爬虫------Beautiful Soup与json的转化
BeautifulSoup4和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,
支持CSS选择器(http://www.w3school.com.cn/cssref/css_selectors.asp)、Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。
如果我们没有显式地指定解析器,所以默认使用这个系统的最佳可用HTML解析器(“lxml”)。
但是我们可以通过soup = BeautifulSoup(html,“lxml”)方式指定lxml解析器。
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
• Tag,通俗点讲就是 HTML 中的一个个标签
• NavigableString,获取标签内部的文字
• BeautifulSoup,对象表示的是一个文档的内容
• Comment,是一个特殊类型的 NavigableString 对象,其输出的内容不包括注释符号
#创建 Beautiful Soup 对象(多个默认得到一个)
soup = BeautifulSoup(html,"lxml")
print(soup.title)#
print(soup.name)# [document] #soup 对象本身比较特殊,它的 name 即为 [document]
print(soup.head.name)# head #对于其他内部标签,输出的值便为标签本身的名称
print(soup.p.attrs)# {'clasprint(soup.p.attrs)s': ['title'], 'name': 'dromouse'}# 在这里,我们把 p 标签的所有属性打印输出了出来,得到的类型是一个字典。
print(soup.p.attrs["class"][0])获取标签属性
print(soup.p['class']) # soup.p.get('class')# ['title'] #还可以利用get方法,传入属性的名称,二者是等价的
print(soup.p.string)得到p标签里的内容。类型为NavigableString子类为Comment
print(type(soup.p.string))#
print(soup.p.text)得到p标签里的内容字符串
tag 的 .content 属性可以将tag的子节点以列表的方式输出
print(soup.head.contents) #[
hildren它返回的不是一个 list,不过我们可以通过遍历获取所有子节点。
我们打印输出 .children 看一下,可以发现它是一个 list 生成器对象
print(soup.head.children)#
.contents 和 .children 属性仅包含tag的直接子节点,.descendants 属性可以对所有tag的子孙节点进行递归循环,和 children类似,我们也需要遍历获取其中的内容。
for child in soup.descendants:
print(child)
搜索文档树--find_all:语法:.find_all(name, attrs, recursive, text, **kwargs)
A.传字符串:print(soup.find_all(name='b'))换行或这有别的标签获取不到内容string
B.传正则表达式:for tag in soup.find_all(re.compile("^b"))只取标签
C.传列表:print(soup.find_all(["a", "b"]))只取标签
keyword 参数:查找id为link3的标签print(soup.find_all(id='link2'))取标签放在列表
href得到所有的连接:
links = soup.find_all(href=re.compile(r'http://example.com/'))
#得到所以的链接
for link in links:
print(link.attrs["href"])或 print(link["href"])
#搜索tag名
soup.find_all("title")
#关于属性
#搜索id为"link2"的标签
soup.find_all(id='link2')
#这里属性的值可以使用字符串,正则表达式 ,列表,True
soup.find_all(id=re.compile("elsie"))
#可以指定多个条件
soup.find_all(href=re.compile("elsie"), id='link1')
#对于有些不能指定的标签(meta)Keywords可以用正则
soup.find_all(attrs={""name":"Keywords"})
#搜索内容为‘联系我们’的a标签用lambda
tell_us = soup.find_all(lambda e: e.name == 'a' and '联系我们' in e.text)
#对于class -->class为python保留字使用class_
soup.find_all(class_="top")
#属性结束
#关于string(内容)
#基础 内容为'Elsie'的
soup.find_all(string="Elsie")
#内容在数组中的
soup.find_all(string=["Tillie", "Elsie", "Lacie"])
#内容匹配正则表达式的
soup.find_all(string=re.compile("Dormouse"))
#匹配函数
soup.find_all(string=is_the_only_string_within_a_tag)
#内容结束
#搜索限制
#限制搜索数量为2
soup.find_all("a", limit=2)
#只搜索直接子节点
soup.html.find_all("a", recursive=False)
#搜索限制结束
Selectors选择器(选择器(select)-用得多)
scrapy Selectors 内置 XPath 和 CSS Selector 表达式机制
Selector有四个基本的方法,最常用的还是xpath:
xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表
extract(): 序列化该节点为Unicode字符串并返回list。可以用get替代
css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表,语法同 BeautifulSoup4
re(): 根据传入的正则表达式对数据进行提取,返回Unicode字符串list列表
1 通过标签名查找--直接标签名:print(soup.select('title'))
2 通过类名查找--.print(soup.select('.sister'))
3 通过 id 名查找--# print(soup.select('#link1'))
4 组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,二者需要用空格分开 print(soup.select('p #link1'))
直接子标签查找,则使用 > 分隔 print(soup.select("head > title"))
5 属性查找。查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。
print(soup.select('a[class="sister"]'))
6 获取内容以上的 select 方法返回的结果都是列表形式,可以遍历形式输出,然后用
get_text() 方法来获取它的内容。
JSON数据格式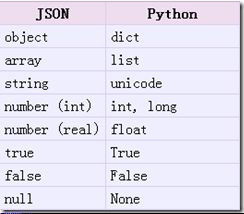
json模块
json简单说就是javascript中的对象和数组,所以这两种结构就是对象和数组两种结构,通过这两种结构可以表示各种复杂的结构
json模块提供了四个功能:dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换。
json.lo1ads()--Json转Python对象,在内存转化
#转换成python里面的列表python_list = json.loads(str_list)
json.dumps()--python转json字符串,在内存转化
#转换成json里面的列表str_list = json.dumps(list_str)# '[1, 2, 3, 4]'
注意:json.dumps() 序列化时默认使用的ascii编码
添加参数 ensure_ascii=False 禁用ascii编码,按utf-8编码
chardet.detect()返回字典, 其中confidence是检测精确度
#检查默认是用什么编码
encode = chardet.detect(str_dict.encode())
#设置使用utf-8编码
print(json.dumps(dict_str, ensure_ascii=False) )# {"name": "大猫", "city": "北京"}
json.dump()--Python转json对象,写入文件
import json
list_str = [{"city": "北京"}, {"name": "大刘"}]
#保存列表到list_str.json文件中,并且以utf-8编码
fw = open("list_str.json","w",encoding="utf-8")
json.dump(list_str, fw, ensure_ascii=False)
dict_str = {"city": "北京", "name": "大刘"}
#保存字典到dict_str.json文件中,并且以utf-8编码
fw = open("dict_str.json","w",encoding="utf-8")
json.dump(dict_str,fw , ensure_ascii=False,)
json.load()--json转python类型,读取文件
import json
f = open("list_str.json","r",encoding="utf-8")
strList = json.load(f)
print(strList)#[{'city': '北京'}, {'name': '大刘'}]
strDict = json.load(open("dict_str.json",encoding="utf-8"))
print(strDict)#{'name': '大刘', 'city': '北京'}