Hadoop集群安装配置教程(Hadoop2.7.6_Ubuntu 32位)
1.环境
本文使用两个节点作为集群,hadoop1主机作为主节点,hadoop2主机作为从节点。hadoop1通过Hadoop安装教程_伪分布式配置(Hadoop2.7.6/Ubuntu14.04 32位),hadoop2为hadoop1虚拟机的复制。在一台电脑上运行两个虚拟机搭建集群。
2.配置IP
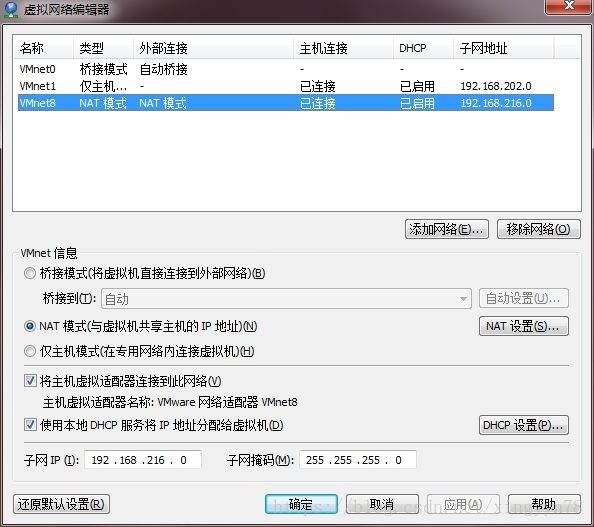
因为在一台主机上运行两台虚拟机,所以选择NAT模式,虚拟机默认通过DHCP服务器获取IP地址,搭建集群需要固定IP,因此对于虚拟机需要将通过DHCP获取IP地址修改为指定IP地址。通过查看虚拟网络编辑器及DHCP设置,获取VMware的设置。在虚拟机中打开系统设置,选择硬件中的网络,打开选项,选择IPv4设置,将DHCP换成手动,根据DHCP分配的默认路由,DNS服务器的IP地址构建IP地址。VMware的DHCP默认从x.x.x.128分配,为了方便记忆,这里hadoop1使用192.168.216.210;hadoop2使用192.168.216.220.

3.修改主机名
因为hadoop2是直接复制的hadoop1虚拟机,所以两个主机名一样,通过修改/etc/hostname文件与/etc/hosts文件修改主机名。(主机名可以随意起),这里一个为hadoop2,一个为hadoop1。在hadoop2主机中通过gedit /etc/hostname命令,打开hostname文件,将主机名hadoop1,修改为hadoop2。
通过gedit /etc/hosts命令,打开hosts文件,将对应的映射127.0.0.1 hadoop1,修改为192.168.216.220 hadoop2,在hadoop2主机中添加192.168.216.10 hadoop1映射。在hadoop1主机中将对应的映射127.0.0.1 hadoop1修改为192.168.216.210 hadoop1,添加192.168.216.20 hadoop2映射。修改完成后hosts内容应包含如下映射。修改完成后使用reboot命令重启主机或者通过界面重启主机后使配置文件生效。
127.0.0.1 localhost
192.168.216.210 hadoop1
192.168.216.220 hadoop2
此时在主机hadoop1中可以使用ping hadoop2命令ping同hadoop2主机。
此时在主机hadoop2中可以使用ping hadoop1命令ping同hadoop1主机。
4.配置SSH无密钥访问
因为hadoop2是直接复制的hadoop1虚拟机,hadoop1虚拟机已经配置好自身SSH免密登录,所以hadoop2与hadoop1拥有一样的公钥私钥,因此对hadoop2重新生成公钥和私钥。
通过cd ~/.ssh进入到.ssh文件夹中,将文件夹中的所有文件使用rm命令删除。图为.ssh文件夹中包含的内容。

在.ssh目录下执行命令ssh-keygen -t rsa,生成id_rsa(私钥)和id_rsa.pub(公钥)。使用cp ~/.ssh/id_rsa.pub ~/.ssh/hadoop2.id_rsa.pub将生成的公钥进行备份,使用命令scp ~/.ssh/hadoop2.id_rsa.pub hadoop1:~/.ssh并远程拷贝到hadoop1文件夹中。其中SSH的登录密码为hadoop1的用户密码。
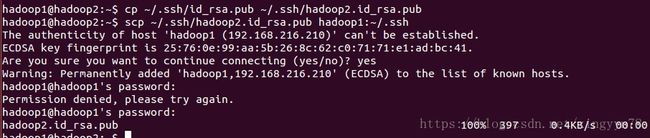
在hadoop1主机上,切换至.ssh目录,将hadoop2.id_rsa.pub追加到authorized_keys文件中。
cd ~/.ssh
cat hadoop2.id_rsa.pub >>authorized_keys
scp authorized_keys hadoop2:~/.ssh至此SSH免密码登录方式已经设置完成,在hadoop1主机上使用ssh hadoop2命令即可无密码登录hadoop2节点。
5修改hadoop配置文件
在hadoop1主机上进行配置文件修改。
进入到hadoop解压缩的文件夹中,使用mkdir命令创建tmp,logs,hdf,/hdf/data,/hdf/name,部分文件夹在伪分布式配置中已经创建,可删除重新创建。
修改hadoop配置文件,在./hadoop-2.7.6/etc/hadoop目录中。
5.1修改hadoop-2.7.3/etc/hadoop/slaves,使用sudo gedit slaves打开slaves文件配置从节点,将localhost替换为hadoop2。
5.2修改hadoop-2.7.3/etc/hadoop/core-site.xml
fs.default.name - 这是一个描述集群中NameNode节点的URI(包括协议、主机名称、端口号)。
hadoop.tmp.dir - 是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在这个路径中。使用sudo gedit core-site.xml,将文件中的配置修改为
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://hadoop1:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/home/hadoop1/Download/hadoop-2.7.6/tmpvalue>
property>
configuration>5.3修改hadoop-2.7.3/etc/hadoop/hdfs-site.xml文件
dfs.data.dir - 这是DataNode结点被指定要存储数据的本地文件系统路径。dfs.name.dir - 这是NameNode结点存储hadoop文件系统信息的本地系统路径。
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>/home/hadoop1/Download/hadoop-2.7.6/hdfs/namevalue>
<final>truefinal>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/home/hadoop1/Download/hadoop-2.7.6/hdfs/datavalue>
<final>truefinal>
property>
configuration>5.4修改mapred-site.xml文件,不存在则使用cp mapred-site.xml.template mapred-site.xml文件复制生成mapred-site.xml文件。mapreduce.framework.name - MapReduce使用的yarn框架。mapreduce.jobhistory.address - MapReduce JobHistory Server地址。mapreduce.jobhistory.webapp.address - MapReduce JobHistory Server Web UI地址。
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop1:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoop1:19888value>
property>
configuration>5.5修改hadoop-2.7.3/etc/hadoop/yarn-site.xml。yarn.nodemanager.aux-services.mapreduce.shuffle.class - 启用的资源调度器主类。yarn.resourcemanager.address-ResourceManager 对客户端暴露的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等。yarn.resourcemanager.scheduler.address-ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等。yarn.resourcemanager.resource-tracker.address-ResourceManager对NodeManager暴露的地址.。NodeManager通过该地址向RM汇报心跳,领取任务等。yarn.resourcemanager.admin.address-ResourceManager 对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等。yarn.resourcemanager.webapp.address-ResourceManager对外web ui地址。用户可通过该地址在浏览器中查看集群各类信息。yarn.nodemanager.aux-services - NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序。
<configuration>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>hadoop1:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>hadoop1:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>hadoop1:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>hadoop1:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>hadoop1:8088value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>5.6将配置好的环境变量scp到hadoop2主机中。首先在hadoop2主机上进入到hadoop解压文件夹中etc文件夹内,使用rm -rf hadoop,删除hadoop配置文件。在hadoop1主机上执行下面命令:
scp -r ./hadoop-2.7.6/etc/hadoop/ hadoop1@hadoop2:/home/hadoop1/Download/hadoop-2.7.6/etc
#scp -r local_folder remote_username@remote_ip:remote_folder具体明令根据文件夹路径进行修改6.启动Hadoop
在主节点hadoop1上,首先执行hdfs namenode -format # 首次运行需要执行初始化,之后不需要命令初始化HDFS。运行start-all.sh启动所有hadoop服务。


Web管理页面同伪分布式模式一样:MapReduce管理界面:http://hadoop1:8088/ ;HDFS管理界面:http://hadoop1:50070。