Hadoop全分布式集群搭建详细步骤
集群搭建的步骤有很多,并不是一成不变的标准顺序,我写的只是仅供大家的一个参考,希望能帮到大家,如果有不对的地方也希望大家留言指教。
首先要创建一个虚拟机然后将虚拟机打开
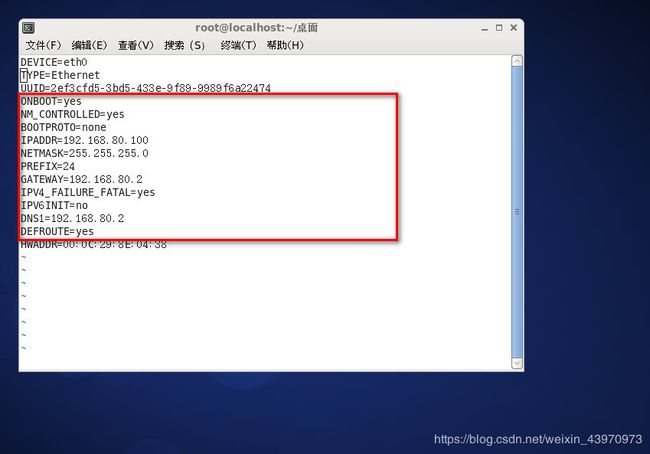
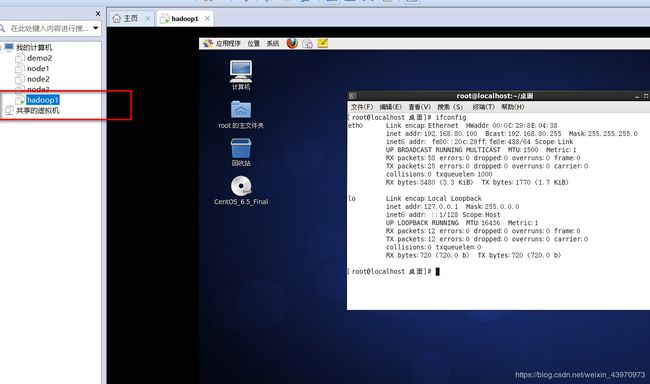
1.修改虚拟机IP地址和配置NAT模式,根据下面的命令和图片中红色框内容进行设置
IPADDR是本台虚拟机的IP地址
vi /etc/sysconfig/network-scripts/ifcfg-eth0
2.修改本机的IPV4
打开网络右键打开属性
点击更改适配器设置
双击打开IPv4进行设置
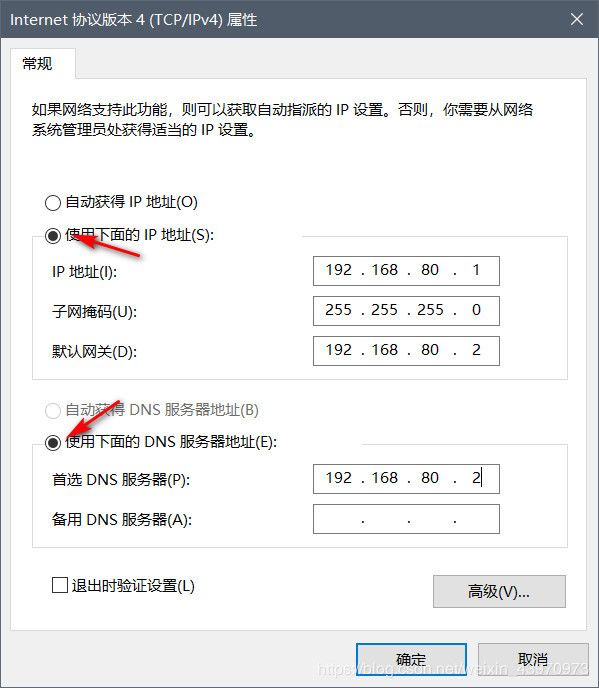
按照下图进行设置,设置完毕确认即可
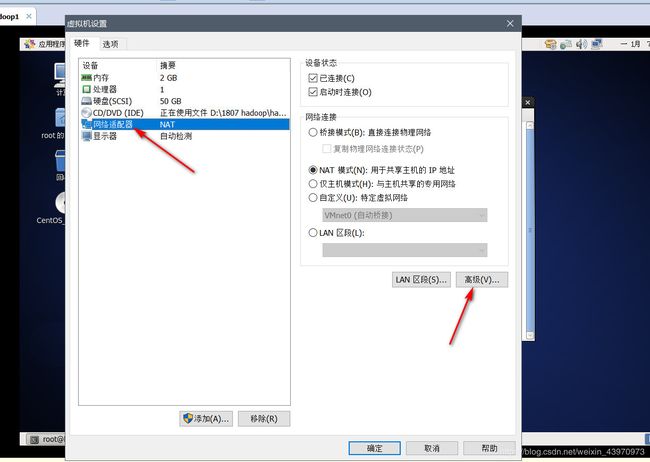
点击你的虚拟机右键打开设置
点击网络适配器点击高级
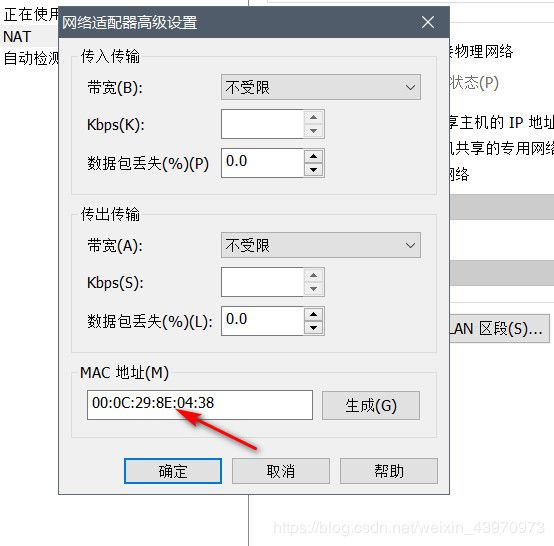
将vi /etc/sysconfig/network-scripts/ifcfg-eth0 中的HWADDR改为下面的mac地址
3.连接Xshell
4.查看防火墙状态
service iptables status
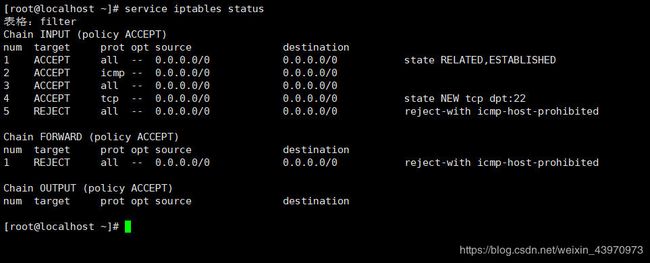
发现有防火墙开启,然后需要将防火墙关闭
service iptables stop

然后再查看一下防火墙状态
![]()
在通过 chkconfig iptables off 命令将防火墙永久关闭
5.然后进入home目录
cd /home
再home目录下创建一个soft文件夹
mkdir soft
在进入soft目录
cd soft/
再soft目录下创建两个文件夹用于存放jdk和hadoop
mkdir JDK mkdir hadoop
6.连接winSCP将hadoop和jdk安装包传入新建的JDK和hadoop文件夹内
7.查看已安装的jdk
rpm -qa | grep jdk

将已安装的jdk卸载了
rpm -e --nodeps jdk版本号
![]()
8.解压jdk
进入 cd /home/soft/JDK jdk的压缩包存放目录

通过 tar -zvxf jdk-8u191-linux-x64.tar.gz 解压jdk
解压完毕后与通过ll查看 蓝色字体的 jdk1.8.0_191就是jdk解压后的目录

通过 mv jdk1.8.0_191/ jdk 将解压包名称修改为jdk 方便后边写路径

9.配置环境变量 ,在最下面配置环境变量,如果安装路径与我的不同记得修改记得修改环境变量的JAVA_HOME路径
vi /etc/profile
export JAVA_HOME=/home/soft/JDK/jdk
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
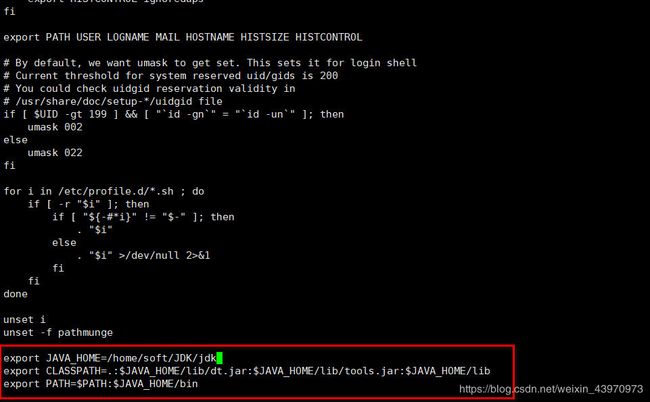
写入后, 刷新profile使环境变量生效
source /etc/profile
查看jdk版本是否安装成功
java -version
10.然后进入hadoop压缩包存放地址解压hadoop
tar -zvxf hadoop-2.8.5.tar.gz

配置hadoop环境变量
export HADOOP_HOME=/home/soft/hadoop/hadoop-2.8.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
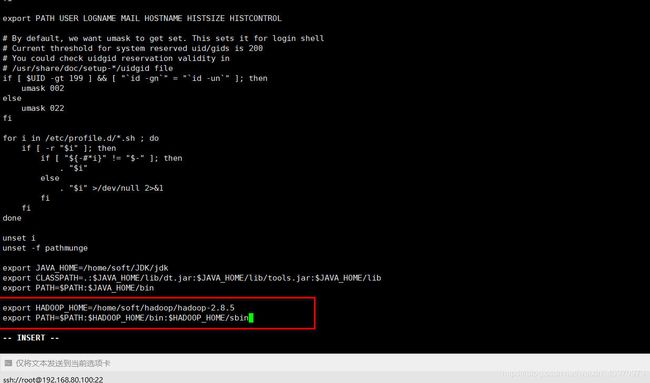
再刷新profile使环境变量生效
source /etc/profile
11.接下来需要修改hadoop的配置文件,需要进入hadoop配置文件的存放地址
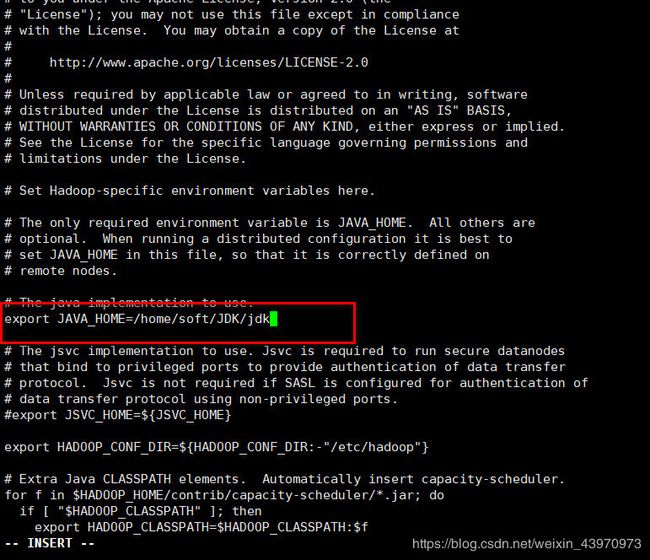
修改hadoop-env.sh
vi hadoop-env.sh
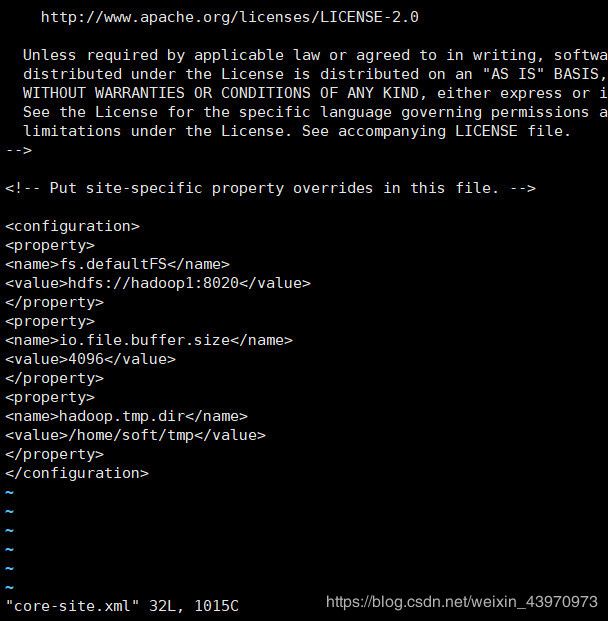
配置配置core-site.xml
vi core-site.xml
fs.defaultFS
hdfs://hadoop1:8020
io.file.buffer.size
4096
hadoop.tmp.dir
/home/soft/tmp
配置hdfs-site.xml
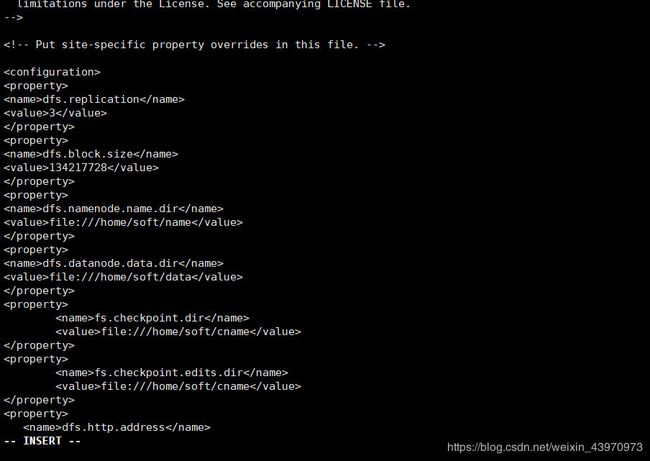
vi hdfs-site.xml
dfs.replication
3
dfs.block.size
134217728
dfs.namenode.name.dir
file:///home/soft/name
dfs.datanode.data.dir
file:///home/soft/data
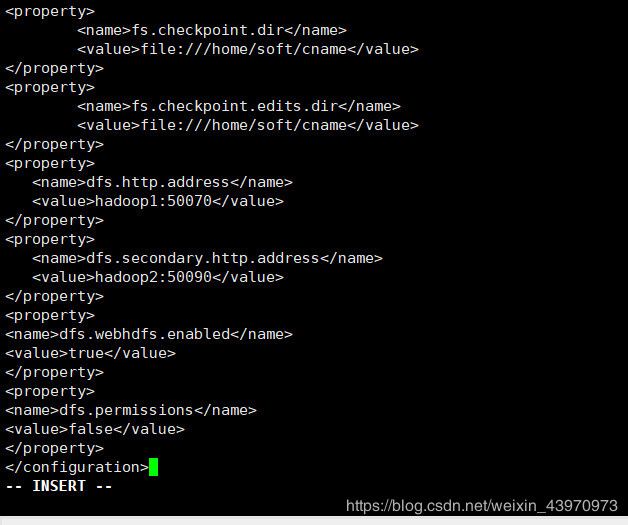
fs.checkpoint.dir
file:///home/soft/cname
fs.checkpoint.edits.dir
file:///home/soft/cname
dfs.http.address
hadoop1:50070
dfs.secondary.http.address
hadoop2:50090
dfs.webhdfs.enabled
true
dfs.permissions
false
配置yarn-site.xml
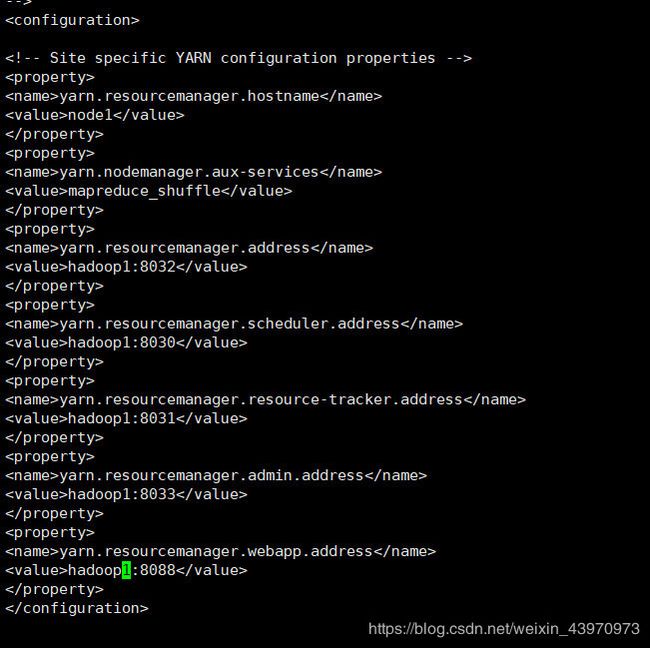
vi yarn-site.xml
yarn.resourcemanager.hostname
hadoop1
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
hadoop1:8032
yarn.resourcemanager.scheduler.address
hadoop1:8030
yarn.resourcemanager.resource-tracker.address
hadoop1:8031
yarn.resourcemanager.admin.address
hadoop1:8033
yarn.resourcemanager.webapp.address
hadoop1:8088
配置slaves
三个虚拟机的主机名
创建一个名为mapred-site.xml的文件
touch mapred-site.xml
将mapred-site.xml.template的内容写入mapred-site.xml文件内
cat mapred-site.xml.template >> mapred-site.xml
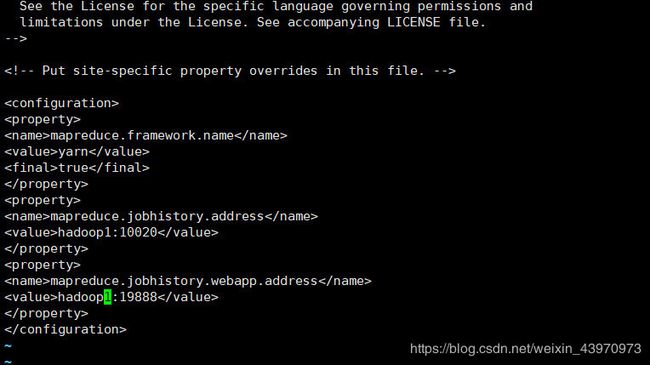
然后再配置mapred-site.xml
vi mapred-site.xml
mapreduce.framework.name
yarn
true
mapreduce.jobhistory.address
hadoop1:10020
mapreduce.jobhistory.webapp.address
hadoop1:19888
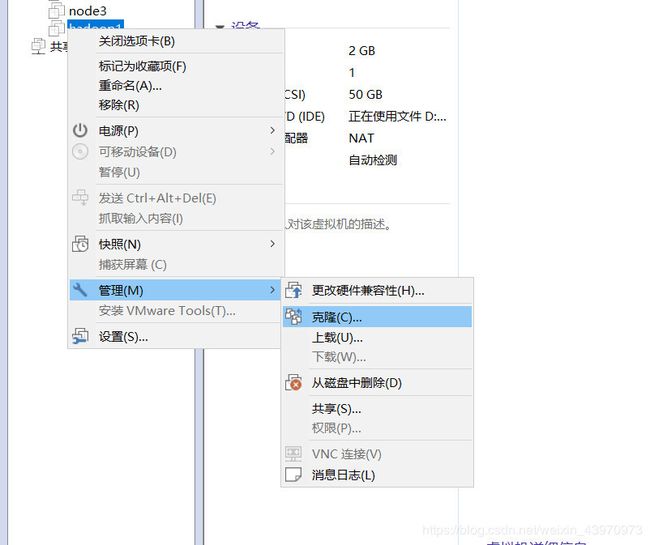
克隆两台虚拟机
先将虚拟机关闭,右键虚拟机管理里面的克隆虚拟机
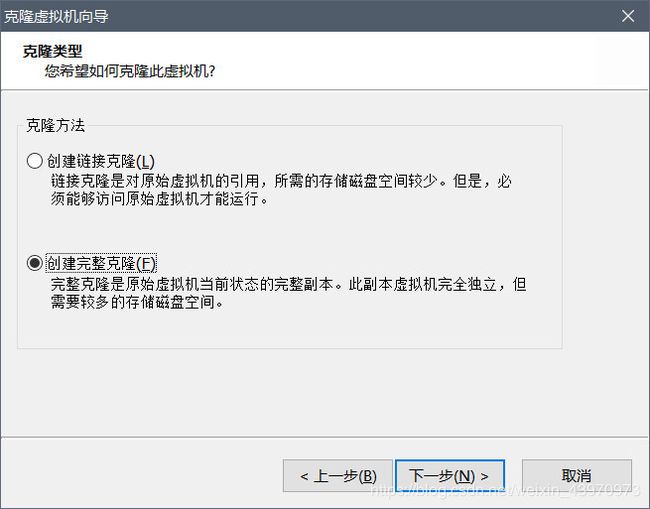
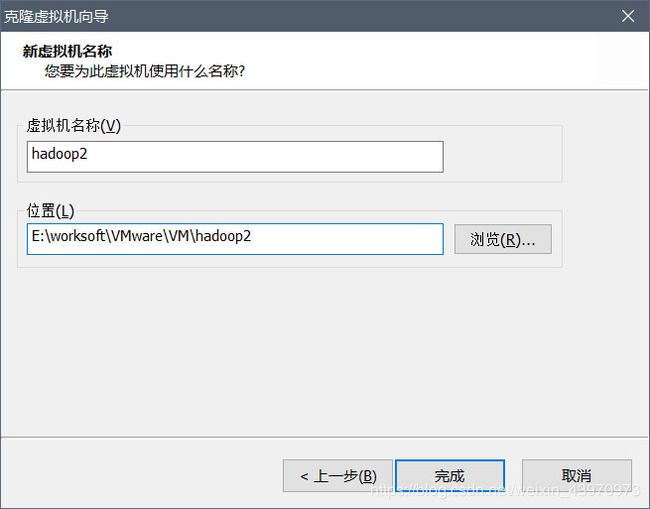
打开克隆后的hadoop2虚拟机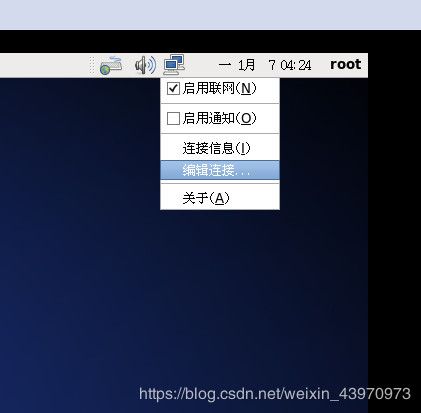
删除 Auto eth1
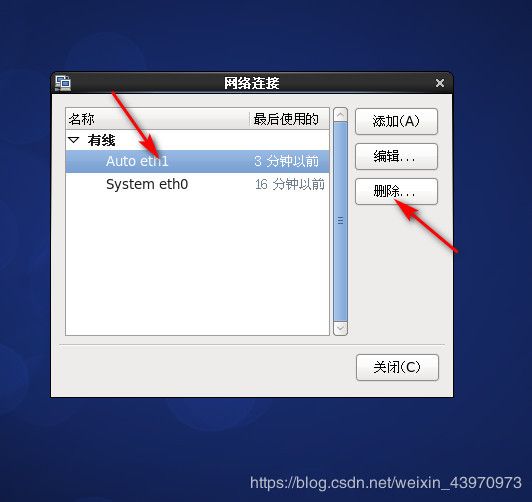
修改ip地址和HWADDR vi /etc/sysconfig/network-scripts/ifcfg-eth0
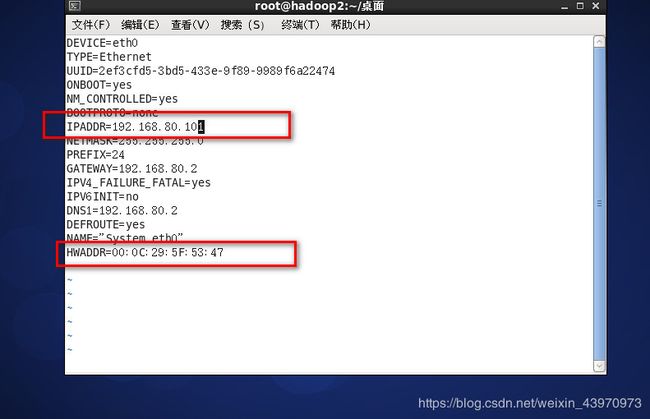
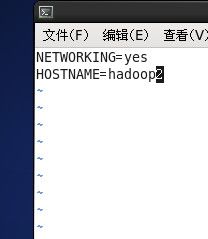
修改主机名 vi /etc/sysconfig/network 修改完后需要重启虚拟机
然后打开第三台hadoop3虚拟机进行以上和hadoop2一样的操作
接下来对三台主机都进行主机映射配置
vi /etc/hosts
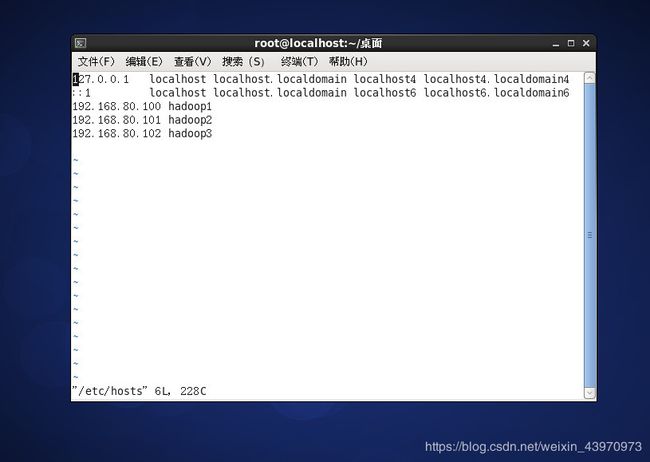
然后就是最后一步设置免密登陆就完成了
连接上三台虚拟机的XShell
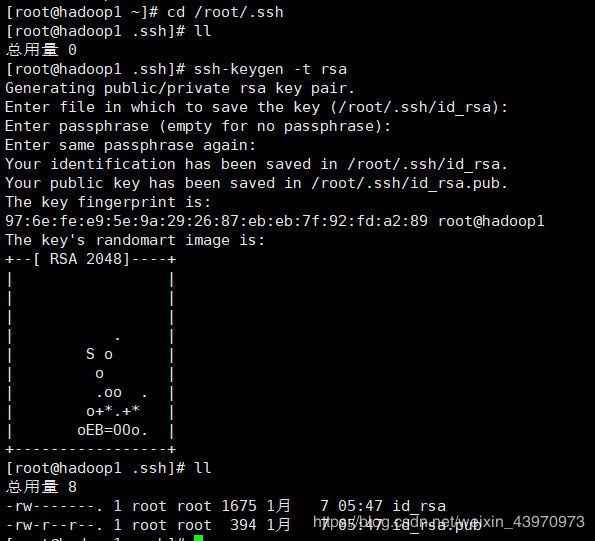
- 首先进入root底下的.ssh目录
cd /root/.ssh cd /root/.ssh - 然后生成一个密钥(需要在三台虚拟机中都执行此命令,生成密钥)
ssh-keygen -t rsa(三次回车) - 然后创建authorized_keys文件
touch authorized_keys - 将id_rsa.pub的内容写入authorized_keys文件
cat id_rsa.pub >> authorized_keys - 将authorized_keys传到hadoop2的/root/.ssh下
scp authorized_keys hadoop2:/root/.ssh/
6.然后在hadoop2下将将id_rsa.pub的内容写入authorized_keys文件
cat id_rsa.pub >> authorized_keys
7.再将authorized_keys文件传到hadoop3的/root/.ssh下
scp authorized_keys hadoop3:/root/.ssh/
8.然后在hadoop3下将将id_rsa.pub的内容写入authorized_keys文件
cat id_rsa.pub >> authorized_keys
9.再将authorized_keys文件传到hadoop1和hadoop2的/root/.ssh下覆盖之前的authorized_keys文件
scp authorized_keys hadoop1:/root/.ssh/
scp authorized_keys hadoop2:/root/.ssh/
10.在虚拟机上用ssh hadoop1或者ssh hadoop2或者ssh hadoop3进行测试,如果不需要输入密码则免密设置成功
接下来就可以进行格式化然后启动集群
格式化 hdfs namenode -format (只有第一次启动才会格式化)
启动 start-all.sh
网页验证:
http:192.168.80.100:50070
http:192.168.80.100:8088
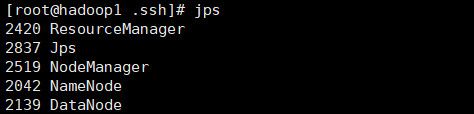
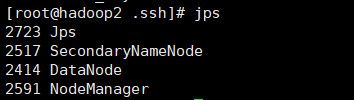
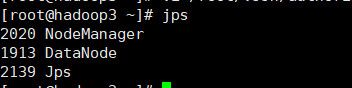
在虚拟机上分别运行一下jps