数据分析与挖掘之手写体识别(KNN算法)
K-近邻算法(KNN)概述
最简单最初级的分类器是将全部的训练数据所对应的类别都记录下来,当测试对象的属性和某个训练对象的属性完全匹配时,便可以对其进行分类。但是怎么可能所有测试对象都会找到与之完全匹配的训练对象呢,其次就是存在一个测试对象同时与多个训练对象匹配,导致一个训练对象被分到了多个类的问题,基于这些问题呢,就产生了KNN。
KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
下面通过一个简单的例子说明一下:如下图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
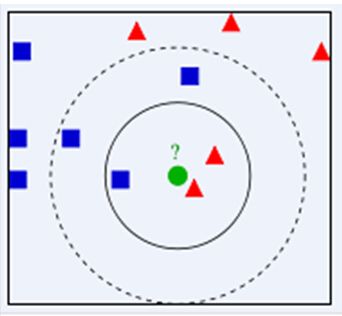
由此也说明了KNN算法的结果很大程度取决于K的选择。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:

同时,KNN通过依据k个对象中占优的类别进行决策,而不是单一的对象类别决策。这两点就是KNN算法的优势。
接下来对KNN算法的思想总结一下:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
我们对KNN算法思想及流程有了初步的了解,KNN是采用测量不同特征值之间的距离方法进行分类,也就是说对于每个样本数据,需要和训练集中的所有数据进行欧氏距离计算。这里简述KNN算法的特点:
优点:精度高,对异常值不敏感,无数据输入假定 缺点:计算复杂度高,空间复杂度高 适用数据范围:数值型和标称型(具有有穷多个不同值,值之间无序)
knn算法代码:
#-*- coding: utf-8 -*-
from numpy import *
import operator
import time
from os import listdir
def classify(inputPoint,dataSet,labels,k):
dataSetSize = dataSet.shape[0] #已知分类的数据集(训练集)的行数
#先tile函数将输入点拓展成与训练集相同维数的矩阵,再计算欧氏距离
diffMat = tile(inputPoint,(dataSetSize,1))-dataSet #样本与训练集的差值矩阵
sqDiffMat = diffMat ** 2 #差值矩阵平方
sqDistances = sqDiffMat.sum(axis=1) #计算每一行上元素的和
distances = sqDistances ** 0.5 #开方得到欧拉距离矩阵
sortedDistIndicies = distances.argsort() #按distances中元素进行升序排序后得到的对应下标的列表
#选择距离最小的k个点
classCount = {}
for i in range(k):
voteIlabel = labels[ sortedDistIndicies[i] ]
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1
#按classCount字典的第2个元素(即类别出现的次数)从大到小排序
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
return sortedClassCount[0][0]KNN算法实战—手写体识别
from numpy import *
import operator
from os import listdir
import time
#从列方向扩展
#tile(a,(size,1))
def knn(k,testdata,traindata,labels):
traindatasize=traindata.shape[0]
dif=tile(testdata,(traindatasize,1))-traindata
sqdif=dif**2
sumsqdif=sqdif.sum(axis=1)
distance=sumsqdif**0.5
sortdistance=distance.argsort()
count={}
for i in range(0,k):
vote=labels[sortdistance[i]]
count[vote]=count.get(vote,0)+1
sortcount=sorted(count.items(),key=operator.itemgetter(1),reverse=True)
return sortcount[0][0]
'''
#图片处理
#先将所有图片转为固定宽高,比如32*32,然后再转为文本
#pillow
from PIL import Image
im=Image.open("C:/Users/me/Pictures/weixin3.jpg")
fh=open("C:/Users/me/Pictures/weixin3.txt","a")
#im.save("C:/Users/me/Pictures/weixin.bmp")
width=im.size[0]
height=im.size[1]
#k=im.getpixel((1,9))
#print(k)
for i in range(0,width):
for j in range(0,height):
cl=im.getpixel((i,j))
clall=cl[0]+cl[1]+cl[2]
if(clall==0):
#黑色
fh.write("1")
else:
fh.write("0")
fh.write("\n")
fh.close()
'''
#加载数据-文本向量化 32x32 -> 1x1024
def datatoarray(fname):
arr=[]
fh=open(fname)
for i in range(0,32):
thisline=fh.readline()
for j in range(0,32):
arr.append(int(thisline[j]))
return arr
arr1=datatoarray("E:/python小笔记/手写体识别/testandtraindata/testdata/0_4.txt")
#建立一个函数取文件名前缀
def seplabel(fname):
filestr=fname.split(".")[0]
label=int(filestr.split("_")[0])
return label
#建立训练数据
def traindata():
labels=[]
trainfile=listdir("E:/python小笔记/手写体识别/testandtraindata/traindata/")
num=len(trainfile)
#长度1024(列),每一行存储一个文件
#用一个数组存储所有训练数据,行:文件总数,列:1024
trainarr=zeros((num,1024))
for i in range(0,num):
thisfname=trainfile[i]
thislabel=seplabel(thisfname)
labels.append(thislabel)
trainarr[i,:]=datatoarray("E:/python小笔记/手写体识别/testandtraindata/traindata/"+thisfname)
return trainarr,labels
#用测试数据调用KNN算法去测试,看是否能够准确识别
def datatest():
trainarr,labels=traindata()
testlist=listdir("E:/python小笔记/手写体识别/testandtraindata/testdata/")
tnum=len(testlist)
for i in range(0,tnum):
thistestfile=testlist[i]
testarr=datatoarray("E:/python小笔记/手写体识别/testandtraindata/testdata/"+thistestfile)
rknn=knn(3,testarr,trainarr,labels)
print(rknn)
'''
#datatest()
#抽某一个测试文件出来进行试验
trainarr,labels=traindata()
thistestfile="8_76.txt"
testarr=datatoarray("E:/python小笔记/手写体识别/testandtraindata/testdata/"+thistestfile)
rknn=knn(3,testarr,trainarr,labels)
print("测试样本8,输出结果:%d"% rknn)
'''
#测试函数
def handwritingTest():
trainarr,labels=traindata() #构建训练集
testlist=listdir("E:/python小笔记/手写体识别/testandtraindata/testdata/") #获取测试集
errorCount = 0.0 #错误数
mTest = len(testlist) #测试集总样本数
t1 = time.time()
for i in range(mTest):
thistestfile = testlist[i]
classNumStr = seplabel(thistestfile)
testarr=datatoarray("E:/python小笔记/手写体识别/testandtraindata/testdata/"+thistestfile)
#调用knn算法进行测试
rknn=knn(3,testarr,trainarr,labels)
print ("训练结果输出: %d, 真实值: %d" % (rknn, classNumStr))
if (rknn != classNumStr): errorCount += 1.0
print ("\n测试样本总量: %d" % mTest ) #输出测试总样本数
print ("其中:测试错误样本数: %d" % errorCount) #输出测试错误样本数
print ("错误率: %f" % (errorCount/float(mTest))) #输出错误率
t2 = time.time()
print ("测试耗时: %.2fmin, %.4fs."%((t2-t1)//60,(t2-t1)%60)) #测试耗时