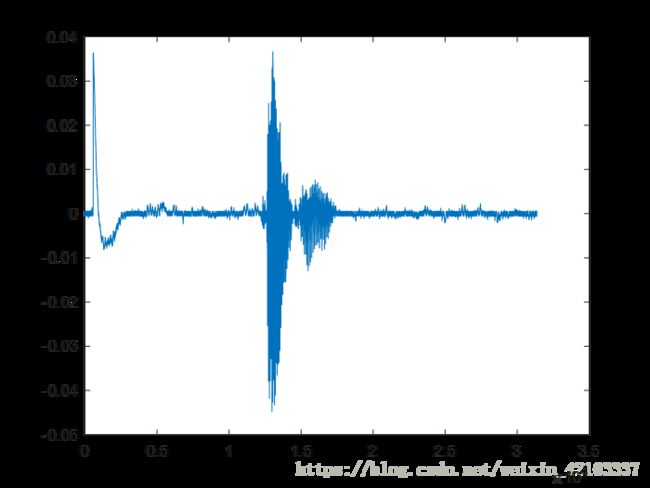
可以清晰的看见在非语音段出现了一个明显的水平线(上为原信号下为处理信号)
代码部分
| for (con = 2480;con < 4080;con++) //默认噪声帧数为10帧 { sum = sum + fabs(*(y + con)); } sum = sum / 1600.0;
for (con = 0;con < voice_length;con++) { if (*(y + con) > 0) *(p_voice + con) = *(y + con) - sum; else *(p_voice + con) = *(y + con) + sum; *(n_voice + con) = *(p_voice + con); } |
二、端点检测
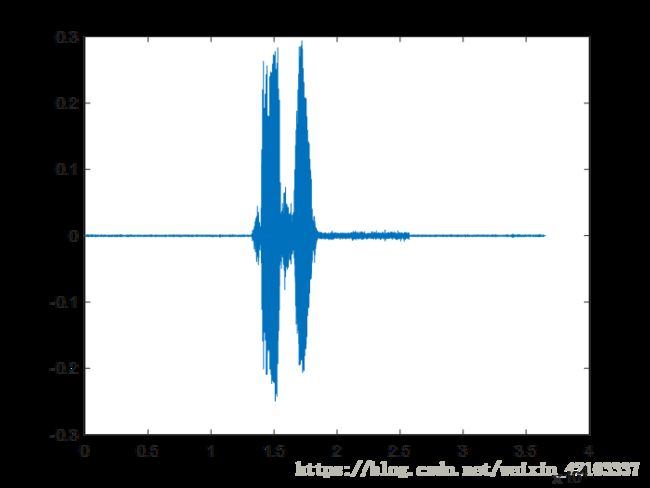
端点检测为本算法包括所有语音信号处理过程中极为重要的一部分,端点检测的准确程度直接影响声音识别效果的好坏,因为准确的端点检测才能避免在对语音帧进行傅里叶变换的过程中不会受到太多无效信号段的影响。端点检测算法目前普遍使用的是短时过零率和短时幅度值的双阈值法。
1、双阈值判断
短时过零率即计算一帧语音中过零采样点的比例,当该比例大于一定值时认为该帧为有声帧。在本算法中,“过零”并非真正意义的越过0值极为过零。由于有噪声的存在不简单的认为过零值的信号为有声信号。在这里我们选择的是10帧噪声帧每一帧最大值的均值。之所以这样选择是因为在经过预处理后噪声基本在同一水平,在该水平下的信号一律认为是噪声或者清音(由于清音一定配合浊音,此处的判别会在后面提及),只有超过该水平的声音才认为是有效声音。在本算法中,为了进一步提升抗噪性能,在做了均值处理后,大于均值2倍的信号认为是有效信号值。
短时幅度值即计算一帧语音中幅度值的均值,当均值大于一定阈值时认为该帧为有声帧。在本算法中,对于该阈值的选择。经过测试,选在在噪声幅值最大值均值的50%。即一帧语音中有50%的信号的赋值都超过了门限值,则可认为这一帧是有效语音帧。
代码处理:
con = noise_start; //噪声段的起始点采用了与预处理相同的2480
temp = noise_start;
n_thl_ratio=2; s_thl_ratio=0.5;
for (con2 = 1;con2 <= noise_num;con2++)
//默认噪声帧数为10帧,来计算幅度阈值
{
for (con = temp;con < temp + noise_len-1;con++)
{
if (fabs(*(n_voice + con)) > noise_max)
noise_max = fabs(*(n_voice + con));
}
n_max_mean = n_max_mean + noise_max;
noise_max = 0.0;
temp = con;
}
n_max_mean = n_max_mean / (double)noise_num;
noise_thl = n_max_mean*n_thl_ratio;
s_thl = ((double)frame_len)*noise_thl*s_thl_ratio;
//printf("端点检测短时幅度值检测完成\n");
temp = (voice_length - frame_len) / (frame_len - frame_mov) + 1;
S = (double *)malloc(temp * sizeof(double));
Z = (double *)malloc(temp * sizeof(double));
//用于保存短时过零率和短时幅度值
for (temp = temp - 1;temp >= 0;temp--)
{
*(S + temp) = 0;
*(Z + temp) = 0;
}
frame = (double *)malloc((frame_len ) * sizeof(double));
frame_con = -1;
for (con2 = 0;con2 <= (voice_length - frame_len);con2 = con2 + (frame_len - frame_mov))
{
frame_con = frame_con + 1;
for (temp = con2, con = 0;temp <= con2 + frame_len - 1;temp++, con++)
*(frame + con) = *(n_voice + temp);
for (con = 0;con < frame_len;con++)
*(S + frame_con) = *(S + frame_con) + fabs(*(frame + con));
for (con = 0;con < frame_len - 1;con++)
{
if (*(frame + con) >= noise_thl)
last_sig = 1;
else if (*(frame + con) < (0.0 - noise_thl))
last_sig = -1;
if (last_sig == -1)
{
if (*(frame + con + 1) >= noise_thl)
*(Z + frame_con) = *(Z + frame_con) + 1;
}
else if (last_sig == 1)
{
if (*(frame + con + 1) < (0.0 - noise_thl))
*(Z + frame_con) = *(Z + frame_con) + 1;
}
}
//printf("完成短时过零率和短时幅度值\n");
}
效果图:
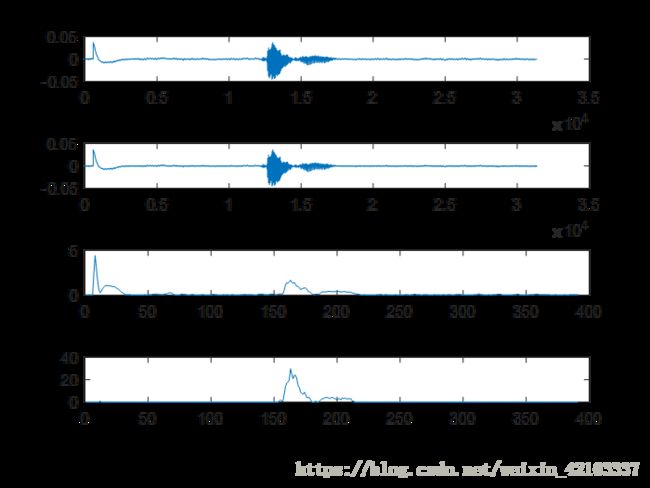
2、状态转换检验
刚刚提到在语音中出现清音时有可能出现无法满足双阈值的情况。同时,语音中出现的脉冲噪声则有可能恰恰相反,出现了满足双阈值之一的可能。如果仅仅在当前帧中对双阈值进行判断就判断是否为语音帧,则以上两种情况都有可能发生误判。因此选择使用状态转换判决,给声音设置4个状态:0——无声段 1——前端过渡段 2——有声段 3——后端过渡段。流程如下(初始状态为0——无声段):
(1)判断当前语音帧是否满足双阈值其一,如果满足进入(2)-(5),如果不满足()
(2)如果当前(即上一帧)状态为2—有声段,则保持不变。
(3)如果当前(即上一帧)状态为0—无声段,则状态变为1—前端过渡段,且前端过渡帧数加一,回到(1)。
(4)如果当前(即上一帧)状态为1—前端过渡段,如果前端过渡段帧数到达了最大帧数,则状态变为2—有声段,否则前端过渡帧数加一,回到(1)。
(5)如果当前(即上一帧)状态为3—后端过渡段,即在声音消失的时候又检测到有声音,认为是中间极短暂停顿,状态变为2—有声段,后端过渡帧数置0,回到(1)
(6)如果当前(即上一帧)状态为0—无声段,则保持不变,回到(1)。
(7)如果当前(即上一帧)状态为2—有声段,则状态变为3—后端过渡段,且后端过渡帧数加一,回到(1)。
(8)如果当前(即上一帧)状态为3—后端过渡段,如果后端过渡段帧数到达了最大帧数,则状态变为0—无声段,否则后端过渡帧数加一,回到(1)。
(9)如果当前(即上一帧)状态为1—前端过渡段,即在无声的时候又检测到有声音,认为是中间极短暂脉冲噪声,状态变为0—无声段,前端过渡段帧数置0,回到(1)。
代码处理:
for (con2 = 0;con2 <= (voice_length - frame_len);con2 = con2 + (frame_len - frame_mov))
{
frame_con = frame_con + 1;
if (*(S + frame_con) > s_thl || *(Z + frame_con) > z_thl)
{
if (cur_stus == 2)
;
else if (cur_stus == 0)
{
cur_stus = 1;
font_duration = 1;
}
else if (cur_stus == 1)
{
font_duration = font_duration + 1;
if (font_duration >= v_durmin_f)
{
cur_stus = 2;
valid_con = valid_con + 1;
//printf("第%d段语音", valid_con+1);
valid_start[valid_con] =( frame_con - v_durmin_f + 1);
//printf("当前帧为%d,起始帧为%d ", frame_con,(frame_con - v_durmin_f - 1));
font_duration = 0;
}
}
else if (cur_stus == 3)
{
back_duration = 0;
cur_stus = 2;
}
}
else
{
if (cur_stus == 0)
;
else if (cur_stus == 2)
{
cur_stus = 3;
back_duration = 1;
}
else if (cur_stus == 3)
{
back_duration = back_duration + 1;
if (back_duration >= s_durmax_f)
{
cur_stus = 0;
valid_end[valid_con] = (frame_con - s_durmax_f + 1);
back_duration = 0;
}
}
else if (cur_stus == 1)
{
font_duration = 0;
cur_stus = 0;
}
}
}
//printf("端点检测完成并保存\n");
for (con = 0;con <= 19;con++)
{
valid_start[con] = valid_start[con] * (frame_len - frame_mov)+80.0;
valid_end[con] = valid_end[con] * (frame_len - frame_mov)+80.0;
}
if (cur_stus == 2|| back_duration!=0)
valid_end[valid_con] = voice_length;
//结尾处理:防止文件结束时声音未结束而程序错误
效果图:


图中可以看出端点检测效果良好。(上为原信号下为提取信号)。
三、预加重与加窗处理
对于语音信号,一般都会进行预加重以及加窗处理。
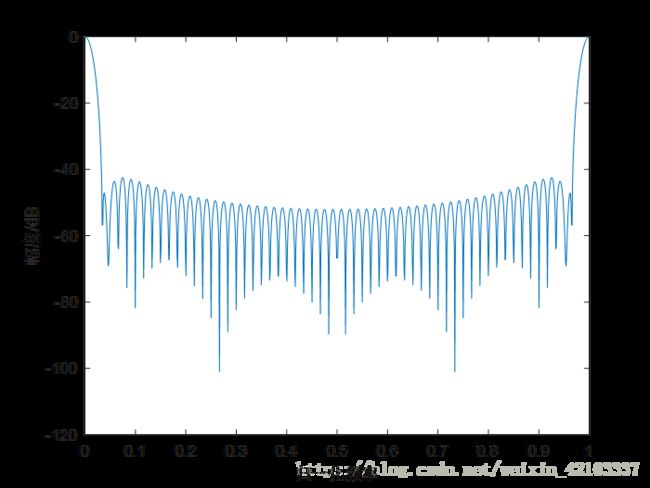
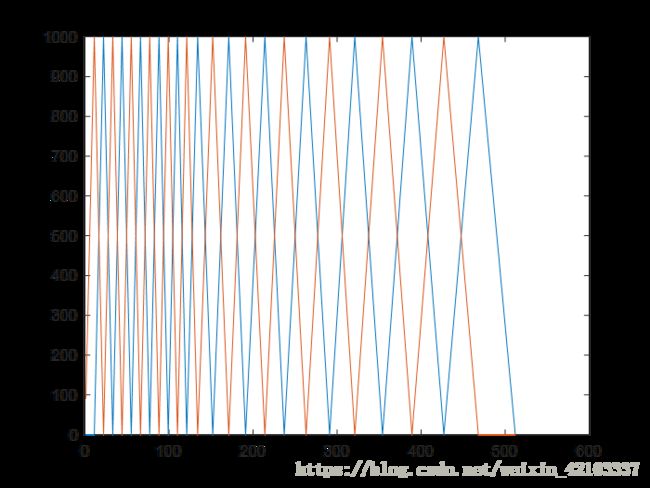
1、语音信号的预加重,目的是为了对语音的高频部分进行加重,去除口唇辐射的影响,增加语音的高频分辨率。一般通过传递函数为一阶FIR高通数字滤波器来实现预加重,其中a为预加重系数,0.9 代码处理: void pre_emphasis(double *p_voice, int *valid_start, int *valid_end, int n, double *hf_voice) { int i,j; double u = 0.95;//预加重系数 for (j = 0, i = valid_start[n - 1];i <= valid_end[n - 1] - 1;i++, j++) { *(hf_voice + j) = *(p_voice + i); } //printf("预加重语音段初始化完成\n"); for (i = 1;i <= (valid_end[n - 1] - valid_start[n - 1] - 2);i++) *(hf_voice + i - 1) = *(hf_voice + i) - u*(*(hf_voice + i - 1)); *(hf_voice + i ) = 0; *(hf_voice + i + 1) = 0;} 2、加窗。为了便于后续语音处理,需对分帧后的信号加窗。加窗可以选择矩形窗、汉明窗汉宁窗等,这些窗函数的频率响应都具有低通特性,但不同的窗函数形状将影响分帧后短时特征的特性。在相同的时域点数下汉明窗的带宽大约是同样宽度矩形窗带宽的两倍。同时,在通带外汉明窗的衰减比矩形窗大得多。矩形窗的主瓣较小,旁瓣较高;而汉明窗具有最宽的主瓣宽度和最低的旁瓣高度。对语音信号分析来说,窗函数的形状是非常重要的,矩形窗的谱平滑性较好,但波形细节易丢失,并且矩形窗会产生泄露现象。而汉明窗可以有效地克服泄露现象,应用范围也最为广泛。基于以上论述,本设计选用汉明窗作为窗函数。如图: 在本程序中,考虑到最终该程序需要在c语言环境下运行,一方面考虑到C语言进行相关与卷积的操作都非常不便,因此在matlab中进行1024点dft变换后将频域的系数保存在文件中,在C程序中直接读文件的形式进行频域逐项相乘。代码处理如下: %%%%%%%%%%%% 汉明窗 %%%%%%%%%%%% w(n)=0.54-0.46*cos[2*pi*n/(N-1)], 0<=n<=(N-1) %移植到语言时上时应先计算好窗函数在每一点的取值 然后存储于程序中 程序运行时直接取用 ham_top=10000; hamm=zeros(frame_len,1); for i=1:frame_len hamm(i)=0.54-0.46*cos(2*pi*(i-1)/(frame_len-1)); end hamm=int32(hamm*ham_top); hamm=double(hamm); plot(hamm); csvwrite('hamm.c',hamm'); C语言中参数文件的读取将在后面与三角滤波器的设计一起展示。 在语音识别系统中,时域下的数字信号难以进行分析与识别。通常的做法是对时域信号进行变换,提取其中某种特定的参数,通过一些更加能反映语音本质特征的参数来进行语音识别。特征提取是识别过程中一个非常重要的环节,选取的特征直接影响到识别的结果。目前语音特征的提取方法主要有以下三类: Mel 频率滤波器组模拟人的耳蜗声道模型,将声道分为24个三角滤波器的叠加。Mel 频率可以用如下公式表示: fMel=2595×log1+f700 利用Matlab画出关系如图: 对频率轴的不均匀划分是 MFCC 特征区别于普通倒谱特征的最重要特点。将频率按照变换到 Mel 域后,Mel 带通滤波器组的中心频率是按照 Mel 频率刻度均匀排列的。在本设计中,MFCC 倒谱系数的计算过程如下述。 (2)取频谱平方,得能量谱。并用 24 个 Mel 三角带通滤波器进行滤波;将每个滤波器频带内的能量进行叠加,输出 Mel 功率谱。 (3)对每个滤波器的输出值取对数,得到相应频带的对数功率谱。然后对 24 个对数功率进行反离散余弦变换得到 12 个 MFCC 系数,即对于一帧语音,都会得到一个1×24的能量值矢量,并得到一个1×12的MFCC特征系数矢量。 对于一段有效语音帧对应的MFCC系数矩阵,每一行系数矢量对应一帧语音。为了节省运算时间,降低代码复杂度,对于C语言所不擅长的数学运算,我们采用在Matlab中预先计算好三角滤波器系数及中心频率,由于对于三角滤波器,在做频域乘积的时候会涉及到奇偶项的问题,因此按中心频率次序分为奇项系数与偶项系数分别保存。另外,为了便于识别,另将模板的mfcc矩阵也进行了保存。 代码处理: %%%%%%%%%%%%% MFCC %%%%%%%%%%%%%% f_max=fs/2; % 最大频率分量 mel_max=2595*log10(1+f_max/700); % 最大mel频率 tri_num=24; % Mel三角滤波器个数。必须是偶数 % 减小会导致MFCC系数分辨率下降 % FFT点数不变,此数增加会因为整形数舍入导致误差增大 mfcc_num=12; % MFCC阶数 t_max=2000; % 语音最长时间 单位ms frm_max=t_max/(frame_time*(1-frame_mov_rtio));% 最大帧数 mfcc=zeros(frm_max,mfcc_num); % mfcc系数 pow_spct=zeros(frm_max,tri_num); % 经三角滤波器输出的对数功率谱 mel_step=mel_max/(tri_num+1); % Mel三角滤波器中心频率间隔 mel_thl=1000; % Mel变换线性对数临界点 fft_point=1024; % FFT点数 tri_cen=zeros(tri_num,1); % 三角滤波器中心频率 tri_top=1000; % 三角滤波器顶点值 过大会导致溢出 过小会导致三角滤波器输出精度下降 tri_odd=zeros(fft_point/2,1); % 奇数三角滤波器首尾相连的折线 tri_even=zeros(fft_point/2,1); % 偶数三角滤波器首尾相连的折线 for i=1:tri_num if i<(mel_thl/mel_step) % 小于1000Hz线性尺度 tri_cen(i)=mel_step*i; else % 大于1000Hz对数尺度 tri_cen(i)=(exp(log(10)*(mel_step*i)/2595)-1)*700; % Mel运算逆运算 end end tri_cen=int32(tri_cen/(f_max/(fft_point/2))); %plot(tri_cen); csvwrite('tri_cen.c',tri_cen'); tri_cen=double(tri_cen); for j=1:tri_cen(1) tri_odd(j)=tri_top*j/tri_cen(1); end for j=tri_cen(1)+1:tri_cen(2) tri_odd(j)=tri_top*(tri_cen(2)-j)/(tri_cen(2)-tri_cen(1)); end for h=3:2:tri_num for j=tri_cen(h-1):tri_cen(h) tri_odd(j)=tri_top*(j-tri_cen(h-1))/(tri_cen(h)-tri_cen(h-1)); end for j=(tri_cen(h)+1):tri_cen(h+1) tri_odd(j)=tri_top*(tri_cen(h+1)-j)/(tri_cen(h+1)-tri_cen(h)); end end for h=2:2:tri_num-2 for j=tri_cen(h-1):tri_cen(h) tri_even(j)=tri_top*(j-tri_cen(h-1))/(tri_cen(h)-tri_cen(h-1)); end for j=(tri_cen(h)+1):tri_cen(h+1) tri_even(j)=tri_top*(tri_cen(h+1)-j)/(tri_cen(h+1)-tri_cen(h)); end end for j=tri_cen(tri_num-1):tri_cen(tri_num) tri_even(j)=tri_top*(j-tri_cen(tri_num-1))/(tri_cen(tri_num)-tri_cen(tri_num-1)); end for j=(tri_cen(tri_num)+1):fft_point/2 tri_even(j)=tri_top*(fft_point/2-j)/(fft_point/2-tri_cen(tri_num)); end tri_even=int32(tri_even); tri_odd=int32(tri_odd); csvwrite('tri_even.c',tri_even'); csvwrite('tri_odd.c',tri_odd'); tri_even=double(tri_even); tri_odd=double(tri_odd); x=1:fft_point/2; plot(x,tri_even,x,tri_odd); 计算得到的三角滤波器组如图所示: 对于保存好的三角滤波器组的系数,对于语音帧计算MFCC系数的时候,在对当前帧的语音进行1024点dft计算之后,将1024个频点分别于各个滤波器系数相乘,最后求幅值叠加得到MFCC系数矩阵。 double ** mfcc_coefficient(double tri_cen[24], double tri_odd[512], double tri_even[512], double hamm[160], double *hf_voice, int valid_frm_num) { double f_max = 4000, mel_max, mel_step = 85.8440,PI; int tri_num = 24, mfcc_num = 12, t_max = 2000, frm_max = 200, mel_th1 = 1000, fft_point = 1024, tri_top = 1000, frame_len = 160, frame_mov = 80, ham_top = 10000; double pow_spct[200][24], valid_frm[160], **mfcc; int con, j, i, h; complex_s *x; double *frq_spct; PI = atan(1) * 4; x = (complex_s *)malloc(sizeof(complex_s) * fft_point); frq_spct = (double *)malloc(sizeof(double) * fft_point); mfcc = (double **)malloc(200 * sizeof(double *)); 代码处理如下: for (con = 0;con < 200;con++) { *(mfcc + con) = (double *)malloc(12 * sizeof(double)); } //printf("内存分配完成\n"); mel_max = 2595.0 * log10(1.0 + f_max / 700.0); //for (con = 0;con < valid_frm_num;con++) //*(hf_voice + con) = *(hf_voice + con) * 2048.0; for (i = 0;i < valid_frm_num;i++) { for (h = 0;h < fft_point;h++) { if (h < 160) { *(valid_frm + h) = *(hf_voice + ((i*(frame_len - frame_mov) + h))); *(valid_frm + h) = *(valid_frm + h) *(*(hamm + h)) / ham_top; (*(x + h)).real = *(valid_frm + h); (*(x + h)).img = 0.0; } else { (*(x + h)).real = 0.0; (*(x + h)).img = 0.0; } } //printf("x保存了一维的第%d帧声音信号并进行了补零补为1024点长信号\n", i); //x[N]保存了一维的一帧声音信号并进行了补零补为1024点长 //initW(&*W, frame_len); fft(fft_point, &*x); for (con = 0;con < fft_point;con++) { if (con < fft_point / 2) (*(frq_spct + con)) = ((*(x + con)).real*(*(x + con)).real + (*(x + con)).img*(*(x + con)).img); else (*(frq_spct + con)) = sqrt((*(x + con)).real*(*(x + con)).real + (*(x + con)).img*(*(x + con)).img); } //得到了声音信号的频谱frq_spct[1024] //printf("得到了声音信号的频谱frq_spct\n"); pow_spct[i][0] = 0; for (j = 0;j < tri_cen[1];j++) pow_spct[i][0] = pow_spct[i][0] + (*(frq_spct + j))*tri_odd[j]; //printf("计算完第一个三角滤波器输出\n"); for (h = 2;h <= tri_num - 2;h = h + 2) { pow_spct[i][h] = 0; for (j = *(tri_cen + h-1)-1;j <= *(tri_cen + h+1)-1;j++) pow_spct[i][h] = pow_spct[i][h] + (*(frq_spct + j))*tri_odd[j]; } //printf("计算完奇数三角滤波器输出\n"); for (h = 1;h <= tri_num - 3;h = h + 2) { for (j = *(tri_cen + h-1)-1;j <= *(tri_cen + h+1)-1;j++) pow_spct[i][h] = pow_spct[i][h] + (*(frq_spct + j))*tri_even[j]; } //printf("计算完偶数三角滤波器输出\n"); pow_spct[i][tri_num - 1] = 0.0; for (j = tri_cen[tri_num - 2]-1;j < 512;j++) pow_spct[i][tri_num - 1] = pow_spct[i][tri_num - 1] + (*(frq_spct + j))*tri_even[j]; //printf("计算完最后一个三角滤波器输出\n"); for (h = 1;h <= tri_num;h++) pow_spct[i][h - 1] = log(pow_spct[i][h - 1]); //printf("计算完三角滤波器输出取对数\n"); for (h = 1;h <= mfcc_num;h++) { mfcc[i][h - 1] = 0; for (j = 1;j <= tri_num;j++) { mfcc[i][h - 1] = mfcc[i][h - 1] + cos((double)h*PI*((double)j - 0.5) / (double)tri_num)*pow_spct[i][j - 1]; //printf("计算完第%d帧语音的第%d个mfcc系数\n", i + 1, h + 1); } //printf("%.3f ", mfcc[i][h - 1]); } //printf("\n完成第%d帧的mfcc特征系数\n", i); } //建立mfcc矩阵 //printf("完成建立mfcc矩阵\n"); //outputmfcc(mfcc, valid_frm_num); return mfcc; } 在本方案中,如果使用HMM或其他需要训练匹配模型的的语音识别算法都需要经过大量样本的模型训练,在训练阶段需要提供大量的语音数据,通过反复计算才能得到模型参数,这显然对于硬件是一个挑战,同时对应于我们需要完成的孤立词语音的识别功能,这个性能上并没有巨大的优势,而耗费了更多的资源,因此我们采用了更加快捷的识别方式—— 动态时间规整DTW算法。 在时间序列中,需要比较相似性的两段时间序列的长度可能并不相等,在语音识别领域表现为不同人的语速不同。因为语音信号具有相当大的随机性,在这些复杂情况下,使用传统的欧几里得距离无法有效地求的两个时间序列之间的距离(或者相似性)。 也就是说,大部分情况下,两个序列整体上具有非常相似的形状,但是这些形状在x轴上并不是对齐的。所以我们在比较他们的相似度之前,需要通过DTW把时间序列进行延伸和缩短,来计算两个时间序列性之间的相似性。 动态时间规整DTW是一个典型的优化问题,它用满足一定条件的的时间规整函数W(n)描述测试模板和参考模板的时间对应关系,求解两模板匹配时累计距离最小所对应的规整函数。 我们有两个时间序列Q和C,他们的长度分别是n和m,一个序列为参考模板,一个序列为测试模板,序列中的每个点的值为语音序列中每一帧的特征矢量。语音序列Q第i帧的特征向量是qi Q = q1, q2,…,qi,…, qn C = c1, c2,…, cj,…, cm 为了对齐这两个序列,我们构造一个n x m的矩阵网格,矩阵元素(i, j)表示qi和cj两个点的欧式距离,d(qi, cj)= (qi-cj)2。每一个矩阵元素(i, j)表示点qi和cj的对齐。再寻找一条通过此网格中若干格点的路径,路径通过的格点即为两个序列进行计算的对齐的点。 我们把这条路径定义为规整路径,并用W来表示, W的第k个元素定义为wk=(i,j)k,定义了序列Q和C的映射。这样我们有: W=w1,w2,…,wk,…,wK; maxm,n≤K 首先,这条路径不是随意选择的,需要满足以下几个约束: 1)边界条件:w1=(1, 1)和wK=(m, n)。所选的路径必定是从左下角出发,在右上角结束。 2)连续性:DTW不可能跨过某个点去匹配,只能和自己相邻的点对齐。 3)单调性: W上面的点必须是随着时间单调进行的。以保证图B中的虚线不会相交。 结合连续性和单调性约束,每一个格点的路径就只有三个方向了。例如如果路径已经通过了格点(i, j),那么下一个通过的格点只可能是下列三种情况之一:(i+1, j),(i, j+1)或者(i+1, j+1)。 满足上面这些约束条件的路径可以有指数个,然后我们感兴趣的是使得下面的规整代价最小的路径: 分母中的K主要是用来对不同的长度的规整路径做补偿。这个最短的距离也就是这两个时间序列的最后的距离度量。 我们定义一个累加距离矩阵。从(0, 0)点开始匹配这两个序列Q和C,每到一个点,之前所有的点计算的距离都会累加。到达终点(n, m)后,这个累积距离就是我们上面说的最后的总的距离,也就是序列Q和C的相似度。 累积距离γ(i,j)可以按下面的方式表示,累积距离γ(i,j)为当前格点距离d(i,j),也就是点qi和cj的欧式距离(相似性)与可以到达该点的最小的邻近元素的累积距离之和: 即最后得到的γ(m,n)即为最小距离。 代码处理: double dtw(double **mfcc_modle,double **mfcc_in,int n,int m) //n为模板帧数,根据模板是已知的;m为输入特征向量系数矩阵帧数,需要计算 //返回值为当前模板与当前输入的匹配值 { double **d,**D; int i,j; double d1, D1, D2, D3, Dmin,dist=0.0; d = (double **)malloc(n * sizeof(double *)); for (i = 0;i < n;i++) { *(d + i) = (double *)malloc(m * sizeof(double)); } D = (double **)malloc(n * sizeof(double *)); for (i = 0;i < n;i++) { *(D + i) = (double *)malloc(m * sizeof(double)); } //printf("成功创建DTW矩阵\n"); for (i = 0;i < n;i++) { for (j = 0;j < m;j++) { d[i][j] = 0.0; //printf("计算模板第%d帧和输入第%d帧的欧式距离", i, j); //printf("%f\n", vdistance(mfcc_modle[i], mfcc_in[j])); d[i][j] = vdistance(mfcc_modle[i], mfcc_in[j]); } } //printf("计算完成\n"); D[0][0] = 2 * d[0][0]; for (j = 1;j < m;j++) D[0][j] = d[0][j] + D[0][j - 1]; //printf("第1行累计距离计算完成\n"); for (i = 1;i < n;i++) { for (j = 0;j < m;j++) { d1 = d[i][j]; D1 = D[i - 1][j] + d1; if (j > 0) { D2 = D[i - 1][j - 1] + 2 * d1; D3 = D[i][j - 1] + d1; } Dmin = D1; if (D2 <= Dmin) Dmin = D2; else ; if (D3 <= Dmin) Dmin = D3; else ; D[i][j] = Dmin; } //printf("第%d行累计距离计算完成\n", i + 1); } dist = D[n-1][m-1]; return dist; } 在VisualStudio2015中运行C语言控制台程序,对算法程序进行检测测试。经过测试,本算法识别率相当高,只要在录音中能完整的录入语音,不会出现语音发音缺失的情况,都可以正常的识别出预设的三个词。若想进一步提高精确度也可再添加更多模板即可。 在测试中,对同班6位同学进行了测试,测试结果均为通过 (1)较大噪声干扰与较差的录音效果 (2)音量较小的录音效果: (3)有较严重的尾音拖尾 (4)中间段有较强的脉冲噪声 其余测试案例将保存在Sample文档中 另附一张对于测试用例test2.txt的程序运行输出截图以及matlab检验 本次给我最大的感受还是自己动手去编写,调整测试一个算法的困难。虽然本次算法中两个核心的部分VAD端点识别和MFCC特征系数提取都是早期的成果,网上也有不少代码可以参考。但是要真正的落到实处化为己用还是存在着很多很多的困难。VAD中各种不同的阈值参数的调整,通过状态转换的方式来改进端点检测的性能,选取合适的噪声段和降噪方式,选取合适的阈值判断条件这些等等,有前人之智的部分,也有不少靠着自己的冥思苦想才得以解决。MFCC特征系数中,考虑到硬件的条件选择采用文件的方式进行计算,在各个频点对齐的计算上也花了不少的功夫。 给自己印象最为深刻的还是C语言程序的编写,由于限定了硬件平台,没法再使用MATLAB这么“轻松”的工具,没法用自然语言和直观的数据空间来检查自己编写的正误与算法的正确性。转而到C语言上,在C语言上对矩阵进行操作实在苦不堪言,本身调用的困难程度,还有C语言对于内存空间和调用种种严格的限制一度然我进度缓慢。但不得不说经过了课设的锻炼,C语言的能力有得到了再一次的提升。 1、《语音信号处理》,2009年06月机械工业出版社出版,赵力 2、语音信号处理之(一)动态时间规整(DTW)https://blog.csdn.net/zouxy09/article/details/9140207 3、语音信号处理之(四)梅尔频率倒谱系数(MFCC)https://blog.csdn.net/zouxy09/article/details/9156785 4、用c语言实现的FFT https://blog.csdn.net/tf18269639242/article/details/53024276 附C语言完整代码: 

四、语音帧的MFCC特征矢量系数矩阵的提取
1.基于线性预测分析的提取方法。这一类的典型代表是线性预测倒谱系数 LPCC。
2.基于频谱分析的提取方法。这一类的典型代表是 Mel 频率倒谱系数 MFCC。
3.基于其它数字信号处理技术的特征分析方法。如小波分析、时频分析、人工神经网络分析等。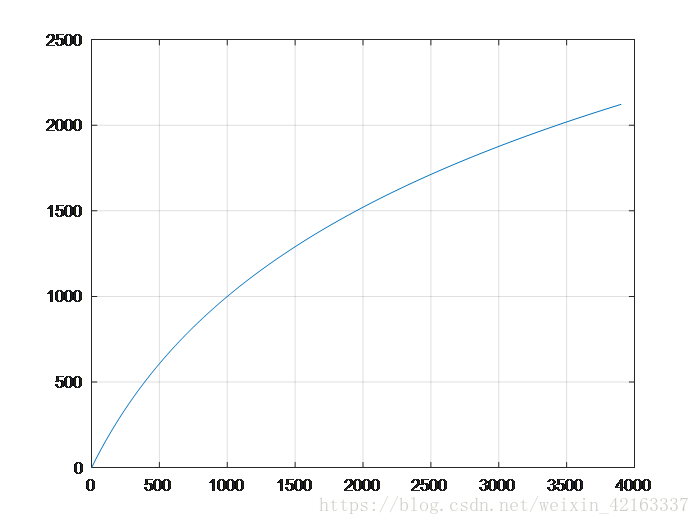
(1)对预处理后的语音信号进行1024点傅里叶变换,得出频谱。
五、 特征匹配算法选择



![]()
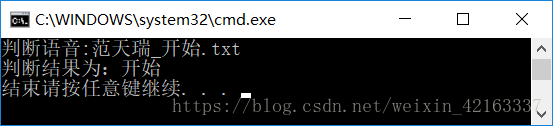
六、检验效果



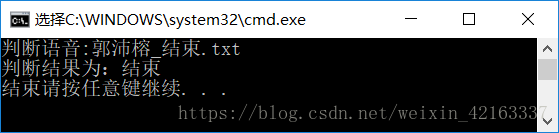

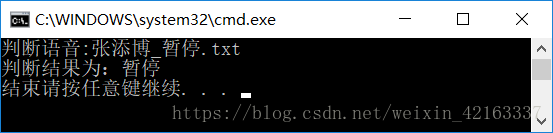
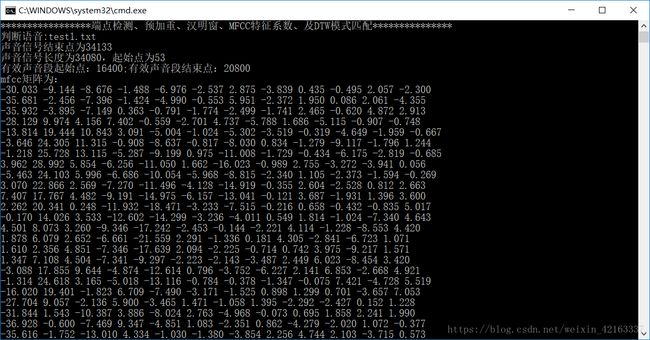


七、心得体会
八、参考资料
九、附录
#include