又双叒叕来更新啦!Hadoop———MapReduce篇
文章目录
- MapReduce(计算)
- MapReduce概述
- MapReduce定义
- MapReduce的优缺点
- 核心思想
- MapReduce计算程序运行时的相关进程
- 官方WordCount源码
- MapReduce编程规范
- 手动实现WordCount
- Windows上Java程序实现
- 集群上运行
- 序列化
- 序列化概述
- 自定义bean对象实现序列化接口
- 实操实现
- MapReduce框架原理
- 数据切片和MapTask并行度决定机制
- Job提交源码过程分析
- Job切片源码
- CombineTextInputFormat切片机制
- 实操测试
- FileInputFormat实现类
- 自定义InputFormat
- 自定义OutputFormat
- MapReduce流程完整分析
- Shuffle机制(重点!!!)
- 数据分区Partition
- 自定义Partition
- WritableComparable 排序
- 排序的分类
- 自定义排序
- 全排序实现
- 区内排序实现
- 合并Combiner
- 代码实现Combiner
- 辅助排序(分组排序)GroupingComparator
- 分组排序代码实现
- MapTask工作流程
- ReduceTask工作流程
- 设置ReduceTask并行度
- Join多种应用
- ReduceJoin
- MapJoin
- 计数器
- 数据清洗
- Hadoop数据压缩
- 常用的压缩编码
- 压缩方式的选择
- 数据压缩的位置选择
- 压缩的相关参数配置
- 数据压缩实操
- 数据流的压缩和解压
- 压缩实例
- 解压实例
- Map和Reduce的输出压缩
- YARN资源调度器
- 工作原理
- 任务调度器
- 任务推测执行
- 推测执行算法原理
- Hadoop企业优化
- 调优的方法
- 小文件处理方法汇总
- 扩展案例
- 案例一:多Job串联
- 案例二:TopN
MapReduce(计算)
MapReduce概述
MapReduce定义
分布式运算程序的编程框架!,是用户开发“基于Hadoop的数据分析应用”的核心框架。
核心功能:
将 用户编写的业务逻辑代码 和 自带默认组件 整合成一个完整的分布式运算程序,并允许再Hadoop集群上。
MapReduce的优缺点
优点:
-
易于编程
简单实写一些接口,就可以完成一个分布式程序。可以分布到大量的廉价的机器上运行。
-
扩展性良好
可以通过增加机器来增强计算能力
-
高容错性
把失效节点上的计算任务自动转移到其他节点上。
-
适合PB以上海量数据的离线处理
缺点:
- 不擅长实时计算
- 不擅长流式计算(流式计算:输入数据的动态的)
- 不擅长DAG(有向图)计算
多个应用程序之间存在依赖关系,后一个程序的输入是前一个程序的输出。这就要求MapReduce需要将计算结果写入磁盘,频繁的IO操作使得工作效率变低。
核心思想

MapReduce的计算过程主要两个阶段Map和Reduce。
过程简单分析:
- 首先是数据输入,并对数据进行分片默认每片128MB
- MapTask阶段,逐行处理数据,并进行排序整理,将数据以KV形式保存。
- 将数据分区整理,整理合成的数据交由Reduce处理
- ReduceTask处理完将数据写入文件并输出。
存在问题
- MapTask和ReduceTask阶段究竟做了什么事情?
- Map阶段的数据和Reduce阶段的是如何衔接的?
- Map阶段的数据分区排序是如何进行?
MapReduce计算程序运行时的相关进程
- MrAppMaster:管理整个程序的过程调度和状态协调
- MapTask:管理Map阶段的数据处理流程
- ReduceTask:管理Reduce阶段的数据处理流程
官方WordCount源码
在hadoop的/share/mapreduce目录中有example的.jar文件,其中就有一个WordCount.class文件,使用工具将其反编译就能看到源码。
发现在源码中有很多数据类型没有见过:
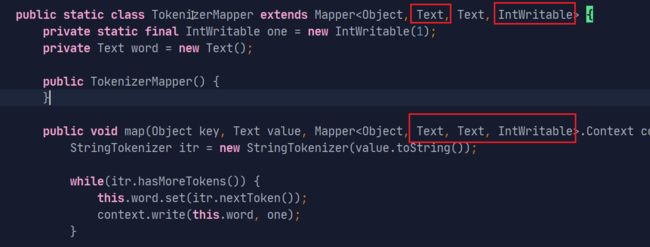
总觉得和Java中的数据类型相似,却又说不清为什么。
其实是由于Hadoop进行了数据序列化,原来的Java数据类型转化为了眼前的Hadoop序列化数据类型
| Java数据类型 | Hadoop Writable类型 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable、VIntWritable(可变长) |
| long | LongWritable、VLongWritable(可变长) |
| float | FloatWritable |
| double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
MapReduce编程规范
分三个阶段:Mapper阶段、Reducer阶段、Driver阶段
Mapper阶段
- 自定义类要继承父类Mapper
- Mapper的输入数据是KV的形式,类型可自定义
- Mapper中的业务逻辑写在
map()方法中 - Mapper的输出数据也是KV形式
- map()方法对每一个输入KV数据只调用一次
Reducer阶段
- 自定义的类要继承Recuder父类
- Reduce的输入数据类型要对应Mapper的输出数据类型!!
- 业务逻辑写在
reduce()方法中 - ReduceTask进程,对一组相同的Key的数据组调用一次reduce()方法。
Driver阶段
相当于Yarn集群的客户端,将整个程序提交到Yarn集群,提交的是封装了MapReduce程序相关运行参数的job对象。
手动实现WordCount
Windows上Java程序实现
-
准备好输入数据文件

-
Maven项目创建
-
依赖导入
<dependency> <groupId>junitgroupId> <artifactId>junitartifactId> <version>4.13version> dependency> <dependency> <groupId>org.apache.logging.log4jgroupId> <artifactId>log4j-coreartifactId> <version>2.12.1version> dependency> <dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-commonartifactId> <version>2.7.7version> dependency> <dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-clientartifactId> <version>2.7.7version> dependency> <dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-hdfsartifactId> <version>2.7.7version> dependency> -
log4j的配置文件参考HDFS笔记
-
程序编码
-
Mapper
-
继承Mapper类,并写明泛型类型:
/** * @author 桜 * @version 1.0 * * KEYIN: 输入数据的 KEY类型,由于我们读取文件,KEY是文件的偏移量,所以使用LongWritable * VALUEIN: 输入数据的Value类型,读取的是文件的内容,是字符串故是 Text * KEYOUT: 输出数据的KEY类型,输出是 <单词,1>的形式所以 是Text * VALUEOUT: 数字1,IntWritable **/ public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { }注意不要导错包
-
简单浏览Mapper类代码
类中只有四个方法,核心代码逻辑主要写在三个方法中:
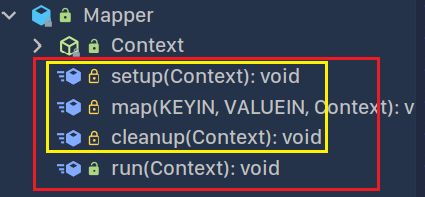
官方的注释中写明了这几个方法的用处:
- setup()在MapTask开始调用一次,可以用于做一些初始化操作
- map()则是核心逻辑代码位置,需要对其进行重写!对每一个输入的KV都会调用一次。
- cleanup()是在MapTask结束时调用一次,可用于资源关闭等操作
- run()将前三个方法进行顺序调度,有经验的可以重写这个方法,自定义控制Mapper的执行流程。
-
没有什么特殊要求,只需要重写map()方法:
在map方法中完成mapper阶段数据处理的逻辑。public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private Text keyOut = new Text(); private IntWritable valueOut = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 获取文件的行 String inputLine = value.toString(); // 对行按空格进行切分,得到单词 String[] words = inputLine.split(" "); // 将单词以
-
-
-
Reducer
-
自定义类继承Reducer,并写明参数泛型
注意!KEYIN,和VALUEIN应该于Mapper阶段的KEYOUT、VALUEOUT对应
/** * @author 桜 * @version 1.0 * @date 2020-6-20 15:37 * @description * KEYIN、和 VALUEIN与Mapper阶段是的KEYOUT、VALUEOUT保存一致 * KEYOUT和VALUEOUT:由于我们预期结果是 <单词,出现次数> 所以分别是 Text和 IntWritable **/ public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { } -
查看源码,结构和Mapper源码大同小异:

只不过要注意的是,reduce()方法针对具有相同key的数据组调用一次,所以方法的第一个参数是数据组的KEY,第二个参数则是一个VALUEIN类型的可迭代的数据,可以用迭代器对此数据组中的VALUE进行迭代。
-
重写reduce()方法,实现reducer阶段的逻辑
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable valueOut = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // 获得values的迭代器 Iterator<IntWritable> iterator = values.iterator(); int sum = 0; // 对values进行迭代累加 while (iterator.hasNext()) { IntWritable value = iterator.next(); int i = value.get(); sum += i; } valueOut.set(sum); // 结果数据写出,key是不变的 context.write(key, valueOut); } }
-
-
Driver
要做以下几件事
- 获取Job对象
- 设置jar包存储目录
- 关联Mapper类Reducer类
- 设置Mapper阶段的输出数据的KV类型
- 设置最终输出数据的KV类型
- 设置输入路径和输出路径
- 提交任务
过程中千万不要导错包!!mapred包都是过时的!!
public class WordcountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 1.获取Job对象 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 2. 设置jar包存储位置,使用class动态指定 job.setJarByClass(WordcountDriver.class); // 3. 关联Mapper类和Reducer类 job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReducer.class); // 4. 设置Mapper阶段的输出数据类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 5. 设置最终输出数据的数据类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 6. 设置输入和输出文件路径,这里直接使用args指定 在我们运行的时候动态指定 // 注意是mapreduce.lib.input.FileInputFormat 不要导错包!! FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7. 提交job,使用waitForCompletion(),参数为true时运行会输出运行信息 boolean result = job.waitForCompletion(true); // 系统退出,提交成功则正常退出exit(0) System.exit(result ? 0 : 1); } }
-
运行配置:
在运行的配置中对应配置好输入文件和输出路径

-
运行
遇见报错(null) entry in command string: null chmod 0700
需要三个文件:winutils.exe、libwinutils.lib、hadoop.dll确保winutils能正常运行,三者保持版本相同。
前面两个拷贝到hadoop的bin目录,第三个拷贝到C:windows/System32目录中
解决方案参考博客:https://ask.hellobi.com/blog/jack/5063
-
查看输出结果:
在指定的输出路径下就有这样四个文件,前俩是校验和不用管,在最后那个文件中就放着计算的输出结果:

结果:

集群上运行
首先要在pom.xml中加上这一段:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<version>3.1.1version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
<archive>
<manifest>
<mainClass>com.sakura.mr.WordcountDrivermainClass>
manifest>
archive>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
在MainClass中指定运行的主类,然后打包,出现下面两个jar包:

将第一个Jar包拷贝到集群上测试使用:
hadoop jar MapReduce-1.0-SNAPSHOT.jar com.sakura.mr.WordcountDriver /user/sakura/input /user/sakura/output
几个注意点:
- YARN服务必须启动
- jar运行必须指定主类:WordcountDriver
- 文件目录使用的是集群的hdfs中的目录。
即使输入目录中有多个文件,也是可以处理的。
第二个jar包是带有依赖的,在Windows上使用 java -jar 并指定主类和输入输出目录也可以运行。
序列化
序列化概述
什么是序列化
序列化,就是将内存中的对象转化成字节数据,便于在网络上进行传输和数据存储。
反序列化,顾名思义就是将字节数据转化为内存中的对象。
为什么要序列化?
内存中的对象,断电即失,想要把对象进行存储和网络传输,直接操作对象是行不通的,必须将对象转化为机器认识的或者网络可以传输的字节数据,后面恢复数据到内存或者再其他主机再现对象,只需要将字节数据反序列化即可。
既然要序列化,Java也可以序列化,为什么还要开发一个序列化框架?
Java的序列化框架 Serializable是一个重量级的序列化框架!一个对象被序列化后,会附带大量的额外信息(校验信息,Header、继承体系等),这种序列化框架适合传输庞大的对象,而对于简单的对象这些额外数据不便于在网络中传输。而Hadoop自研制的序列化机制(Writable)则可以很好解决这个问题。有以下几个优点:
- 紧凑:存储空间高效利用
- 快速:读写数据的开销小
- 可扩展:随着通信协议的升级而升级
- 交互操作:支持多语言交互,没有语言之间的限制
自定义bean对象实现序列化接口
之前我们只提到普通对象的序列化,那些自定义对象则需要手动实现序列化(实现序列化接口)
-
实现Writable接口
-
由于在反序列化中,使用反射调用无参构造,所以对象的无参构造也是要有的
-
重写序列化方法
public void write(DataOutput out) throws IOException { out.writeUTF(name); out.writeInt(age); out.writeChar(sex) } -
重写反序列化方法
public void readFields(DataInput in) throws IOException { name = in.readUTF(); age = out.readInt(); sex = in.readChar() } -
保证序列化方法和反序列方法中数据转化顺序一致!(在传输过程中是类似队列的模式对数据进行传输),所以保证序列一致才能保证对象再现。
-
想要最终展示数据,输出对象的内容,重写toString()方法
-
如果对象需要在计算过程中作为key进行传输,Hadoop框架要求key是支持排序的,所以就还要实现Comparable接口,并重写compareTo()方法,指明比较规则。
实操实现
-
准备输入数据

输入数据:记录编号 电话号 用户名 上传流量 下载流量
期望输出:电话号 上传总流量 下载总流量 总流量
-
封装上传、下载、总和流量成为一个对象并实现Writable接口,重写序列化write()、反序列化readFields()方法,注意顺序保持一致!
并重写toString()方法,务必加上无参构造。
-
Mapper类逻辑编写
public class FlowcountMapper extends Mapper<LongWritable, Text, Text, Flow> { private Flow flow = new Flow(); private Text keyOut = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 获取文件行 String line = value.toString(); // 切割数据 依次为 id,phone,username,upFlow,downFlow String[] values = line.split(" "); // 设置valueOut flow.setUpFlow(Integer.parseInt(values[values.length - 2])); flow.setDownFlow(Integer.parseInt(values[values.length - 1])); flow.setTotalFlow(Integer.parseInt(values[values.length - 2]) + Integer.parseInt(values[values.length - 1])); keyOut.set(values[1]); // 写出 context.write(keyOut, flow); } } -
Reducer类逻辑编写
public class FlowcountReducer extends Reducer<Text, Flow, Text, Flow> { private Flow flow = new Flow(); @Override protected void reduce(Text key, Iterable<Flow> values, Context context) throws IOException, InterruptedException { int upSum = 0; int downSum = 0; int total = 0; // 迭代累加数据 Iterator<Flow> iterator = values.iterator(); while (iterator.hasNext()) { Flow value = iterator.next(); upSum += value.getUpFlow(); downSum += value.getDownFlow(); total += value.getTotalFlow(); } flow.setUpFlow(upSum); flow.setDownFlow(downSum); flow.setTotalFlow(total); // 数据写出 context.write(key, flow); } } -
Driver类编写
public class FlowcountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { args = new String[2]; args[0] = "f:/input/flow.txt"; args[1] = "f:/output"; // 获取Job对象 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 设置Jar job.setJarByClass(FlowcountDriver.class); // 关联Mapper、Reducer job.setMapperClass(FlowcountMapper.class); job.setReducerClass(FlowcountReducer.class); // 设置Mapper阶段输出数据类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Flow.class); // 设置最终数据的数据的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(Flow.class); // 设置输入输出路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 提交job boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } } -
运行并查看输出结果:

输出的数据中Flow对象 可以通过修改toString方法来修改输出格式,减去不必要的信息,便于数据处理。
MapReduce框架原理
数据切片和MapTask并行度决定机制
在Map阶段通过增加MapTask数量的确可以起到加快数据处理的目的,那么多少个MapTask才更适合当前的任务呢?通过什么决定呢?
首先我们要理清两个概念:
-
数据分块
数据分块是在磁盘存储上对文件进行物理分块,是实实在在存在的,不同的块放置在不同的主机上,同时拥有副本。
-
数据切片
数据切片则是逻辑上对数据切片,在处理数据时候按片进行处理。而文件本身并没有被切片。
假设:我们设置切片大小为100MB,要处理的数据是300MB。
由于数据分块的默认大小是128MB,数据被分为三块存放在3个DataNode上,当我们启动MapTask处理数据时,对数据分片就出现了性能问题:
- 数据切片每次100MB,多余的数据就要拷贝到下一个DataNode上使用另一个MapTask处理。
- 频繁的网络IO,大大降低了数据处理的效率
优化:我们将数据切片的大小改为128MB
每个DataNode启动MapTask处理自己的数据,减少了网络IO的过程。
所以综上来看,总结以下几点:
- 一个Job的MapTask的并行度取决于Map阶段的数据分片片数量
- 每一个分片数据分配一个MapTask进行处理
- 默认情况下,切片大小=BlockSize
- 对数据进行切片的时候,是不会考虑整体数据的,针对于单个文件进行切片(例如:一个30M文件 一个150M文件,切片的结果是:30M、128M、22M,文件之间的切片相互独立)
Job提交源码过程分析
在执行waitForCompletion()方法时有几个重要步骤。
以下是逐步分析:
-
在提交之前先要判断Job的State: JobState只有两种状态(DEFINE:定义状态,RUNNING:运行状态)。确认是定义状态才会执行submit().
-
submit()中会再次确认Job状态——
ensureState -
由于旧版过时的API使用变少,使用
setUseNewAPI()来使Job使用新的API。 -
接下来是
connect()-
检查Cluster对象(集群对象):为空则创建一个Cluster
-
会根据程序运行的环境,来判断到底是创建本地模式协议还是YARN集群模式协议


-
可以看出使用的conf都是非常熟悉的一些配置文件
-
-
获得JobSubmitter并提交Job,并将JobState改变为RUNNING
-
提交任务:
submitJobInternal-
checkSpecs(job)检查配置文件的完整性 -
此时这个路径下还什么都没有

-
随后为job设置了JobId

-
jobid和上面那个路径以拼接就得出了一个新的路径
submitJobDir提交Job的路径:
-
copyAndConfigureFiles(job, submitJobDir);拷贝和配置job到这个路径下 -
对数据分片,并将数据写入

切割完之后,这个路径中就有了job的数据分片信息:

-
writeConf(conf, submitJobFile);将配置文件job.xml写入提交文件夹
-
submitClient.submitJob()这里提交了Job就将state转为了Running
-
其实在这个过程中还会将jar包拷贝到文件系统中(不过在yarn集群中才可以看到。)
-
-
-
给出了这个跟踪路径:
这个路径的job_localxxxx_xxxx是通过运行模式协议和Job的唯一ID组合而成的!

有这样几个文件:

job.split文件中有些乱码,但是关键信息仍然可以识别:是一些数据分片的信息:
job.xml:
里面包含着这个Job相关的所有配置信息以及来源。还记得我们入门Hadoop是在查看Job信息的时候,通过网页就能看到Job的所有配置信息

后面source-chain那一栏就明显写明了job.xml正是这个文件!
-
-
判断verbose是否为true来决定是否输出一些Job相关的信息——
monitorAndPrintJob()- 再次期间会执行任务并清除那个文件夹中的所有内容
Job切片源码
对于源码中的切片过程有必要了解一下:回到job提交的submitJobInternal方法的writeSplit()进去一看究竟把:

在此之前以及生成了submitJobFile,即job.xml,等待切片完成会一并将切片信息文件一并写入Job提交文件夹。
-
进入
writeSplits()
-
首先是获取Job的配置信息
-
然后判断是否使用新的Mapper API(YES)然后进入
writeNewSplits()
-
第一步也是获取配置文件,从里面获取InputFormat的class通过反射创建一个InputFormat对象——TextInputFormat
-
进入
getSplits()==重点!!!==这个方法是文件切片的核心!-
首先就是两个指标值

分别表示切片的最大值最小值:
min为1,MAX为Long.MAXVALUE:9223372036854775807

熟悉着俩个值方便后续我们理解如何调整切片大小
-
两个数组,一个存储切片信息,一个放着待切片的数据:

遍历所有输入文件,通过文件路径和文件系统定位到文件,准备切片
-
isSplitable(job, path)判断文件是否可切割-
如果文件没有被压缩编码,是可以切割的,否则就要另当别论了

并不是所有的压缩文件都不可切割!!
-
-
重点来了!!两个重要参数:splitSize、blockSize!

blockSize=33554432???!! (blockSize/1024)/1024 = 32!!

为毛是32M!!说好的128M呢?!
知识提要:
由于是在本地模式下运行,默认就是32M,在Yarn集群上运行,则会恢复到正常的128M,旧版本(1.x)则是64M
重点的重点来了!!splitSize,看代码就直到这个值和minSize(1)、maxSize(Long.MAX_VALUE)、blockSize(33554432)关系紧密!
Math.max(minSize, Math.min(maxSize, blockSize));请背下这个公式!!结果就是blockSize。不出意外默认情况下就是blockSize!!
-
切片规则来了!!!

可以看出按照什么来切片并不是我们想象的那么容易!!
仅当当前文件大小于splitSize比值大于
SPLIT_SLOP才会继续切片,这个值当然不是1
==1.1 !!!==也就是说哪怕切片大小(splitSize)=128M,遇到小于140.8M(128*1.1)的文件都是不会进行切片的哦!!但是实际切片还是每片128M哦!!
-
剩下的文件和不可切割的单独成片
-
-
结束
getSplits(),得到一个文件切割完后的切片List,每个元素对应每一个切片信息:
将其转为数组并排序!
-
最后使用JobSplitWriter将切片数据写到磁盘上(即那个文件夹中)。并返回切片数组的长度。
-
-
writeNewSplits结束获得一个map,也就是切片的数量。
-
-
writeSplits结束,获得map值,并写入到job的配置中:
后面MrAppMaster,会通过这个值来选择启动几个MapTask!!
CombineTextInputFormat切片机制
在默认使用的TextInputFormat的时候,文件之间的切片是独立进行的。所以就会出现小文件单独成片的情况,从而导致大量的小文件就需要大量的MapTask来处理,使得工作效率低下。
CombineTextInputFormat如何解决问题?
在逻辑上将小文件划分到一个切片中,交给一个MapTask处理。
工作过程
首先将小文件进行虚拟存储,然后分别切片。
存储过程需要一个参数指标:虚拟存储切片最大值
CombineTextInputFormat.setMaxInputSplitSize(job,4194304);设置为4M,实际开发应用中应该根据小文件的大小来进行设置。
-
虚拟存储过程
if fileSize < 虚拟存储切片最大值:单独成片存储
else if 虚拟存储切片最大值 < fileSiez < 虚拟存储切片最大值*2:将文件平均切片
else :超出两倍Max的部分按最大值分片。
-
切片规则
若存储的片大于等于 MaxInputSplitSize 单独切片
若不大于和下一个存储片组合,直到大于MaxInputSplitSize(),然后聚合成片。
实操测试
准备好三个小文件作为wordCount的输入文件。
默认方式运行:切片数量是3
![]()
现在我们对wordCountDriver代码稍做修改。
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
在数据分片里面说过,InputFormat是通过反射创建的,默认是TextInputFormat,这里显式设置为CombineTextInputFormat,并设置虚拟存储切片最大值为4M
这次,小文件被化分到一个分片中由MapTask中处理:
![]()
FileInputFormat实现类
其实不管TextInputFormat还是CombineTextInputFormat都是抽象类FileInputFormat的实现类:

mapred包都是旧版的API,基本很少使用。
-
TextInputFormat:按行读取记录。key是当前行首在文件中的偏移量(LongWritable),value则是本行的内容(Text)。友情提示:
在计算偏移量的时候,不要漏掉了结尾的换行符哦!CRLF(回车换行):“\r\n”,LF(换行):“\n”
前者是Window上的换行方式,后者则是Linux上的换行标准,两者都是换行方式。
在计算偏移量的时候,确定文件的换行符号。
Java
Python Ruby
同样的文本,使用CRLF:两行行首位置的偏移量为0,6;使用LF:分别为0,5
-
KeyValueTextInputFormat同样也是按行读取,但是读取的数据类型是(key value),每行数据中第一个Text是Key,第二个Text是value,中间使用
\t隔开(默认),通过conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR,“-”)修改分隔符。若要使用,请在Driver中使用job.setInputFormatClass()指定其class对象
-
NLineInputFormat使用此种InputFormat,切片不再按照Block进行划分,而是按指定的行数N来划分。
文件总行数/N = 切片数量,若结果不为整数,取天花板值。例如文件一共7行,N指定为3则,切片数是3,其中两片包含前六行,最后一片包含最后一行。
Key、Value与TextInputFormat一致。
使用
NLineInputFormat.setNumLinesPerSplit(job,N);来设置N的值.记住使用job.setInputFormatClass()指定
只是切片规则发生了些许变动,map和reduce逻辑实现不受影响。
看了几个FileInputFormat实现类,能不能我们自己写一个FileInputFormat呢?!当我看了以上几个InputFormat后发现一个共同点:就是继承FileInputFormat类,然后实现isSplitable()和createRecordReader()方法。
自定义InputFormat
需求:需要将输入的多个小文件,整理到同一个SequenceFile文件中,其中合并后SequenceFile文件内容为KV形式:Key为每个被合并文件的路径和文件名,Value则为对应的文件内容。
SequenceFile是Hadoop用来存储二进制形式的key-value对的文件格式。
实现步骤:
- 自定义类继承FileInputFormat
- 改写RecordReader,实现一次读取一个完整的文件并将其封装成为KV。
- 使用
SequenceFileOutputFormat输出最终的合并文件
基础代码:
public class DIYFileInputFormat extends FileInputFormat<Text, BytesWritable> {
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return super.isSplitable(context, filename);
}
@Override
public RecordReader<Text, BytesWritable> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
return null;
}
}
注意这里FileInputFormat的KV泛型是
我们需要一个记录读取器(RecordReader),创建一个类并继承RecordReader,并重写其中的所有方法。
重点是在nextKeyValue()方法中实现一次读取整个文件的过程实现的代码
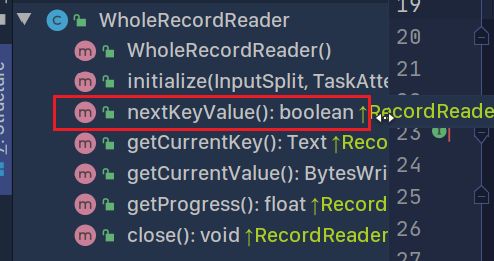
这些函数在哪里使用呢?具体是做什么的呢?
进入到Mapper的源码中:
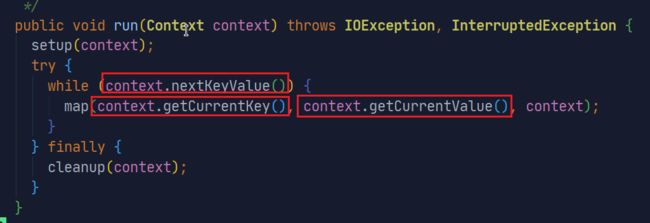
是不是串起来了。
编写RecordReader步骤:
-
通过初始化方法
initalize()和InputFormat连通。createRecordReader()方法的参数和
initalize()参数相同。直接在createRecordReader中调用initalize()并传递参数即可。 -
initalize()中获取两个变量,并提升作用域为全局public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { this.split = (FileSplit) split; conf = context.getConfiguration(); }这里InputSplit转FileSplit是因为我们以及知道我们切片的数据就是File。
-
getCurrentKey(),getCurrentValue()直接返回对应类型的变量即可。@Override public Text getCurrentKey() throws IOException, InterruptedException { return currentKey; } @Override public BytesWritable getCurrentValue() throws IOException, InterruptedException { return currentValue; }这里的currentKey和currentValue都是全局变量,在
nextKeyValue()方法中赋值。 -
close()、getProgress()暂时不做处理。 -
核心来了!!nextKeyValue()
这个方法的任务是什么呢?可以参考参考LineRecordReader中的写法,它的作用就是读取一行的内容封装称KV。
那么我们这个要实现的逻辑应该就是一次读取一个完整的文件,并封装为一个KV-
获取文件路径
split.getPath() -
获取文件系统
想要读取到文件中的内容就需要IO操作,就需要文件系统为我们打开流。
path.getFileSystem(conf); -
通过文件系统和文件路径获取一个流用于读取文件:
fs.open(path) -
使用IOUtils,拷贝文件内容到缓冲区
使用
readFully(),为取保一次读取完毕,使缓冲区和文件长度相同:byte[] buf = new byte[(int) split.getLength()]; IOUtils.readFully(inputStream, buf, 0, buf.length); -
封装Key和Value
// 封装key/value if (currentKey == null) { currentKey = new Text(); currentKey.set(path.toString()); } if (currentValue == null) { currentValue = new BytesWritable(); currentValue.set(buf, 0, buf.length); } -
资源释放,关闭输入流和文件系统

猛然发现这个方法居然是返回一个boolean,表示还有没有东西可读。由于我们每次就读取一个文件,所以我们希望每次执行一次就不再执行,然后读下一个文件。那么直接返回一个false就不会执行
run()方法中的map(),如果直接返回true就会死循环。所以我们加一个标志位控制:第一次执行的时候返回true,第二次执行的时候返回false:完整代码:
public boolean nextKeyValue() throws IOException, InterruptedException { if (isProcess) { // 获取文件路径 Path path = split.getPath(); // 获取文件系统 FileSystem fs = path.getFileSystem(conf); // 获取文件输入流 FSDataInputStream inputStream = fs.open(path); // 拷贝文件内容 byte[] buf = new byte[(int) split.getLength()]; IOUtils.readFully(inputStream, buf, 0, buf.length); // 封装key/value if (currentKey == null) { currentKey = new Text(); currentKey.set(path.toString()); } if (currentValue == null) { currentValue = new BytesWritable(); currentValue.set(buf, 0, buf.length); } // 资源关闭 IOUtils.closeStream(inputStream); fs.close(); // 标志位置为false isProcess = false; return true; } return false; } -
回到DIYFileInputFormat中:
isSplitable()中返回false,告诉程序我们的数据是不可切片的,因为我目的就是将小文件合并,再将它切片毫无意义。
createRecordReader()中,创建一个我们改写的RecordReader,调用其初始化方法,返回这个RecordReader。
public class DIYFileInputFormat extends FileInputFormat<Text, BytesWritable> {
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
@Override
public RecordReader<Text, BytesWritable> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
WholeRecordReader recordReader = new WholeRecordReader();
// 初始化
recordReader.initialize(split, context);
return recordReader;
}
}
自定义Mapper:map()的任务就是将分片的数据写出就行了:
public class MergeFileMapper extends Mapper<Text, BytesWritable, Text, BytesWritable> {
@Override
protected void map(Text key, BytesWritable value, Context context) throws IOException, InterruptedException {
context.write(key, value);
}
}
自定义Reducer:reduce()的任务也是一样
public class MergeFileReducer extends Reducer<Text, BytesWritable, Text, BytesWritable> {
@Override
protected void reduce(Text key, Iterable<BytesWritable> values, Context context) throws IOException, InterruptedException {
// 循环写出
for (BytesWritable value : values) {
context.write(key, value);
}
}
}
其实values中就一个值,也可以不用循环。
Driver类:
有几个注意点:
public class FileMergeDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[2];
args[0] = "f:\\input";
args[1] = "f:\\output";
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FileMergeDriver.class);
job.setMapperClass(MergeFileMapper.class);
job.setReducerClass(MergeFileReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(BytesWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 这里显式写明使用我们自定义的InputFormat
job.setInputFormatClass(DIYFileInputFormat.class);
// 设置OutputFormat为SequenceFileOutputFormat
job.setOutputFormatClass(SequenceFileOutputFormat.class);
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
重点关注设置InputFormat和OutputFormat,千万不要漏了,否则默认使用TextInputFormat和TextOutputFormat
看看输出内容,因为是二进制的存储方式所以难免有乱码,但是基本的内容结构还是清晰可见:

成功将三个文件合并到了一个文件中。
自定义OutputFormat
说完自定义InputFormat,再来谈谈OutputFormat。
先还是来看看FileOutputFormat的实现类:

-
TextOutputFormat将结果记录每一条作为文本行写入到文件,会调用toString()方法
-
SequenceFileOutputFormat这个在我们合并小文件输出的时候用过,其输出可以作为后续MapReduce的输入数据,格式紧凑,容易被压缩。
为什么自定义OutputFormat?
如果MapReduce的输出数据能够直接导入到MySQL、Redis或者HDFS中那该多省事,而==使用自定义的OutputFormat就可以控制最终输出文件的路径和格式!==并且可以灵活对数据分类然后输出到不同的位置!
自定义步骤(与自定义InputFormat类似)
- 继承FileOutputFormat类
- 改写RecordWriter,具体改写输出数据的方法write()
需求:现在又若干个网站,相对这些网站进行分类输出到不同文件,带有数字的网站域名输出到website.log,其他的输出到other.log
实现步骤分析:
Mapper和Reducer都直接将数据内容直接写出,在OutputFormat这里对数据加以判断。
创建到这两个文件的输出流,对应的数据通过对应的输出流写出即可。
代码实现
-
Mapper和Reducer
就直接把数据写出就行了
public class FilterMapper extends Mapper<LongWritable, Text, Text, NullWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 直接写出 context.write(value, NullWritable.get()); } } public class FilterReducer extends Reducer<Text, NullWritable, Text, NullWritable> { @Override protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { // 直接写出 context.write(key, NullWritable.get()); } } -
自定义OutputFormat类
-
创建自定义类继承FileOutputFormat,泛型和Reducer输出泛型一致,并重写
getRecordWriterpublic class FilterOutputFormat extends FileOutputFormat<Text, NullWritable> { @Override public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException { return null; } } -
创建一个RecordWriter类,并继承父类,改写write()、close()方法,并加上一个构造方法,在构造方法中做好初始化准备(例如:获取文件系统,打开输出流)。核心代码在write方法中,数据的输出方式逻辑实现。
public class FilterRecordWriter extends RecordWriter<Text, NullWritable> { private FSDataOutputStream fosWebsite; private FSDataOutputStream fosOther; public FilterRecordWriter(TaskAttemptContext job) { try { // 通过job的配置信息获取文件系统 FileSystem fs = FileSystem.get(job.getConfiguration()); // 打开两个文件的输出流 fosWebsite = fs.create(new Path("f:\\website.log")); fosOther = fs.create(new Path("f:\\other.log")); } catch (IOException e) { e.printStackTrace(); } } @Override public void write(Text key, NullWritable value) throws IOException, InterruptedException { String website = key.toString(); if (website.matches(".*[0-9]+.*")) { website = website + "\r\n"; fosWebsite.write(website.getBytes()); } else { website = website + "\r\n"; fosOther.write(website.getBytes()); } } @Override public void close(TaskAttemptContext context) throws IOException, InterruptedException { IOUtils.closeStream(fosOther); IOUtils.closeStream(fosWebsite); } } -
getRecordWriter()中直接返回
return new FilterRecordWriter(job);
-
-
Driver类
public class FilterDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { args = new String[]{"f:\\input\\websites.txt", "f:\\output"}; Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(FilterDriver.class); job.setMapperClass(FilterMapper.class); job.setReducerClass(FilterReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 这里设置我们自定义的OutputFormat类 job.setOutputFormatClass(FilterOutputFormat.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }虽说其中设置了OutputPath但是和在OutputFormat中设置的输出文件的路径并不冲突,这里的OutputPath只是用于输出执行结果的标志文件_SUCCESS。

-
输出结果查看:
成功分离:

MapReduce流程完整分析
在学习MapReduce之初用一张简易的图显示了job整个工作流程,主要包括两个阶段:
- MapTask
- ReduceTask
中间省略了不少的细节,现在来做一个详细的梳理。
- 客户端传入数据文件
- 按照切片大小对其先按照规则进行数据切片,并同时加载job的配置信息,得到以下几个文件:
- job.split和job.splitmetainfo
- job.xml
- 相关jar包(只有yarn集群模式上才有)
-
掌握这些信息,Yarn ResourceManager就能计算出需要启动多少个MapTask来分别处理这些分片。
-
然后就是
InputFormat和RecordReader出场,每个MapTask都需要这两个东西用于从分片中读取数据。 -
KV形式的数据读入Mapper后,进行一系列的业务逻辑处理,产生了新的KV,这些KV即将送往ReduceTask进行汇总处理。
-
MapTask写出数据,之前我们只知道数据写出,却并不知道写到了哪里去了。现在来认识两个未曾谋面的东西:
OutputCollector(输出收集器),专门用于将MapTask和ReduceTask阶段的数据写出
环形缓冲区,在后面的Shuffle机制会详细聊到,整个环分成两个部分,一个部分写的是KV,另一个部分存放的KV的相关元数据(索引,数据长度,所在分区等)。整个缓冲区的大小默认是100MB,两个部分对向写入数据,当容量大于80%后,反向回写。 -
在环形缓冲区中,KV元数据中就包含了数据的分区信息,按照分区将文件划分若干个区,同一个MapTask中的所有分区不会去到同一个ReduceTask(即每个分区都有对应的ReduceTask,且绝对不会重复)
-
对每个分区中的KV数据,按key的字典顺序进行排序。并序列化磁盘中。到此MapTask的工作完成
-
负责整个job资源调度的MrAppMaster,通过MapTask阶段产生的分区数来决定启动多少个ReduceTask,每个ReduceTask处理固定一个分区。
-
ReduceTask将来自不同MapTask的同一个分区的KV数据合并,通过Reducer阶段的数据处理,并写出到一个文件中(Part-r-xxxx),每个ReduceTask写出的文件不同!
现在再来看这个简易的流程分析图,应该很容易脑补出整流程:
Shuffle机制(重点!!!)
shuffle(洗牌),作用于MapTask之后,ReduceTask之前。包括数据的分区,排序,合并,归并排序,压缩。
数据分区Partition
何为数据分区?
当需求中有多个条件进行判断,并且需要将不同条件的计算结果写入到不同的两个文件中就需要多个ReduceTask,也就必然需要对处理数据按条件进行分区。这里的条件指的就是数据中的key。
何时进行?
数据分区在MapTask写出数据到环形缓冲区之前。
根据什么进行分区,如何执行?
通过调试来解答这个问题:要想执行数据分区,在job中要进行设置:
job.setNumReduceTasks(2);
在Mapper中写出数据的时候,一直深入,直到看到
@Override
public void write(K key, V value) throws IOException, InterruptedException {
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
}
这里的collector就是我们之前说的OutputCollector的其中之一MapOutputCollector。它除了收集了数据的KV,还有数据的分区信息(partition)。我们继续深入看是如何获取的吧:

public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
可以看到默认的取分区的使用的是HashPartition,这只是其中一种:

HashPartition中getPartition()是通过key的hashcode与Integer的最大值 相与 然后对ReduceTask的数量进行取模得到。所以我们无法控制某一个KV分到哪一个分区但是我们能够确定,相同key的KV肯定是在同一个分区中。
看完分区的相关内容,我们来简单看以下OutputCollector是这么把数据写到缓冲区的。collect()方法
首先我们要明确写入的不光是KV的数值,还包括其相关的元数据。来看看有哪些:
-
进入方法,首先是三个数据正确性验证:并且看得出这是一个同步方法,所以过程是单线程操作。
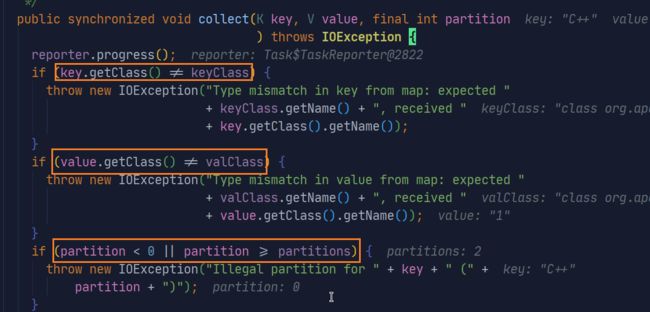
-
缓冲区的大小判断:

这里有一个==softLimit=83886080,这个值刚好就是80M,刚好就是默认缓冲区大小100M的80%!!!bufferRemaining的初始值就等于softLimit,随着数据的不断增加而减少。
-
一旦这个80M被填满了就会触发溢写的操作,也就是写入到磁盘文件中。
-
或者是线程不再工作(即数据读取完毕)也会触发溢写操作。
最终写入的元数据就是这些:

由于我们启动了两个ReduceTask,理所当然就会得到两个文件,且文件之间中key绝对不会出现两者都有的情况。

-
自定义Partition
具体步骤
- 继承Partitioner
- 重写getPartition()方法(根据什么分区)注意:分区的编号从0开始
- 在Driver中设置使用自定义的分区:
job.setPartitionerClass()
注意点:分区的数量与ReduceTask的数量保持一致!!否则ReduceTask数量过少,所有的数据都会放到一个文件中,或者直接报IO异常。数量过多,多出的ReduceTask输出的文件就是空的。
WritableComparable 排序
数据分区完成后,就要对每个分区的数据进行排序操作。记得我们在将序列化的时候,就提到过,如果自定义对象要作为Key进行传输不仅要实现Serializable接口,还要实现Comparable接口,并重写对应的方法。就是因为在排序阶段都是按照key来进行记录排序的!
排序是Hadoop的默认操作,无论业务是否需要,都会进行排序,默认的排序方式是快速排序。
在MapTask阶段,数据被收集放入了环形缓冲区,而不是立即写到磁盘中,当环形缓冲区使用到达预定的阈值(默认80M)时或者所有数据收集完毕,就会对缓冲区中的数据进行一次快速排序。并将排序后的结果溢写到磁盘文件中,当进行了多次溢写后,又会对之前所有溢写的有序文件进行一次归并排序,合并成为一个大的有序文件。
在ReduceTask阶段,先从MapTask生成的有序文件中,取出拷贝数据到内存中!!注意不是磁盘上,当内存使用达到上限的时候,就会将数据溢写到磁盘上,当磁盘上的溢写文件数量达到一定数量就会进行一次归并排序合成一个大的文件。当所有的数据都拷贝完成,统一对内存和磁盘上的所有数据进行一次归并排序。
排序的分类
-
部分排序(区内排序)
当分区有多个时,输出多个文件,保证输出的每个文件内部有序。
-
全排序
最终输出的文件只有一个,且文件的内容有序。在处理大型文件时效率极低。
-
辅助排序
在Reduce端对key进行分组
-
二次排序
在实现了comparable接口的对象排序时,compareTo()方法中排序的指标有两个。
自定义排序
key使用自定义类,自定义类实现Comparable接口,重写int compareTo()方法,在方法中实现排序的逻辑代码。
这样在进行数据排序的时候程序就会根据所写的排序规则来对数据进行排序。
同时实现多个接口(Serializable和Comparable),重写三个方法?Hadoop提供了一个接口,只需要实现一个接口就可以一次重写序列化、反序列化和比较的方法。WritableComparable泛型就填需要序列化和排序的类。
注意:由于排序是在MapTask即将完成的阶段,所以Mapper的自定义类是KEYOUT才有意义。
全排序实现
需求:将手机用户的流量使用情况,按照流量的总量按降序排序。
所以这里我们要使用之前序列化的案例的输出作为本次的输入数据
输入数据:

立项输出数据,将上述数据按照总量进行升序排序
-
修改Flow对象,实现WritableComparable\接口,并重写compareTo()方法
public class Flow implements WritableComparable<Flow> { private int upFlow; private int downFlow; private int totalFlow; public Flow() { } //.. @Override public int compareTo(Flow o) { if (totalFlow > o.totalFlow) { return -1; } else if (totalFlow < o.totalFlow) { return 1; } else { return 0; } } }其他的地方保持不变。
-
Mapper类
public class FlowSortMapper extends Mapper<LongWritable, Text, Flow, Text> { Flow keyOut = new Flow(); Text valueOut = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 解析文本获取数据 String flowValue = value.toString(); String[] values = flowValue.split("\t"); // 输入数据行:13469819044 3366 14199 17565 keyOut.setUpFlow(Integer.parseInt(values[1])); keyOut.setDownFlow(Integer.parseInt(values[2])); keyOut.setTotalFlow(Integer.parseInt(values[3])); valueOut.set(values[0]); context.write(keyOut, valueOut); } }和以前一样直接写出,会自动进行排序。唯一要注意的是,在继承Mapper的时候,后面的KEYOUT、VALUEOUT的泛型不要写错了,KEYOUT是我们进行排序主体!
-
Reducer类
public class FlowSortReducer extends Reducer<Flow, Text, Text, Flow> { @Override protected void reduce(Flow key, Iterable<Text> values, Context context) throws IOException, InterruptedException { // 直接循环写出 流量相同的一组电话号 for (Text value : values) { context.write(value, key); } } }由于我们最终输出的数据是电话号在前,流量情况在后。所以输出的泛型要还原成输入数据的样子,泛型要进行调换。
每次reduce中处理的是key相同的(即流量使用相同的)的一组value(手机号),所以只需要循环写出就可以了。 -
Driver类
public class FlowSortDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { args = new String[2]; args[0] = "f:\\output\\part-r-00000"; args[1] = "f:\\sortedOutput"; Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(FlowSortDriver.class); job.setMapperClass(FlowSortMapper.class); job.setReducerClass(FlowSortReducer.class); job.setMapOutputKeyClass(Flow.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Flow.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } } -
输出结果查看:

数据已经按照我们的要求排好序了。
区内排序实现
之前实现的是全排序,所有的输出数据集中在一个文件中。而在数据进行分区的时候也希望每个分区的数据是有序。实现起来也非常简单,只需要在全排序的基础上写一个自定义Partition,写好分区逻辑,然后再Driver类中设置使用自定义的Partition类,以及ReduceTask的数量即可,排序的工作仍然交给Hadoop自动完成。
合并Combiner
什么是Combiner?
Combiner是Mapper和Recuder之外的一个组件,在MR执行过程中是一个可选项。Combinner的父类是Reducer。主要用于局部数据汇总。是一种MapReduce框架的优化手段。

Combiner的作用?
在Mapper阶段会排序、分区,每个分区中都有大量的KV对,这些KV对中总有一些相同的Key。普通的方式是通过网络传输到ReduceTask所在的节点然后交给Reducer进行value汇总。这样就有大量的网络传输消耗,而Combinner就是在传输之前对MapTask所在节点的数据进行局部汇总然后在传输给ReduceTask,这样Reducer拿到的数据就是已经汇总过一次的数据了,后续的汇总工作就会简单很多,并且大大降低了网络传输消耗。
有什么局限?应用场景?
局限在于,提前汇总以后Reducer并不能具体知道Mapper阶段产生的每一个Value的值或者多个Key产生了这些Value,而只能知道这些Value的汇总值。对于求均值是十分不利的。极易出现差错
Combiner的应用前提是不影响最终的业务逻辑。
例如:两个MapTask分别产生了{
假如我要得出Key=xs的所有value的均值:
普通方式:(80+70+90)/3=260/3;
使用Combiner后:第一个MapTask的数据进行一次汇总=> {
结果计算:(150+90)/2=120;
显然以上两个结果有很大出入。后者Reducer只知道MapTask一中xs的value汇总值是150,却并不清楚150是多少个KV汇总而成,求均值产生错误。
但是在汇总数据这一块Combiner是一个称职的好帮手!
代码实现Combiner
-
创建一个Combiner自定义类,继承Reducer
注意泛型,输入是Mapper的输出,只是汇总并不需要改变数据所以输出和输入(Mapper的输出)的类型一样。这样Combiner在Mapper和Ruducer之间就是一个可有可无的选项。
-
重写reduce()方法,方法中只需要完成对MapTask阶段的数据进行局部汇总。
-
在Driver中设置CombinerClass
job.setCombinerClass(..)
如果1,2步的实现步骤和Reducer的实现步骤完全一致,(即两者只有类名不同)可以直接使用Reducer.class 代替Combiner.class
辅助排序(分组排序)GroupingComparator
分组排序是什么?
分组排序在Reducer端进行,对于从MapTask阶段拷贝过来的数据按照Key进行分组,然后组内进行排序。
出现的原因及其作用
ReduceTask一般都是从多个MapTask中拷贝数据进行处理。多处拷贝的数据并不能保证有序,所以需要对这些数据进行再次排序,这次排序在Reduce端完成(这是一次归并排序)。然后数据又会按照key或者指定的要求进行分组,每一组集中处理调用一次reduce(),分组排序对找到数据中TopN非常有帮助。
特殊之处:
当我们传输的数据的Key使用的是自定义的对象的时候,Reducer在处理数据的时候默认是KEY相同的数据作为一组调用一次reduce()方法,而自定义对象中有很多属性,想要保证完全一致是不可能的,GroupingComparator就可以自定义组划分的依据,比如key对象中只要一个属性是相同就视为是同一组。这样即时是KEY对象不完全相同,只要指定的属性是相同的就可以划分到一个组中同时处理。
分组排序代码实现
需求:现在有一批订单交易数据,要求挑选出每个订单中价格最高的商品交易记录。
输入数据:
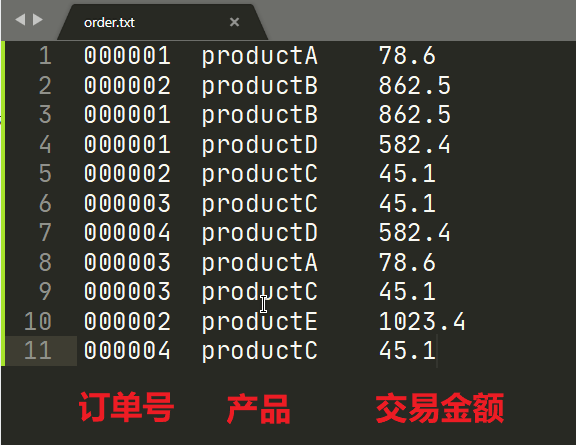
期望输出数据

-
订单类
我们将订单号和交易金额封装成订单类,并继承WritableComparable
public class Order implements WritableComparable<Order> { private int orderId; private double price; public Order() { } /** * @param o * @return * 二次排序,订单号升序,订单号相同,按价格降序 */ @Override public int compareTo(Order o) { int result; if (orderId > o.getOrderId()) { result = 1; } else if (orderId < o.getOrderId()) { result = -1; } else { result = (price > o.getPrice()) ? -1 : 1; } return result; } @Override public void write(DataOutput out) throws IOException { out.writeInt(orderId); out.writeDouble(price); } @Override public void readFields(DataInput in) throws IOException { orderId = in.readInt(); price = in.readDouble(); } //..getter() setter() toString() } -
Mapper类
由于这个情况特殊,Mapper阶段输出只有KEY,而没有VALUE
public class OrderSortMapper extends Mapper<LongWritable, Text, Order, NullWritable> { private Order order = new Order(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String orderInfo = value.toString(); String[] values = orderInfo.split("\t"); order.setOrderId(Integer.parseInt(values[0])); order.setPrice(Double.valueOf(values[2])); context.write(order, NullWritable.get()); } }VALUE类型直接使用NullWritable表示是一个空值。写出的时候,不能用NULL!!!!使用NullWritable.get()
-
Reducer类
public class OrderSortReducer extends Reducer<Order, NullWritable, Order, NullWritable> { @Override protected void reduce(Order key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key, NullWritable.get()); } }由于是要得到每个订单的交易额最大值,所以写出排序后的第一条数据就可以了
-
Driver类
public class OrderSortDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { args = new String[]{"f:\\input\\order.txt", "f:\\output"}; Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(OrderSortDriver.class); job.setMapperClass(OrderSortMapper.class); job.setReducerClass(OrderSortReducer.class); job.setMapOutputKeyClass(Order.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(Order.class); job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } } -
首次启动测试:
经过 调试可以看出每次调用reduce()只有一个KV被处理,结果也就所所以的订单信息都被输出了,并没有达到想要的结果:

其中的原因就是即时是订单号相同的Order,由于Key不是完全相同所以无法归到同一个组中进行集中处理。
-
GroupingComparator类
这个类就是实现让程序判断只要订单号相同就划分到一组中并排好序。
-
继承
WritableComparator并重写compare()方法父类中提供了三种方式,根据实际情况而定,本需求就是WritableComparable对象之间的比较。

-
添加一个空参构造,调用父类的构造传入组内排序的类的Class,和一个true。至于为什么是true,有何作用调试再看
public class OrderSortGroupingComparator extends WritableComparator { public OrderSortGroupingComparator() { super(Order.class, true); } @Override public int compare(WritableComparable a, WritableComparable b) { int result; Order orderA = (Order) a; Order orderB = (Order) b; if (orderA.getOrderId() < orderB.getOrderId()) { result = -1; } else if (orderA.getOrderId() > orderB.getOrderId()) { result = 1; } else { result = 0; } return result; } }-
Driver中设置一下
job.setGroupingComparatorClass(..);
-
-
再次启动查看结果:
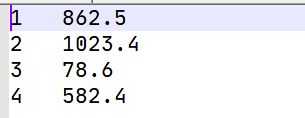
一步步调试来看看结果:
这次调试,只调用了4次reduce(),那么也就是说我们成功将这些订单号相同的数据归到了一组中。并且深入调试可以发现,那个compare()方法在reduce()之前就进行了调用。
关于之前的调用WritableComparator()的构造并设置了一个为true的参数。我们看看这个true发挥着什么作用:
源码:
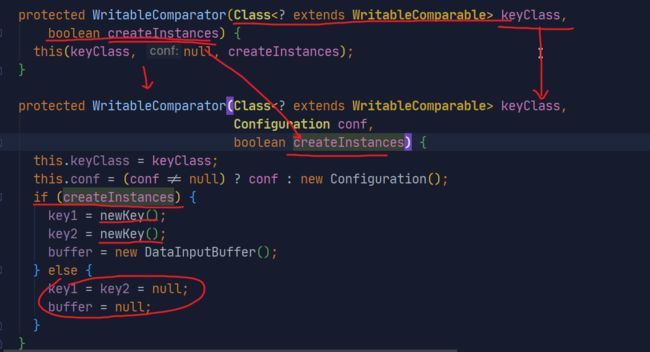
这个true,就控制在进行比较的时候是否创建对象,若为false,直观的看参与比较的就是两个空值肯定会报异常的,所以一般设置为true比较好。而且第一个参数就是我们进行比较的Key的类的Class对象。
MapTask工作流程
- RecordReader读取文件
- Map阶段:解析读入的信息分离出数据
- Collect阶段:收集数据及其元数据(分区,起始位置,索引等),并写入到环形缓冲区
- 溢写阶段,将环形缓冲区的内容写到本地文件中(此阶段还包括了分区排序)
- Combine阶段(可选):将MapTask的输出数据进行局部汇总
ReduceTask工作流程
- Copy阶段:将MapTask产生的数据拷贝指定的分区到内存中,超过预定的阈值则溢写到磁盘上。
- Merge阶段:所有数据拷贝完成之后,将所有的溢写文件和内存中的数据合并到一起。
- Sort阶段:使用归并排序使得合并的数据文件内部有序。
- Reduce阶段:按照业务逻辑分批(默认Key相同为一批)处理这些数据,并将结果输出到文件中。
设置ReduceTask并行度
ReduceTask的数量是会影响到Job的执行效率的,之前在MapTask的并行度决定机制中提到==MapTask的并行度由系统计算数据切片的数量决定。==而在数据分区的时候,我们却可以由我们手动调整ReduceTask的数量job.setNumReduceTasks(2);,但是前提是分区的数量要大于1。
几个注意点!
-
ReduceTask的数量并不是越大越好,而是要根据集群的性能和业务需求进行综合判断
-
ReduceTask=0的时候,表示没有ReduceTask,输出的文件个数和MapTask个数一致
-
默认的ReduceTask的数量是1,也就是默认输出一个文件。
-
当设置多个ReduceTask的时候,可能产生数据倾斜的情况,出现每个ReduceTask处理数据不均匀的情况。
-
当MapTask阶段的分区数>1,但是ReduceTask只有一个,是不会进行数据分区的,反正到头来都是到一个ReduceTask上进行处理。进行分区处理的前提就是(ReduceNum>1)。
相反,分区数是1,但是ReduceTask的数量>1,正常执行但是只有一个有效的输出文件,其他的都是空文件。
Join多种应用
Join是什么?
看到Join首先想到的是SQL里面表连接使用的Join关键字,而这里的Join也不例外,同样也是用于连接多张数据表而生的,我们开发时的数据不可能单从一张表中获取,大部分都是连接其他表然后组合获取最终的结果。就像MySQL的查询也肯定不是查一张表就能拿到数据,大部分时间我们都是连接其他表然后组合相关列才能拿到最终的结果。
Join有哪些实现呢?
ReduceJoin和MapJoin
ReduceJoin
工作原理
Map端的主要工作:为来自不同表或者文件的KV对,打标签以区别不同的来源记录。然后用连接字段作为key,其余部分和新加的标志作为value。
Reduce端的主要工作:将Map端传入的数据进行分组(key是表连接字段),在同一个分组中通过标签将来自不同表/文件的记录分离,然后进行字段合并。
连接字段:就是两张表通过哪个字段进行关联,相当于 SQL中 join…on…的字段
实操
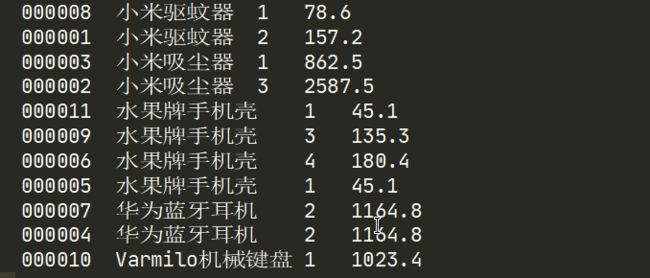
案例需求:现有两张表:订单表和产品表:

联合两张表得出以下格式的表:
| 订单号 | 产品名 | 数量 | 总价 |
|---|---|---|---|
| 000001 | 小米驱蚊器 | 2 | 157.2 |
需求分析,步骤:
-
创建一个表类:包括所有表的所有字段,并实现Writable接口,重写序列化和反序列化方法。重写的toString()输出格式和需求一致。
-
Map阶段,分别从文件中读取数据并标记上数据来源,使用连接字段作为Key,此案例中连接字段是产品编号,将这些记录封装成KV,最终得到一下这个表:
产品编号 订单号 产品名 数量 单价 总价 来源 productA 000001 2 bill productB 000002 3 bill … … … … productA 小米驱蚊器 78.6 product productB 小米吸尘器 865.2 product … … … … 按key经过排序后:
产品编号 订单号 产品名 数量 单价 总价 来源 productA 000001 2 bill productA 000008 1 bill productA 小米驱蚊器 78.6 product … … … … productB 000002 3 bill productB 小米吸尘器 865.2 product … … … … -
Reduce阶段,拿到排序好的表,每一组相同的key的数据会进入一次reduce()
在同一组(Key相同)数据中肯定只有一条来自product表的记录和若干条订单记录,将其分离开,然后分别从记录中抽出需要的数据并并封装成目标对象:
订单号 产品名 数量 总价 000001 小米驱蚊器 2 157.2
代码实现:
-
表类
public class TableBean implements Writable { private String productCode; private String billId; private String productName; private int productNum; private double price; private double totalPrice; // 记录来源 private String source; public TableBean() { } @Override public void write(DataOutput out) throws IOException { out.writeUTF(productCode); out.writeUTF(billId); out.writeUTF(productName); out.writeInt(productNum); out.writeDouble(price); out.writeDouble(totalPrice); out.writeUTF(source); } @Override public void readFields(DataInput in) throws IOException { productCode = in.readUTF(); billId = in.readUTF(); productName = in.readUTF(); productNum = in.readInt(); price = in.readDouble(); totalPrice = in.readDouble(); source = in.readUTF(); } @Override public String toString() { return billId + "\t" + productName + "\t" + productNum + "\t" + totalPrice; } // Getter Setter } -
Mapper类
这里我们不能只重写map()方法了,还要setup()中先做好文件读取的准备,两个文件在分片的时候划为两个分片,每次读取一个文件调用一次setup(),在这里就要判断读取的是哪个文件,方便我们打标签。
public class ReduceJoinMapper extends Mapper<LongWritable, Text, Text, TableBean> { private String from; private Text code = new Text(); private TableBean valueOut = new TableBean(); @Override protected void setup(Context context) throws IOException, InterruptedException { // 从分片中获取文件名 FileSplit split = (FileSplit) context.getInputSplit(); from = split.getPath().getName(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] fields = line.split("\t"); // 读取订单文件 if (from.startsWith("bill")) { //000001 productA 2 valueOut.setBillId(fields[0]); valueOut.setProductCode(fields[1]); valueOut.setProductNum(Integer.parseInt(fields[2])); valueOut.setPrice(0); valueOut.setTotalPrice(0); valueOut.setProductName(""); valueOut.setSource("bill"); } else { // 读取产品文件 //productA 小米驱蚊器 78.6 valueOut.setProductCode(fields[0]); valueOut.setProductName(fields[1]); valueOut.setPrice(Double.valueOf(fields[2])); valueOut.setBillId(""); valueOut.setTotalPrice(0); valueOut.setProductNum(0); valueOut.setSource("product"); } code.set(valueOut.getProductCode()); context.write(code, valueOut); } } -
Reducer类
在Reduce中拿到已经排序的好带有标签的表,对每一组记录,分离出一条产品记录和若干条订单记录
public class ReduceJoinReducer extends Reducer<Text, TableBean, TableBean, NullWritable> { @Override protected void reduce(Text key, Iterable<TableBean> values, Context context) throws IOException, InterruptedException { List<TableBean> bills = new ArrayList<>();; TableBean product = new TableBean(); for (TableBean value : values) { if ("bill".equals(value.getSource())) { TableBean tmp = new TableBean(); try { BeanUtils.copyProperties(tmp, value); bills.add(tmp); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (InvocationTargetException e) { e.printStackTrace(); } } else{ try { BeanUtils.copyProperties(product, value); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (InvocationTargetException e) { e.printStackTrace(); } } } for (TableBean bill : bills) { double total = bill.getProductNum() * product.getPrice(); bill.setTotalPrice(total); bill.setProductName(product.getProductName()); context.write(bill, NullWritable.get()); } } }里面使用了
BeanUtils.copyProperties(),是为了将真实对象的数据取出来,否则存的都是引用没有意义。但是Apache的BeanUtils进行属性拷贝,性能较差,替换解决方案有:Spring BeanUtils,Cglib BeanCopier或者纯粹使用get Set。 -
Driver
就是普通的Driver,唯一不同的就是设置输入路径时设置了多个文件的路径:
public class ReduceJoinDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { args = new String[]{"f:\\input\\bill.txt", "f:\\input\\product.txt", "f:\\output"}; Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(ReduceJoinDriver.class); job.setMapperClass(ReduceJoinMapper.class); job.setReducerClass(ReduceJoinReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(TableBean.class); job.setOutputKeyClass(TableBean.class); job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0]), new Path(args[1])); FileOutputFormat.setOutputPath(job, new Path(args[2])); boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } } -
运行并查看结果:
MapJoin
在使用ReduceJoin的时候发现,大部分的表连接的工作都在Reduce端完成,而Map端就仅仅只是打标签的工作,这未免有点太不公平了。既然Map打完标签就丢给Reduce去做分离,那么也肯定可以在Map端先分离完成再交给Reduce。
适用场景:
当需要对多张表进行合并,且其中有多张小表,和若干张大表的时候,可以将小表读入到缓存中,然后完成对表的合并就可以大大提高效率。如果业务只是表的合并的话,甚至可以省略Reduce阶段,全权交给Map阶段完成。
优点
不会发生Reduce端的数据倾斜问题。
具体步骤
-
在Setup()方法中,将小表的文件读入到缓存集合中。可以用Hashmap来作为表的缓存集合。
- context.getCacheFiles();获取缓存文件的URI,转换成Path。
- 创建一个BufferedReader,用于读取缓存文件
- 对缓存文件内容逐行读取,并对每一行数据进行切割,存入HashMap中留作备用
-
首先要在驱动类中加载缓存到job中
job.addCacheFile(new URI(file://f:/xx/xx)) -
map()方法中正常读取大表文件,切割数据,在需要用到小表的数据的时候,直接从HashMap中取出即可,对表数据完成拼接合并。然后直接写出。
注意在这个过程中可以完全不用Reduce,在驱动类中用job.setNumReduceTasks(0);表示不使用ReduceTask。数据也可以直接写出到文件中,Driver类中也不必设置Mapper的输出KV类型。
计数器
在我们每次运行一个MapReduce程序的时候,控制台的输出中都包含了大量的数据信息,包括读取的数据字节数,处理的记录数,输入的记录数,输出的记录数等等。这些数据可以方便我们对job的执行过程有更准确的把握。方便我们对job的执行情况进行监控。
定制自己的计数器:计数器API
-
采用枚举的方式统计计数
enum MyCounter{MALFORMED,NORMAL}
// 对枚举定义的计数器+1
context.getCounter(MyCounter.MALFORMED).increment(1);
-
采用计数器组,计数器名称的方式统计
context.getCounter(“counterGroup”,”counter”).increment(1);
数据清洗
何为数据清洗?
简单的来说,数据清洗就是将从数据源中采集的数据进行一次过滤,只留下我们需要的数据。其实之前的对数据分割,然后留下有用的信息这也可以算作是一种简单的数据清洗。
数据清洗完全可以在Map端完成,无需ReduceTask。
实操(数据清洗+计数器)
需求:还是以网站的那个文件作为输入文件,要求只写出网站的域名中不带数字的,(其实这种只是普通的数据清洗,所以看起来比较容易,真实的开发中,数据清洗要对记录中的每个字段进行分析。),并统计出网站中包含数字的网站个数,和不包含数字的网站个数。

-
Mapper类:
public class DataCleanMapper extends Mapper<LongWritable, Text, Text, NullWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String website = value.toString(); boolean result = parseValue(website, context); if (result) { context.write(value, NullWritable.get()); } else { return; } } private boolean parseValue(String value,Context context){ if (value.matches(".*\\d+.*")) { // DataClean组下的withNum计数器加一 context.getCounter("DataClean", "withNum").increment(1); return false; } else { // ... context.getCounter("DataClean", "withoutNum").increment(1); return true; } } } -
Driver
public class DataCleanDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { args = new String[]{"f:\\input\\websites.txt", "f:\\output"}; Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(DataCleanDriver.class); job.setMapperClass(DataCleanMapper.class); // Reducer个数设置为0,不启用Reducer job.setNumReduceTasks(0); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }直接从Mapper端写出,可以不用设置MapOutputKeyClass和MapOutputValueClass。
-
运行结果查看:
-
输出结果:

这个文件名有点和平时不一样,平时都是part-r-00000x,这里是part-m-00000x,不用说也知道是怎么回事吧。
-
看控制台输出的计数器:

OHOHOHOHOHOHOHOHOHOHOH!OHOHOHOHOHOHOH!
-
Hadoop数据压缩
什么是数据压缩?为什么采用数据压缩?
Hadoop所在的应用场景中,往往伴随着大量的数据传输,也就意味着有频繁的数据磁盘IO操作和网络IO操作,所以文件的大小通常就决定了IO操作的消耗的磁盘资源和网络带宽,间接影响到了MapReduce的执行效率。
数据压缩,可以在不影响文件内容的情况下对文件数据采用特定的算法,减少底层存储系统的读写字节数,提高传输效率,在数据规模巨大和工作负载密集的情况下十分有用。
任何情况都要用数据压缩吗?
数据压缩在某些场景下,数据压缩确实能提高MapReduce的工作性能,但是也并不是所有的数据都要进行压缩,也并非所有的数据都可以压缩。数据压缩并不是毫无成本的,使用压缩算法压缩数据是需要CPU进行运算的,尽管压缩也解压的CPU资源消耗并不多,但是频繁集中的数据解压压缩也会给CPU增加运算负担。
压缩运用得当可以提高Hadoop的运行效率,运用不当则会降低性能!
采用压缩的基本原则:
- 运算密集型(数据需要复杂的计算,且多次数据运算之间间隔很短):少用压缩
- IO密集型(经常对数据进行IO操作):多用压缩
常用的压缩编码
| 压缩格式 | 是否自带? | 算法 | 文件扩展名 | 是否可切片? | 压缩后,是否需要修改原程序? |
|---|---|---|---|---|---|
| DEFLATE | Y | DEFLATE | .deflate | N | N,和处理文件一样 |
| Gzip | Y | DEFLATE | .gz | N | N |
| Bzip2 | Y | bzip2 | .bz2 | Y | N |
| LZO | N | LZO | .lzo | Y | 需要建索引,指定输入格式 |
| Snappy | N | Snappy | .snappy | N | N |
各种压缩格式对应的编码/解码器
| 压缩格式 | 编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | org.apache.hadoop.io.compress.GzipCodec |
| Bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
压缩方式的选择
-
Gzip
优点:压缩率高,压缩解压速度快。压缩后的文件不需要做特殊处理,和处理文本一样。大多数Linux系统都自带Gzip命令。
缺点:不支持切分
使用场景:适用于压缩后文件大小和一个文件块的大小相近的文件。
-
Bzip2
优点:支持切分,压缩率高!Hadoop自带
缺点:压缩/解压速度慢
使用场景:适合对速度要求不高,但是要求高压缩率的场景;适合大文件压缩,且压缩后的文件不会频繁使用和访问的场景;适合需要对大文件进行压缩以减少存储空间且需要支持切片的场景。
-
LZO
优点:压缩率适中,压缩和解压速度较快;支持切分;是Hadoop中最流行的压缩格式;
缺点:压缩率没有Gzip高,Hadoop本身不支持,需要在Linux下按照lzop命令使用。在实际应用中还需要对lzo格式的文件做一些特殊的处理(为了支持Split需要建立索引,需要指定InputFormat为Lzo格式)
使用场景:适用于大文件压缩后,大小仍然需要进行切分的数据,且文件越大,Lzo的优势越明显。
-
Snappy
优点:压缩/解压速度极快!压缩率合理
缺点:不支持split;压缩率不高;Hadoop本身不支持,需要安装
使用场景:当MapReduce作业的Map输出的数据较大的时候,可以使用Snappy将数据压缩,并作为Reduce阶段的数据输入。相当于Map和Reduce中间数据的压缩格式。
数据压缩的位置选择
-
输入端压缩
在有大量数据并计划重复处理的情况下,应该考虑在输入端对数据进行压缩,并且不用指定编解码方式。**Hadoop自动检查文件的扩展名,使用适当的编解码方式对文件进行压缩和解压。**若扩展名无法匹配,则不会使用任何的编解码器。
-
Mapper端的输出压缩
当MapTask的输出数据比较庞大的时候,应该考虑将输出的数据暂时进行压缩。经过压缩后的数据能显著改善内部数据Shuffle过程,并且很好地解决了因为文件大小地原因导致地数据传输缓慢地问题,推荐使用解压缩速度快地方式:例如LZO、Snappy
-
Reduce端的输出压缩
整个Job完成,输出数据存放到磁盘上,可能作为下一个MapReduce的输入数据,所以在此阶段对数据进行压缩,可以减小磁盘空间的占用,也可以提高下一个MapReduce的输入数据传输效率。
压缩的相关参数配置
-
io.compression.codecs(core-site.xml)默认值:org.apache.hadoop.io.compress.DefaultCodec/GzipCodec/BZip2Codec
作用阶段:输入压缩
Hadoop通过文件扩展名自动选择编码/解码器。
-
mapreduce.map.output.compress(mapred-site.xml)默认值:false
作用阶段:Mapper输出
默认关闭Mapper端的输出压缩,设置为true即可开启。
-
mapreduce.map.output.compress.codec(mapred-site.xml)默认值:org.apache.hadoop.io.compress.DefaultCodec
作用阶段:Mapper输出
当开启Mapper输出数据压缩的时候,配置使用的压缩方式。(企业中多用LZO和Snappy)
-
mapreduce.output.fileoutputformat.compress(mapred-site.xml)默认值:false
作用阶段:Reducer输出
默认关闭Reducer端的输出数据压缩,设置为true开启
-
mapreduce.output.fileoutputformat.compress.codec(mapred-site.xml)默认值:org.apache.hadoop.io.compress.DefaultCodec
作用阶段:Reducer输出
当Reducer端的输出压缩开启的时候,配置使用的压缩方式。
-
mapreduce.output.fileoutputformat.compress.type(mapred-site.xml)默认值:RECORD,其他可选:NONE、BLOCK
作用阶段:Reducer输出
SequenceFile输出使用的压缩类型:默认以记录为单位进行一次压缩(RECORD)、以块为单位进行压缩(BLOCK),NONE。
数据压缩实操
数据流的压缩和解压
CompressionCodec类提供了两个方法供我们使用以进行快速的压缩和解压操作。
createOutputStream(OutpuStream):用于将一个普通的输出流转化为以特定压缩格式写出的输出流,以达到压缩数据的目的。createInputStream(InputStream):将一个压缩文件输入流解析成为一个普通的输入流,达到对数据解压的目的。
压缩实例
主要步骤:
两个参数:输入文件的路径,压缩方式对应的编码器的全限定名
- 创建一个普通的文件输入流(fis),用于将文件内容读到程序。
- 使用反射通过编码器的全限定名获取编码器的Class,并通过此创建一个编码器(codec)。
- 创建一个普通的输出流(fos),输出路径:文件名+压缩方式的后缀扩展
- 使用编码器(codec)调用
createOutputStream(OutputStream),把刚创建的输出流作为参数传入,得到一个压缩格式写出的输出流(cos)。 - 输入流(fis)和压缩格式输出流(cos)进行数据对拷
- 关闭流资源
代码:
public class CompressionTest {
public static void main(String[] args) {
try {
compress("f:/input/words.txt", "org.apache.hadoop.io.compress.GzipCodec");
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
private static void compress(String filePath, String codecClassName) throws IOException, ClassNotFoundException {
// 1. 获取输入流
FileInputStream fis = new FileInputStream(new File(filePath));
// 2. 获取编码器实例
Class codecClass = Class.forName(codecClassName);
CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, new Configuration());
// 3. 获取普通的输出流
FileOutputStream fos = new FileOutputStream(new File(filePath + codec.getDefaultExtension()));
// 4. 转化为压缩格式的输出流
CompressionOutputStream cos = codec.createOutputStream(fos);
// 5. 流数据对拷:缓存区大小设置1M,并设置不自动关闭流资源。
IOUtils.copyBytes(fis, cos, 1024 * 1024, false);
// 6. 资源关闭
IOUtils.closeStream(cos);
IOUtils.closeStream(fos);
IOUtils.closeStream(fis);
}
}
输出的压缩文件:![]()
现在我们尝试使用解压方式对文件进行解压。
解压实例
主要步骤:
- 首先判断文件是否可以解压缩,需要创建一个编码器工厂(CompreesionCodecFactory),调用
getCodec(Path filePath)来获取合适的编码器(codec),若为空则表示无法对文件进行解压。 - 为压缩文件创建一个普通的输入流(fis)
- 编码器实例(codec)调用
createInputStream(InputStream)将普通的输入流,转化为压缩格式的输入流(cis),用于将压缩文件解码成未编码状态读入程序。 - 创建一个输出流(fos),用于将解压后文件内容写出。为了便于区分原文件,可以加上合适的后缀 (自定义)。
- 流之间的数据对拷
- 关闭资源
代码
private static void decompress(String fileName) throws IOException {
// 1. 判断是否可解压,获取编码器
CompressionCodecFactory codecFactory = new CompressionCodecFactory(new Configuration());
CompressionCodec codec = codecFactory.getCodec(new Path(fileName));
if (null == codec) {
System.out.println("File Can't Be Decompressed");
return;
}
// 2. 创建一个输入流
FileInputStream fis = new FileInputStream(new File(fileName));
// 3. 转化为压缩格式的输入流
CompressionInputStream cis = codec.createInputStream(fis);
// 4. 创建一个输出流
FileOutputStream fos = new FileOutputStream(new File(fileName + ".decode"));
// 5. 流数据对拷
IOUtils.copyBytes(cis, fos, 1024 * 1024, false);
// 6. 资源关闭
IOUtils.closeStream(fos);
IOUtils.closeStream(cis);
IOUtils.closeStream(fis);
}
输出结果:解码正常
Map和Reduce的输出压缩
Map端输出的数据的压缩并不影响MapReduce最终的数据输出,因为输出的数据最终都是存盘到本地通过网络传输到Reduce端进行处理。对数据压缩只是提高传输速度和IO效率。
只需要在Driver类中增加相关参数的配置即可
// 1.获取Job对象
Configuration conf = new Configuration();
// 开启Mapper输出数据压缩
conf.set("mapreduce.map.output,compress", "true");
conf.set("mapreduce.map.output.compress.codec", "org.apache.hadoop.io.compress.GzipCodec");
// 开启Reducer输出数据压缩
conf.set("mapreduce.output.fileoutputformat.compress", "true");
conf.set("mapreduce.output.fileoutputformat.compress.codec", "org.apache.hadoop.io.compress.GzipCodec");
Job job = Job.getInstance(conf);
//...
输出文件:解压后的数据和普通输出结果相同。

YARN资源调度器
Yarn框架的组成结构,参考Hadoop学习笔记入门篇>Hadoop的组成>Yarn架构,Yarn是一个资源调度平台,负责管理和分配服务器的资源,相当于一个分布式操作系统平台,而MapReduce的一个个Job相当于运行在操作系统上的用应用程序,需要相应的运算资源才能够正常运行。
工作原理

首先了解几个概念:
- ResourceManager是整个服务器集群的资源管理员。负责处理客户端的请求,以及监控NodeManager(NM)和ApplicationMaster(AM)。
- NodeManger负责单个节点的资源分配,处理AM和ResourceManager的命令。
- ApplicationMaster主要负责对象是单个Job,主要工作就是对Job的数据进行切分,以及资源的调度分配,和Job的数据监控
- Container是对不同维度的资源进行封装,用于资源分配的单位。
当Job的启动模式为本地(LocalJobRunner)时,是不会涉及Yarn资源调度全部部分的。仅当以YARNRunner启动时,才会涉及以下步骤:
-
启动MapReduce程序,Job运行
-
Jar包运行时,向RM申请一个Application
-
RM给出一个Job的资源提交位置(hdfs://…/staging/application_id/),需要Job提供相关的资源文件(job.split,job.xml,xxx.jar;jar包在YARN运行模式下是必须的!)
-
提交资源文件,请求启动Application,(若有很多任务等待启动,会加入任务调度队列,等待执行)
-
a:ResourceManager分配Task和相应的资源给空闲的NodeManager,并创建一个资源容器。
b:启动MRAppMaster,管理任务资源分配
-
下载提交的任务相关文件,对Job进行初始化。
-
检索提交资源文件中的split文件对数据先进行切分,并计算需要启动的MapTask的个数
-
准备Map阶段,向RM申请若干个运行MapTask的Container。
-
a:将Container分配到若干NM上
b:启动MapTask,开始处理对应的切片数据
-
从提交的任务资源文件中获取相关的文件支持MapTask运行
-
正式运行MapTask,每个MapTask结束后产生若干个数据分区。
-
通过数据分区合并后,通过分区数量再决定启动若干个ReduceTask,回到8。然后最终运行完成将数据写出,并回收所有的资源。开始处理RM中任务队列的下一个任务。
任务调度器
上面说到当提交任务数量较多的时候,Task会暂时进入等待队列,准备任务调度器按一定的规则调用运行Task。Hadoop的作业调度器有三种:
FIFO(队列),Capacity Scheduler(容量调度器),Fair Scheduler(公平调度器)。默认使用的是容量调度器:(yarn-default.xml)
-
FIFO,按照队列先进先出的规则,按照提交时间的顺序来调度作业和资源分配。
-
Capacity Scheduler(容量调度器)
支持多个队列,可配置每个队列管理的资源,每个队列采用FIFO的调度策略。
为了防治单个用户的作业独占资源,会对每个用户的作业资源量进行限制。
调度策略:
- 首先按队列中正在运行的任务数与队列分配得到的资源数的比值,找到最小的作为选择队列
- 再选择队列中,按照作业优先级和提交时间顺序选择,同时考虑用户资源量限制和内存限制。选择出适合的Task予以运行。
-
Fair Scheduler(公平调度器)
与容量调度器类似,也支持多队列,每个队列的资源量可配置。队列中个每个作业对所在队列的资源公平共享。每个队列中的 job 按照优先级分配资源,优先级越高分配的资源越多,但是每个 job 都会分配到资源以确保公平。
在资源有限的情况下,每个 job 理想情况下获得的计算资源与实际获得的计算资源存在一种差距, 这个差距就叫做缺额。在同一个队列中,job的资源缺额越大,越先获得资源优先执行。作业是按照缺额的高低来先后执行的,而且可以看到上图有多个作业同时运行。(作业并发执行,之间互不影响)
任务推测执行
一个作业由若干个Map任务和Reduce任务构成。而一个作业的完成的速度,却决于最慢的的任务。
问题:如果其中一个任务由于系统Bug或者某种故障,导致进度很慢,而其他的任务均已完成,那么采取什么措施呢?
答案是:推测执行机制
在发现作业中存在某个任务进度很慢,速度低于作业中任务的平均速度。则为此任务启动一个备份任务,和原任务同时运行,谁先运行结束就采取谁的运行结果。
无论什么时候都可以采用推测执行机制吗?
当然不是!前提条件是:
-
每个Task只能有一个备份任务
-
当前Job的至少5%任务已完成
-
要在mapred-site.xml中配置开启
<property> <name>mapreduce.map.speculativename> <value>truevalue> property> <property> <name>mapreduce.reduce.speculativename> <value>truevalue> property>
无论什么任务都可以使用推测执行机制吗?
显然也不是,以下情况不适合使用推测执行机制
- 任务间存在严重的负载倾斜。(某一个Task的任务繁重,执行时间理所当然会较慢,此时再开启一个备份任务,反而使原任务变得更慢)
- 特殊任务:例如向数据库中写入数据。(原任务正在向数据库中写数据,此时再开一个备份任务再次向数据库中写数据就可能产生错误。)
推测执行算法原理
首先通过当前任务的执行进度和任务运行的时间计算出推测运行时间estimatedRunTime
推测运行时间estimatedRunTime =(当前时刻—任务启动时刻)/ 任务运行进度
再通过任务启动时间,得出推测执行完成时刻estimatedEndTime
推测完成时刻estimatedEndTime = 推测运行时间estimatedRunTime + 任务启动时刻
如果再当前时刻为任务启动一个备份任务,则可以结合Job的其他任务的平均运行时间推算出备份任务的完成时刻 estimatedEndTime'
备份任务推测完成时刻estimatedEndTime‘ = 当前时刻 + 已完成任务的平均运行时间
MR总是挑选出(estimatedEndTime’—estimatedEndTime)备份任务推测完成时间和推测完成时间差值最大的任务,开启备份任务。以节省最多的时间。
为了方式大量的任务同时开启备份任务导致的资源浪费,MR为每个Job设置的备份任务数量上限。
推测执行机制采用了经典的==‘空间换时间’==的优化算法。同时开启两个相同的任务处理相同的数据,虽然会消耗更多的资源,但是有效缩短了任务的执行时间。所有再集群资源紧缺的情况下,应当合理判断使用该机制。
Hadoop企业优化
MapReduce跑的慢的原因
-
硬件方面(花钱解决)
CPU、内存、磁盘、网络
-
IO操作不当
- 严重的数据倾斜(某一个Task处理的数量过多,执行时间长拖慢整个MapReduce的运行速度)
- 数据切片、数据块大小设置的不合理,导致Map和Reduce的数量的不合理
- Map阶段运行时间过长,Shuffle耗时长导致Reuduce长时间等待。
- 小文件过多,频繁的IO和数据处理拉低MR的运行效率。
- 大量的不可分块的超大文件,导致数据处理难度极大。
- 溢写的次数过多,增加IO次数,以及对应的多次merge(合并)也属于IO操作,大大增加了任务的执行时间。
调优的方法
从六个方面入手:数据输入、Map端、Reduce端、IO优化、数据平衡、相关调优参数
- 数据输入:
- 合并小文件,减少任务装载次数。
- 使用CombineTextInputFormat,解决输入端大量小文件的场景。
- Map阶段:
- 减少环形缓冲区溢写的次数,调整环形缓冲区的大小(io.sort.mb和sort.spill.percent参数值)增大触发溢写的内存上限,以减少溢写的IO操作
- 减少合并(Merge)的次数,调整io.sort.factor参数,增大Merge的文件数以减少Merge的次数。
- Map阶段的输出,在不影响业务的情况下,进行Combine处理,提高网络传输的效率。
- Reduce阶段:
- 合理设置Reduce和Map的数量,不宜多也不宜少。根据业务进行衡量。
- 设置Map、Reduce共存:调整slowstart.completedmaps参数,使Map运行到一定阶段就开始运行Reduce,减少等待时间。
- 规避使用Reduce,Reduce阶段连接数据会消耗大量的网络资源。如果Reduce端的工作可以由Map端代替完成的化,可以不开启Reduce。
- 合理设置Reduce端的Buffer,数据进入Reduce端的时候,首先进入内存,到达一定阈值之后,将数据溢写到磁盘上,后期频繁的磁盘IO读取数据会降低性能。通过配置mapred.job.reduce.inout.buffer.percent参数,默认为0.0,保留指定比例的内存直接读取Buffer中的数据供Reduce计算。减少磁盘IO,但是会占用一定的内存资源,酌情调整。
- IO优化:
- 采用数据压缩,安装Snappy和LZO压缩编码器,对数据进行压缩,提高传输效率
- 使用SequenceFile(二进制文件),格式紧凑并且适于封装小文件。
- 数据倾斜:
- 抽样和范围分区:对原始数据进行抽样分析,预设分区。
- 自定义分区:在熟悉数据的情况下,将高频出现的归类划分为多个分区,其他的由剩余的Reduce进行处理。
- Combine:Map端进行Combine。对数据进行精简,可以减少数据倾斜。
- 使用MapJoin,避免使用ReduceJoin
- 常用调优参数:
- 资源相关:(mapred-default.xml)
mapreduce.map.memory.mb:一个MapTask可使用的内存上限,默认1024(单位MB),使用资源量超过该值,则会被强制杀掉。mapreduce.reduce.memory.mb:一个ReduceTask。。。mapreduce.map.cpu.vcores:MapTask可使用CPU的核心数,默认为1mapreduce.reduce.cpu.vcores:ReduceTask。。。mapreduce.reduce.shuffle.parallelcopies:每个Reduce从Map中取数据的并行数,默认值5mapreduce.reduce.shuffle.merge.percent:Reduce端Buffer中数据到达多少比例,开始溢写数据到磁盘,默认是0.66;mapreduce.reduce.shuffle.input.buffer.percent:Buffer占Reduce可以用的内存的百分比;默认是0.7;mapreduce.reduce.input.buffer.percent:指定多少比例的内存来读和存Buffer中的数据,默认是0.0;
- YARN相关参数(yarn-default.xml)
yarn.scheduler.minimum-allocation-mb:应用程序Container分配最小内存:1024MByarn.scheduler.maximum-allocation-mb:应用程序Container分配的最大内存:8192MByarn.scheduler.minimum-allocation-vcores:应用程序Container分配最小CPU核数:1yarn.scheduler.maximum-allocation-vcores:应用程序Container分配最大CPU核数:32yarn.nodemanager.resource.memory-mb:给Containers分配的最大物理内存(即集群中单个节点可使用的最大内存):8192MB
- Shuffle性能调优的相关参数(mapred-default.xml)
mapreduce.task.io.sort.mb:环形缓冲区的大小默认100Mmapreduce.map.sort.spill.percent:环形缓冲区溢出的阈值(比例):默认80%
- 容错相关
mapreduce.map.maxattempts:MapTask最大失败尝试次数:4mapreduce.reduce.maxattempts:ReduceTask最大失败尝试次数:4mapreduce.task.timeout:Task超时时间,此段时间内Task没有读取新数据也没有输出数据,则任务Task处于Block状态,当超时时间结束,则强制关闭该Task,默认值:600000(毫秒)=10分钟;在一些长时间拉去数据的场景下,应对适当调高此参数。
- 资源相关:(mapred-default.xml)
小文件处理方法汇总
- HDFS中使用
hadoop archive对多个小文件进行归档,归档为.har文件 - 使用
CombineTextInputFormat,其切片机制将多个小文件划分到一个切片中给一个MapReduce处理 - 使用
SequenceFile存储小文件,Key为文件名,Value为文件内容。SequenceFile是二进制文件,结构紧凑,适合封装小文件,减少磁盘占用。 开启JVM重用:每个Map运行在JVM,开启重用后,减少了JVM启动关闭的时间,让JVM在运行一个Map后,还可以运行其他Map。减少45%的时间。通过设置mapreduce.job.job.numtasks参数10~20。
扩展案例
案例一:多Job串联
需求描述:给出多个单词文件。
第一个Job统计以
单词名--文件名作为Key,以单词在文件中出现的次数作为value输出结果。第二个Job以第一个Job的输出作为输入,输出以
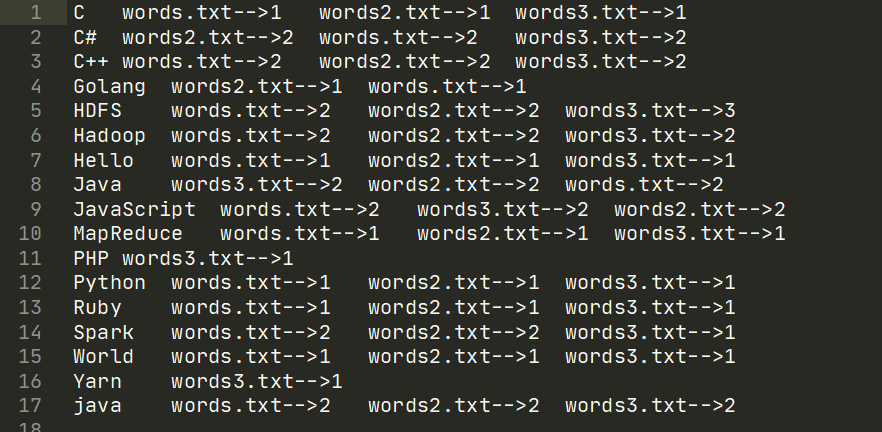
单词名作为Key,Value则是每个文件中该单词出现的次数:格式为文件名-->次数
示例:
文件一:wrodsA.txt
java c++ mapreduce hadoop mapreduce
文件二:wordsB.txt
hadoop spark c++ java hadoop
# 第一个Job的期望输出
c++--wordA.txt 1
hadoop--wordA.txt 1
java--wordA.txt 1
mapreduce--wordA.txt 2
c++--wordB.txt 1
hadoop--wordB.txt 2
java--wordB.txt 1
spark--wordB.txt 1
# 第二个Job的期望输出
c++ wordA.txt-->1 wordB.txt-->1
hadoop wordA.txt-->1 wordB.txt-->2
java wordA.txt-->1 wordB.txt-->1
mapreduce wordA.txt-->2
spark wordB.txt-->1
FirstJob代码:
// Mapper
public class FirstJobMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
String currentFileName = new String();
Text keyOut = new Text();
IntWritable valueOut = new IntWritable(1);
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 获取文件名
FileSplit split = (FileSplit) context.getInputSplit();
currentFileName = split.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String lineWords = value.toString();
String[] words = lineWords.split(" ");
// 循环写出
for (String word : words) {
keyOut.set(word + "--" + currentFileName);
context.write(keyOut, valueOut);
}
}
}
// Reducer
public class FirstJobReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable valueOut = new IntWritable(0);
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 累加求和
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
valueOut.set(sum);
context.write(key, valueOut);
}
}
// Driver忽略
结果输出(部分):

SecondJob代码
//Mapper
public class SecondJobMapper extends Mapper<LongWritable, Text, Text, Text> {
Text keyOut = new Text();
Text valueOut = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 输入数据格式:C#--words.txt 2
// 期望输出格式:C# words.txt-->2
String line = value.toString();
String[] fields = line.split("--");
// 切割后的数据{"C#","words.txt 2"}
keyOut.set(fields[0]);
valueOut.set(fields[1].replaceFirst("\t", "-->"));
context.write(keyOut, valueOut);
}
}
//Reducer
public class SecondJobReducer extends Reducer<Text, Text, Text, Text> {
Text valueOut = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuffer sb = new StringBuffer();
for (Text value : values) {
sb.append(value.toString());
sb.append("\t");
}
valueOut.set(sb.toString());
context.write(key, valueOut);
}
}
最终结果输出:
案例二:TopN
在之前的Shuffle机制中,在学习自定义排序的时候,就已经非常接近TopN的案例要求,只不过我们要按照要求输出前N个结果即可。代码还存在可以优化的地方。
改进处:
在Maper和Reducer中,可以使用Set来存储Value,因为Set是默认有序的。当Set中值的数量超过了N,就移除末尾\ 首位的值,加入新的值。