【Python】学习笔记(三):机器学习基础入门
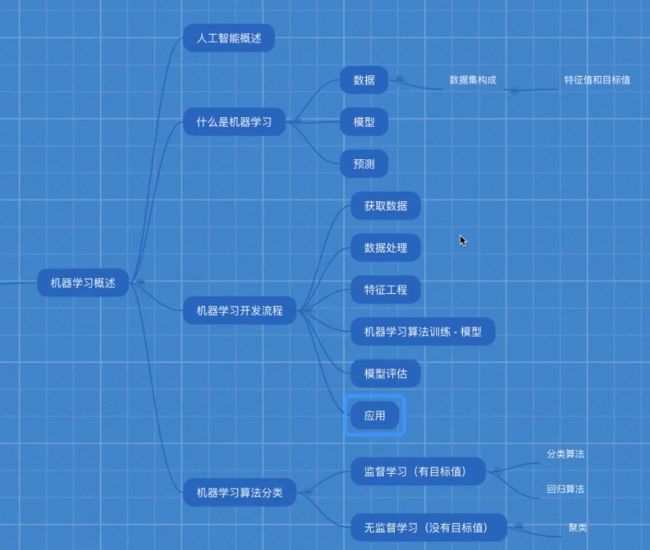
机器学习简介
1 机器学习
1.1 数据集
数据集 = 特征值 + 目标值
1.2 算法分类
- 监督学习
- 目标值:类别 - 分类问题
- 目标值:连续数据 - 回归问题
- 无监督学习:无目标值

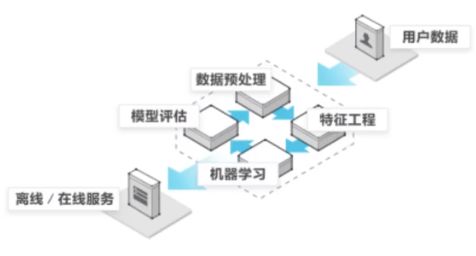
1.3 机器学习流程
1.4 Scikit-learn
pip3 install Scikit-learn==0.19.1

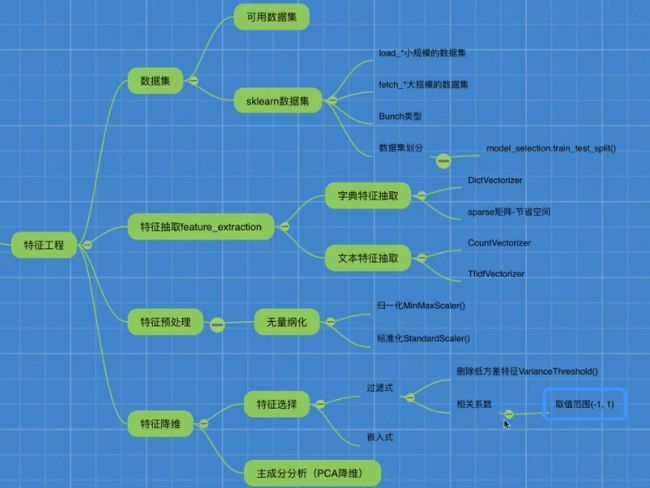
2 sklearn 特征工程
2.1 scikit-learn数据集API

2.2 数据集
2.2.1 小数据集
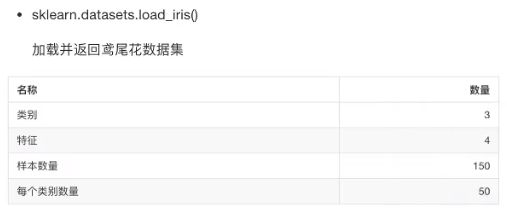
2.2.2 大数据集

2.2.3 返回值
# 导入鸢尾花
from sklearn.datasets import load_iris

2.2.4 数据集的划分
from sklearn.model_selection import train_test_split


x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size = 0.2, random_state = 22)
print(f"测试集:{x_train}, 大小:{x_train.shape}")
2.3 特征工程 Feature Engineering
- sklearn 特征工程
- pandas 数据清洗,数据处理
2.3.1 特征抽取API
sklearn.feature_extraction
2.3.2 字典的特征提取
from sklearn.feature_extraction import DictVectorizer

def dict_demo():
"""字典特征抽取"""
data = [{'city': '北京', 'temperayure': 100},
{'city': '上海', 'temperayure': 60 },
{'city': '深圳', 'temperayure': 30 }]
# 1.实例化一个转换器类
transfer = DictVectorizer(sparse= False)
# 2.调用fit_transform()
data_new = transfer.fit_transform(data) # data_new.toarray()
print("数据:", data_new)
print("特征名字:", transfer.get_feature_names())
return None
- 应用场景
- 特征比较多
- 1 数据集的特征,转化成字典类型
- 2 DictVectorizer 转换
- 特征比较多
2.3.3 文本的特征提取 -1
- 特征:句子、短语、单词
from sklearn.feature_extraction.text import CountVectorizer

stop_words 停用词
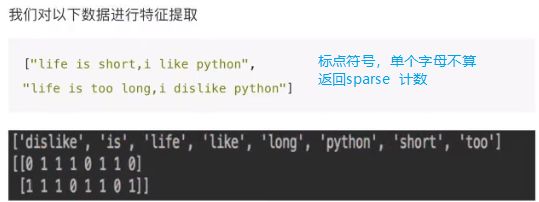
**sparse.toarray() ** — sparse包含变成数组的方法,字典/文本提取均可使用
- 中文分词
def dict_cn_demo():
"""
"我爱北京天安门" -> "我 爱 北京 天安门"
"""
text = "我爱北京天安门"
a = jieba.cut(text) # 返回迭代器
b = list(a) # ['我', '爱', '北京', '天安门']
c = " ".join(b) # "我 爱 北京 天安门" str
print(c)
return None
def cut_CN(text):
"""
"我爱北京天安门" -> "我 爱 北京 天安门"
"""
return " ".join(list(jieba(text)))
2.3.4 文本的特征提取 -2
from sklearn.feature_extraction.text import TfidfVectorizer



2.4 特征预处理
sklearn.preprocessing

2.4.1 归一化
鲁棒性较差,最大值/最小值为Nan容易出现问题
from sklearn.preprocessing import MinMaxScaler


def minmax_demo():
"""
归一化
"""
# 1.获取数据
# data.to_csv("data.csv", index= False)
data = pd.read_csv("data.csv")
data = data.iloc[:, :3]
print("data:", data)
# 2.获取转换器类
transfer = MinMaxScaler(feature_range= (0, 1))
# 3.fit_transform
data_new = transfer.fit_transform(data)
print("data_new", data_new)
return None
2.4.2 标准化
# 适合大样本
from sklearn.preprocessing import StandardScaler


def stand_demo():
"""
标准化
"""
# 1.获取数据
data = pd.read_csv("data.csv")
data = data.iloc[:, :3]
print("data:", data)
# 2.获取转换器类
transfer = StandardScaler()
# 3.fit_transform
data_new = transfer.fit_transform(data)
print("data_new", data_new)
return None
2.5 特征降维
2.5.1 特征降维
from sklearn.feature_selection import VarianceThreshold

【Filter过滤式】


【Embedded嵌入式】
…
def variance_demo():
"""
过滤低方差特征
"""
# 1.获取数据
data = pd.read_csv("data.csv")
print("data:", data.head())
# 2.实例化转换器
transter = VarianceThreshold()
# 3.调用fit_transform
data_new = transter.fit_transform(data)
print("data_new:", data_new, data_new.shape)
return None
2.5.2 相关系数
- 皮尔逊相关系数:反映变量之间相关关系密切程度(散点图可以观察)
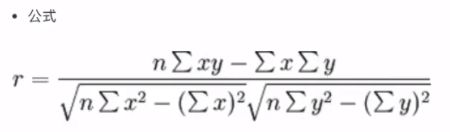

- API
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-imaB5JQX-1583501771196)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20200304174051073.png)]
from scipy.stats import pearsonr
# 计算两个变量的相关性 返回 r = (相关系数, p 显著水平 越小越好)
r = pearsonr(data["pe_ratio"], data["pb_ratio"])
2.6 主成分分析(PCA)

- API

from sklearn.decomposition import PCA
def pca_demo():
data = [[2, 8, 4, 5],
[6, 3, 0, 8],
[5, 4, 9, 1]]
# 1.实例化转换器类
transfer = PCA(n_components= 2) # 4个特征转换成2个特征
# 2.fit_transform
data_new = transfer.fit_transform(data)
print("data_new\n", data_new)
return None
2.7 总结一
3 分类算法
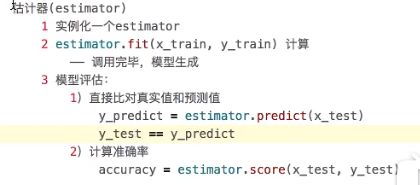
3.1 sklearn转换器和估计器
3.1.1 转换器

3.1.2 估计器(sklearn机器学习算法实现)

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oYztJ3rr-1583502198782)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20200304220403929.png)]
3.2 K-紧邻算法(KNN)
K Nearest Neighbor
K 值取得过小,容易受到异常点的影响
K 值取得过大,样本不均匀的影响

【训练流程】
- 1.获取数据
- 2.数据集划分(train & test)
- 3.特征工程(标准化,降维?)
- 4.KNN预估器流程
- 5.模型评估
【示例】
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
def knn_iris():
"""
KNN 算法对鸢尾花分类
"""
# - 1.获取数据
iris = load_iris()
# - 2.数据集划分(train & test)
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size = 0.1, random_state = 6)
# - 3.特征工程:标准化 - 训练和测试用一样的fit
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test) # 和训练(x_train)用相同的计算(fit)
# - 4.KNN预估器流程 K值
estimator = KNeighborsClassifier(n_neighbors = 3)
estimator.fit(x_train, y_train)
# - 5.模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_predict == y_test)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率:\n", score)
return None
if __name__ == "__main__":
# KNN算法对鸢尾花分类
knn_iris()

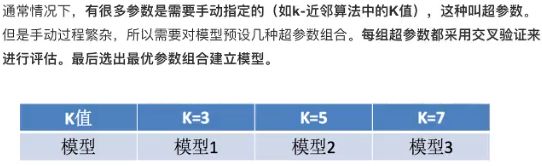
3.3 模型选择与调优
3.3.1 交叉验证(cross validation)


3.3.2 超参数搜索-网格搜索(Grid Search)
寻找合适的K值

from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
def knn_iris_gscv():
"""
KNN 算法对鸢尾花分类,添加网格搜索和交叉验证
"""
# - 1.获取数据
iris = load_iris()
# - 2.数据集划分(train & test)
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size = 0.1, random_state = 8)
# - 3.特征工程:标准化 - 训练和测试用一样的fit
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test) # 和训练(x_train)用相同的计算(fit)
# - 4.KNN预估器流程 K值
estimator = KNeighborsClassifier()
# ------加入网格搜索与交叉验证
# ------参数准备K值搜索:param_dict,交叉次数:cv
param_dict = {"n_neighbors":[1, 3, 5, 7, 9, 11]}
estimator = GridSearchCV(estimator, param_grid = param_dict, cv = 8)
# ------新增内容
estimator.fit(x_train, y_train) # 训练
# - 5.模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_predict == y_test)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率:\n", score)
print("最佳参数:\n", estimator.best_params_)
print("最佳结果:\n", estimator.best_score_)
print("最佳估计器:\n", estimator.best_estimator_)
print("交叉验证结果:\n", estimator.cv_results_)
return None
if __name__ == "__main__":
# KNN算法对鸢尾花分类
knn_iris_gscv()
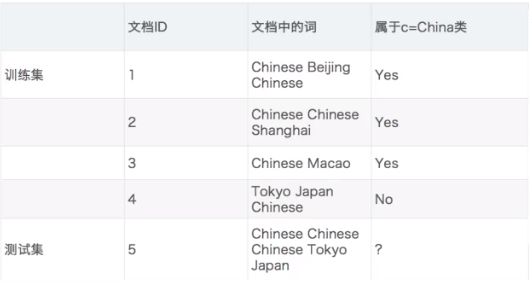
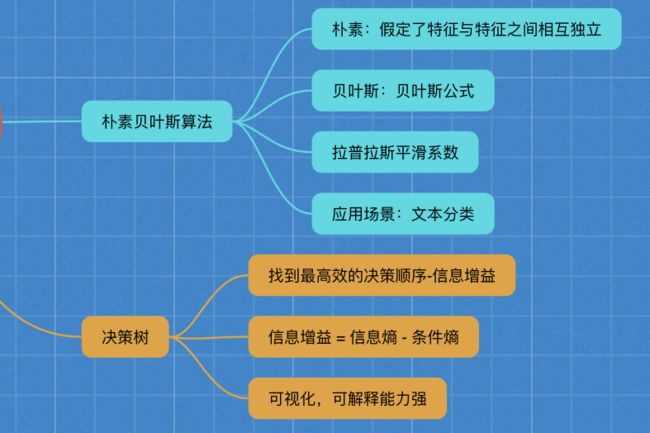
3.4 朴素贝叶斯算法
朴素(相互独立)+贝叶斯(贝叶斯公式)
应用:文本分类,情感分析
3.4.1 贝叶斯公式



3.4.2 拉普拉斯平滑系数
from sklearn.naive_bayes import MultinomialNB
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T5hPOnwv-1583501771257)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20200305120042622.png)]
- API
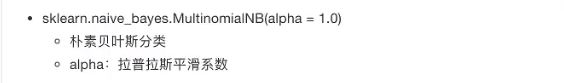
3.4.3 代码演示
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
def nb_news():
"""
朴素贝叶斯算法,新闻分类
"""
# 1.获取数据
news = fetch_20newsgroups(subset= "all")
# 2.划分数据集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
# 3.特征工程:文本抽取 tfidf
transfer = TfidfVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.朴素贝叶斯算法预估器流程
estimator = MultinomialNB()
estimator.fit(x_train, y_train) #训练
# 5.模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_predict == y_test)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率:\n", score)
return None
if __name__ == "__main__":
nb_news()

3.5 决策树
如何高效的进行决策
3.5.1 原理



- 决策树API
from sklearn.tree import DecisionTreeClassifier, export_graphviz

3.5.2 示例
def decision_iris():
"""
决策树算法对鸢尾花分类,添加网格搜索和交叉验证
"""
# - 1.获取数据
iris = load_iris()
# - 2.数据集划分(train & test)
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target)
# - 3.决策树预估器
estimator = DecisionTreeClassifier(criterion= "entropy")
estimator.fit(x_train, y_train)
# - 4.模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_predict == y_test)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率:\n", score)
# 数据可视化
export_graphviz(estimator, out_file= "iris_tree.dot", feature_names= iris.feature_names)
# 生成文件复制到:http://www.webgraphviz.com/
return None

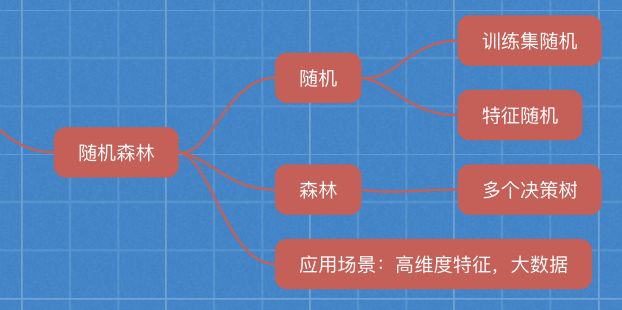
3.6 随机森林(集成学习方法)
适合大数据,处理高维特征数据

【示例:网格搜索+随机森林】
from sklearn.model_selection import GridSearchCV # 网格搜索
from sklearn.ensemble import RandomForestClassifier #随机森林
# - 4.随机森林预估器
estimator = RandomForestClassifier()
# ------加入网格搜索与交叉验证
# ------参数准备搜索网格:param_dict,交叉次数:cv
param_dict = {"n_estimators":[120, 150, 300], "max_depth":[5, 8, 15]}
estimator = GridSearchCV(estimator, param_grid = param_dict, cv = 3)
# ------新增内容
estimator.fit(x_train, y_train)
# - 5.模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_predict == y_test)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率:\n", score)
print("最佳参数:\n", estimator.best_params_)
print("最佳结果:\n", estimator.best_score_)
print("最佳估计器:\n", estimator.best_estimator_)
print("交叉验证结果:\n", estimator.cv_results_)
3.7 总结二

4 回归与聚类算法
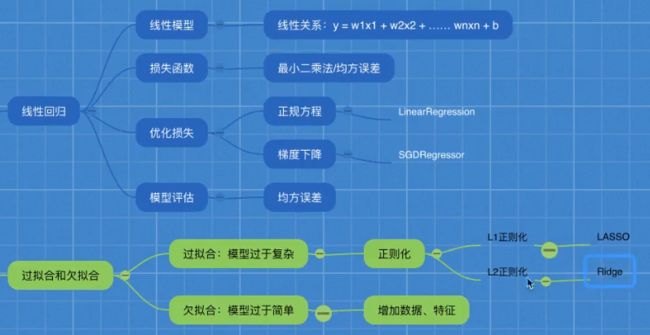
4.1 线性回归

4.1.1 损失函数

4.1.2 优化方法-正规方程

4.1.3 优化方法-梯度下降
适合大数据

4.1.4 线性回归API

4.1.5 示例:波士顿房价预测
- 1.获取数据集
- 2.划分数据集
- 3.特征工程:无量纲化(标准化)
- 4.预估器流程:fit() -> 模型
- 5.得出模型
- 6.模型评估
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor # 正规方程/梯度下降
from sklearn.metrics import mean_squared_error # 均方误差
def liner1():
"""
正规方程优化方法
"""
# - 1.获取数据集
boston = load_boston()
# print("boston数据:", boston.data.shape)
# - 2.划分数据集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target)
# - 3.特征工程:无量纲化(标准化)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# - 4.预估器流程:fit() -> 模型
estimator = LinearRegression()
estimator.fit(x_train, y_train)
# - 5.得出模型
print("正规方程w权重系数:\n", estimator.coef_)
print("正规方程b偏置:\n", estimator.intercept_)
# - 6.模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("正规方程,均方误差为:", error)
return None
def liner2():
"""
梯度下降优化方法
"""
# - 1.获取数据集
boston = load_boston()
# - 2.划分数据集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target)
# - 3.特征工程:无量纲化(标准化)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# - 4.预估器流程:fit() -> 模型
estimator = SGDRegressor()
estimator.fit(x_train, y_train)
# - 5.得出模型
print("梯度下降w权重系数:\n", estimator.coef_)
print("梯度下降b偏置:\n", estimator.intercept_)
# - 6.模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("梯度下降,均方误差为:", error)
return None
if __name__ == "__main__":
# 正规方程
liner1()
# 梯度下降
liner2()
4.1.6 回归性能分析



4.2 过拟合和欠拟合
4.2.1 定义

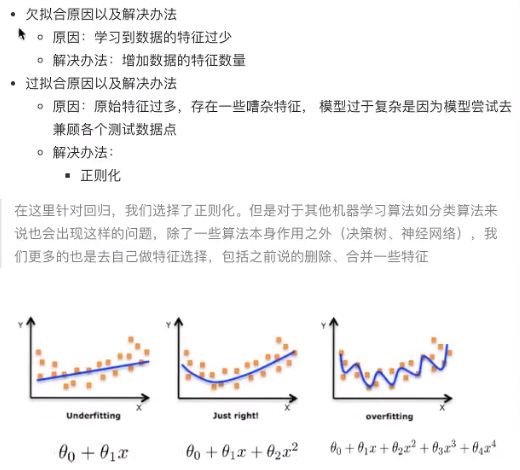
4.2.2 正则化解决过拟合

4.3 岭回归-带L2正则化的回归
解决过拟合问题
4.3.1 API


from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge # 正规方程/梯度下降
from sklearn.metrics import mean_squared_error # 均方误差
def liner3():
"""
岭回归优化方法
"""
# - 1.获取数据集
boston = load_boston()
# - 2.划分数据集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target)
# - 3.特征工程:无量纲化(标准化)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# - 4.预估器流程:fit() -> 模型
estimator = Ridge(alpha= 0.5, max_iter= 10000)
estimator.fit(x_train, y_train)
# - 5.得出模型
print("岭回归w权重系数:\n", estimator.coef_)
print("岭回归b偏置:\n", estimator.intercept_)
# - 6.模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("岭回归,均方误差为:", error)
return None
4.4 逻辑回归与二分类
4.4.1 定义

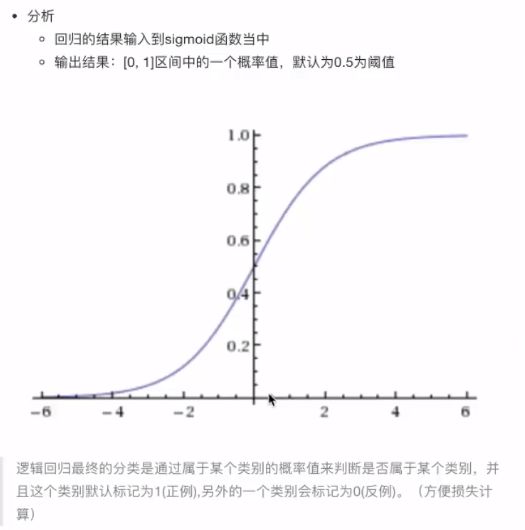
4.4.2 对数似然损失

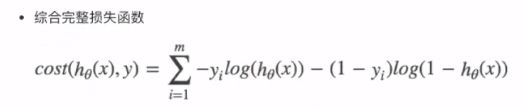
4.4.3 逻辑回归API

from sklearn.linear_model import LogisticRegression
transfer = LogisticRegression() # 预估器
transfer.fit(x_train, x_test) #训练
transfer.coef_ #回归系数
transfer.intercept_ #偏置
4.4.4 二分类的评估方法
1 召回率&精确率
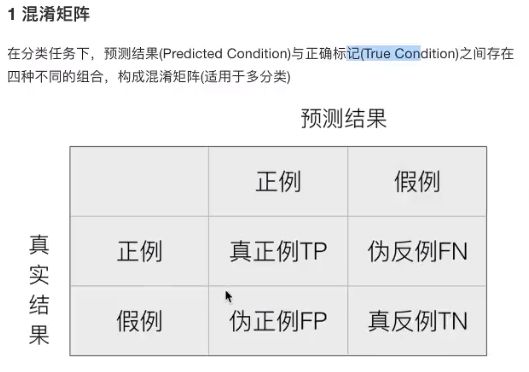



[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JujAUqgk-1583501771300)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\image-20200306203133157.png)]
from sklearn.metrics import classification_report
report = classification_report(y_test, y_predict, labels = [2, 4], target_names = ["良性", "恶性"])
2 ROC曲线与AUC指标

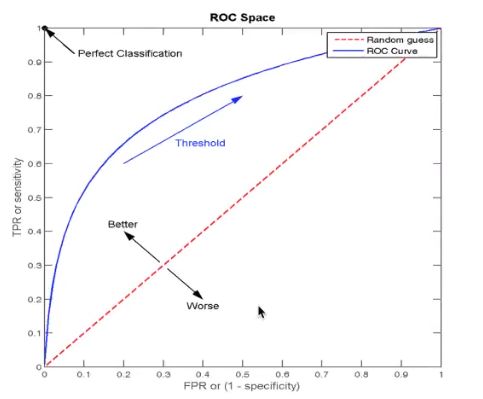


4.5 模型保存和加载
4.5.1 sklearn模型的保存和加载
rf为预估器estimator

from sklearn.externals import joblib
# ------保存模型------
joblib.dump(estimator, "my_ridge.pkl")
# ------加载模型------
estimator = joblib.load("my_ridge.pkl")
4.6 无监督学习 k-means
无目标值
- K-means(聚类)
- PCA(降维)
4.6.1 API

4.6.2 示例
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# 预估器KMeans
estimator = KMeans(n_clusters= 3)
# 训练
estimator.fit(data_new)
# 评估,性能评估指标
score = silhouette_score(data_new, y_predict)
4.6.3 Kmeans性能评估指标




4.7 总结三