Hadoop安装教程_伪分布式配置(Hadoop2.7.6/Ubuntu14.04 32位)
Hadoop官方教程:Hadoop: Setting up a Single Node Cluster
1.环境
本文使用 Ubuntu 版本为 14.04 32位 ,请自行安装。Ubuntu需要安装JDK(JDK安装教程),因hadoop官方高版本只发布64位编译版,因此安装32位需要自行编译,编译过程可参考ubuntu编译hadoop源码。(部分64位hadoop编译版可运行在32位机上,只是会报warning,部分功能报错)
2.安装SSH,配置SSH免密登录
2.1安装SSH服务
Ubuntu默认安装了SSH client,因此还需要安装SSH server。
sudo apt-get install openssh-server #安装SSH服务
ps -e |grep ssh #查看SSH服务是否启动,若存在sshd进程则服务已启动
sudo /etc/init.d/ssh restart #若SSH服务未启动,启动SSH服务2.2配置SSH免密登录
2.2.1在linux系统的终端的任何目录下通过切换命令:cd ~/.ssh进入到.ssh目录下。
2.2.2 执行命令ls ,查看.ssh目录下内容。此时该目录下没有任何文件和文件夹。
2.2.3在.ssh目录下执行命令ssh-keygen -t rsa,如图所示,生成id_rsa(私钥)和id_rsa.pub(公钥)。
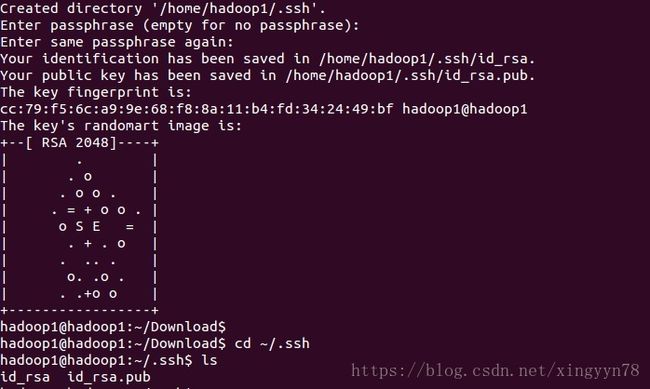
2.2.4在本机上执行ssh-copy-id localhost命令(localhost可替换为主机名,主机名请根据实际虚拟机的主机名输出;相当于该主机给自身设置免密码登录),访问主机如需要密码,密码是本用户登录密码。
2.2.5在本机上执行ssh localhost,可不用输入密码,直接通过ssh连接到本机。
3.Hadoop伪分布式配置
3.1解压hadoop-2.7.6.tar.gz
将从网上下载或本地编译获得的hadoop-2.7.6.tar.gz解压缩,进入解压出的文件夹中(本文为hadoop-2.7.6),执行./bin/hadoop version,查看是否可用。

3.2修改hadoop配置文件
3.2.1修改配置文件core-site.xml(使用gedit etc/hadoop/core-site.xml).将configuration节点添加子节点,修改为下面内容:
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://localhost:9000value>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop1/Download/hadoop-2.7.6/tmpvalue>
property>
configuration>3.2.2修改配置文件hdfs-site.xml(使用gedit etc/hadoop/hdfs-site.xml).将configuration节点添加子节点,修改为下面内容:
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.name.dirname>
<value>/home/hadoop1/Download/hadoop-2.7.6/hdfs/namevalue>
property>
<property>
<name>dfs.data.dirname>
<value>/home/hadoop1/Download/hadoop-2.7.6/hdfs/datavalue>
property>
configuration>3.2.3 etc/hadoop目录下查看是否有配置文件mapred-site.xml。目录下默认情况下没有该文件,可通过执行如下命令:cp mapred-site.xml.template mapred-site.xml修改一个文件的命名,然后执行编辑文件命令:gedit mapred-site.xml并修改该文件内容:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>3.2.4在etc/hadoop目录下执行gedit yarn-site.xml修改为:
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>3.3配置hadoop环境变量
使用gedit ~/.bashrc打开配置文件。
添加相应环境变量:
export HADOOP_HOME=/home/hadoop1/Download/hadoop-2.7.6 #相应文件夹路径
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin使用source ~/.bashrc命令使配置文件生效。
4.Hadoop运行
4.1格式化namenode
第一次运行格式化namennode。执行hdfs namenode -format命令。
4.2启动hadoop hdfs
执行start-dfs.sh命令。
4.3启动yarn
执行start-yarn.sh命令。
可使用start-all.sh一次启动所有hadoop进程
4.4查看运行进程
使用jps命令,查看运行中java进程。
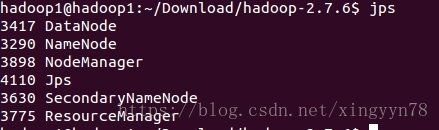
5.web管理界面
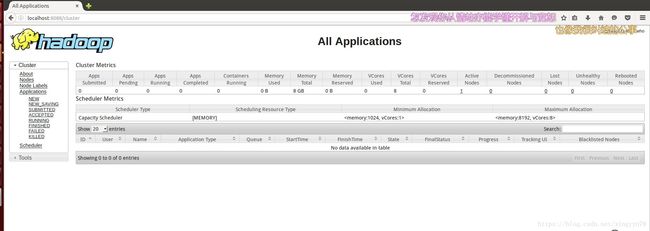
5.1MapReduce管理界面:http://localhost:8088/
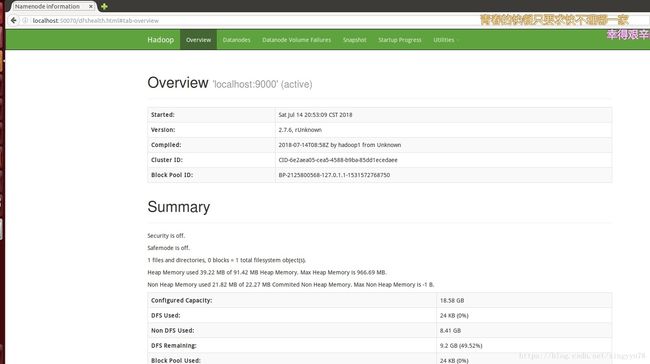
5.2HDFS管理界面:http://localhost:50070/
6退出
可执行stop-all.sh 命令,一次性关闭所有hadoop进程,也可以通过stop-dfs.sh stop-yarn.sh分别关闭进程。