电子表格(xls或xlsx)的读取效率比较(xlrd,openpyxl,xlwings)
一、前因
每天要从电子表格里提取数据,表格文件有点大,如下:

并且表格每天都在增加数据,不停变大,用EXCEL2007打开那叫一个慢,其实有用的数据就是那么更新的几条。
二、思路
用PYTHON把几个表中每天更新的内容提取了出来,汇总在一个表中,此表较小,操作快。提取过程也是较慢,现就xlrd、openpyxl、xlwings三种读取方式作比较,择优选择。
三、结果
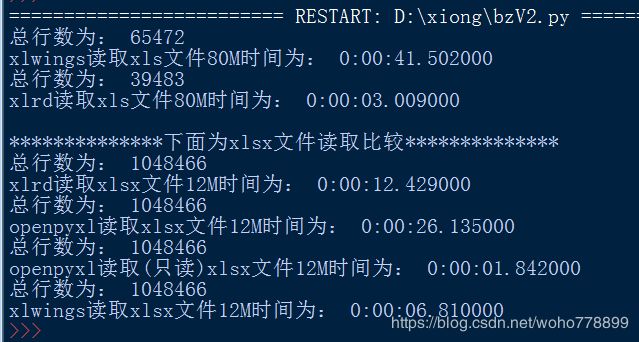
图为读取指定文件的指定SHEET的总行数,并计算所划的时间,单位为秒,越小越快。
读取XLS文件,用xlrd较快;读取xlsx文件,用openpyxl只读模式。
四、代码
import xlrd
import openpyxl
import xlwings
import datetime
t_0=datetime.datetime.now()#取出现在时间
fn=u'D:/xiong/1.xls'
app =xlwings.App(visible=False, add_book=False)
xls = app.books.open(fn)#打开电子表格文件
sheet1=xls.sheets[1]#打开第2个sheet
info=sheet1.used_range
n=info.last_cell.row#取出总行数
print(u'总行数为:',n)
t_5=datetime.datetime.now()-t_0
print(u'xlwings读取xls文件80M时间为:',t_5)
t_0=datetime.datetime.now()#取出现在时间
fn=u'D:/xiong/1.xls'
xls=xlrd.open_workbook(filename=fn)#打开电子表格文件
sheet1=xls.sheet_by_index(1)#打开第二个sheet
n=sheet1.nrows#取出总行数
print(u'总行数为:',n)
t_1=datetime.datetime.now()-t_0
print(u'xlrd读取xls文件80M时间为:',t_1)
print(u'\n**************下面为xlsx文件读取比较**************')
t_0=datetime.datetime.now()
fn=u'D:/xiong/2.xlsx'
xlsx=xlrd.open_workbook(filename=fn)#打开电子表格文件
sheet1=xlsx.sheet_by_index(0)#打开第1个sheet
n=sheet1.nrows#取出总行数
print(u'总行数为:',n)
t_2=datetime.datetime.now()-t_0
print(u'xlrd读取xlsx文件12M时间为:',t_2)
t_0=datetime.datetime.now()
fn=u'D:/xiong/2.xlsx'
xlsx=openpyxl.load_workbook(fn)#打开电子表格文件
sheet1=xlsx.worksheets[0]#打开第1个sheet
n=sheet1.max_row#读取总行数
print(u'总行数为:',n)
t_3=datetime.datetime.now()-t_0
print(u'openpyxl读取xlsx文件12M时间为:',t_3)
t_0=datetime.datetime.now()
fn=u'D:/xiong/2.xlsx'
xlsx=openpyxl.load_workbook(fn,read_only=True)#打开电子表格文件
sheet1=xlsx.worksheets[0]#打开第1个sheet
n=sheet1.max_row#读取总行数
print(u'总行数为:',n)
t_4=datetime.datetime.now()-t_0
print(u'openpyxl读取(只读)xlsx文件12M时间为:',t_4)
t_0=datetime.datetime.now()#取出现在时间
fn=u'D:/xiong/2.xlsx'
app =xlwings.App(visible=False, add_book=False)
xlsx = app.books.open(fn)#打开电子表格文件
sheet1=xlsx.sheets[0]#打开第1个sheet
info=sheet1.used_range
n=info.last_cell.row#取出总行数
print(u'总行数为:',n)
t_6=datetime.datetime.now()-t_0
print(u'xlwings读取xlsx文件12M时间为:',t_6)
五、openpyxl应用场景
xlsx=openpyxl.load_workbook(fn,read_only=True)这句要不要加“read_only=True”?
其一:如果只是读取指定位置的数据,比如:sheet1.cell(330,1).value,加上比较快。
不加的情况是

加了的情况是

快很多。
其二:如果是对整个数据进行循环、条件查找什么的,不能加,否则慢的要死,等于死机。
这样理解:加了“read_only=True”,数据不载入内存,需要就到磁盘查找,对大文件这样更快,但循环查找什么的,造成反复读盘,这样就慢了;不加,数据一次性载入内存,首次载入时间长,但载入内存后,处理起来就更快了。