Hadoop高可用集群搭建(实操、干货)
Hadoop
一、HDFS-HA 集群配置
1.1 配置 HDFS-HA 集群
1.官方地址:http://hadoop.apache.org/
2.HDFS 高可用集群规划,请保证 Hadoop 完全分布式和 ZooKeeper 完全分布 式环境已经安装完成。
hadoop102 hadoop103
JournalNode JournalNode
3.在 hadoop102 配置 core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://myclustervalue>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/install/hadoop/data/tmpvalue>
property>
configuration>
4.在 hadoop102 配置 hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservicesname>
<value>myclustervalue>
property>
<property>
<name>dfs.ha.namenodes.myclustername>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpcaddress.mycluster.nn1name>
<value>hadoop102:9000value>
property>
<property>
<name>dfs.namenode.rpcaddress.mycluster.nn2name>
<value>hadoop103:9000value>
property>
<property>
<name>dfs.namenode.httpaddress.mycluster.nn1name>
<value>hadoop102:50070value>
property>
<property>
<name>dfs.namenode.httpaddress.mycluster.nn2name>
<value>hadoop103:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://hadoop102:8485;hadoop103:8485;hadoop104:8485/my clustervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>
sshfence
shell(/bin/true)
value>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/hadoop/.ssh/id_rsavalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/opt/install/hadoop/data/jnvalue>
property>
<property>
<name>dfs.permissions.enablename>
<value>falsevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.myclustername>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailover ProxyProvidervalue>
property>
configuration>
5.拷贝配置好的 hadoop 环境到其他节点。
1.2 启动 HDFS-HA 集群
1.在各个 JournalNode 节点上,输入以下命令启动 journalnode 服务:
$HADOOP_HOME/sbin/hadoop-daemon.sh start journalnode
2.在[nn1]上,对其进行格式化,并启动:
$HADOOP_HOME/bin/hdfs namenode -format
$HADOOP_HOME/sbin/hadoop-daemon.sh start namenode
3.在[nn2]上,同步 nn1 的元数据信息:
$HADOOP_HOME/bin/hdfs namenode -bootstrapStandby
4.启动[nn2]:
$HADOOP_HOME/sbin/hadoop-daemon.sh start namenode
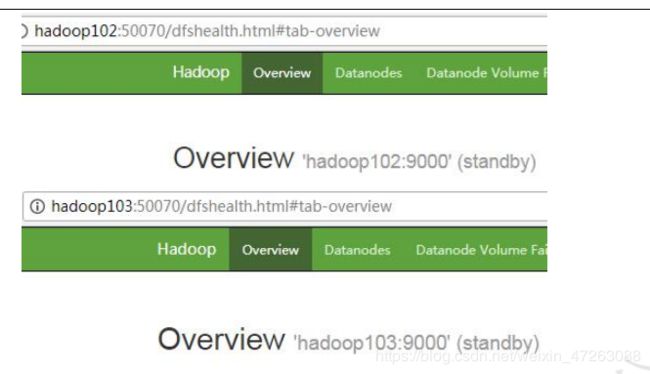
5.查看 web 页面显示
6.在[nn1]上,启动所有 datanode
$HADOOP_HOME/sbin/hadoop-daemons.sh start datanode
7.将[nn1]切换为 Active
$HADOOP_HOME/bin/hdfs haadmin -transitionToActive nn1
8.查看是否 Active
$HADOOP_HOME/bin/hdfs haadmin -getServiceState nn1
1.3 配置 HDFS-HA 自动故障转移
1.具体配置
(1)在 hdfs-site.xml 中增加
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
(2)在 core-site.xml 文件中增加
<property>
<name>ha.zookeeper.quorumname>
<value>hadoop102:2181,hadoop103:2181,hadoop104:2181value>
property>
2.启动
(1)关闭所有 HDFS 服务:
$HADOOP_HOME/sbin/stop-dfs.sh
(2)启动 Zookeeper 集群:
$HADOOP_HOME/bin/zkServer.sh start
(3)初始化 HA 在 Zookeeper 中状态:
$HADOOP_HOME/bin/hdfs zkfc -formatZK
(4)启动 HDFS 服务:
$HADOOP_HOME/sbin/start-dfs.sh
(5)在各个 NameNode 节点上启动 DFSZK Failover Controller,先在哪台机器 启动,哪个机器的 NameNode 就是 Active NameNode
$HADOOP_HOME/sbin/hadoop-daemon.sh start zkfc
3.验证
(1)将 Active NameNode 进程 kill kill -9 namenode 的进程 id
(2)将 Active NameNode 机器断开网络 service network stop
**二、YARN-HA 配置
2.1 配置 YARN-HA 集群
1.规划集群
hadoop102 hadoop103
ResourceManager ResourceManager\
2.具体配置
(1)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>cluster-yarn1value>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>hadoop102value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>hadoop103value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>hadoop102:2181,hadoop103:2181,hadoop104:2181value>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
configuration>
(2)同步更新其他节点的 yarn-site.xml 配置信息
3.启动 yarn
(1)在 hadoop102 中执行:
$HADOOP_HOME/sbin/start-yarn.sh
(2)在 hadoop103 中执行:
$HADOOP_HOME/sbin/yarn-daemon.sh start resourcemanager
(3)查看服务状态
$HADOOP_HOME/bin/yarn rmadmin -getServiceState rm1