HBase导入海量数据、使用BuckLoa向HBase中导入数据 13
前言
博主之前简单介绍了,HBase写入数据的原理与HBase表在hdfs上的存储结构,还搞了搞HBase提供的导入工具ImportTsv, 想了解更多ImportTsv使用,请戳HBase导入海量数据之使用ImportTsv向HBase中导入大量数据
今天咱们了解下Buckload
如下图示,充分解释了Buckload的导入原理,通过MapReduce程序在hdfs中直接生成HFlie文件,然后将HFile文件移动到HBase中对应表的HDFS目录下
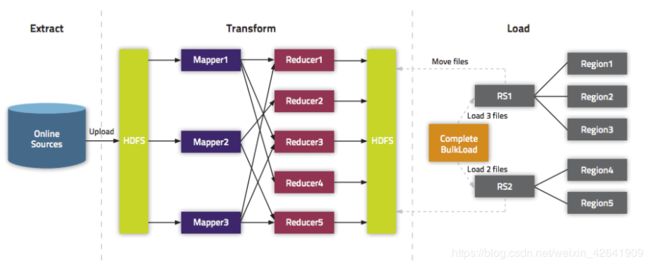
- ImportTsv是命令行导入,Buckload可以自定义程序生成HFile,再进行导入,由此可见,BuckLoad比较灵活
1. BuckLoad导入数据到HBase,程序编写步骤
- 编写mapper程序,无论是map还是reduce,输出类型必须是
- 编写map方法,包含处理数据的逻辑。
- 将处理后的数据写到hdfs中
- 配置MapReduce任务的输入/输出格式,输入/输出类型,输入/输出目录等
- 使用BuckLoad方式导入数据,有两种方法:
- 代码: 创建LoadIncrementalHFiles对象,调用doBulkLoad方法,加载刚才MapReduce程序生成HFile到表中即可。
doBulkLoad有两种,HTable已经过时了,现在推荐使用第一种,
- 代码: 创建LoadIncrementalHFiles对象,调用doBulkLoad方法,加载刚才MapReduce程序生成HFile到表中即可。
LoadIncrementalHFiles loader = new LoadIncrementalHFiles(conf);
loader.doBulkLoad(new Path(OUTPUT_PATH),admin,table,connection,getRegionLocator(tableName.valueOf(tableName)))
- 命令行:在命令行中使用如下命令
HADOOP_CLASSPATH=`$HBASE_HOME/bin/hbase classpath` hadoop jar $HBASE_HOME/lib/hbase-server-version.jar completebulkload <生成的HFile路径> <表名称>
2. 实例展示
2.1 背景
这有一个用户浏览网站的日志,分隔符为逗号,
共有四列:
- 手机号反转(避免Region热点)
- 手机号
- Mac地址
- 用户访问记录(用&&分割)访问记录内容:时间戳-agent-访问目录-上行流量-下行流量
56279618741,14781697265,65:85:36:f9:b1:c0,
1539787307-Mozilla/5.0 Macintosh; Intel Mac OS X 10_10_1 AppleWebKit/537.36 KHTML like Gecko Chrome/37.0.2062.124 Safari/537.36-https://dl.lianjia.com/ershoufang/102100802770.html-13660-6860
&&1539786398-Mozilla/5.0 Windows NT 5.1 AppleWebKit/537.36 KHTML like Gecko Chrome/36.0.1985.67 Safari/537.36-https://dl.lianjia.com/ershoufang/102100576898.html-1959-91040
&&1539785462-Mozilla/5.0 Windows NT 10.0 AppleWebKit/537.36 KHTML like Gecko Chrome/40.0.2214.93 Safari/537.36-https://dl.lianjia.com/ershoufang/102100762258.html-12177-53132
2.2 数据大小
12.48GB,共1999940条数据
2.3 需求
- 手机号反转做Rowkey,
- 将手机号,Mac地址,用户访问地址插入到Info列簇的phoneNumber,macAddress,userView列中,
- 将用户访问记录转为json格式
2.4 代码实现
- 编写Mapper程序和map方法
需要注意的是,要对rowkey的长度进行判断,筛选出rowkey长度大于0的,否则会报错
public static class BuckLoadMap extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] dataLine = value.toString().split(",");
// 手机号反转
String phoneNumberReverse = dataLine[0];
// 手机号
String phoneNumber = dataLine[1];
// mac地址
String macAddress = dataLine[2];
// 用户访问浏览历史
String userViewHistory = dataLine[3];
// 解析用户访问浏览历史
String[] userViewHistoryParse = userViewHistory.split("&&");
// 创建StringBuffer用户拼接json
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("[");
for (String view : userViewHistoryParse) {
// 拼接json
String[] viewDetail = view.split("-");
String time = viewDetail[0];
String userAgent = viewDetail[1];
String visitUrl = viewDetail[2];
String upFlow = viewDetail[3];
String downFlow = viewDetail[4];
String json = "{\"time\":\"" + time + "\",\"userAgent\":\"" + userAgent + "\",\"visitUrl\":\"" + visitUrl + "\",\"upflow\":\"" + upFlow + "\",\"downFlow\":\"" + downFlow + "\"}";
stringBuffer.append(json);
stringBuffer.append(",");
}
stringBuffer.append("]");
stringBuffer.deleteCharAt(stringBuffer.lastIndexOf(","));
userViewHistory = stringBuffer.toString();
// 将手机号反转作为rowkey
ImmutableBytesWritable rowkey = new ImmutableBytesWritable(phoneNumberReverse.getBytes());
// 筛选出rowkey为0的rowkey,某则导入的时候会报错
if (rowkey.getLength()>0){
// 将其他列数据插入到对应列族中
Put put = new Put(phoneNumberReverse.getBytes());
put.addColumn("info".getBytes(), "phoneNumber".getBytes(), phoneNumber.getBytes());
put.addColumn("info".getBytes(), "macAddress".getBytes(), macAddress.getBytes());
put.addColumn("info".getBytes(), "userViewHistory".getBytes(), userViewHistory.getBytes());
context.write(rowkey, put);
}
}
}
- 编写Reduce任务配置
- 导入包的时候,注意导入的FileInputFormat和FileOutputFormat是下面这两个包
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public static void main(String[] args) throws Exception {
final String INPUT_PATH= "hdfs://cluster/louisvv/weblog-20181121.txt";
final String OUTPUT_PATH= "hdfs://cluster/louisvv/HFileOutput";
Configuration conf=HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "192.168.1.22,192.168.1.50,192.168.1.51");
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("zookeeper.znode.parent", "/hbase-unsecure");
conf.set("hbase.master", "192.168.1.22:16010");
String tableName="user-view";
Connection connection = null;
try {
// 创建hbase connection
connection = ConnectionFactory.createConnection(conf);
// 获取hbase admin
Admin admin=connection.getAdmin();
// 创建hbase table
Table table = connection.getTable(TableName.valueOf(tableName));
// 设置mapreduce job相关内容
Job job=Job.getInstance(conf);
job.setJarByClass(BuckLoadImport.class);
// 设置mapper class
job.setMapperClass(BuckLoadImport.BuckLoadMap.class);
// 设置map输出key类型为ImmutableBytesWritable
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
// 设置map输出value类型为put
job.setMapOutputValueClass(Put.class);
// 设置job的输出格式为HFileOutputFormat2
job.setOutputFormatClass(HFileOutputFormat2.class);
// 设置文件输入输出路径
FileInputFormat.addInputPath(job,new Path(INPUT_PATH));
FileOutputFormat.setOutputPath(job,new Path(OUTPUT_PATH));
// 设置HFileOutputFormat2
HFileOutputFormat2.configureIncrementalLoad(job,table,connection.getRegionLocator(TableName.valueOf(tableName)));
// 等待程序退出
job.waitForCompletion(true);
- 编写好job的配置后,等待MapReduce程序运行完毕,创建LoadIncrementalHFiles,调用doBulkLoad方法
// 使用buckload方式导入刚才MapReduce程序生成的HFile
LoadIncrementalHFiles loader = new LoadIncrementalHFiles(conf);
loader.doBulkLoad(new Path(OUTPUT_PATH),admin,table,connection.getRegionLocator(TableName.valueOf(tableName)));
- 程序编写好了后,打包,上传到服务器上
在执行程序之前,需要创建表,如果不创建,则会自动创建
建表语句:
create 'user-view',
{NAME => 'desc', BLOOMFILTER => 'ROWCOL', COMPRESSION => 'SNAPPY', BLOCKCACHE => 'false', REPLICATION_SCOPE => '1'},
{NAME => 'info', BLOOMFILTER => 'ROWCOL', COMPRESSION => 'SNAPPY', BLOCKCACHE => 'false', REPLICATION_SCOPE => '1'},SPLITS => ['0','1', '2', '3', '4','5','6','7','8','9']
- 运行程序
hadoop jar /louisvv/HBase-test.jar cn.louisvv.weblog.hbase.BuckLoadImport
截取部分MapReduce日志如下:
通过日志,可以看到,一共输入1999940条数据,输出1999936条数据,过滤了4条有问题的数据
18/11/23 13:30:43 INFO mapreduce.Job: Running job: job_1542881108771_0004
18/11/23 13:31:30 INFO mapreduce.Job: map 0% reduce 0%
省略....
18/11/23 14:07:33 INFO mapreduce.Job: map 100% reduce 100%
18/11/23 14:07:37 INFO mapreduce.Job: Job job_1542881108771_0004 completed successfully
18/11/23 14:07:38 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=18234502087
FILE: Number of bytes written=36506399063
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=13423862333
HDFS: Number of bytes written=3778584104
HDFS: Number of read operations=1051
HDFS: Number of large read operations=0
HDFS: Number of write operations=30
Job Counters
Launched map tasks=200
Launched reduce tasks=11
Data-local map tasks=200
Total time spent by all maps in occupied slots (ms)=4528492
Total time spent by all reduces in occupied slots (ms)=3817650
Total time spent by all map tasks (ms)=2264246
Total time spent by all reduce tasks (ms)=1908825
Total vcore-milliseconds taken by all map tasks=2264246
Total vcore-milliseconds taken by all reduce tasks=1908825
Total megabyte-milliseconds taken by all map tasks=9274351616
Total megabyte-milliseconds taken by all reduce tasks=7818547200
Map-Reduce Framework
Map input records=1999940
Map output records=1999936
Map output bytes=18226502217
Map output materialized bytes=18234515161
Input split bytes=20400
Combine input records=0
Combine output records=0
Reduce input groups=1927972
Reduce shuffle bytes=18234515161
Reduce input records=1999936
Reduce output records=5783916
Spilled Records=3999872
Shuffled Maps =2200
Failed Shuffles=0
Merged Map outputs=2200
GC time elapsed (ms)=365192
CPU time spent (ms)=5841130
Physical memory (bytes) snapshot=570273415168
Virtual memory (bytes) snapshot=1170857234432
Total committed heap usage (bytes)=627039010816
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=13423769333
File Output Format Counters
Bytes Written=3778584104
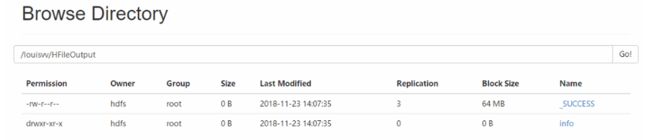
- 在hdfs上查看生产的HFile文件
- 生成的HFile目录,发现其中有一个info目录,是生成的列族目录
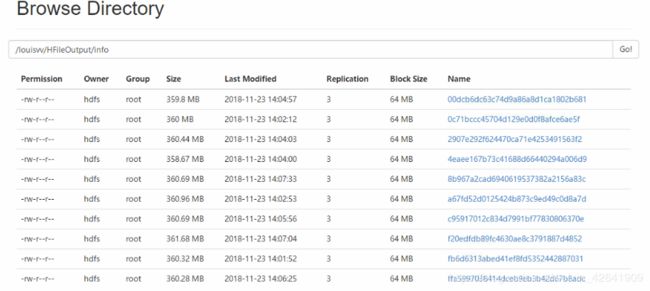
- 查看info目录下的内容,生产的是Region文件
- 使用BuckLoad方法向表中导入数据:
我这里使用的是命令行方式导入,命令如下:
HADOOP_CLASSPATH=`/usr/hdp/2.6.0.3-8/hbase/bin/hbase classpath` hadoop jar hbase-server-1.1.2.2.6.0.3-8.jar completebulkload /yw/HFileOutput user-view
数据导入成功,部分日志如下:
18/11/23 16:29:55 INFO zookeeper.ZooKeeper: Client environment:java.library.path=:/usr/hdp/2.6.0.3-8/hadoop/lib/native/Linux-amd64-64:/usr/lib/hadoop/lib/native/Linux-amd64-64:/usr/hdp/current/hadoop-client/lib/native/Linux-amd64-64:/usr/hdp/2.6.0.3-8/hadoop/lib/native
18/11/23 16:29:55 INFO zookeeper.ZooKeeper: Client environment:java.io.tmpdir=/tmp
18/11/23 16:29:55 INFO zookeeper.ZooKeeper: Client environment:java.compiler=<NA>
18/11/23 16:29:55 INFO zookeeper.ZooKeeper: Client environment:os.name=Linux
18/11/23 16:29:55 INFO zookeeper.ZooKeeper: Client environment:os.arch=amd64
18/11/23 16:29:55 INFO zookeeper.ZooKeeper: Client environment:os.version=3.10.0-514.el7.x86_64
18/11/23 16:29:55 INFO zookeeper.ZooKeeper: Client environment:user.name=hdfs
18/11/23 16:29:55 INFO zookeeper.ZooKeeper: Client environment:user.home=/home/hdfs
18/11/23 16:29:55 INFO zookeeper.ZooKeeper: Client environment:user.dir=/usr/hdp/2.6.0.3-8/hbase/lib
18/11/23 16:29:55 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=ai-main:2181,ai-node3:2181,ai-node4:2181 sessionTimeout=90000 watcher=org.apache.hadoop.hbase.zookeeper.PendingWatcher@757f675c
18/11/23 16:29:55 INFO zookeeper.ClientCnxn: Opening socket connection to server ai-node4/192.168.1.51:2181. Will not attempt to authenticate using SASL (unknown error)
18/11/23 16:29:55 INFO zookeeper.ClientCnxn: Socket connection established to ai-node4/192.168.1.51:2181, initiating session
18/11/23 16:29:55 INFO zookeeper.ClientCnxn: Session establishment complete on server ai-node4/192.168.1.51:2181, sessionid = 0x366665b1dbf0295, negotiated timeout = 60000
18/11/23 16:29:57 INFO zookeeper.RecoverableZooKeeper: Process identifier=hconnection-0x46c3a14d connecting to ZooKeeper ensemble=ai-main:2181,ai-node3:2181,ai-node4:2181
18/11/23 16:29:57 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=ai-main:2181,ai-node3:2181,ai-node4:2181 sessionTimeout=90000 watcher=org.apache.hadoop.hbase.zookeeper.PendingWatcher@38fc5554
18/11/23 16:29:57 INFO zookeeper.ClientCnxn: Opening socket connection to server ai-node3/192.168.1.50:2181. Will not attempt to authenticate using SASL (unknown error)
18/11/23 16:29:57 INFO zookeeper.ClientCnxn: Socket connection established to ai-node3/192.168.1.50:2181, initiating session
18/11/23 16:29:57 INFO zookeeper.ClientCnxn: Session establishment complete on server ai-node3/192.168.1.50:2181, sessionid = 0x2673ae5cb901733, negotiated timeout = 60000
18/11/23 16:29:57 WARN mapreduce.LoadIncrementalHFiles: Skipping non-directory hdfs://cluster/yw/HFileOutput/_SUCCESS
18/11/23 16:29:58 INFO hfile.CacheConfig: CacheConfig:disabled
18/11/23 16:29:58 INFO hfile.CacheConfig: CacheConfig:disabled
18/11/23 16:29:58 INFO hfile.CacheConfig: CacheConfig:disabled
18/11/23 16:29:58 INFO hfile.CacheConfig: CacheConfig:disabled
18/11/23 16:29:58 INFO hfile.CacheConfig: CacheConfig:disabled
18/11/23 16:29:58 INFO hfile.CacheConfig: CacheConfig:disabled
18/11/23 16:29:58 INFO hfile.CacheConfig: CacheConfig:disabled
18/11/23 16:29:58 INFO hfile.CacheConfig: CacheConfig:disabled
18/11/23 16:29:58 INFO hfile.CacheConfig: CacheConfig:disabled
18/11/23 16:29:58 INFO hfile.CacheConfig: CacheConfig:disabled
18/11/23 16:29:59 INFO compress.CodecPool: Got brand-new decompressor [.snappy]
18/11/23 16:29:59 INFO compress.CodecPool: Got brand-new decompressor [.snappy]
18/11/23 16:29:59 INFO compress.CodecPool: Got brand-new decompressor [.snappy]
18/11/23 16:29:59 INFO compress.CodecPool: Got brand-new decompressor [.snappy]
18/11/23 16:29:59 INFO compress.CodecPool: Got brand-new decompressor [.snappy]
18/11/23 16:29:59 INFO compress.CodecPool: Got brand-new decompressor [.snappy]
18/11/23 16:29:59 INFO compress.CodecPool: Got brand-new decompressor [.snappy]
18/11/23 16:29:59 INFO compress.CodecPool: Got brand-new decompressor [.snappy]
18/11/23 16:29:59 INFO compress.CodecPool: Got brand-new decompressor [.snappy]
18/11/23 16:29:59 INFO mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://cluster/yw/HFileOutput/info/f20edfdb89fc4630ae8c3791887d4852 first=80000042581 last=89999917251
18/11/23 16:29:59 INFO mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://cluster/yw/HFileOutput/info/fb6d6313abed41ef8fd5352442887031 first=00000006731 last=09999955271
18/11/23 16:29:59 INFO mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://cluster/yw/HFileOutput/info/ffa5997038414dceb9eb3b42d67b8adc first=70000014781 last=79999981941
18/11/23 16:29:59 INFO mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://cluster/yw/HFileOutput/info/4eaee167b73c41688d66440294a006d9 first=40000093231 last=49999941151
18/11/23 16:29:59 INFO mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://cluster/yw/HFileOutput/info/0c71bccc45704d129e0d0f8afce6ae5f first=1 last=19999956131
18/11/23 16:29:59 INFO mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://cluster/yw/HFileOutput/info/8b967a2cad6940619537382a2156a83c first=90000069581 last=99999997631
18/11/23 16:29:59 INFO mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://cluster/yw/HFileOutput/info/2907e292f624470ca71e4253491563f2 first=30000029371 last=39999882551
18/11/23 16:29:59 INFO mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://cluster/yw/HFileOutput/info/a67fd52d0125424b873c9ed49c0d8a7d first=20000123931 last=29999959681
18/11/23 16:29:59 INFO mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://cluster/yw/HFileOutput/info/00dcb6dc63c74d9a86a8d1ca1802b681 first=50000024931 last=59999976981
18/11/23 16:29:59 INFO mapreduce.LoadIncrementalHFiles: Trying to load hfile=hdfs://cluster/yw/HFileOutput/info/c95917012c834d7991bf77830806370e first=60000015751 last=69999815851
18/11/23 16:29:59 INFO client.ConnectionManager$HConnectionImplementation: Closing master protocol: MasterService
18/11/23 16:29:59 INFO client.ConnectionManager$HConnectionImplementation: Closing zookeeper sessionid=0x2673ae5cb901733
18/11/23 16:29:59 INFO zookeeper.ZooKeeper: Session: 0x2673ae5cb901733 closed
18/11/23 16:29:59 INFO zookeeper.ClientCnxn: EventThread shut down
- 验证
使用hbase shell 查看数据是否存在,就拿这条数据进行测试
56279618741,14781697265,65:85:36:f9:b1:c0,
1539787307-Mozilla/5.0 Macintosh; Intel Mac OS X 10_10_1 AppleWebKit/537.36 KHTML like Gecko Chrome/37.0.2062.124 Safari/537.36-https://dl.lianjia.com/ershoufang/102100802770.html-13660-6860
&&1539786398-Mozilla/5.0 Windows NT 5.1 AppleWebKit/537.36 KHTML like Gecko Chrome/36.0.1985.67 Safari/537.36-https://dl.lianjia.com/ershoufang/102100576898.html-1959-91040
&&1539785462-Mozilla/5.0 Windows NT 10.0 AppleWebKit/537.36 KHTML like Gecko Chrome/40.0.2214.93 Safari/537.36-https://dl.lianjia.com/ershoufang/102100762258.html-12177-53132
进入hbase shell,查找该用户浏览信息
hbase(main):002:0> get 'user-view','56279618741'
COLUMN CELL
info:macAddress timestamp=1542953074902, value=65:85:36:f9:b1:c0
info:phoneNumber timestamp=1542953074902, value=14781697265
info:userViewHistory timestamp=1542953074902, value=[{"time":"1539787307","userAgent":"Mozilla/5.0 Macintosh; Intel Mac OS X 10_10_1 AppleWebKit/537.36 KHTML li
ke Gecko Chrome/37.0.2062.124 Safari/537.36","visitUrl":"https://dl.lianjia.com/ershoufang/102100802770.html","upflow":"13660","downFlow":"
6860"},{"time":"1539786398","userAgent":"Mozilla/5.0 Windows NT 5.1 AppleWebKit/537.36 KHTML like Gecko Chrome/36.0.1985.67 Safari/537.36",
"visitUrl":"https://dl.lianjia.com/ershoufang/102100576898.html","upflow":"1959","downFlow":"91040"},{"time":"1539785462","userAgent":"Mozi
lla/5.0 Windows NT 10.0 AppleWebKit/537.36 KHTML like Gecko Chrome/40.0.2214.93 Safari/537.36","visitUrl":"https://dl.lianjia.com/ershoufan
g/102100762258.html","upflow":"12177","downFlow":"53132"}]
3 row(s) in 0.0420 seconds