前一段时间群里有小伙伴问 lucifer 我一个问题:”immutablejs 是什么?有什么用?“。我当时的回答是:immutablejs 就是 tree + sharing,解决了数据可变性带来的问题,并顺便优化了性能。今天给大家来详细解释一下这句话。
背景
我们还是通过一个例子来进行说明。如下是几个普通地不能再普通的赋值语句:
a = 1;
b = 2;
c = 3;
d = {
name: "lucifer",
age: 17,
location: "西湖",
};
e = ["脑洞前端", "力扣加加"];上面代码的内存结构大概是这样的:
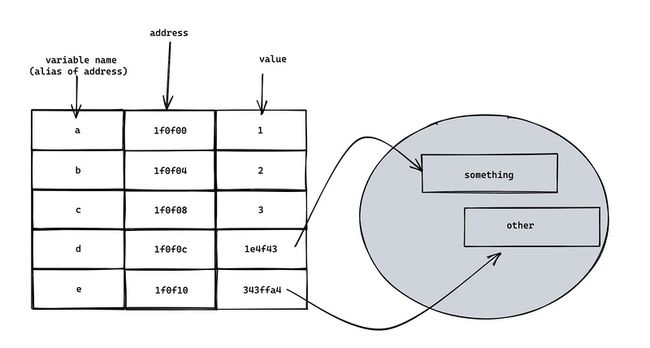
lucifer 小提示:可以看出,变量名( a,b,c,d,e )只是内存地址的别名而已
由于 d 和 e 的值是引用类型,数据长度不确定,因此实际上数据区域会指向堆上的一块区域。而 a,b,c 由于长度是编译时确定的,因此可以方便地在栈上存储。
lucifer 小提示:d 和 e 的数据长度不确定, 但指针的长度是确定的,因此可以在栈上存储指针,指针指向堆上内存即可。
实际开发我们经常会进行各种赋值操作,比如:
const ca = a;
const cb = b;
const cc = c;
const cd = d;
const ce = e;经过上面的操作,此时的内存结构图:
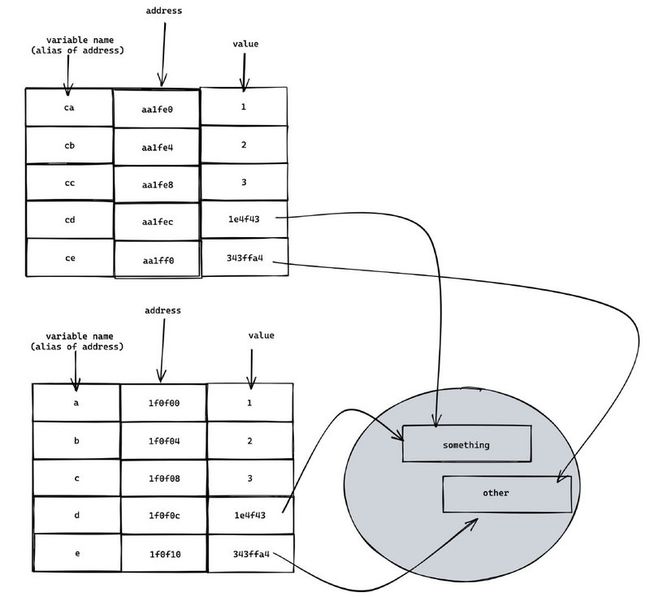
可以看出,ca,cb,cc,cd,ce 的内存地址都变了,但是值都没变。原因在于变量名只是内存的别名而已,而赋值操作传递的是 value。
由于目前 JS 对象操作都是 mutable 的, 因此就有可能会发生这样的 “bug”:
cd.name = "azl397985856";
console.log(cd.name); // azl397985856
console.log(d.name); // azl397985856上面的 cd.name 原地修改了 cd 的 name 值,这会影响所有指向 ta 的引用。
比如有一个对象被三个指针引用,如果对象被修改了,那么三个指针都会有影响。
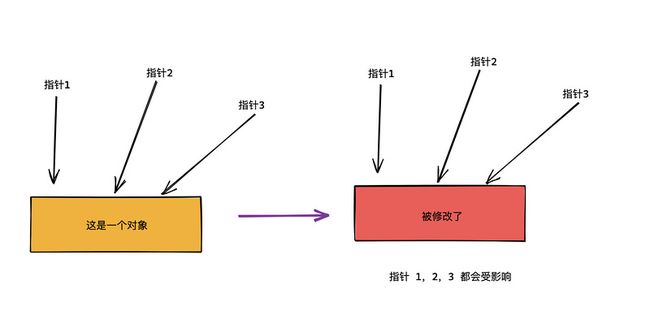
你可以把指针看成线程,对象看成进程资源,资源会被线程共享。 多指针就是多线程,当多个线程同时对一个对象进行读写操作就可能会有问题。
于是很多人的做法是 copy(shallow or deep)。这样多个指针的对象都是不同的,可以看成多进程。
接下来我们进行一次 copy 操作。
const sa = a;
const sb = b;
const sc = c;
const sd = { ...d };
const se = [...e];
// 有的人还觉得不过瘾
const sxbk = JSON.parse(JSON.stringify(e));旁观者: 为啥你代码那么多 copy 啊?
当事人: 我也不知道为啥要 copy 一下,不过这样做使我安心。
此时引用类型的 value 全部发生了变化,此时内存图是这样的:
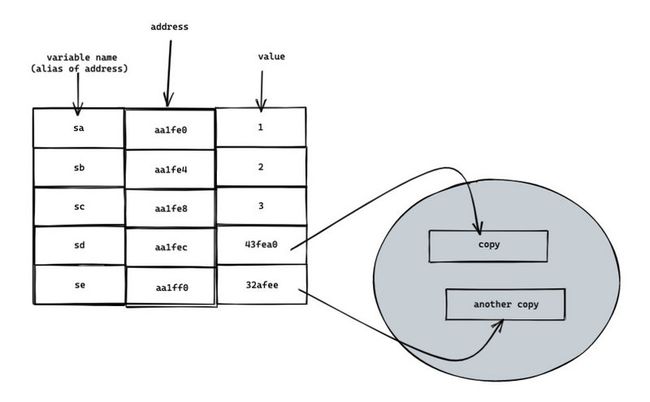
上面的 ”bug“ 成功解决。
lucifer 小提示: 如果你使用的是 shallow copy, 其内层的对象 value 是不会变化的。如果此时你对内层对象进行诸如 a.b.c 的操作,也会有”bug“。
完整内存图:
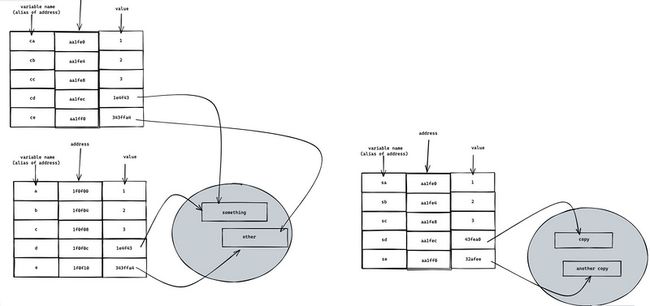
(看不清可以尝试放大)
问题
如果是 shallow copy 还好, 因为你只 copy 一层,但是随着 key 的增加,性能下降还是比较明显的。
据测量:
- shallow copy 包含 1w 个 属性的对象大概要 10 ms。
- deep copy 一个三层的 1w 个属性的对象大概要 50 ms。
而 immutablejs 可以帮助我们减少这种时间(和内存)开销,这个我们稍后会讲。
数据仅供参考,大家也可以用自己的项目测量一下。
由于普通项目很难达到这个量级,因此基本结论是:如果你的项目对象不会很大, 完全没必要考虑诸如 immutablejs 进行优化,直接手动 copy 实现 immutable 即可。
如果我的项目真的很大呢?那么你可以考虑使用 immutable 库来帮你。 immutablejs 是无数 immutable 库中的一个。我们来看下 immutablejs 是如何解决这个性能难题的。
immutablejs 是什么
使用 immutablejs 提供的 API 操作数据,每一次操作都会返回一个新的引用,效果类似 deep copy,但是性能更好。
开头我说了,immutablejs 就是 tree + sharing,解决了数据可变带来的问题,并顺便提供了性能。 其中这里的 tree 就是类似 trie 的一棵树。如果对 trie 不熟悉的,可以看下我之前写的一篇前缀树专题。
immutablejs 就是通过树实现的结构共享。举个例子:
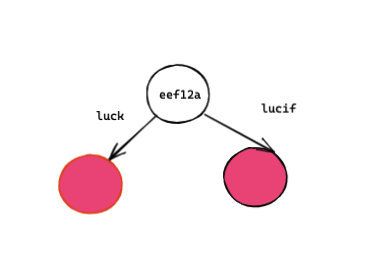
const words = ["lucif", "luck"];我根据 words 构建了一个前缀树,节点不存储数据, 数据存储在路径上。其中头节点表示的是对象的引用地址。
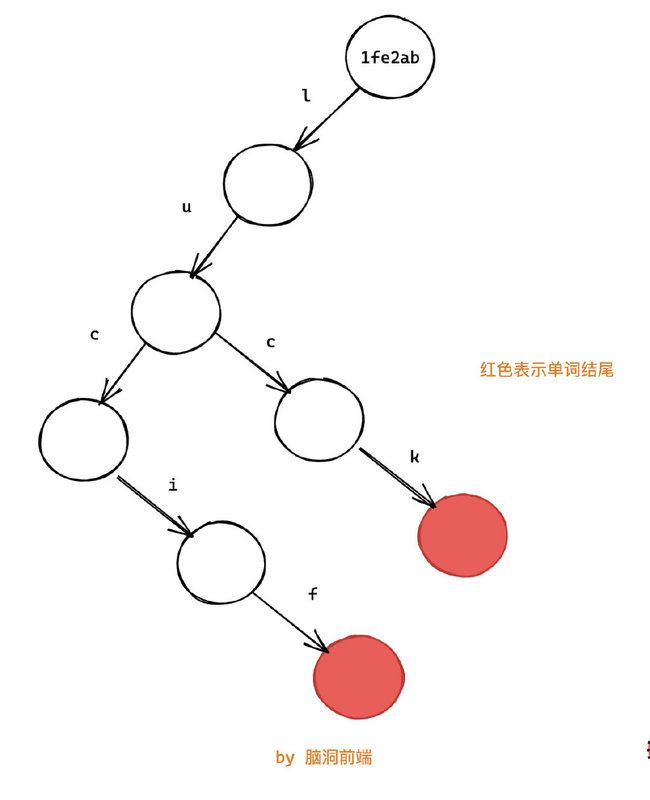
这样我们就将两个单词 lucif 和 luck存到了树上:
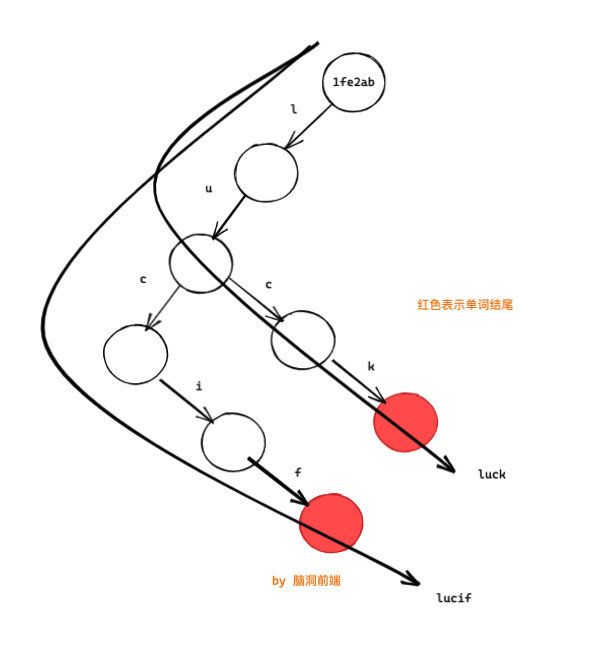
现在我想要将 lucif 改成 lucie,普通的做法是完全 copy 一份,之后修改即可。
newWords = [...words];
newWords[1] = "lucie";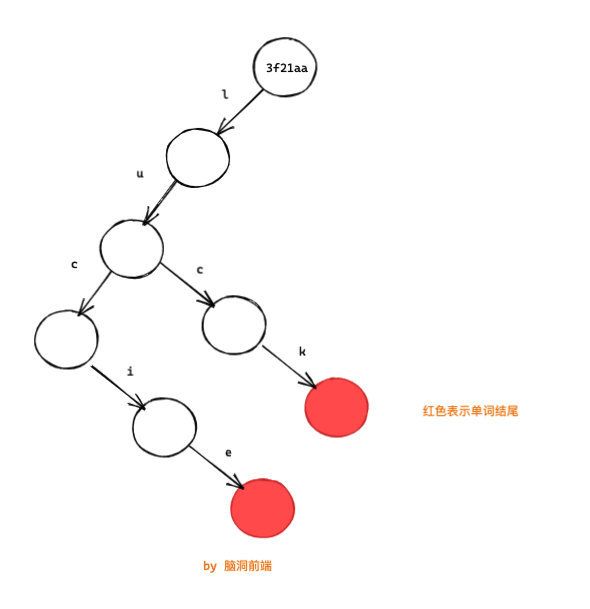
(注意这里整棵树都是新的,你看根节点的内存地址已经变了)
而所谓的状态共享是:
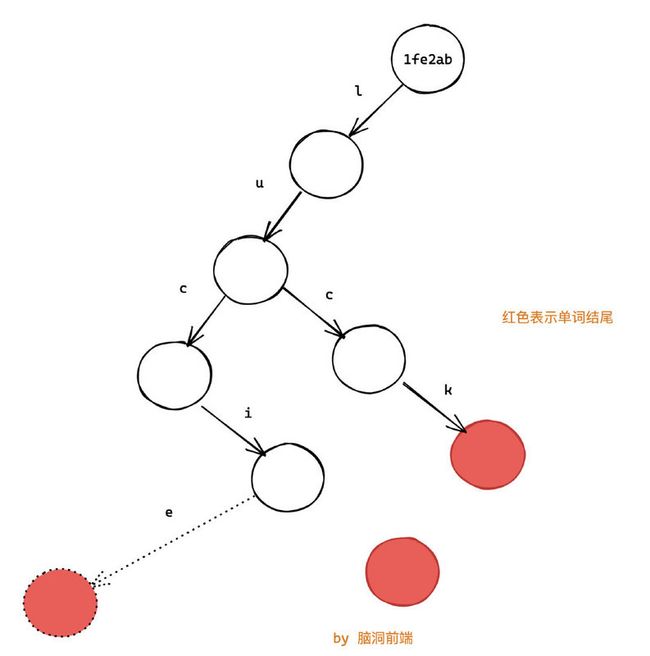
(注意这里整棵树除了新增的一个节点, 其他都是旧的,你看根节点的内存地址没有变)
可以看出,我们只是增加了一个节点,并改变了一个指针而已,其他都没有变化,这就是所谓的结构共享。
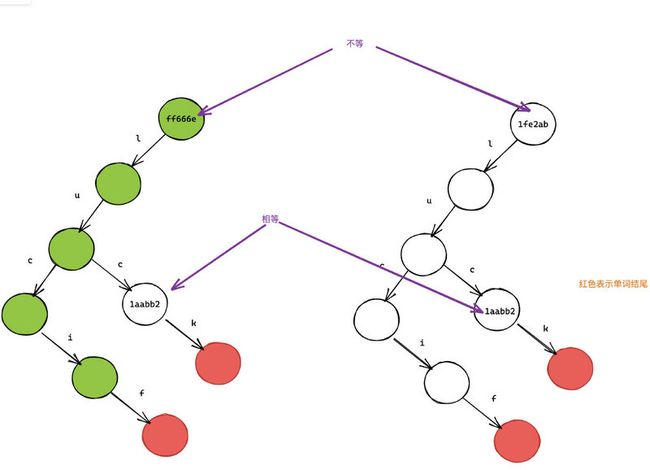
还是有问题
仔细观察会发现:使用我们的方法,会造成 words 和 newWords 引用相等(都是 1fe2ab),即 words === newWords。
因此我们需要沿着路径回溯到根节点,并修改沿路的所有节点(绿色部分)。在这个例子,我们仅仅少修改两个节点。但是随着树的节点增加,公共前缀也会随着增加,那时性能提升会很明显。
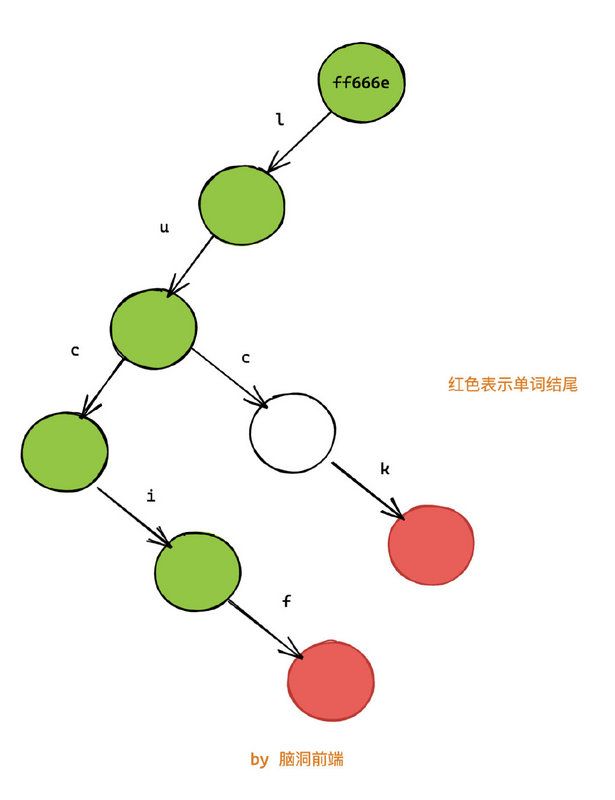
整个过程类似下面的动图所示:
取舍之间
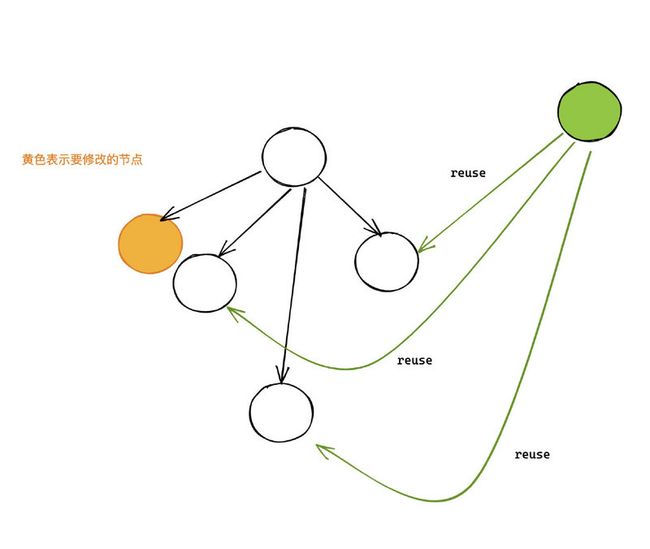
前面提到了 沿着路径回溯到根节点,并修改沿路的所有节点。由于树的总节点数是固定的,因此当树很高的时候,某一个节点的子节点数目会很少,节点的复用率会很低。想象一个极端的情况,树中所有的节点只有一个子节点,此时退化到链表,每次修改的时间复杂度为 O(P),其中 P 为其祖先节点的个数。如果此时修改的是叶子节点,那么 P 就等于 N,其中 N 为 树的节点总数。
树很矮的情况,树的子节点数目会增加,因此每次回溯需要修改的指针增加。如图是有四个子节点的情况,相比于上面的两个子节点,需要多创建两个指针。
想象一种极端的情况,树只有一层。还是将 lucif 改成 lucie。我们此时只能重新建立一个全新的 lucie 节点,无法利用已有节点,此时和 deep copy 相比没有一点优化。
因此合理选择树的叉数是一个难点,绝对不是简单的二叉树就行了。这个选择往往需要做很多实验才能得出一个相对合理的值。
React
React 和 Vue 最大的区别之一就是 React 更加 "immutable"。React 更倾向于数据不可变,而 Vue 则相反。如果你恰好两个框架都使用过,应该明白我的意思。
使用 immutable 的一个好处是未来的操作不会影响之前创建的对象。因此你可以很轻松地将应用的数据进行持久化,以便发送给后端做调试分析或者实现时光旅行(感谢可预测的单向数据流)。
结合 Redux 等状态管理框架,immutablejs 可以发挥更大的作用。这个时候,你的整个 state tree 应该是 immutablejs 对象,不需要使用普通的 JavaScript 对象,并且操作也需要使用 immutablejs 提供的 API 来进行。 并且由于有了 immutablejs,我们可以很方便的使用全等 === 判断。写 SCU 也方便多了。
SCU 是 shouldComponentUpdate 的缩写。
通过我的几年使用经验来看,使用类似 immutablejs 的库,会使得性能有不稳定的提升。并且由于多了一个库,调试成本或多或少有所增加,并且有一定的理解和上手成本。因此我的建议是技术咱先学着,如果项目确实需要使用,团队成员技术也可以 Cover的话,再接入也不迟,不可过早优化。
总结
由于数据可变性,当多个指针指向同一个引用,其中一个指针修改了数据可能引发”不可思议“的效果。随着项目规模的增大,这种情况会更加普遍。并且由于未来的操作可能会修改之前创建的对象,因此无法获取中间某一时刻的状态,这样就缺少了中间的链路,很难进行调试 。数据不可变则是未来的操作不会影响之前创建的对象,这就减少了”不可思议“的现象,并且由于我们可以知道任何中间状态,因此调试也会变得轻松。
手动实现”数据不可变“可以应付大多数情况。在极端情况下,才会有性能问题。immutablejs 就是 tree + sharing,解决了数据可变带来的问题,并顺便优化了性能。它不但解决了手动 copy 的性能问题,而且可以在 $O(1)$ 的时间比较一个对象是否发生了变化。因此搭配 React 的 SCU 优化 React 应用会很香。
最后推荐我个人感觉不错的另外两个 immutable 库 seamless-immutable 和 Immer。
关注我
大家也可以关注我的公众号《脑洞前端》获取更多更新鲜的前端硬核文章,带你认识你不知道的前端。
知乎专栏【 Lucifer - 知乎】
点关注,不迷路!